Data Integration supports full and incremental data replication for entire instances from sources such as ApsaraDB for OceanBase, MySQL, Oracle, and PolarDB to MaxCompute. This task combines a full data load with ongoing incremental replication. It begins with a full migration of your existing data, followed by the continuous capture of incremental data. These changes are then merged into the destination on the following day (T+1). This topic uses a MySQL-to-MaxCompute task as an example to demonstrate how to create an Entire Instance Full and Incremental task.
How it works
An Entire Instance Full and Incremental task uses a unified workflow for the initial full data migration and ongoing incremental synchronization. After the task starts, the system automatically creates and coordinates offline and real-time subtasks to merge data into the destination base table.
The core process consists of three phases:
Full data load: After the task starts, an offline synchronization subtask runs first. This subtask performs a one-time migration of the schema and existing data for all selected source tables to their destination base tables in MaxCompute. Once the full load is complete, this offline subtask is suspended.
Incremental data synchronization: After the full load, the system starts a real-time synchronization subtask. This subtask continuously captures incremental data changes (Insert, Update, Delete) from the source database (for example, through MySQL Binlog) and writes them in near real-time to a temporary log table in MaxCompute.
Periodic merge: The system automatically runs a merge task daily (on T+1). This task merges the previous day's (Day T) incremental data from the Log table into the Base table. This process generates the latest full snapshot for day T and writes it to a new partition in the Base table.
The following diagram illustrates the data flow when writing to a partitioned table:

This synchronization task has the following features:
Many-to-many/many-to-one table mapping: You can synchronize multiple source tables to their corresponding destination tables or use mapping rules to consolidate data from multiple source tables into a single destination table.
Task composition: An entire instance synchronization task consists of an offline subtask for the full load, a real-time subtask for incremental synchronization, and a merge task for data consolidation.
Target table support: Data can be written to both partitioned and non-partitioned tables in MaxCompute.
Prerequisites
Resource requirements: These tasks require a Serverless Resource Group. The minimum required resources are either an 8-core, 16 GB Exclusive Resource Group for Data Integration or 2 CUs for a Serverless Resource Group.
Network connectivity: The Data Integration resource group must be able to connect to both the source (for example, MySQL) and the destination (for example, MaxCompute) data sources. For more information, see Configure a network connection.
Region restrictions: You can only synchronize data to a self-managed MaxCompute data source that is in the same region as your DataWorks workspace. When using a self-managed source, you must also bind a MaxCompute compute resource in the Data Development section of your DataWorks workspace. Failure to do so will prevent the creation of MaxCompute SQL nodes, causing the full synchronization `done` node to fail.
Scheduling resource group restrictions: The task uses the configured Serverless Resource Group as its scheduling resource group.
Target table type restrictions: You cannot synchronize source data to a MaxCompute external table.
Important
Primary key requirement: Tables without a primary key are not supported. You must manually define a Business Primary Key for any such tables during configuration.
Data visibility delay: On the day an Entire Instance Full and Incremental task is configured, you can only query the historical full data. Incremental data can be queried in MaxCompute only after the next day's merge operation completes. For more information, see the data writing section in Introduction to full and incremental synchronization to MaxCompute.
Storage and lifecycle: The synchronization task creates a new full data partition every day. To prevent excessive storage consumption, the task automatically sets a default 30-day lifecycle for any new MaxCompute tables it creates. If this duration is insufficient, you can modify the lifecycle by clicking the MaxCompute table name during task configuration. For more information, see Step 5: Map to destination tables.
SLA: Data Integration uses MaxCompute data channels for data uploads and downloads. For details about the Service Level Agreement (SLA) for these data channels, see Tunnel. Evaluate your technical choices for data synchronization based on the MaxCompute data channel SLA.
Binlog retention policy: Real-time synchronization depends on the source MySQL binlog. Ensure that the binlog retention period is long enough to prevent synchronization failures. If a task is paused for an extended period or fails and needs to be retried, the required starting position in the binlog might be lost if the retention period is too short.
Billing
An Entire Instance Full and Incremental task consists of three components that are billed separately: an offline synchronization task for the full load phase, a real-time synchronization task for the incremental phase, and a periodic task for the periodic merge phase. All three phases consume CUs from the resource group (for billing details, see Billing of Data Integration). The periodic task also incurs scheduling fees (for more information, see Billing of scheduling).
In addition, the synchronization process to MaxCompute requires periodic merges of full and incremental data, which consumes MaxCompute computing resources. These costs are charged directly by MaxCompute and are proportional to the amount of full data you synchronize and the merge frequency. For more information about pricing, see Billing.
