A MySQL data source enables bidirectional synchronization with MySQL. This topic describes how DataWorks supports this synchronization through Data Integration.
Supported MySQL versions
-
Offline read and write:
Supports MySQL 5.5.x, 5.6.x, 5.7.x, and 8.0.x. Compatible with Amazon RDS for MySQL, Azure Database for MySQL, and Amazon Aurora MySQL.
Offline synchronization can read from views.
-
Real-time read:
Data Integration uses real-time subscription to read data from MySQL. It supports real-time synchronization of MySQL versions 5.5.x, 5.6.x, 5.7.x, and 8.0.x, but does not support new MySQL 8.0 features, such as the functional index. This feature is also compatible with Amazon RDS for MySQL, Azure Database for MySQL, and Amazon Aurora MySQL.
ImportantIf you need to synchronize data from DRDS, do not configure it as a MySQL data source. Instead, configure it directly as a DRDS data source. For instructions, see Configure a DRDS data source.
Limitations
Real-time synchronization
-
You cannot synchronize data from MySQL read-only instances running a version earlier than 5.6.x.
-
Synchronizing tables that contain functional indexes is not supported.
-
XA ROLLBACK is not supported.
For transactions in the XA PREPARE state, real-time synchronization writes the data to the destination. If an XA ROLLBACK command is issued, real-time synchronization does not roll back the prepared data. To handle this scenario, you must manually remove the table from the real-time synchronization task and then add it back to resynchronize.
-
The binary log format of the MySQL server must be set to ROW.
-
Real-time synchronization does not synchronize cascading deletes in associated tables.
-
For Amazon Aurora MySQL databases, you must connect to your primary/writer instance. You cannot enable the Binlog feature on Aurora MySQL read replicas, and real-time synchronization tasks require Binlog for incremental updates.
-
For online DDL changes to MySQL tables, real-time synchronization only supports adding columns (Add Column) via Data Management Service (DMS).
-
Reading stored procedures from MySQL is not supported.
Offline synchronization
-
When you use the MySQL Reader plugin to synchronize multiple tables from a sharded database, you must set the concurrency to a value greater than the number of tables to enable table splitting. Otherwise, the system creates one task per table.
-
Reading stored procedures from MySQL is not supported.
Supported data types
For a complete list of MySQL data types in each version, see the official MySQL documentation. This table lists the support status for major data types, using MySQL 8.0.x as an example.
|
Type |
Offline read (MySQL Reader) |
Offline write (MySQL Writer) |
Real-time read |
Real-time write |
|
TINYINT |
|
|
|
|
|
SMALLINT |
|
|
|
|
|
INTEGER |
|
|
|
|
|
BIGINT |
|
|
|
|
|
FLOAT |
|
|
|
|
|
DOUBLE |
|
|
|
|
|
DECIMAL/NUMERIC |
|
|
|
|
|
REAL |
|
|
|
|
|
VARCHAR |
|
|
|
|
|
JSON |
|
|
|
|
|
TEXT |
|
|
|
|
|
MEDIUMTEXT |
|
|
|
|
|
LONGTEXT |
|
|
|
|
|
VARBINARY |
|
|
|
|
|
BINARY |
|
|
|
|
|
TINYBLOB |
|
|
|
|
|
MEDIUMBLOB |
|
|
|
|
|
LONGBLOB |
|
|
|
|
|
ENUM |
|
|
|
|
|
SET |
|
|
|
|
|
BOOLEAN |
|
|
|
|
|
BIT |
|
|
|
|
|
DATE |
|
|
|
|
|
DATETIME |
|
|
|
|
|
TIMESTAMP |
|
|
|
|
|
TIME |
|
|
|
|
|
YEAR |
|
|
|
|
|
LINESTRING |
|
|
|
|
|
POLYGON |
|
|
|
|
|
MULTIPOINT |
|
|
|
|
|
MULTILINESTRING |
|
|
|
|
|
MULTIPOLYGON |
|
|
|
|
|
GEOMETRYCOLLECTION |
|
|
|
|
Prerequisites
To ensure that data synchronization tasks run correctly, prepare your MySQL environment before you add it as a data source in DataWorks.
This topic describes the required prerequisites.
Verify the MySQL version
Data Integration supports only specific versions of MySQL. For more information, see the Supported MySQL versions section. You can check the version of your MySQL database by running the following command:
SELECT version();Configure account permissions
We recommend creating a dedicated MySQL account for DataWorks to access the data source.
-
Optional: Create an account.
For detailed instructions, see Create a MySQL account.
