Kafka is a distributed message queue service that features high throughput and high scalability. Kafka is widely used for big data analytics such as log collection, monitoring data aggregation, streaming processing, and online and offline analysis. Kafka is an essential service for the big data ecosystem. This topic describes how to synchronize data from a self-managed MySQL database hosted on Elastic Compute Service (ECS) to a self-managed Kafka cluster by using Data Transmission Service (DTS). The data synchronization feature allows you to extend message processing capabilities.
Prerequisites
- A Kafka cluster is created and the Kafka version is 0.10.1.0 to 2.7.0.
- An ApsaraDB RDS for MySQL instance is created. For more information, see Create an ApsaraDB RDS for MySQL instance.
Usage notes
- DTS uses read and write resources of the source and destination databases during initial full data synchronization. This may increase the loads of the database servers. If the database performance or specifications are unfavorable, or the data volume is large, database services may become unavailable. For example, DTS occupies a large amount of read and write resources in the following cases: a large number of slow SQL queries are performed on the source database, the tables have no primary keys, or a deadlock occurs in the destination database. Before you synchronize data, evaluate the impact of data synchronization on the performance of the source and destination databases. We recommend that you synchronize data during off-peak hours. For example, you can synchronize data when the CPU utilization of the source and destination databases is less than 30%.
- The source database must have PRIMARY KEY or UNIQUE constraints and all fields must be unique. Otherwise, the destination database may contain duplicate data records.
Billing
| Synchronization type | Task configuration fee |
|---|---|
| Schema synchronization and full data synchronization | Free of charge. |
| Incremental data synchronization | Charged. For more information, see Billing overview. |
Limits
- Only tables can be selected as the objects to synchronize.
- DTS does not synchronize the data in a renamed table to the destination Kafka cluster. This applies if the new table name is not included in the objects to be synchronized. If you want to synchronize the data in a renamed table to the destination Kafka cluster, you must reselect the objects to be synchronized. For more information, see Add an object to a data synchronization task.
Supported synchronization topologies
- One-way one-to-one synchronization
- One-way one-to-many synchronization
- One-way many-to-one synchronization
- One-way cascade synchronization
Preparations
Before you configure the data synchronization task, you must create a database account and configure binary logging. For more information, see Create an account for a self-managed MySQL database and configure binary logging.
Procedure
- Purchase a data synchronization instance. For more information, see Purchase a DTS instance. Note On the buy page, set Source Instance to MySQL, Destination Instance to Kafka, and Synchronization Topology to One-Way Synchronization.
- Log on to the DTS console. Note If the Data Management (DMS) console appears instead of the DTS console, you can move the pointer over the
 icon and click the
icon and click the  icon to return to the DTS console.
