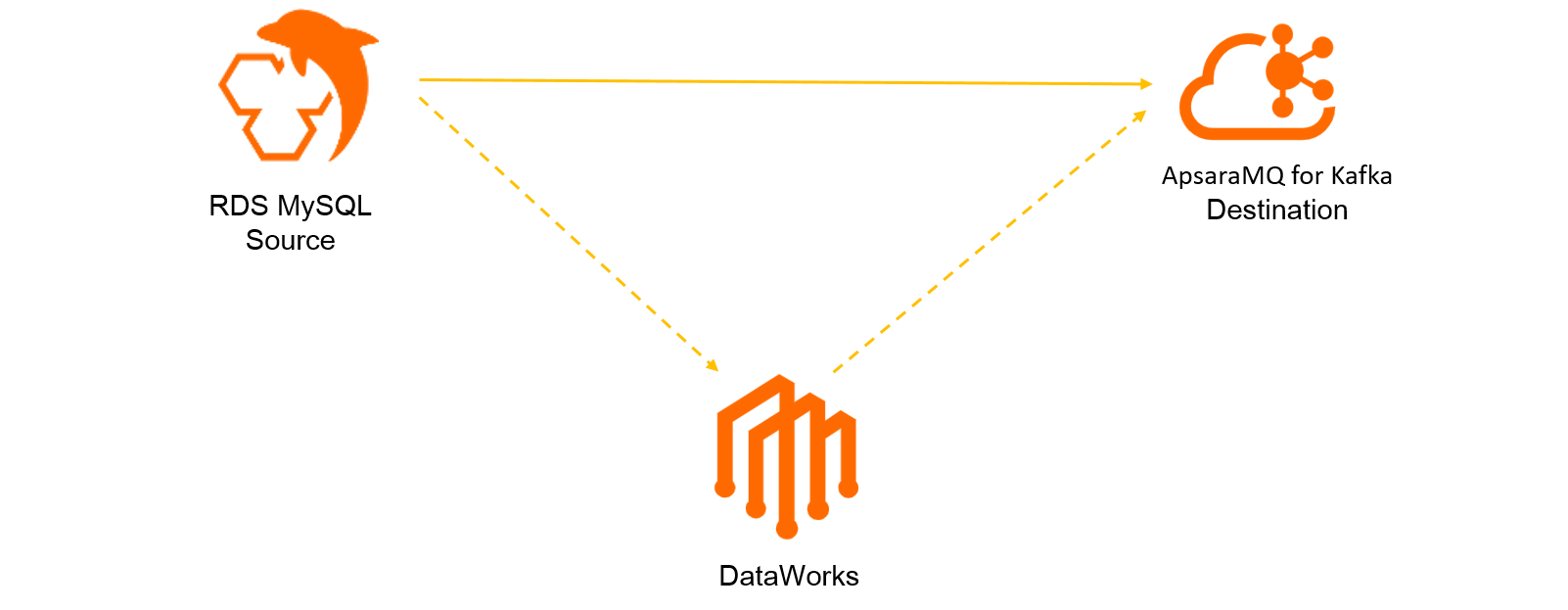
A MySQL source connector synchronizes row-level changes from an ApsaraDB RDS for MySQL database to topics in your ApsaraMQ for Kafka instance. The connector uses DataWorks to capture change data capture (CDC) events -- including INSERT, UPDATE, and DELETE operations -- and delivers them to Kafka topics.
How it works
When you create a MySQL source connector through the ApsaraMQ for Kafka console, the system automatically:
Activates DataWorks Basic Edition (free of charge).
Creates a DataWorks workspace and an exclusive resource group for data integration.
Generates destination topics in your Kafka instance -- one topic per source table.
The exclusive resource group (4 vCPUs, 8 GB memory) runs the data synchronization tasks. Resource groups use monthly subscriptions and renew automatically upon expiration.
Exclusive resource groups for data integration are paid services. For pricing details, see Billing overview.
