Scheduling parameters act as dynamic values in data synchronization node configurations — replacing static dates, table names, or field values with runtime-computed values derived from the node's data timestamp. This topic covers four common scenarios: synchronizing incremental data, handling dynamic table or file names, defining destination fields, and backfilling historical data.
Before you begin
Before clicking Run or Run with Parameters in the top toolbar of the configuration tab of a batch synchronization node, manually assign constants to the variables referenced in the node code. Data Integration does not support smoke testing on batch synchronization nodes in the development environment.
To verify that scheduling parameters are replaced as expected, use one of the following methods:
-
Run smoke testing on an SQL node that uses the same scheduling parameters. If the SQL node passes, the parameters are configured correctly. For details, see Configure and use scheduling parameters.
-
Commit the node to Operation Center in the development environment.
Scenario overview
| Scenario | Supported Reader plug-ins (examples) | Details |
|---|---|---|
| Synchronize incremental data | MySQL Reader, LogHub Reader, Kafka Reader | Scenario 1 and Scenario 4 |
| Synchronize data from tables or files with dynamic names | Object Storage Service (OSS) Reader, FTP Reader, MySQL Reader | Scenario 2 |
| Assign a constant or time-based value to a destination field | Varies by data source | Scenario 3 |
Scenario 1: Synchronize incremental data
Scheduling parameters in a filter condition act as dynamic time boundaries: at runtime, each expression is replaced with the actual date derived from the node's data timestamp. This ensures each run reads only the data generated within the target time window, avoiding full reloads. Make sure the filter condition syntax is supported by the source.
For more information, see Scenario: Configure an incremental offline data synchronization task.
The time range used in filter conditions is a left-closed, right-open interval.
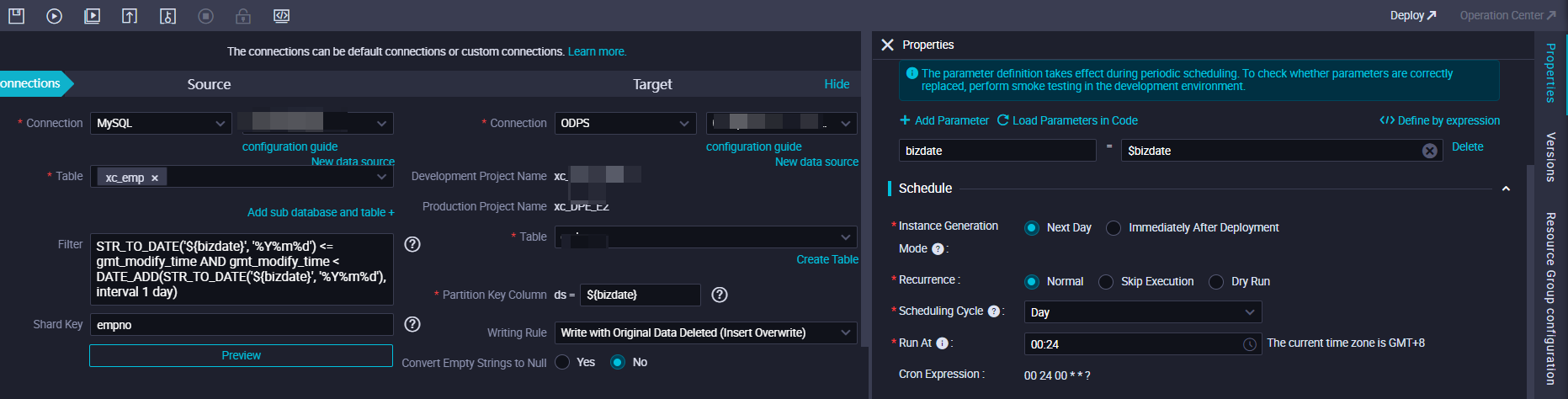
Example 1: Sync LogHub data every 10 minutes to a T-1 MaxCompute partition
The node generates a scheduling instance every 10 minutes. $bizdate specifies the data timestamp of the data synchronization node, and the partition filter expressions resolve to the corresponding 10-minute window boundaries at runtime.
