When a service version becomes unavailable, requests to that version return HTTP 503 errors. Fallback routing solves this by automatically redirecting requests to an alternative service version at the proxy level. Service Mesh (ASM) extends the Istio VirtualService resource with a fallback field that defines this alternative route.
This topic walks through fallback routing using the Bookinfo sample application. You will:
Route all traffic to a specific service version
Define a fallback target that receives traffic when the primary version is unreachable
Combine fallback with weighted routing for advanced scenarios
Verify fallback behavior through custom access logs
How fallback differs from retries and circuit breakers
ASM provides several resilience mechanisms. Choose the right one based on the failure mode you need to handle:
| Mechanism | Failure mode | Behavior | When to use |
|---|---|---|---|
| Fallback | All endpoints in a subset are unreachable | Redirects to an alternative subset | A backup version or deployment can serve requests |
| Retries | Transient errors (timeouts, 5xx) | Resends the request to the same subset | Errors are intermittent and likely to succeed on retry |
| Circuit breaker | Sustained high error rate | Stops sending traffic to unhealthy endpoints | Protect downstream services from cascading failures |
Fallback operates at the routing level: the sidecar proxy checks whether the target subset has healthy endpoints before forwarding the request. If no healthy endpoints exist, it routes to the fallback target instead.
Prerequisites
| Requirement | Details |
|---|---|
| ASM instance | Enterprise Edition or Ultimate Edition, version 1.17.2.22 or later |
| Kubernetes cluster | A Container Service for Kubernetes (ACK) cluster added to the ASM instance. See Add a cluster to an ASM instance. |
| Sample application | Bookinfo deployed in the cluster. See Deploy an application in an ASM instance. |
| Sidecar proxy version | 1.17 or later on all data plane pods |
If your ASM instance version is earlier than 1.17, update it to 1.17.2.22 or later. See Update an ASM instance. Alternatively, submit a ticket for technical support.
Check the sidecar proxy version for each pod on the Instances Status page in the ASM console. See Upgrade management.
Bookinfo reviews service versions
The Bookinfo reviews service has three versions, each identifiable by its star rating on the product page:
| Version | Star rating |
|---|---|
| v1 | No stars |
| v2 | Black stars |
| v3 | Red stars |
The productpage service calls reviews. A VirtualService routes all traffic to reviews-v3. When v3 becomes unavailable, the fallback rule redirects requests to reviews-v2 instead of returning a 503 error.
Download the configuration files used in this topic.
Step 1: Create the destination rule for the reviews service
Define a DestinationRule with subsets for each version of the reviews service.
Create a file named
reviews.yamlwith the following content:apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: reviews spec: host: reviews subsets: - name: v1 labels: version: v1 - name: v2 labels: version: v2 - name: v3 labels: version: v3Connect to the ASM instance using kubectl and the KubeConfig file, then apply the rule:
kubectl apply -f reviews.yamlGet the ingress gateway IP address using either method:
Run the following command:
kubectl get svc -n istio-system istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].ip}'Find the IP on the Ingress Gateway page in the ASM console. See Query the IP address of the ASM instance's ingress gateway.
Open
http://<gateway-ip>/productpagein a browser. The Reviews served by field and the star rating identify the version serving each request. Refresh the page several times -- requests are distributed across v1, v2, and v3. For example,reviews-v2displays black stars: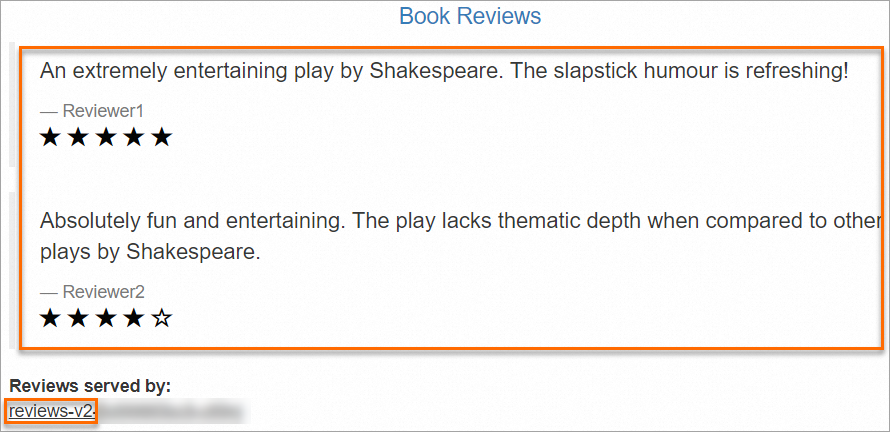
Step 2: Configure a basic fallback rule
Route all traffic to reviews-v3 and set reviews-v2 as the fallback target.
