When many jobs run concurrently in a job resource group, they can compete for more resources than the group can supply. For example, a critical aggregation job that upstream dashboards depend on may need to run before lower-priority data sync jobs — even when both are waiting at the same time. AnalyticDB for MySQL Data Lakehouse Edition (V3.0) queues jobs that cannot run immediately, keeping them in the submitted state until resources become available. Priority queues let you control which jobs move to the front of that queue.
Prerequisites
Before you begin, ensure that you have:
An AnalyticDB for MySQL Data Lakehouse Edition (V3.0) cluster running V3.1.6.3 or later
A job resource group with at least one job submitted to it
Priority levels
Four priority levels are available, listed from highest to lowest:
| Level | Description |
|---|---|
| HIGH | Jobs enter the high-priority queue and run before all lower-priority jobs. |
| NORMAL | Default level. Extract, transform, and load (ETL) queries and SELECT queries use this level unless configured otherwise. |
| LOW | Jobs enter the low-priority queue and yield to NORMAL and HIGH jobs. |
| LOWEST | Jobs run last when resources are available. |
Set job priorities
View in the console
You can view the priorities of jobs in job resource groups in one of the following two ways.
Set a job's priority before submitting it. Once a job is in the submitted state — regardless of whether it is running — you cannot change its priority.
The configuration method depends on the job type:
| Job type | Configuration method | Key |
|---|---|---|
| XIHE bulk synchronous parallel (BSP) | SQL hint | query_priority |
| Spark SQL | SET statement | spark.adb.priority |
| Spark batch | conf parameter in the job payload | spark.adb.priority |
XIHE BSP jobs
Add a hint before the query:
/*+ query_priority=<priority_level>*/ <your_query>The following example sets the priority to HIGH:
/*+ query_priority=HIGH*/ SELECT * FROM test_table;Spark SQL jobs
Run a SET statement before your query in the same session:
SET spark.adb.priority = <priority_level>;
<your_query>The following example sets the priority to LOW:
SET spark.adb.priority = LOW;
SELECT * FROM test_table;Spark batch jobs
Include spark.adb.priority in the conf object of your job submission payload:
{
"comments": [
"-- Here is just an example of SparkPi. Modify the content and run your spark program."
],
"args": [
"1000"
],
"file": "local:///tmp/spark-examples.jar",
"name": "SparkPi",
"className": "org.apache.spark.examples.SparkPi",
"conf": {
"spark.driver.resourceSpec": "medium",
"spark.executor.instances": 2,
"spark.executor.resourceSpec": "medium",
"spark.adb.priority": "HIGH"
}
}View job priorities
XIHE BSP and Spark SQL jobs
Log on to the AnalyticDB for MySQL console.
In the left-side navigation pane of a cluster, choose Job Development > SQL Development.
On the Execution Records tab, view the priority of each job.

Spark batch jobs
Log on to the AnalyticDB for MySQL console.
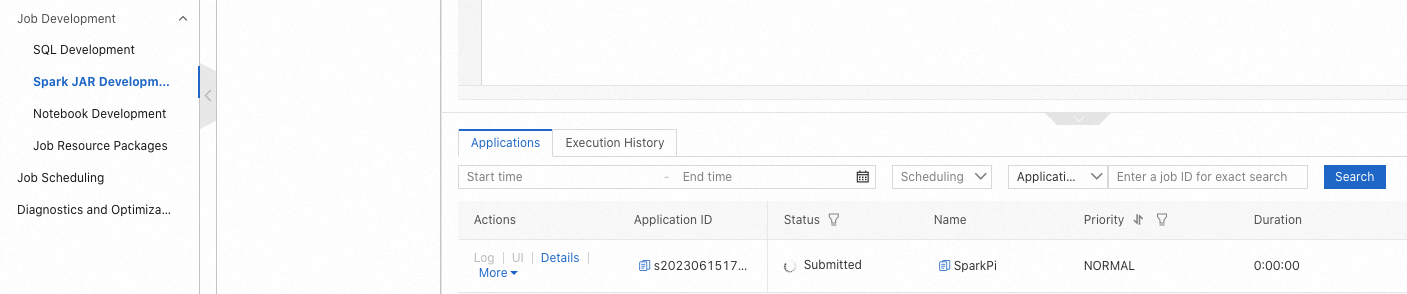
In the left-side navigation pane of a cluster, choose Job Development > Spark JAR Development.
On the Applications tab, view the priority of each job.
View using SQL
Run the SHOW job status WHERE job = '<JobId>'; statement.