By integrating with Alibaba Cloud's Managed Service for Prometheus and Grafana for metric storage and visualization, Message Queue for Apache RocketMQ provides a Dashboard feature. The Dashboard offers a centralized and comprehensive view of metrics to help you quickly assess your service's operational status. This topic describes the Dashboard's use cases, background, metrics, billing, and query methods.
Use cases
Scenario 1: Use timely alerts to detect and troubleshoot message consumption exceptions in real time.
Scenario 2: Verify message sending status by investigating the delivery path when order statuses are abnormal.
Scenario 3: Analyze message traffic trends, distribution patterns, and volume to plan for future business growth.
Scenario 4: View and analyze application dependency topologies to optimize or refactor your architecture.
Background
In the message lifecycle of Message Queue for Apache RocketMQ, key performance indicators such as consumer lag, buffering, and processing latency directly reflect your application's performance and the broker's health. Therefore, the key metrics for Message Queue for Apache RocketMQ are most relevant in the following scenarios.
Message backlog
The following figure shows the status of messages in a specific queue of a topic.
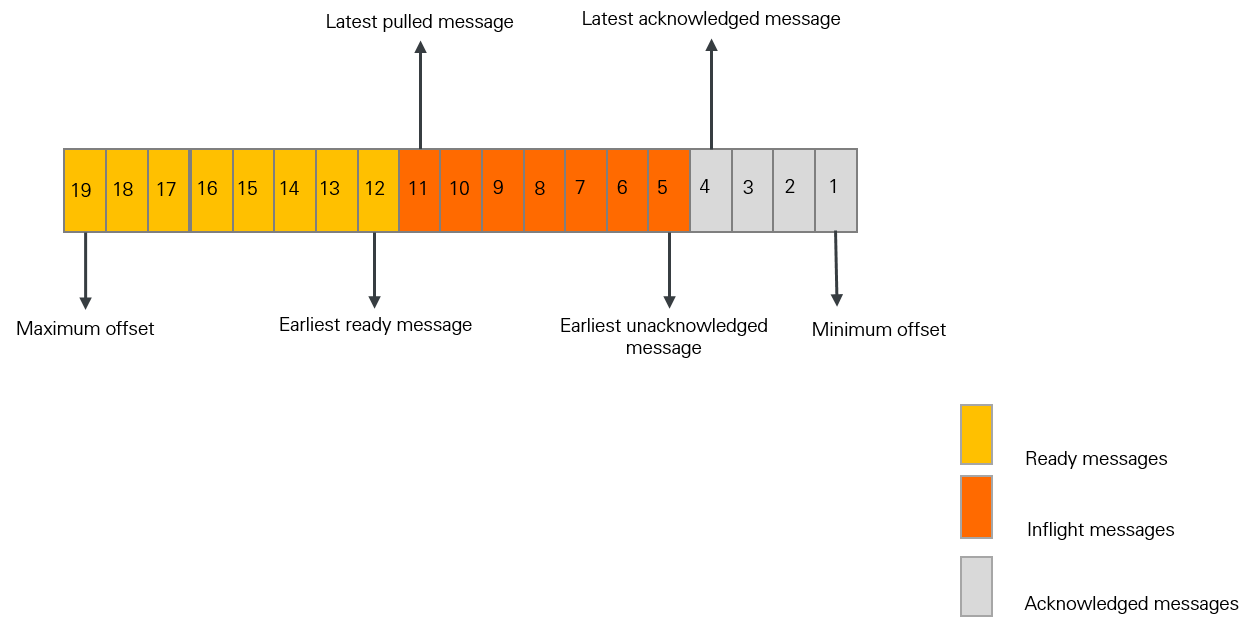
The preceding figure shows the status of messages in a specific queue of a given topic. Message Queue for Apache RocketMQ collects statistics on the number of messages and the time taken at different processing stages. These metrics directly reflect the message processing rate and accumulation in the queue. By observing these metrics, you can preliminarily determine whether your service consumption is abnormal. The specific metric definitions and calculation formulas are as follows:
Category | Metric | Description | Calculation formula |
Message count metrics | inflight messages | The number of messages that a consumer client is processing but has not yet acknowledged. | Offset of the latest pulled message - Offset of the latest acknowledged message |
ready messages | The number of messages on the Message Queue for Apache RocketMQ broker that are ready for consumption. | Maximum message offset - Offset of the latest pulled message | |
consumer lag | The total number of messages awaiting consumption or currently being processed. | Number of inflight messages + Number of ready messages | |
Message latency metrics | Ready time |
| N/A |
Ready message queuing time | The time elapsed from the ready time of the oldest ready message to the present. This metric reflects the timeliness of message pulling by consumers. | Current time - Ready time of the oldest ready message | |
consumer lag time | The time elapsed from the ready time of the earliest unacknowledged message to the present. This metric reflects the timeliness of message processing by consumers. | Current time - Ready time of the earliest unacknowledged message |
PushConsumer consumption
The PushConsumer SDK uses a Reactor thread model to handle real-time message processing. The SDK uses a long-polling thread to asynchronously pull messages into an internal cache queue. These messages are then submitted to consumer threads, which trigger a listener to execute the local consumption logic.