-
Grant permissions.
-
Batch
In batch synchronization scenarios:
-
To read data from MySQL, the account must have the read (
SELECT) permission on the tables that you want to synchronize. -
To write data to MySQL, the account must have the write (
INSERT,DELETE, andUPDATE) permissions on the tables that you want to synchronize.
-
-
Real-time
In real-time synchronization scenarios, the account must have the
SELECT,REPLICATION SLAVE, andREPLICATION CLIENTpermissions on the database.
You can run the following commands to grant the required permissions. Alternatively, you can grant the account the
SUPERpermission. In the following command, replace'sync_account'with the name of the account you created.-- Optional: Create a synchronization account that can connect from any host ('%'). -- CREATE USER 'sync_account'@'%' IDENTIFIED BY 'your_password'; -- Grant the required permissions to the synchronization account. GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'sync_account'@'%';The
*.*syntax grants the permissions on all tables in all databases. You can also grant the permissions on a specific table in a specific database. For example, to grant permissions on theusertable in thetestdatabase, run the following command:GRANT SELECT, REPLICATION CLIENT ON test.user TO 'sync_account'@'%';.NoteThe
REPLICATION SLAVEpermission is a global permission and cannot be granted for a specific database or table. -
Enable MySQL binlog (for real-time synchronization only)
Data Integration performs real-time incremental data synchronization by subscribing to MySQL binlogs. Before you configure a synchronization task in DataWorks, you must enable MySQL binlog.
-
If a binlog is being consumed, the database cannot delete it. High latency in a real-time synchronization task can delay the deletion of the source binlog, which may exhaust disk space. We recommend that you configure latency alerts for your task and monitor the database disk space.
-
Retain binlogs for at least 72 hours. If a task fails and the binlogs are no longer available, you cannot reset the checkpoint to a position before the failure, which can cause data loss. In this case, you must use batch synchronization to backfill the data.
-
Check whether binlog is enabled.
-
Run the following statement to check whether binlog is enabled.
SHOW variables LIKE "log_bin";If the returned value is
ON, binlog is enabled. -
To check the binlog status on a replica database, run the following statement.
SHOW variables LIKE "log_slave_updates";If the returned value is
ON, binlog is enabled on the replica database.
If the returned value is not as expected:
-
For open-source MySQL, see the MySQL official documentation for instructions on enabling binlog.
-
For RDS for MySQL, see Back up an ApsaraDB RDS for MySQL instance for instructions on enabling binlog.
-
For PolarDB for MySQL, see Enable or disable binary logging for instructions on enabling binlog.
-
-
Check the binlog format.
Run the following statement to check the binlog format.
SHOW variables LIKE "binlog_format";Possible returned values:
-
A return value of ROW indicates that the enabled binlog format is
ROW. -
STATEMENT: The binlog format is
STATEMENT. -
MIXED: The binlog format is
MIXED.
ImportantDataWorks real-time synchronization supports only the ROW format. If the returned value is not ROW, you must change the
binlog_formatsetting. -
-
Check whether full row images are logged.
Run the following statement to check the row image setting.
SHOW variables LIKE "binlog_row_image";Possible returned values:
-
FULL: Full row images are logged.
-
MINIMAL: Minimal row images are logged instead of full row images.
ImportantDataWorks real-time synchronization supports only MySQL servers that have full row images enabled for binlog. If the returned value is not FULL, you must modify the binlog_row_image setting.
-
Configure OSS binlog read permissions
When you add a MySQL data source, if you set Configuration Mode to ApsaraDB for RDS and your RDS for MySQL instance is in the same region as your DataWorks workspace, you can enable Read binlogs from OSS. With this feature enabled, DataWorks fetches binlogs from OSS if direct access to the RDS for MySQL binlogs fails, preventing interruptions to real-time synchronization tasks.
If you use a Alibaba Cloud RAM User or a Alibaba Cloud RAM Role for OSS binlog access identity, you must also grant the required permissions.
-
RAM user
-
Log on to the Resource Access Management (RAM) console, go to the Users page, and find the target RAM user.
-
In the Operations column, click Add Permissions.
-
Configure the following parameters and click OK.