Topic naming and partitions
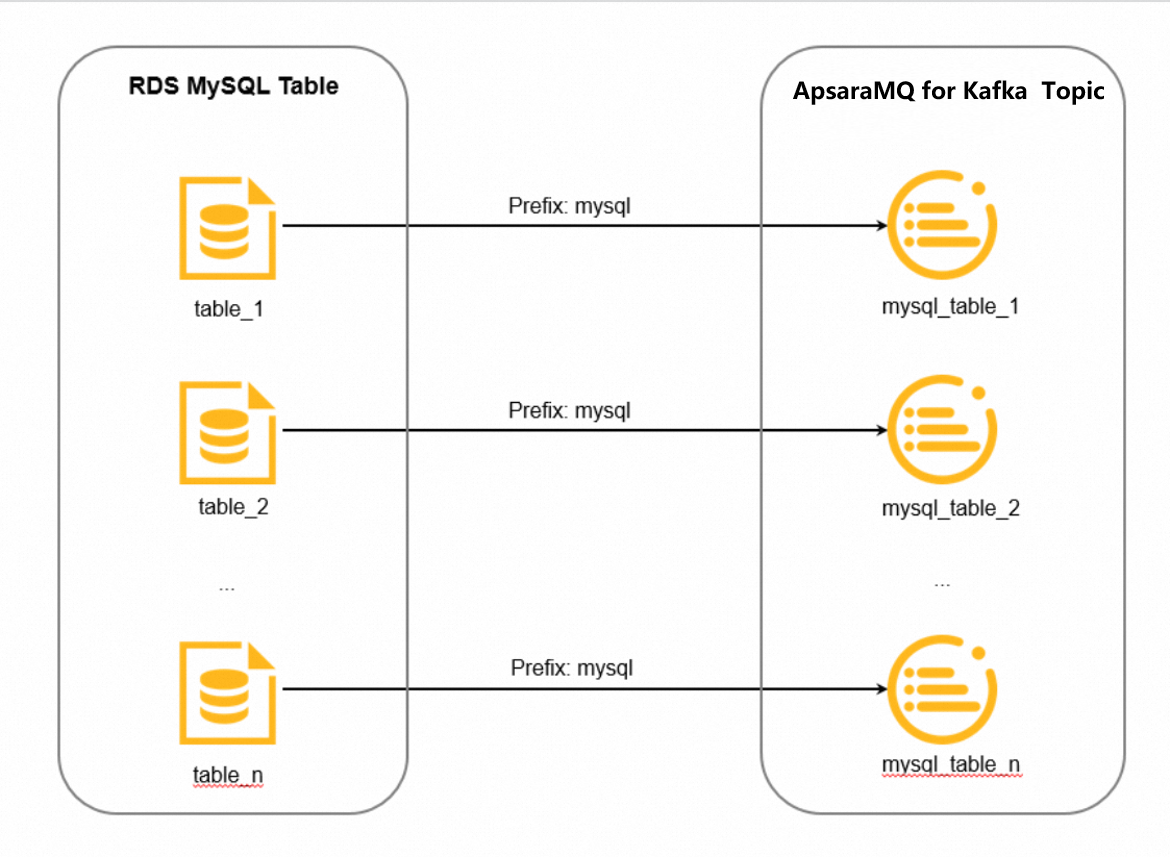
DataWorks generates one destination topic per source table using the naming pattern:
<topic-prefix>_<source-table-name>The underscore is added automatically. For example, if the prefix is mysql and the source tables are table_1, table_2, and table_n, the generated topics are mysql_table_1, mysql_table_2, and mysql_table_n.
Partition count depends on whether the source table has a primary key:
| Source table type | Partitions per topic |
|---|---|
| Has a primary key | 6 |
| No primary key | 1 |
Make sure your Kafka instance has enough available topics and partitions. If the instance runs out of either, topic creation fails and the connector cannot be deployed.
Region and networking
Same region -- When both the RDS MySQL instance and the Kafka instance are in the same region, the system automatically creates an elastic network interface (ENI) in the corresponding virtual private cloud (VPC) and binds it to the Elastic Compute Service (ECS) instance of the exclusive resource group. No manual networking setup is required.
Different regions -- When the instances are in different regions, make sure that:
A Cloud Enterprise Network (CEN) instance exists under the same Alibaba Cloud account.
The VPCs of both the RDS MySQL instance and the Kafka instance are attached to the CEN instance.
Cross-region bandwidth is configured for the CEN instance.
Without proper CEN configuration, the system may create a CEN instance automatically, but with minimal bandwidth. This can cause connectivity errors during connector creation or at runtime.
Exclusive resource group limits
| Limit | Value |
|---|---|
| Max connectors per resource group | 3 |
| Max VPC ENI associations per resource group | 2 |
If an existing resource group has fewer than three connectors, DataWorks reuses it for new connectors. However, if CIDR block overlaps or other technical constraints prevent reuse, DataWorks creates a new resource group instead.