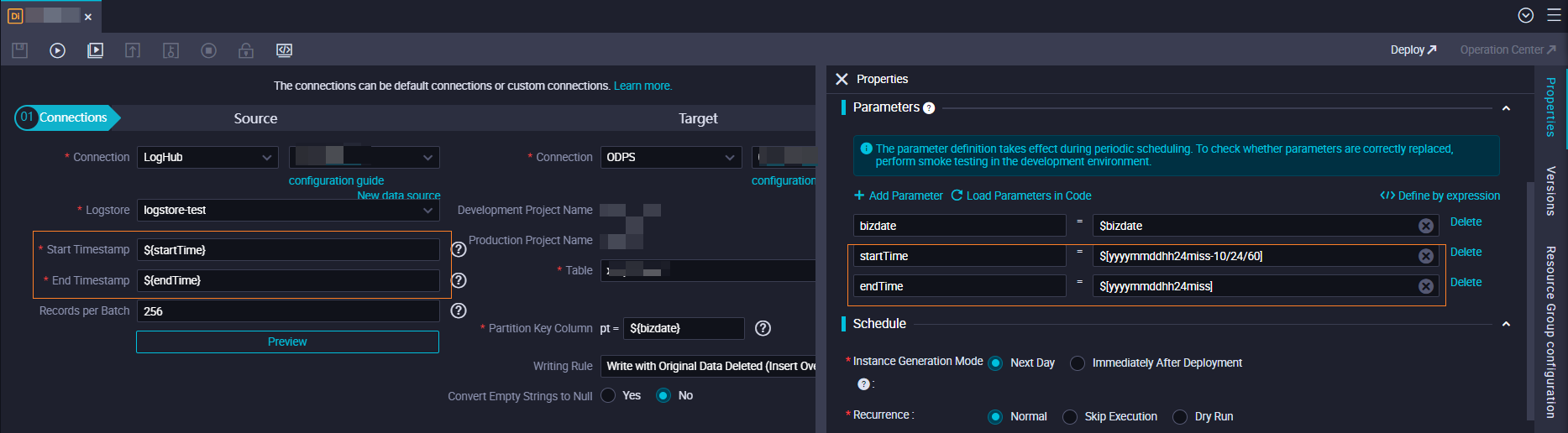
Example 2: Sync the previous day's LogHub data to a T-1 MaxCompute partition at 00:00 daily
The filter condition uses $bizdate to capture all data generated on the previous day. The time range is a left-closed, right-open interval.
Scenario 2: Synchronize data from tables or files with dynamic names
Embed scheduling parameters directly in the source table name or file path so the node automatically reads from the correct table or file on each run.
For some Reader plug-ins, you must use the code editor to configure scheduling parameters for dynamic names. When variables are used in the configuration, data preview is not supported.
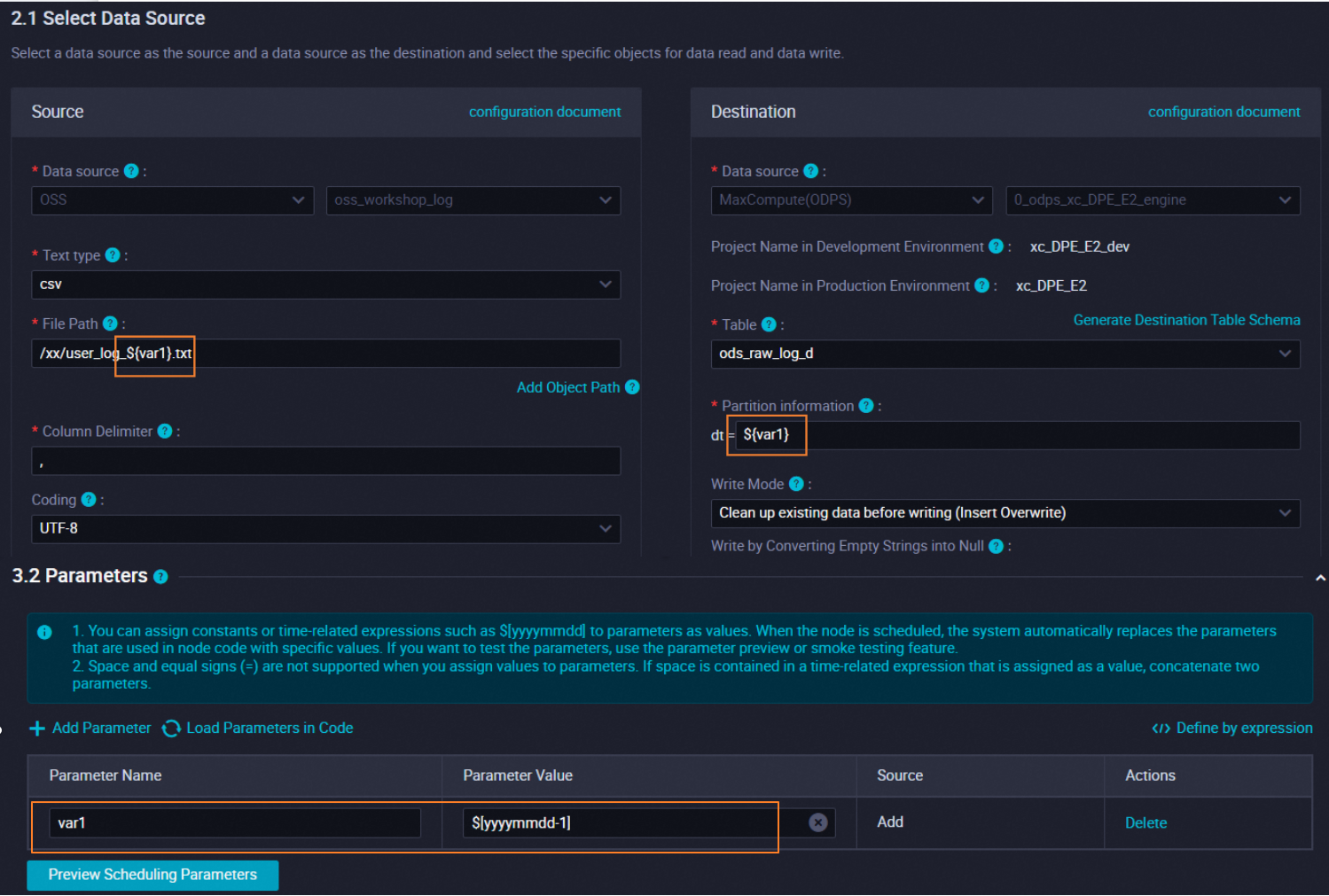
Example 1: Sync OSS files with date-based names to MaxCompute