Procedure
1. Select the task type
Go to the Data Integration page.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Integration.
In the left-side navigation pane, click Synchronization Task. At the top of the page, click Create Synchronization Task. In the Create Synchronization Task dialog box, specify the following key information:
Source Type:
MySQL.Destination Type:
MaxCompute.Name: Enter a custom name for the task.
Task Type:
Entire Instance Full and Incremental.Sync Procedure: Schema Migration, Incremental Synchronization, Full Synchronization, and Periodic Merge are selected by default.
2. Configure data sources and the resource group
For Source Data Source, select your added
MySQLdata source. For Target Data Source, select your addedMaxComputedata source.In the Runtime Resource section, select the Resource Group for the task and allocate Resource Group CUs for it. You can set CUs separately for full synchronization and incremental synchronization to control resource usage and prevent waste.
NoteDataWorks offline synchronization tasks are submitted to the Data Integration execution resource group by the scheduling resource group. Therefore, in addition to using the execution resource group, the offline task also consumes resources from the scheduling resource group, which incurs scheduling instance fees.
Ensure that both the source and destination data sources pass the Connectivity Test.
3. Select the databases and tables to synchronize
In the Source Table area, select the tables to sync from the source data source. Click the ![]() icon to move the tables to the Selected Tables list.
icon to move the tables to the Selected Tables list.
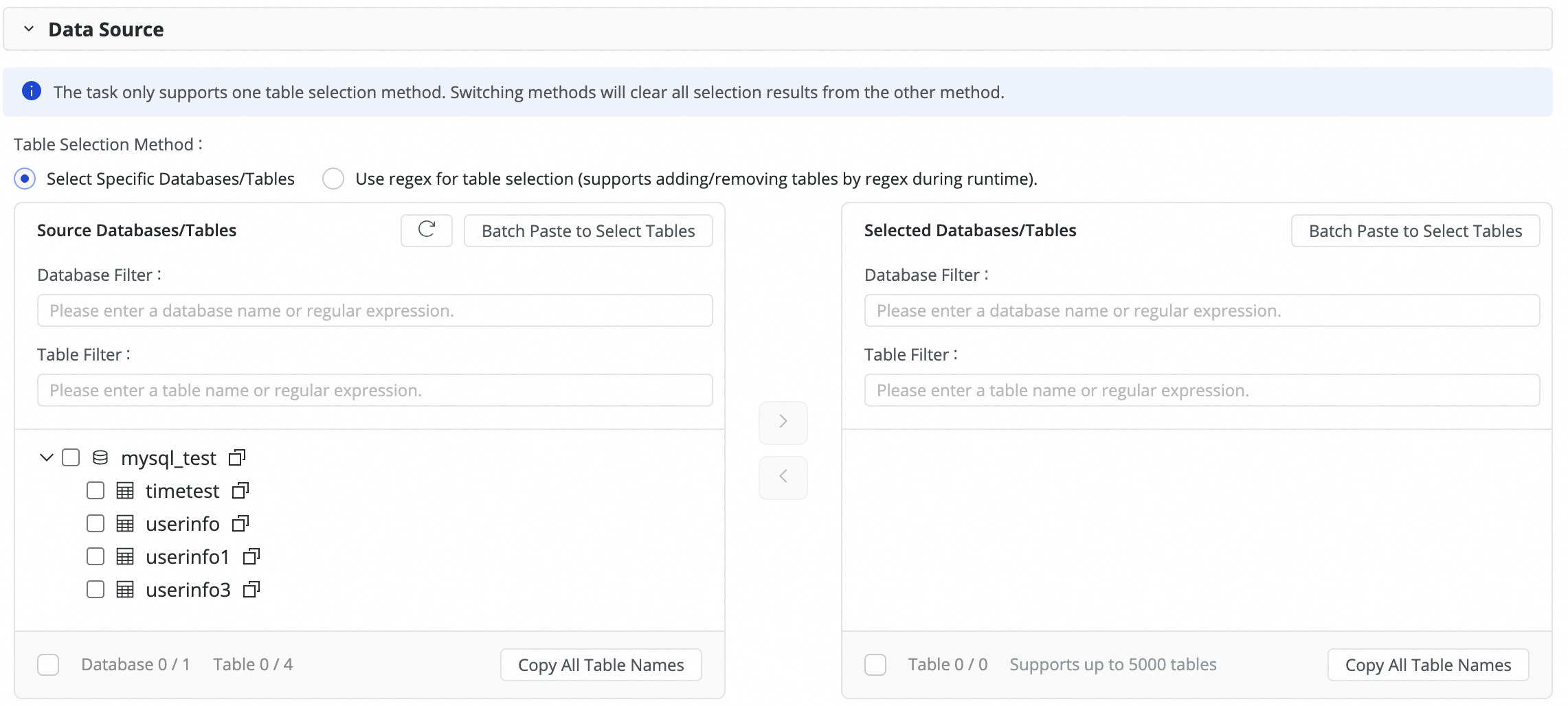
If you have a large number of databases or tables, you can use the Database Filter or Table Filter, or configure regular expressions to select the tables you want to synchronize.