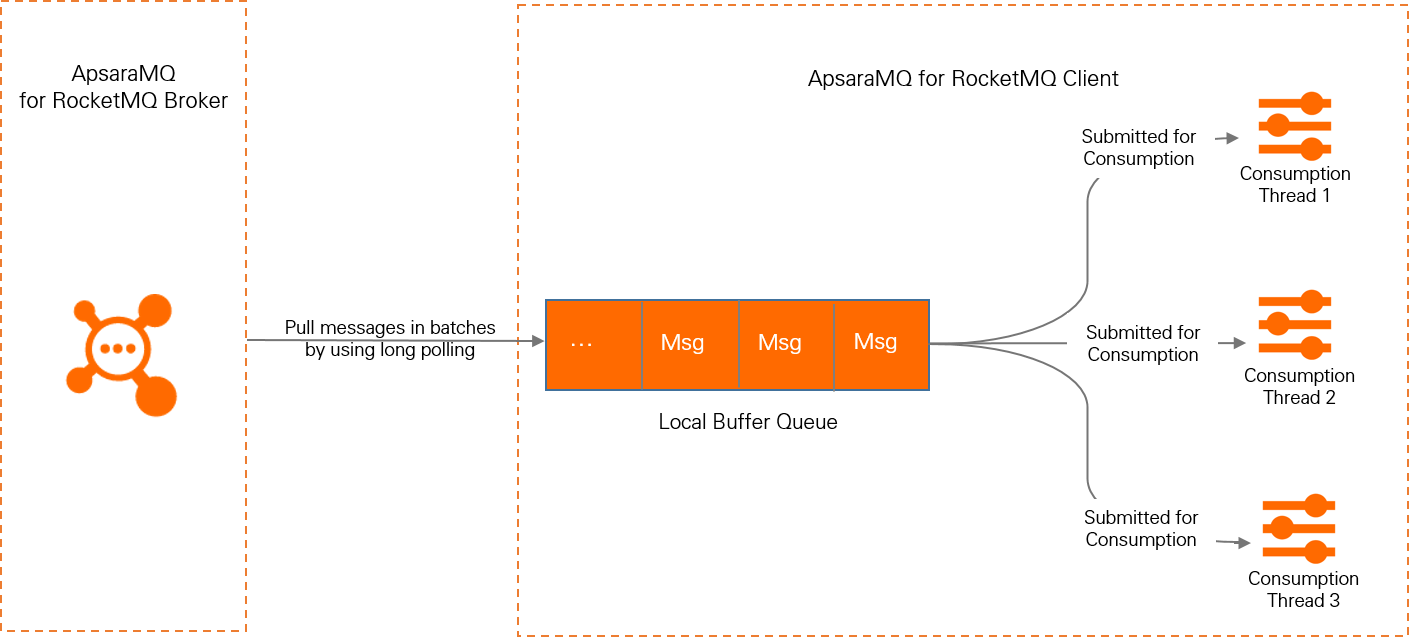
For more information about how it works, see PushConsumer.
In the PushConsumer consumption scenario, the following metrics are related to the local cache queue:
Number of messages in the local cache queue: The total number of messages in the local cache queue.
Size of messages in the local cache queue: The total size of all messages in the local cache queue.
Message wait time: The duration that messages are temporarily stored in the local cache queue.