-
Scope: Alibaba Cloud account
-
Permission Policy: system policy
-
Policy Name:
AliyunDataWorksAccessingRdsOSSBinlogPolicy
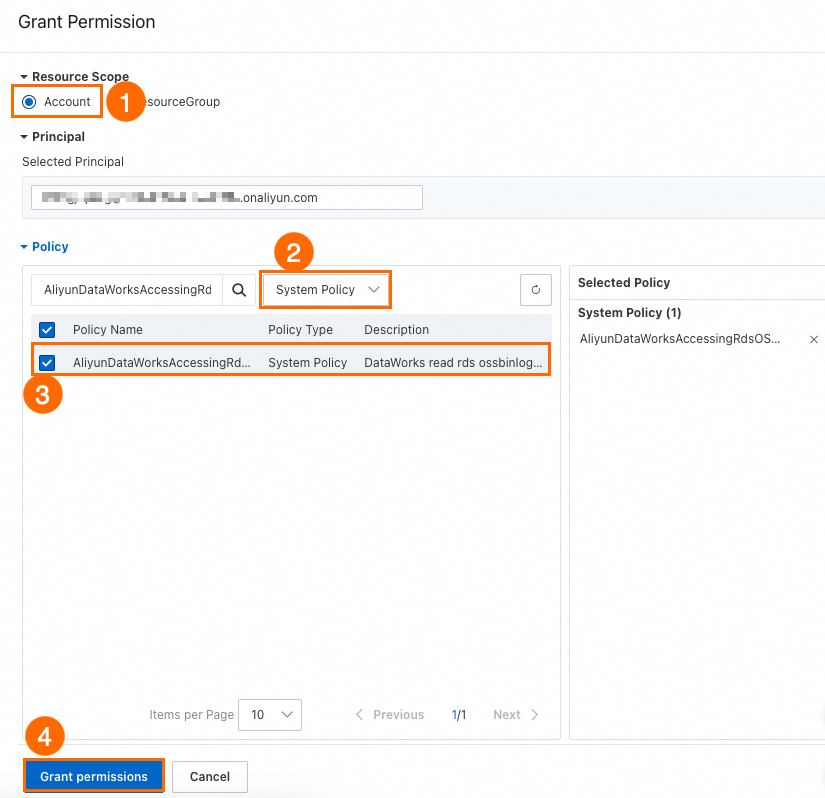
-
-
-
RAM role
-
Log on to the Resource Access Management (RAM) console and create a RAM role. For more information, see Create a RAM role for a trusted Alibaba Cloud account.
Key parameters:
-
Select trusted entity: Alibaba Cloud account
-
Select account: Other Alibaba Cloud account. Enter the ID of the Alibaba Cloud account that owns the DataWorks workspace.
-
Role name: Enter a custom name.
-
-
Grant permissions to the RAM role. For more information, see Grant permissions to a RAM role.
Key parameters:
-
Permission Policy: system policy
-
Policy Name:
AliyunDataWorksAccessingRdsOSSBinlogPolicy
-
-
Modify the trust policy of the RAM role. For more information, see Edit the trust policy of a RAM role.
{ "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "Service": [ "<your_alibaba_cloud_account_id>@di.dataworks.aliyuncs.com", "<your_alibaba_cloud_account_id>@dataworks.aliyuncs.com" ] } } ], "Version": "1" }
-
Add a data source
Alibaba Cloud instance mode
If your MySQL database runs on an Alibaba Cloud RDS instance, we recommend that you create the data source in Alibaba Cloud instance mode. Configure the parameters as follows:
|
Parameter |
Description |
|
Data Source Name |
The data source name must be unique within the workspace. We recommend using a name that clearly identifies the business and environment, for example, |
|
Configuration Mode |
Select Alibaba Cloud instance mode. For more information about configuration modes, see Scenario 1: Instance Mode (Current Cloud Account) and Scenario 2: Instance Mode (Other Cloud Account). |
|
Alibaba Cloud Account |
Select the cloud account to which the instance belongs. If you select Another Alibaba Cloud Account, you must configure cross-account permissions. For more information, see Cross-Account Authorization (RDS, Hive, or Kafka). If you select other cloud account, provide the following information:
|
|
Region |
The instance's region. |
|
Instance |
Select the name of the instance to connect to. |
|
Standby library settings |
If your RDS instance has a read-only instance (standby instance), you can configure tasks to read data from it. This prevents read operations from interfering with the performance of the primary instance. |
|
Instance Address |
After selecting the correct instance, click Get Latest Address to view information such as its public/private address, VPC, and VSwitch. |
|
Database |
The name of the database to which the data source connects. Ensure that the specified user has the required permissions to access this database. |
|
Access identity |
Select the credential source that DataWorks uses to access MySQL. The following options are supported:
|
|
Support OSS binlog reading |
If enabled, DataWorks attempts to fetch binlogs from OSS when RDS binlogs are inaccessible. This prevents interruptions to real-time synchronization tasks. For more information, see Configure authorization for reading OSS binlogs. Based on your authorization configuration, set the OSS binlog access identity. |
|
Authentication Method |
Select no authentication or SSL authentication. If you select SSL authentication, ensure it is also enabled on the instance. Prepare the certificate file and upload it to Authentication File Management. |
|
Version |
Log on to the MySQL server and run the |
Connection string mode
You can also use the connection string mode to create a data source, which offers more flexibility. Configure the parameters as follows:
|
Parameter |
Description |
|
Data Source Name |
The data source name must be unique within the workspace. We recommend using a name that clearly identifies the business and environment, for example, |
|
Configuration Mode |
Select User-created Data Store with Public IP Addresses. In this mode, a JDBC URL is used to connect to the database. |
|
Connection string preview |
After entering the connection address and database name, DataWorks automatically generates a preview of the JDBC URL. |
|
Connection Address |