Create a file named
reviews-route-fallback-sample1.yaml: Thefallback.targetfield tells the sidecar proxy to forward requests toreviews-v2whenreviews-v3is unreachable.apiVersion: networking.istio.io/v1beta1 kind: VirtualService metadata: name: reviews-route namespace: default spec: hosts: - reviews http: - route: - destination: host: reviews subset: v3 fallback: target: host: reviews subset: v2Apply the VirtualService:
kubectl apply -f reviews-route-fallback-sample1.yamlOpen
http://<gateway-ip>/productpageand refresh. All requests now route to v3 (red stars).
Simulate a v3 failure by scaling its deployment to zero replicas:
kubectl scale deployment reviews-v3 --replicas=0Refresh the page. Requests now fall back to v2 (black stars).
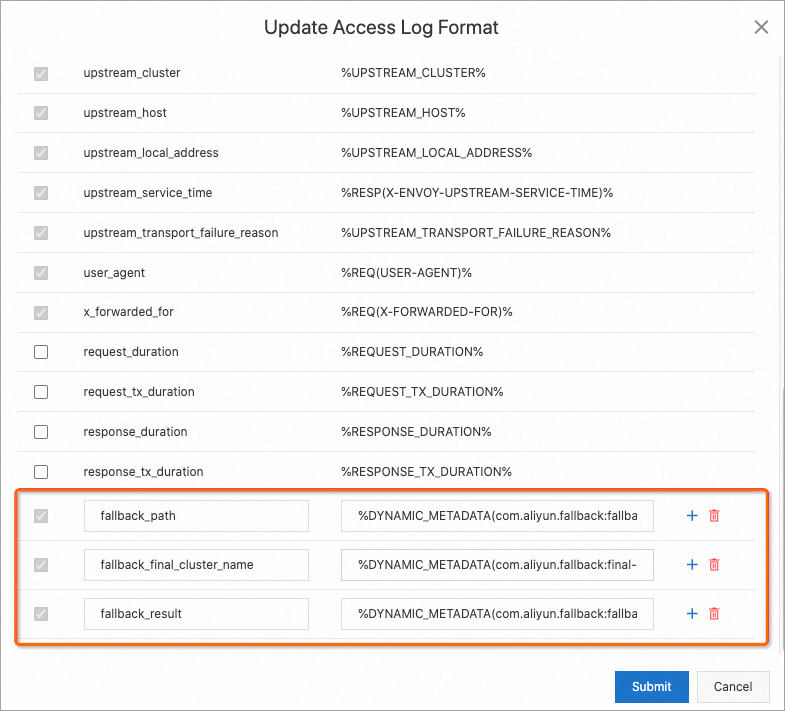
Add fallback-related fields to the custom access log format to confirm the fallback triggered. See Customize access log fields for setup instructions.