Metric details
All metrics related to TPS, message sends and receives, or message counts are calculated based on a 4 KB normal message. Multipliers for message size and advanced message types are applied. For more information, see Calculation specifications.
The following table describes the metric fields.
Field | Value |
Metric type |
|
Label |
|
Broker metrics
Metric type | Metric name | Unit | Description | Labels |
Gauge | rocketmq_instance_requests_max | count/s | The maximum messaging TPS (sends and receives) for the instance per minute. Throttled requests are excluded. This value is the maximum of 60 TPS samples taken once per second over a one-minute interval. |
|
Gauge | rocketmq_instance_requests_in_max | count/s | The maximum message sending TPS for the instance per minute. Throttled requests are excluded. This value is the maximum of 60 TPS samples taken once per second over a one-minute interval. |
|
Gauge | rocketmq_instance_requests_out_max | count/s | The maximum message consumption TPS for the instance per minute. Throttled requests are excluded. This value is the maximum of 60 TPS samples taken once per second over a one-minute interval. |
|
Gauge | rocketmq_topic_requests_max | count/s | The maximum TPS for sending messages to a topic in the instance per minute. Throttled requests are excluded. This value is the maximum of 60 TPS samples taken once per second over a one-minute interval. |
|
Gauge | rocketmq_group_requests_max | count/s | The maximum message consumption TPS for a consumer group in the instance per minute. Throttled requests are excluded. This value is the maximum of 60 TPS samples taken once per second over a one-minute interval. |
|
Gauge | rocketmq_instance_requests_in_threshold | count/s | The throttling threshold for message sending in the instance. |
|
Gauge | rocketmq_instance_requests_out_threshold | count/s | The throttling threshold for message consumption in the instance. |
|
Gauge | rocketmq_throttled_requests_in | count | The number of throttled message sending attempts. |
|
Gauge | rocketmq_throttled_requests_out | count | The number of throttled message consumption attempts. |
|
Gauge | rocketmq_instance_elastic_requests_max | count/s | The maximum elastic TPS for message sending and consumption in the instance. |
|
Counter | rocketmq_requests_in_total | count | The total number of API calls for message sending. |
|
Counter | rocketmq_requests_out_total | count | The total number of API calls for message consumption. |
|
Counter | rocketmq_messages_in_total | message | The total number of messages sent from producers to the broker. |
|
Counter | rocketmq_messages_out_total | message | The total number of messages delivered from the broker to consumers. This includes messages that are being processed, were successfully processed, or whose processing failed. |
|
Counter | rocketmq_throughput_in_total | byte | The message throughput from producers to the broker. |
|
Counter | rocketmq_throughput_out_total | byte | The message throughput from the broker to consumers. This includes messages that are being processed, were successfully processed, or whose processing failed. |
|
Counter | rocketmq_internet_throughput_out_total | byte | The outbound internet traffic used for messaging. |
|
Histogram | rocketmq_message_size | byte | A histogram of message sizes, recorded upon successful sending. Distribution buckets:
|
|
Gauge | rocketmq_consumer_ready_messages | message | The number of messages on the broker that are ready for consumption. This metric reflects the number of messages that have not yet been processed by consumers. |
|
Gauge | rocketmq_consumer_inflight_messages | message | The number of inflight messages, which are messages that consumer clients are processing but have not yet acknowledged. |
|
Gauge | rocketmq_consumer_queueing_latency | ms | The queueing time of ready messages, calculated as the duration from the ready time of the oldest ready message to the present. This metric indicates the timeliness of message pulling by consumers. |
|
Gauge | rocketmq_consumer_lag_latency | ms | The consumption processing latency, calculated as the duration from the ready time of the oldest unconsumed message to the present. This metric indicates the timeliness of message processing by consumers. |
|
Counter | rocketmq_send_to_dlq_messages | message | The number of messages that become dead letters per minute. A message becomes a dead letter after it fails delivery and exceeds the maximum number of redelivery attempts. These messages are then either discarded or routed to a dead-letter topic based on the consumer group's dead-letter policy. |
|
Gauge | rocketmq_storage_size | byte | The amount of storage space used by the instance, including all files. |
|
Producer metrics
Metric type | Metric name | Unit | Description | Labels |
Histogram | rocketmq_send_cost_time | ms | A histogram of the latency of successful message sending API calls. Distribution buckets:
|
|
Consumer metrics
Metric type | Metric name | Unit | Description | Labels |
Histogram | rocketmq_process_time | ms | A histogram of the message processing time for a PushConsumer, including both successful and failed attempts. This value is calculated as: Distribution buckets:
|
|
Gauge | rocketmq_consumer_cached_messages | message | The number of messages in the local cache queue of a PushConsumer. |
|
Gauge | rocketmq_consumer_cached_bytes | byte | The total size of messages in the local cache queue of a PushConsumer. |
|
Histogram | rocketmq_await_time | ms | A histogram of the message wait time in the local cache queue of a PushConsumer. This value is calculated as: Distribution buckets:
|
|
Billing
The dashboard metrics for Message Queue for Apache RocketMQ are basic metrics in Managed Service for Prometheus. Basic metrics are free of charge. Therefore, the dashboard feature is also free of charge.