Host address: Enter the IP address or domain name of the database. If the database is an Alibaba Cloud RDS instance, you can find the address on the Database Connection page in the instance details. Port number: The database port. The default value is 3306. |
|
Database Name |
The name of the database to which the data source connects. Ensure that the specified user has the required permissions to access this database. |
|
Access identity |
Select the credential source that DataWorks uses to access MySQL. The following options are supported:
|
|
Version |
Log on to the MySQL server and run the |
|
Authentication Method |
Select no authentication or SSL authentication. If you select SSL authentication, ensure it is also enabled on the instance. Prepare the certificate file and upload it to Authentication File Management. |
|
Advanced Parameters |
Parameter: Select a supported parameter from the drop-down list, for example, Value: Enter an appropriate value for the selected parameter, for example, 3000. The URL is then automatically updated to: |
Ensure the DataWorks resource group can connect to the database. Otherwise, subsequent tasks will fail. Network configuration depends on the database environment and data source connection mode. For more information, see Test connectivity.
MySQL synchronization workflow
For information about the entry point for and the procedure of configuring a synchronization task, see the following configuration guides.
Configure single-table offline synchronization
-
See Wizard mode configuration and Script mode configuration for the procedure.
-
See Appendix: MySQL sample script and parameter reference for all script mode parameters and a sample script.
Configure single-table real-time synchronization
See Real-time synchronization task configuration (Legacy) for the procedure.
Configure full-database synchronization
See Full database real-time synchronization task configuration for the procedure.
FAQ
-
Error during real-time synchronization from a MySQL data source
-
Why does real-time synchronization for a MySQL data source slow down?
For other common Data Integration issues, see FAQ about Data Integration.
Appendix: MySQL script examples and parameters
Configure a batch synchronization task by using the code editor
If you want to configure a batch synchronization task by using the code editor, you must configure the related parameters in the script based on the unified script format requirements. For more information, see Script mode configuration. The following information describes the parameters that you must configure for data sources when you configure a batch synchronization task by using the code editor.
Reader script examples
This topic provides configuration examples for a single table in a single database and for sharded tables.
The comments in the following JSON examples are for demonstration purposes only. Remove the comments before you run the script.
-
Single table in a single database
{ "type": "job", "version": "2.0",// The version number. "steps": [ { "stepType": "mysql",// The connector name. "parameter": { "column": [// The columns to read. "id" ], "connection": [ { "querySql": [ "select a,b from join1 c join join2 d on c.id = d.id;" ], "datasource": ""// The data source name. } ], "where": "",// The filter condition. "splitPk": "",// The shard key. "encoding": "UTF-8"// The encoding format. }, "name": "Reader", "category": "reader" }, { "stepType": "stream", "parameter": {}, "name": "Writer", "category": "writer" } ], "setting": { "errorLimit": { "record": "0"// The maximum number of allowed dirty data records. }, "speed": { "throttle": true,// Set to true to enable rate limiting. If false, rate limiting is disabled and the 'mbps' parameter is ignored. "concurrent": 1,// The number of concurrent threads. "mbps": "12"// The rate limit. 1 mbps = 1 MB/s. } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } } -
Sharded tables
NoteThe MySQL Reader can read data from multiple MySQL tables that have the same schema. In this context, "sharded tables" refers to a scenario where data from multiple source tables is written to a single destination table. To synchronize sharded tables at the database level, create a task in Data Integration and select the full database sharding feature.