4. Configure task settings
Time Range for Log Table: This parameter defines the time window for querying data from the log table to be merged into the destination partition.
To prevent partition errors caused by data delays across days, extend this range to ensure all data for a specific partition is correctly merged.
Merge Task Scheduling Settings: Set the daily schedule for the merge task. For more information on how to configure scheduling, see Configure time properties.
Periodic Scheduling Parameters: Configure scheduling parameters. You can use these parameters later in the partition settings to assign values to partitions, which is useful for creating date-based partitions.
Table Partition Settings: Configure partitions for the destination tables. You can set key parameters such as the partition column name and assignment method. The partition value can be assigned by using scheduling parameters to automatically generate date-based partitions.
5. Map to destination tables
In this step, you define the mapping rules between source and destination tables and configure settings like primary keys, dynamic partitions, and DDL/DML rules to control how data is written.
Action | Description | ||||||||||||
Refresh Mapping | The system automatically lists the source tables you selected. You must then refresh the mapping to apply settings and view the destination table properties.
| ||||||||||||
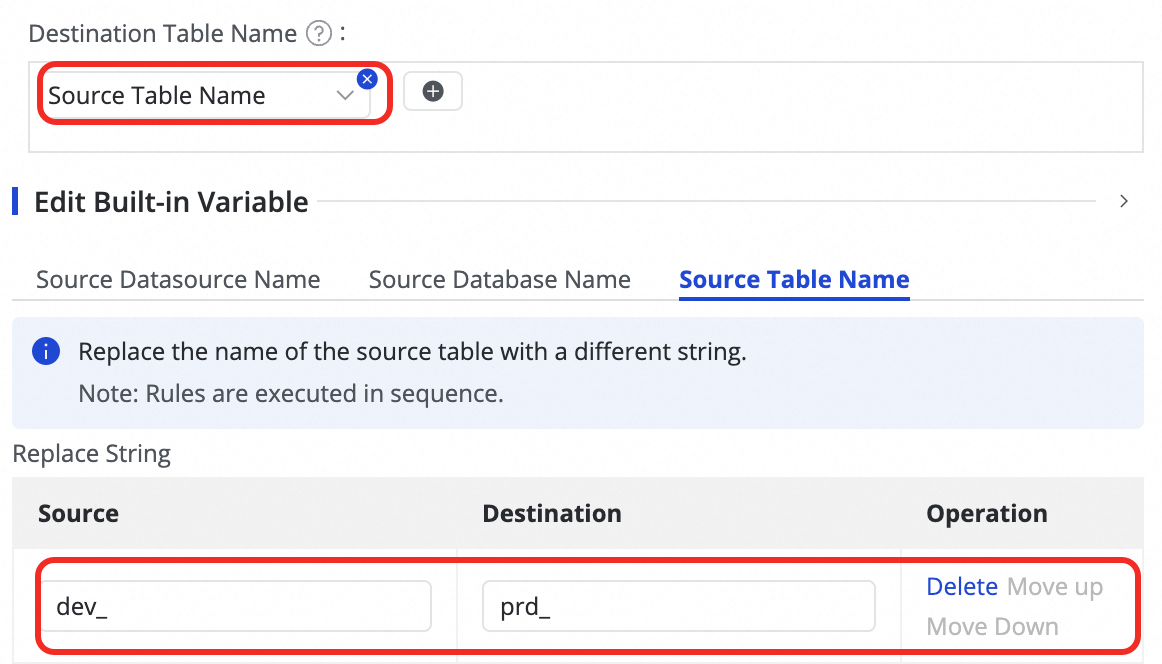
Customize Destination Table Name Mapping (Optional) | The system has a default table naming rule:
You can achieve the following:
| ||||||||||||
Edit Field Type Mapping (Optional) | The system provides a default mapping between source and destination field types. You can click Edit Field Type Mapping in the upper-right corner of the table to customize the mapping. When you are finished, click Apply and Refresh Mapping. When you edit the field type mapping, ensure that the type conversion rules are valid. Incorrect rules can cause type conversion failures, generate dirty data, and disrupt the task. | ||||||||||||
Edit Destination Table Schema (Optional) | The system automatically creates destination tables that do not exist or reuses existing tables with the same name, based on your custom naming rules. DataWorks automatically generates the destination table schema based on the source table schema. In most cases, no manual changes are needed. However, you can modify the table schema in the following ways:
For existing tables, you can only add fields. For new tables, you can add fields, partition fields, and set the table type or properties. For details, refer to the editable areas in the UI. | ||||||||||||
Assign a value to a destination table field | The system automatically maps fields that exist in both the source and destination tables by name. You must manually assign values for any newly added fields.