| Field | Value | Description |
|---|---|---|
fallback_path | %DYNAMIC_METADATA(com.aliyun.fallback:fallback-path)% | Fallback chain. A:B means A fell back to B. A:B:C means A fell back to B, then B to C. |
fallback_final_cluster_name | %DYNAMIC_METADATA(com.aliyun.fallback:final-cluster)% | Cluster that ultimately handled the request after a successful fallback. |
fallback_result | %DYNAMIC_METADATA(com.aliyun.fallback:fallback-result)% | Fallback outcome. If the fallback failed, the request goes to the original route's cluster. |
Check the productpage-v1 istio-proxy logs. A successful fallback from v3 to v2 produces a log entry similar to the following:
{
"authority": "reviews:9080",
"authority_for": "reviews:9080",
"bytes_received": "0",
"bytes_sent": "442",
"downstream_local_address": "192.168.255.46:9080",
"downstream_remote_address": "172.16.0.252:57238",
"duration": "10",
"fallback_path": "outbound|9080|v3|reviews.default.svc.cluster.local:outbound|9080|v2|reviews.default.svc.cluster.local",
"fallback_final_cluster_name": "outbound|9080|v2|reviews.default.svc.cluster.local",
"fallback_result": "fallback successful",
"istio_policy_status": "-",
"method": "GET",
"path": "/reviews/0",
"protocol": "HTTP/1.1",
"request_id": "15b2dffc-5f3f-4060-b9fa-898eab08****",
"requested_server_name": "-",
"response_code": "200",
"response_flags": "-",
"route_name": "-",
"start_time": "2023-05-30T07:02:26.990Z",
"trace_id": "18b3aed8af41****",
"upstream_cluster": "outbound|9080|v2|reviews.default.svc.cluster.local",
"upstream_host": "172.16.0.11:9080",
"upstream_local_address": "172.16.0.252:44448",
"upstream_service_time": "9",
"upstream_transport_failure_reason": "-",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.X.X Safari/537.36",
"x_forwarded_for": "-"
}The three fallback-specific fields confirm the behavior:
fallback_pathshows the chain: v3 cluster to v2 cluster.fallback_final_cluster_nameidentifies v2 as the cluster that served the request.fallback_resultis"fallback successful".
Step 3: Combine fallback with weighted routing
Fallback rules work alongside weighted routing. In this scenario, traffic splits 50/50 between v3 and v2, and each version has its own fallback target.
Restore v3:
kubectl scale deployment reviews-v3 --replicas=1Create a file named
reviews-route-fallback-sample2.yaml: Two independent fallback chains are defined: Retries are disabled (attempts: 0) to isolate fallback behavior from retry behavior during testing.v3 traffic (50%): falls back to v2 if v3 is unavailable
v2 traffic (50%): falls back to v1 if v2 is unavailable
apiVersion: networking.istio.io/v1beta1 kind: VirtualService metadata: name: reviews-route namespace: default spec: hosts: - reviews http: - route: - destination: host: reviews subset: v3 fallback: target: host: reviews subset: v2 weight: 50 - destination: host: reviews subset: v2 fallback: target: host: reviews subset: v1 weight: 50 retries: attempts: 0Apply the updated VirtualService:
kubectl apply -f reviews-route-fallback-sample2.yamlRefresh the product page. Requests are distributed evenly between v3 (red stars) and v2 (black stars).
Test fallback when v3 is down
Scale v3 to zero: Refresh the page. All requests now reach v2: the 50% originally targeted at v3 falls back to v2, and the other 50% routes to v2 directly.