For more information, see Pay-as-you-go.
Prerequisites
A service-linked role must be created.
Role name: AliyunServiceRoleForOns
Role policy name: AliyunServiceRolePolicyForOns
Permissions: Allows Message Queue for Apache RocketMQ to assume this role to access other Alibaba Cloud services, such as CloudMonitor and Managed Service for Prometheus, to enable features such as monitoring, alerting, and the Dashboard.
For more information, see Service-linked roles.
View the Dashboard
You can view the Dashboard on the following pages in the Message Queue for Apache RocketMQ console:
Dashboard page: displays metrics for all topics and consumer groups in an instance.
Instance Details page: displays a producer overview, billing metrics, and throttling metrics for a specific instance.
Topic Details page: displays metrics related to message production and producer clients for a specific topic.
Group Details page: displays metrics related to consumer lag and consumer clients for a specific consumer group.
Log on to the ApsaraMQ for RocketMQ console. In the left-side navigation pane, click Instances.
In the top navigation bar, select a region, such as China (Hangzhou). On the Instances page, click the name of the instance that you want to manage.
Use one of the following methods to view the Dashboard.
Instance Details page: On the Instance Details page, click the Dashboard tab.
Dashboard page: In the left-side navigation pane, click Dashboard.
Topic Details page: In the left-side navigation pane, click Topics. In the topic list, click the name of the target topic. On the Topic Details page, click the Dashboard tab.
Group Details page: In the left-side navigation pane, click Groups. In the group list, click the name of the target group. On the Group Details page, click the Dashboard tab.
FAQ
How to get dashboard metric data?
Log on to the ARMS console by using your Alibaba Cloud account.
In the left-side navigation pane, click Integration Center.
On the Integration Center page, enter
RocketMQin the search box and click the search icon.In the search results, select the cloud service that you want to integrate, such as Aliyun RocketMQ (5.0) Service. For more information about the integration, see Step 1: Integrate the monitoring data of the cloud service.
After the integration is successful, click Integration Management in the left-side navigation pane.
On the Integration Management page, click the Cloud Service Region Environment tab.
In the Cloud Service Region Environment list, click the name of the target environment to open its details page.
In the Basic Information section of the Component Management tab, click the cloud service region next to Prometheus instance.
On the Settings tab, you can obtain the URLs for different data access methods.
How to integrate with self-managed Grafana?
All metric data for Message Queue for Apache RocketMQ is saved in your Alibaba Cloud Managed Service for Prometheus. You can follow the steps in How do I obtain dashboard metric data? to connect to the cloud service and obtain an environment name and HTTP API address. Then, you can use the API to import the dashboard metric data for Message Queue for Apache RocketMQ into your self-managed Grafana instance. For more information, see Use an HTTP API address to connect to Grafana or a self-managed application to access Prometheus data.
How to interpret instance max TPS?
Max TPS is the highest transactions per second (TPS) value recorded over a one-minute period, based on samples taken every second.
Example:
An instance produces 60 normal messages, each 4 KB in size, within one minute. The production rate is 60 messages/minute.
If all 60 messages are sent in the first second, the TPS values for each second in that minute are 60, 0, 0, ..., 0.
The instance's max TPS is 60.
If 40 messages are sent in the first second and 20 are sent in the second second, the TPS values are 40, 20, 0, 0, ..., 0.
The instance's max TPS is 40.