You can assign constants or variables. Switch the type in the Assignment Method menu. The following methods are supported:
| ||||||||||||
Set Source Shard Key | From the source shard key drop-down list, you can select a field from the source table or choose Do not shard. During synchronization, the task splits into multiple subtasks based on this key, which enables data to be read in parallel batches. Use a field with an even data distribution, such as the table's primary key, as the shard key. String, float, and date types are not supported. Currently, the source shard key is supported only when the source is MySQL. | ||||||||||||
Skip Full Synchronization | If you have already configured full synchronization, you can choose to skip the full synchronization for a specific table. This is useful if you have already synchronized the full data to the destination by other means. | ||||||||||||
Full Synchronization Condition | Applies a filter to the source data during the full load phase. Enter only the `WHERE` clause, without the `WHERE` keyword. | ||||||||||||
DML Rule Configuration | DML message handling allows you to finely filter and control the change data ( | ||||||||||||
Full Merge Period | Currently, only daily merges are supported. You can configure the specific time for the merge task schedule in Custom Merge Time. | ||||||||||||
Merge Primary Key | You can define the primary key by selecting one or more columns from the table.
|
 icon and combining values from Manual Input and Built-in Variable. Supported variables include the source data source name, source database name, and source table name.
icon and combining values from Manual Input and Built-in Variable. Supported variables include the source data source name, source database name, and source table name.


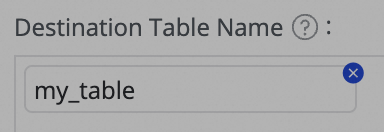

 icon in the Destination Table Name column to add a field.
icon in the Destination Table Name column to add a field.6. Configure DDL capabilities
Certain real-time synchronization tasks detect metadata changes in the source table structure and synchronize updates or take other actions such as alerting, ignoring, or terminating execution.
Click Configure DDL Capability in the upper-right corner of the interface to set processing policies for each change type. Supported policies vary by channel.
Normal Processing: The destination processes the DDL change information from the source.
Ignore: The change message is ignored, and no modification is made at the destination.
Error: The whole database real-time synchronization task is terminated, and the status is set to Error.
Alert: An alert is sent to the user when such a change occurs at the source. You must configure DDL notification rules in Configure Alert Rule.
When DDL synchronization adds a source column to the destination, existing records are not backfilled with data for the new column.
7. Advanced configuration parameters
If you need to fine-tune the task to meet custom synchronization requirements, click Configure in the Custom Advanced Parameters column to modify advanced parameters.
Click Advanced Parameter Settings in the upper-right corner of the page.
Modify the parameter values based on the descriptions provided for each parameter.
Modify these parameters only if you fully understand their purpose. Incorrect settings can cause unforeseen issues, such as task delays, excessive resource consumption that blocks other tasks, or data loss.
8. Run the synchronization task
After the configuration of the synchronization task is complete, click Complete in the lower part of the page.
In the Synchronization Task section of the Data Integration page, find the created synchronization task and click Start in the Operation column.
Click the Name/ID of the synchronization task in the Tasks section and view the detailed running process of the synchronization task.
Next steps
After you configure the task, you can manage it, add or remove tables, configure monitoring and alerts, and view key performance metrics. For more information, see Manage a synchronization task.
FAQ
Q: Why is the data in the Base table not updated as expected?
A: This can happen for several reasons. See the table below for common causes and solutions.

Symptom | Cause | Solution |
The check for data generation in the T-1 partition of the incremental log table fails. | The real-time synchronization task ran abnormally, so data for the T-1 partition of the incremental log table was not generated as expected. |
|
The check for data generation in the T-2 partition of the destination Base table fails. |
|
|