Prerequisites
Before you begin, make sure that you have:
An ApsaraMQ for Kafka instance with the connector feature enabled, deployed in one of these regions: China (Shenzhen), China (Chengdu), China (Beijing), China (Zhangjiakou), China (Hangzhou), China (Shanghai), or Singapore
An ApsaraDB RDS for MySQL instance with a database, database account, and at least one table created. For SQL reference, see Commonly used SQL statements for MySQL
Non-overlapping CIDR blocks between the VPC of your RDS MySQL instance and the VPC of your Kafka instance
DataWorks authorized to access your ENIs through the Cloud Resource Access Authorization page
Both the data source (ApsaraDB RDS for MySQL instance) and the data destination (ApsaraMQ for Kafka instance) created under the same Alibaba Cloud account
Database account permissions
The MySQL database account must have at least the following permissions:
| Permission | Purpose |
|---|---|
SELECT | Read rows from source tables |
REPLICATION SLAVE | Connect to and read the MySQL binary log |
REPLICATION CLIENT | Query binary log status |
Grant these permissions with the following statement:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '<your-username>'@'%';Replace <your-username> with the actual database account username.
RAM user permissions
If you use a Resource Access Management (RAM) user instead of an Alibaba Cloud account, attach these policies to the RAM user:
| Policy | Description |
|---|---|
AliyunDataWorksFullAccess | Manage all DataWorks resources within the Alibaba Cloud account |
AliyunBSSOrderAccess | Purchase Alibaba Cloud services |
For instructions, see Grant permissions to RAM users.
Create and deploy the connector
Log on to the ApsaraMQ for Kafka console.
In the Resource Distribution section of the Overview page, select the region of your instance.
In the left-side navigation pane, click Connectors.
On the Connectors page, select your instance from the Select Instance drop-down list and click Create Connector.
Complete the three-step wizard: Click Next. Step 2: Configure source service Select ApsaraDB RDS for MySQL as the source service and configure the following parameters: Click Next. Step 3: Configure destination service Confirm the destination Kafka instance and click Create.
Step 1: Configure basic information
Parameter Description Example Name A unique connector name within the instance. 1--48 characters; digits, lowercase letters, and hyphens ( -) allowed. Cannot start with a hyphen. The system auto-creates a consumer group namedconnect-<connector-name>.kafka-source-mysqlInstance Displays the name and ID of the selected Kafka instance. demo alikafka_post-cn-st21p8vj****Parameter Description Example Region of ApsaraDB RDS for MySQL Instance Region of the source RDS MySQL instance. China (Shenzhen) ApsaraDB RDS for MySQL Instance ID Instance ID of the source database. rm-wz91w3vk6owmz****Database Name Name of the database to synchronize. mysql-to-kafkaDatabase Account Username for the database connection. mysql_to_kafkaPassword of Database Account Password for the database connection. -- Database Table One or more table names, separated by commas ( ,). Each table maps to one topic.mysql_tblTables to Automatically Add A regular expression to auto-detect and synchronize new tables. Use .*for all tables..*Topic Prefix Prefix for auto-generated topic names. Must be globally unique. mysqlOn the Connectors page, find the connector and click Deploy in the Actions column. When the Status column shows Running, the connector is active and synchronizing data.
Verify data synchronization
Insert a test row into a source table: For more SQL examples, see Commonly used SQL statements for MySQL.
INSERT INTO mysql_tbl (mysql_title, mysql_author, submission_date) VALUES ("mysql2kafka", "tester", NOW());Use the message query feature in ApsaraMQ for Kafka to confirm the data arrived in the corresponding topic. For instructions, see Query messages. A successfully synchronized INSERT event looks like this:
{ "schema": { "dataColumn": [ { "name": "mysql_id", "type": "LONG" }, { "name": "mysql_title", "type": "STRING" }, { "name": "mysql_author", "type": "STRING" }, { "name": "submission_date", "type": "DATE" } ], "primaryKey": [ "mysql_id" ], "source": { "dbType": "MySQL", "dbName": "mysql_to_kafka", "tableName": "mysql_tbl" } }, "payload": { "before": null, "after": { "dataColumn": { "mysql_title": "mysql2kafka", "mysql_author": "tester", "submission_date": 1614700800000 } }, "sequenceId": "1614748790461000000", "timestamp": { "eventTime": 1614748870000, "systemTime": 1614748870925, "checkpointTime": 1614748870000 }, "op": "INSERT", "ddl": null }, "version": "0.0.1" }
Message fields
| Field | Description |
|---|---|
schema.dataColumn | Column names and data types from the source table |
schema.primaryKey | Primary key columns of the source table |
schema.source | Source database type, database name, and table name |
payload.before | Row state before the change (null for INSERT operations) |
payload.after | Row state after the change (null for DELETE operations) |
payload.op | Operation type: INSERT, UPDATE, or DELETE |
payload.timestamp | Event, system, and checkpoint timestamps |
For the full message format specification, see Message formats.
What's next
Query messages in your Kafka topics
Enable the connector feature for additional instances