icon to return to the DTS console. - In the left-side navigation pane, click Data Synchronization.
- In the upper part of the Data Synchronization Tasks page, select the region in which the destination instance resides.
- Find the data synchronization instance and click Configure Task in the Actions column.
- Configure the source database and destination cluster.
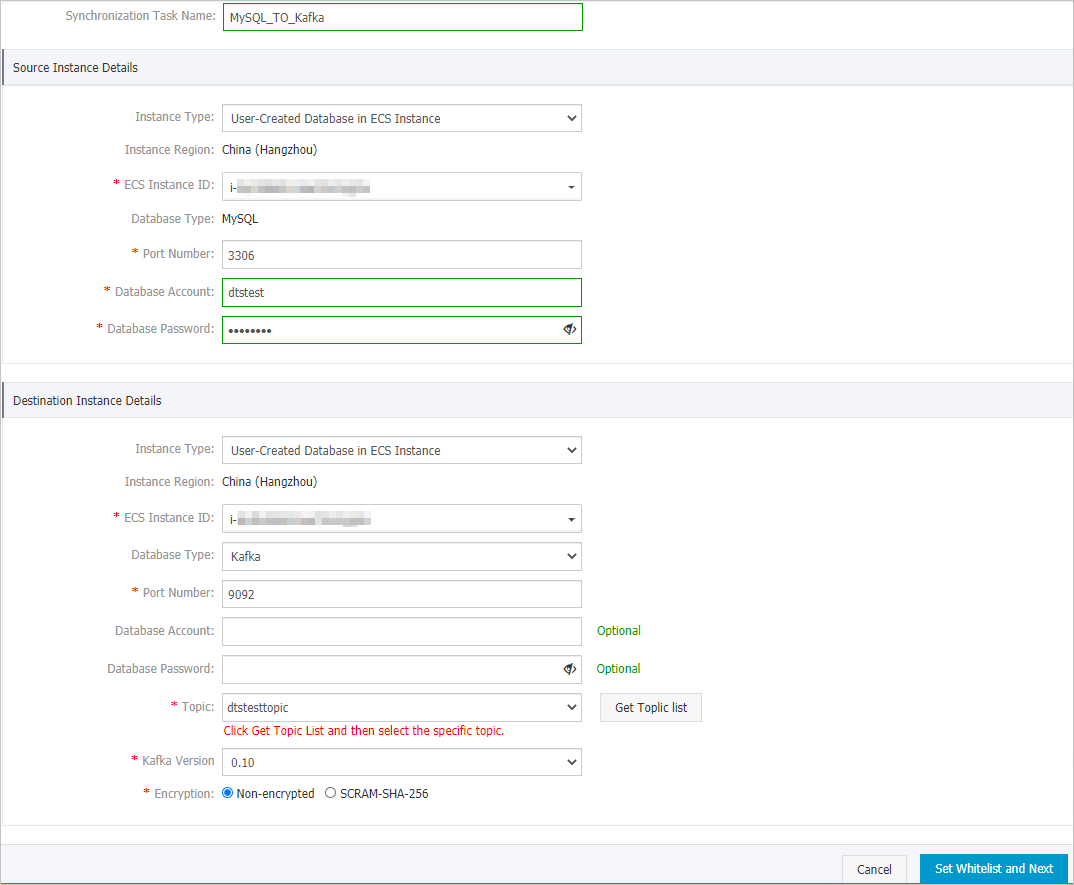
Section Parameter Description None Synchronization Task Name The task name that DTS automatically generates. We recommend that you specify a descriptive name that makes it easy to identify the task. You do not need to use a unique task name. Source Instance Details Instance Type The type of the source database. Select User-Created Database in ECS Instance. Instance Region The source region that you selected on the buy page. You cannot change the value of this parameter. ECS Instance ID The ID of the ECS instance that hosts the source MySQL database. Database Type The database type of the source database. This parameter is set to MySQL and cannot be changed. Port Number The service port number of the self-managed MySQL database. Default Value: 3306. Database Account Enter the account of the self-managed MySQL database. The account must have the SELECT permission on the required objects, the REPLICATION CLIENT permission, the REPLICATION SLAVE permission, and the SHOW VIEW permission. Database Password The password of the database account. Destination Instance Details Instance Type The instance type of the Kafka cluster. In this example, User-Created Database in ECS Instance is selected for this parameter. Note If you select other instance types, you must deploy the network environment for the Kafka cluster. For more information, see Preparation overview.Instance Region The destination region that you selected on the buy page. The value of this parameter cannot be changed. ECS Instance ID The ID of the ECS instance on which the Kafka cluster is deployed. Database Type The type of the destination cluster. Select Kafka. Port Number The service port number of the Kafka cluster. Default value: 9092. Database Account The username that is used to log on to the Kafka cluster. If no authentication is enabled for the Kafka cluster, you do not need to enter the username. Database Password The password that corresponds to the username. If no authentication is enabled for the Kafka cluster, you do not need to enter the password. Topic Click Get Topic List and select a topic name from the drop-down list. Kafka Version The version of the destination Kafka cluster. Encryption Specifies whether to encrypt the connection to the destination cluster. Select Non-encrypted or SCRAM-SHA-256 based on your business and security requirements. - In the lower-right corner of the page, click Set Whitelist and Next. Note
- You do not need to modify the security settings for ApsaraDB instances (such as ApsaraDB RDS for MySQL and ApsaraDB for MongoDB) and ECS-hosted databases. DTS automatically adds the CIDR blocks of DTS servers to the whitelists of ApsaraDB instances or the security group rules of Elastic Compute Service (ECS) instances. For more information, see Add the CIDR blocks of DTS servers to the security settings of on-premises databases.
- After data synchronization is complete, we recommend that you remove the CIDR blocks of DTS servers from the whitelists or security groups.
- Select the objects to be synchronized.
