DataWorks lets you create various types of database nodes to develop SQL tasks, run them on a schedule, and integrate them with other jobs.
Prerequisites
-
A RAM user is added to the workspace (optional).
The RAM user for task development has been added to the workspace and granted the Development or Workspace Administrator (provides extensive permissions and should be granted with caution) role. For more information, see Add members to a workspace.
-
A DataWorks data source is created.
-
Ensure that the serverless resource group for the data source has network connectivity. For more information, see Network connectivity solutions.
-
Ensure that the data source uses a JDBC connection string. For more information, see Data source management.
-
Ensure that the data source supports creating database nodes. For more information, see Supported data sources.
-
-
A database node has been created. For more information, see Create task nodes.
Step 1: Develop a database node
-
After you create a database node, you can develop it.
-
Select a data source.
From the Select a data source drop-down list
 , select the data source for the task. If the required data source is not available, click Add Connection to add a new data source.
, select the data source for the task. If the required data source is not available, click Add Connection to add a new data source.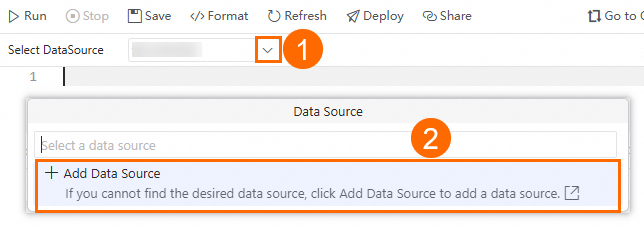 Note
Note-
In a standard mode workspace, DataWorks displays only data sources configured for both the development and production environments.
-
Database nodes support only data sources created using a JDBC connection string.
-
-
Develop the SQL script.
In the SQL editor, write SQL statements to create the task. The following code is a simple query example:
SELECT * FROM you_table_name; --Query the table. SELECT '${var}'; --Configure placeholder parameters.NoteYou can write statements based on the SQL syntax supported by your configured data source.
-
Configure a resource group for debugging.
Click Run Configuration, and from the drop-down list, select a serverless resource group that has network connectivity to the data source.
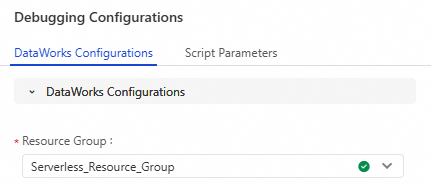 Note
NoteTo access data sources in a public network or VPC environment, use a scheduling resource group that has passed the connectivity test with the data source. For more information, see Network connectivity solutions.
-
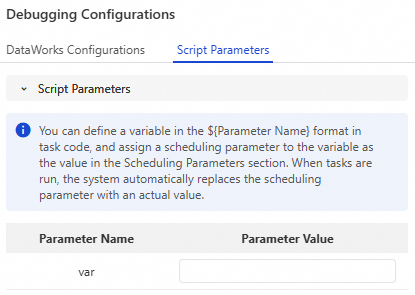
Configure debugging parameters.
Click Run Configuration. In the Script Parameters section, you can assign values to the parameters configured in the database node script.
-
After configuration, click
 to save the SQL node, and then click
to save the SQL node, and then click  to run and test the SQL script and verify that it works as expected.
to run and test the SQL script and verify that it works as expected.
-
-
After debugging the SQL script, click schedule settings on the right side of the SQL editor to configure the schedule for the database node. For more information, see Configure schedule settings.
Step 2: Deploy and manage database nodes
-
After you configure the schedule settings, you can submit and deploy the database node to the production environment. For more information, see Submit and deploy nodes.
-
After deployment, the task runs periodically based on the schedule you configured. You can view the deployed scheduled tasks in and perform O&M operations. For more information, see Manage scheduled tasks.
Supported data sources
DataWorks supports creating database nodes from various data sources. The following lists the supported database nodes:
-
Data sources used for database nodes must be created using a JDBC connection string.
-
Some databases natively support stored procedures, but stored procedures are not supported in DataWorks Data Studio.