Configure the source object path with a scheduling parameter so the node reads from the correct dated folder each day and writes data to the corresponding partition in MaxCompute.
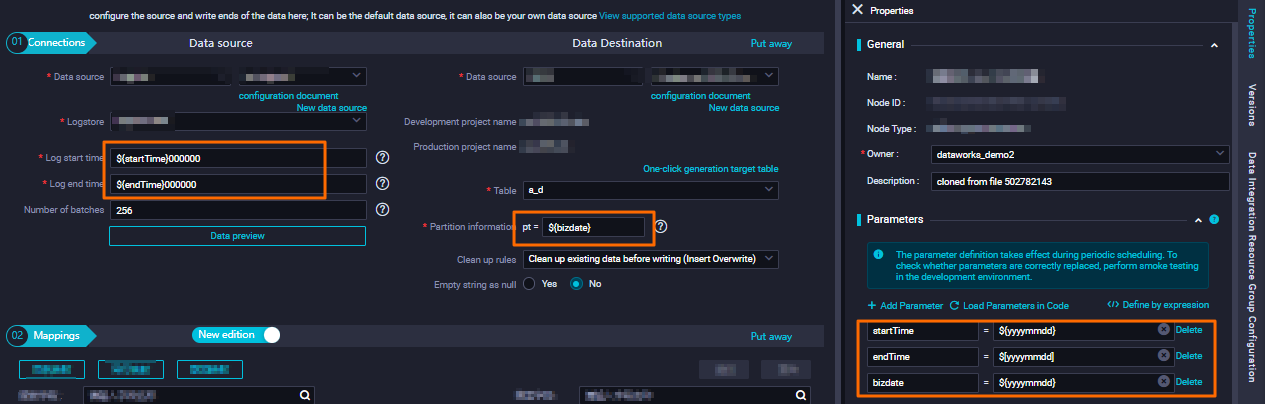
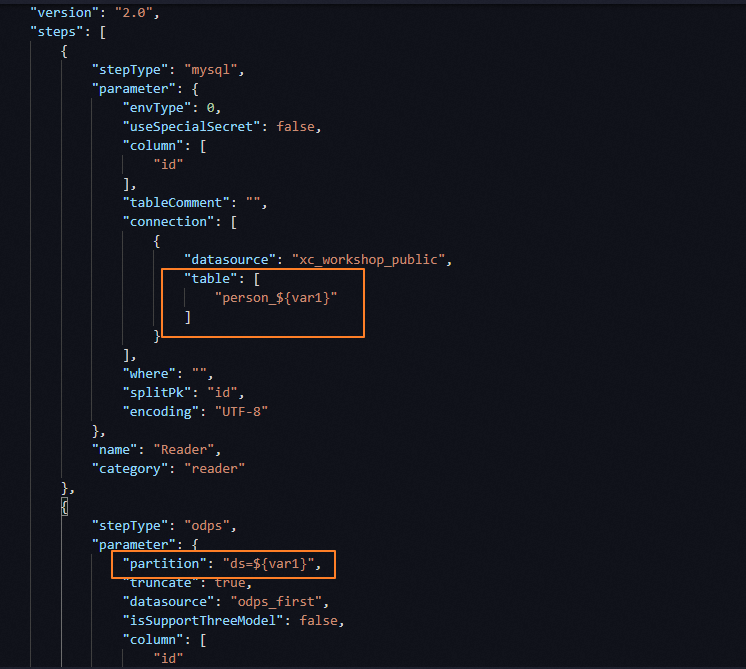
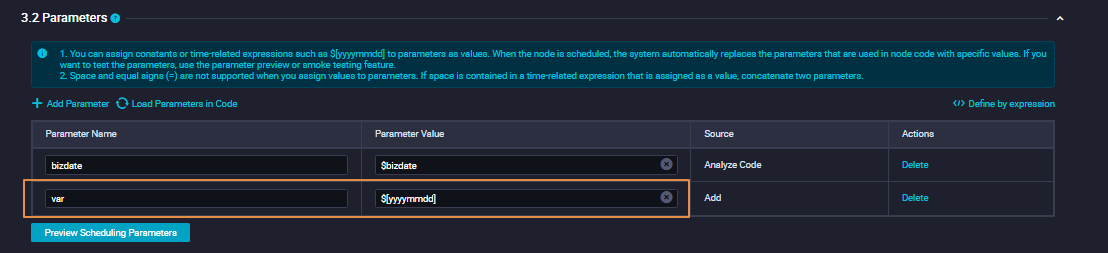
Example 2: Sync MySQL tables with date-based names to MaxCompute
Configure the source table name with a scheduling parameter so the node reads from the correct dated table each day. The following figures show the configuration in both the code editor and the codeless UI.
Scenario 3: Define destination fields
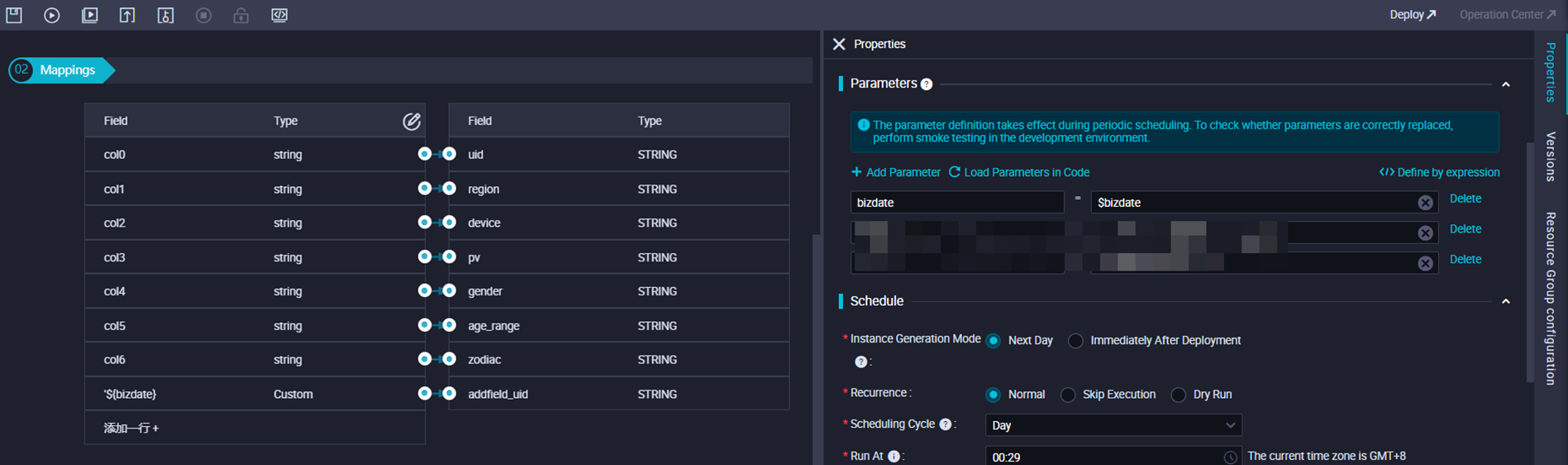
When configuring field mappings, assign a constant derived from the node's data timestamp to a destination field. The system updates that field automatically on every run based on the scheduling parameter value. Support varies by data source type.
For example, the following configuration assigns the data timestamp to a ds field in the destination table, which is updated daily.
Scenario 4: Synchronize historical data
Scheduling parameters are automatically replaced with specific values based on the data timestamps of nodes and value formats of scheduling parameters. This enables dynamic parameter configuration for node scheduling. In a data backfill run, each parameter is replaced using the data timestamp specified by the backfill operation.
Use the data backfill feature in Operation Center to generate data for a specified historical time range. For details, see Data backfill instance O&M.
Example: Backfill incremental MySQL data into time-partitioned MaxCompute tables
The following figure shows how to write incremental data from a MySQL source to a specified time partition in MaxCompute using data backfill.