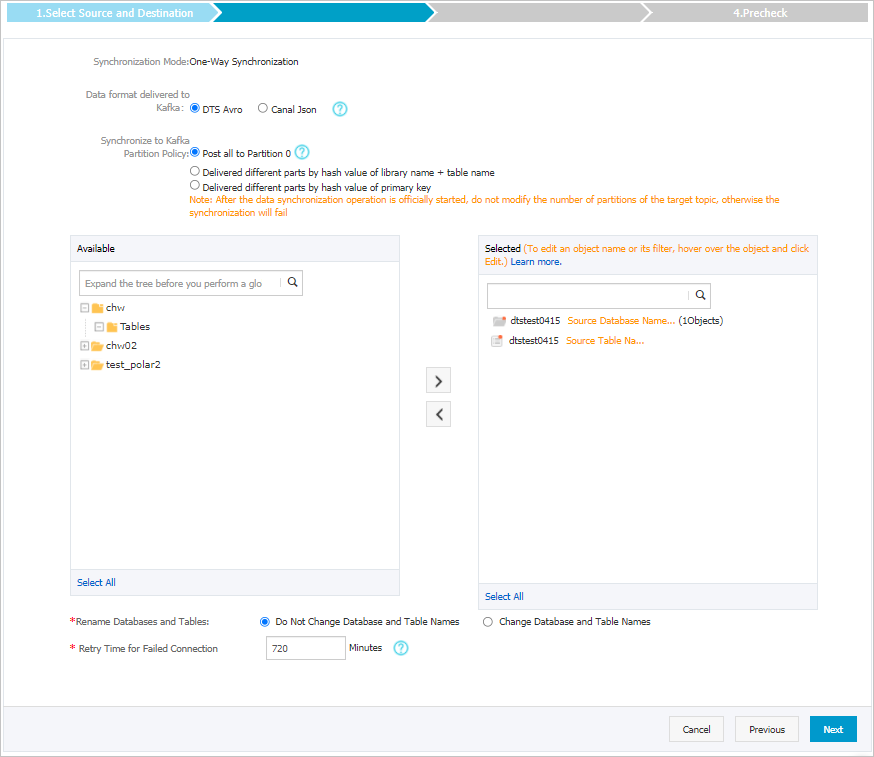
Parameter Description Data Format in Kafka The data that is synchronized to the Kafka cluster is stored in the Avro or Canal JSON format. For more information, see Data formats of a Kafka cluster. Policy for Shipping Data to Kafka Partitions The policy used to synchronize data to Kafka partitions. Select a policy based on your business requirements. For more information, see Specify the policy for synchronizing data to Kafka partitions. Objects to be synchronized Select one or more tables from the Available section and click the  icon to add the tables to the Selected section. Note DTS maps the table names to the topic name that you select in Step 6. You can use the table name mapping feature to change the topics that are synchronized to the destination cluster. For more information, see Rename an object to be synchronized.
icon to add the tables to the Selected section. Note DTS maps the table names to the topic name that you select in Step 6. You can use the table name mapping feature to change the topics that are synchronized to the destination cluster. For more information, see Rename an object to be synchronized.Rename Databases and Tables You can use the object name mapping feature to rename the objects that are synchronized to the destination instance. For more information, see Object name mapping.
Retry Time for Failed Connections By default, if DTS fails to connect to the source or destination database, DTS retries within the next 720 minutes (12 hours). You can specify the retry time based on your needs. If DTS reconnects to the source and destination databases within the specified time, DTS resumes the data synchronization task. Otherwise, the data synchronization task fails.Note When DTS retries a connection, you are charged for the DTS instance. We recommend that you specify the retry time based on your business needs. You can also release the DTS instance at your earliest opportunity after the source and destination instances are released. - In the lower-right corner of the page, click Next.
- Configure initial synchronization.

Parameter Description Initial Synchronization Select both Initial Schema Synchronization and Initial Full Data Synchronization. DTS synchronizes the schemas and historical data of the required objects and then synchronizes incremental data. Filter options Ignore DDL in incremental synchronization phase is selected by default. In this case, DTS does not synchronize DDL operations that are performed on the source database during incremental data synchronization. - In the lower-right corner of the page, click Precheck. Note
- Before you can start the data synchronization task, DTS performs a precheck. You can start the data synchronization task only after the task passes the precheck.
- If the task fails to pass the precheck, click the
 icon next to each failed item to view details.
icon next to each failed item to view details. - After you troubleshoot the issues based on the causes, run a precheck again.
- If you do not need to troubleshoot the issues, ignore failed items and run a precheck again.
- Close the Precheck dialog box after the following message is displayed: Precheck Passed. Then, the data synchronization task starts. You can view the status of the data synchronization task on the Data Synchronization page.