kubectl scale deployment reviews-v3 --replicas=0
Test fallback when both v3 and v2 are down
Scale v2 to zero: Refresh the page. Two behaviors alternate:
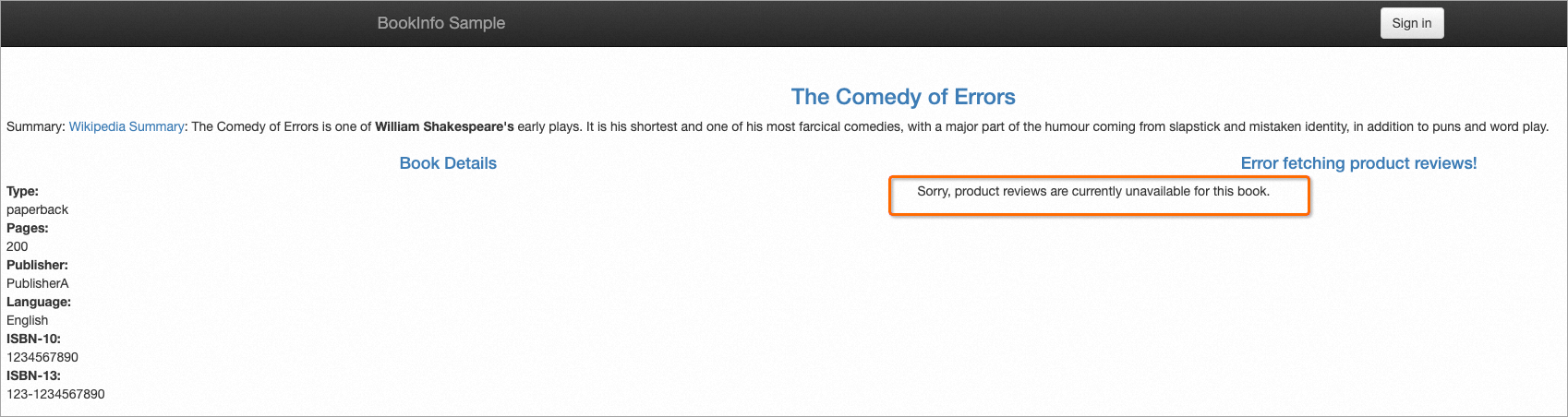
50% of requests succeed: These are requests originally routed to v2, which fall back to v1 (no stars).
50% of requests fail with a 503 error: These are requests originally routed to v3. The proxy attempts to fall back to v2, but v2 is also down, so the fallback chain does not extend to v1.
kubectl scale deployment reviews-v2 --replicas=0Confirm this in the logs: A failed fallback produces a log entry like the following: Key fields in the failed fallback log:
response_code:503indicates the request was not served.response_flags:UH(Upstream Host Unhealthy).fallback_result:"fallback cluster is unhealthy"indicates the fallback target (v2) was also unavailable.upstream_cluster: still shows the v3 cluster, confirming the original routing destination.
kubectl logs -f deployment/productpage-v1 -c istio-proxy --tail=10{ "authority": "reviews:9080", "authority_for": "reviews:9080", "bytes_received": "0", "bytes_sent": "19", "downstream_local_address": "192.168.255.46:9080", "downstream_remote_address": "172.16.0.252:47738", "duration": "0", "fallback_path": "outbound|9080|v3|reviews.default.svc.cluster.local:outbound|9080|v2|reviews.default.svc.cluster.local", "fallback_final_cluster_name": "-", "fallback_result": "fallback cluster is unhealthy", "istio_policy_status": "-", "method": "GET", "path": "/reviews/0", "protocol": "HTTP/1.1", "request_id": "b207a764-b6d7-4ef8-bc71-59f264c3****", "requested_server_name": "-", "response_code": "503", "response_flags": "UH", "route_name": "-", "start_time": "2023-05-30T07:32:08.999Z", "trace_id": "a40c32a7b2cf****", "upstream_cluster": "outbound|9080|v3|reviews.default.svc.cluster.local", "upstream_host": "-", "upstream_local_address": "-", "upstream_service_time": "-", "upstream_transport_failure_reason": "-", "user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.X.X Safari/537.36", "x_forwarded_for": "-" }
Use fallback in production
Fallback routing masks service failures, which is valuable for availability but requires careful planning in production environments.
Monitor fallback frequency
A sustained high fallback rate indicates an underlying issue with the primary service version. Set up alerts on the fallback_result access log field to detect when fallback triggers repeatedly, rather than relying on it as a silent failover.
Capacity planning
When fallback triggers, the fallback target receives additional traffic beyond its normal load. Make sure the fallback service version has enough capacity to handle both its regular traffic and redirected traffic. In the weighted routing scenario from Step 3, v2 must handle up to 100% of total traffic if v3 goes down.
Fallback chain depth
Fallback does not cascade across multiple hops automatically. In the weighted routing example, when v3 falls back to v2 and v2 is also down, the request fails with a 503 -- it does not continue to v1. Each route entry maintains its own independent fallback target. Plan your fallback chains accordingly.