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "mysql", "parameter": { "indexes": [ { "type": "unique", "column": [ "id" ] } ], "envType": 0, "useSpecialSecret": false, "column": [ "id", "buyer_name", "seller_name", "item_id", "city", "zone" ], "tableComment": "Test order table", "connection": [ { "datasource": "rds_dataservice", "table": [ "rds_table" ] }, { "datasource": "rds_workshop_log", "table": [ "rds_table" ] } ], "where": "", "splitPk": "id", "encoding": "UTF-8" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": {}, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" } } ], "setting": { "executeMode": null, "errorLimit": { "record": "" }, "speed": { "concurrent": 2, "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }
Reader parameters
|
Parameter |
Description |
Required |
Default |
|
datasource |
The name of the data source to read from. This name must match a data source configured in the code editor. |
Yes |
None |
|
table |
The name of the source table to synchronize. A Data Integration task can read data from only one logical table. The following examples show how to use advanced patterns for the
Note
The task reads the columns specified in the |
Yes |
None |
|
column |
A JSON array that specifies the columns to read from the source table. To select all columns, use
|
Yes |
None |
|
splitPk |
When MySQL Reader extracts data, if you specify the
|
No |
None |
|
splitFactor |
The sharding factor. This parameter controls how many shards are created. If concurrency is enabled, the data is split into Note
Recommended range: 1 to 100. A value that is too large may cause an out-of-memory (OOM) error. |
No |
5 |
|
where |
A filter condition. In a typical scenario, to synchronize only the current day's data, you can set the
|
No |
None |
|
querySql (Available only in the code editor; not supported in the codeless UI.) |
In some use cases, the Note
The |
No |
None |
|
useSpecialSecret |
Specifies whether to use the password of each individual data source when you have multiple source data sources. Valid values:
If you configure multiple source data sources that have different usernames and passwords, set this parameter to true to use the credentials of each respective data source. |
No |
false |
Writer script example
{
"type": "job",
"version": "2.0",// The version number.
"steps": [
{
"stepType": "stream",
"parameter": {},
"name": "Reader",
"category": "reader"
},
{
"stepType": "mysql",// The connector name.
"parameter": {
"postSql": [],// The SQL statements to run after the task.
"datasource": "",// The data source name.
"column": [// The columns to write to.
"id",
"value"
],
"writeMode": "insert",// The write mode. Valid values: insert, replace, and update.
"batchSize": 1024,// The number of records per batch.
"table": "",// The destination table name.
"nullMode": "skipNull",// The policy for handling NULL values.
"skipNullColumn": [// The columns for which to skip NULL values.
"id",
"value"
],
"preSql": [
"delete from XXX;"// The SQL statements to run before the task.
]
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {// The maximum number of allowed dirty data records.
"record": "0"
},
"speed": {
"throttle": true,// Set to true to enable rate limiting. If false, rate limiting is disabled and the 'mbps' parameter is ignored.
"concurrent": 1,// The number of concurrent threads.
"mbps": "12"// The rate limit in MB/s to prevent excessive I/O pressure on the databases. 1 mbps = 1 MB/s.
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Writer parameters
|
Parameter |
Description |
Required |
Default |
|
datasource |
The name of the destination data source. This name must match a data source configured in the code editor. |
Yes |
None |
|
table |
The name of the destination table. |
Yes |
None |
|
writeMode |
The write mode. The supported options correspond to the MySQL
|
No |
insert |
|
nullMode |
Specifies the policy for handling NULL values from the source. Valid values:
Important
When configured as skipNull, the task dynamically constructs SQL statements for writing data to support default values at the destination. This increases the number of FLUSH operations and reduces synchronization speed. In the worst-case scenario, the task will FLUSH once for each data record. |
No |
writeNull |
|
skipNullColumn |
When nullMode is set to skipNull, the columns specified by this parameter are not forced to Format: |
No |
All columns configured for the task. |
|
column |
The destination columns to write to, specified as a JSON array of strings. Example: |
Yes |
None |
|
preSql |
One or more SQL statements to execute before the synchronization task starts. The codeless UI supports only one statement, while the code editor supports multiple. For example, you can clear existing data from a table: Note
Transactions are not supported for multiple SQL statements. |
No |
None |
|
postSql |
One or more SQL statements to execute after the synchronization task completes. The codeless UI supports only one statement, while the code editor supports multiple. For example, you can add a timestamp column by using the following statement: Note
Transactions are not supported for multiple SQL statements. |
No |
None |
|
batchSize |
The number of records per write batch. Larger values reduce network round-trips and can improve throughput, but setting the value too high may cause an out-of-memory (OOM) error. |
No |
256 |
|
updateColumn |
When |
No |
None |