AnalyticDB for MySQL Serverless Spark is a big data analytics service built on Apache Spark, developed by the AnalyticDB for MySQL team. After you create an AnalyticDB for MySQL cluster, submit Spark jobs with minimal configuration — no Spark cluster deployment required.
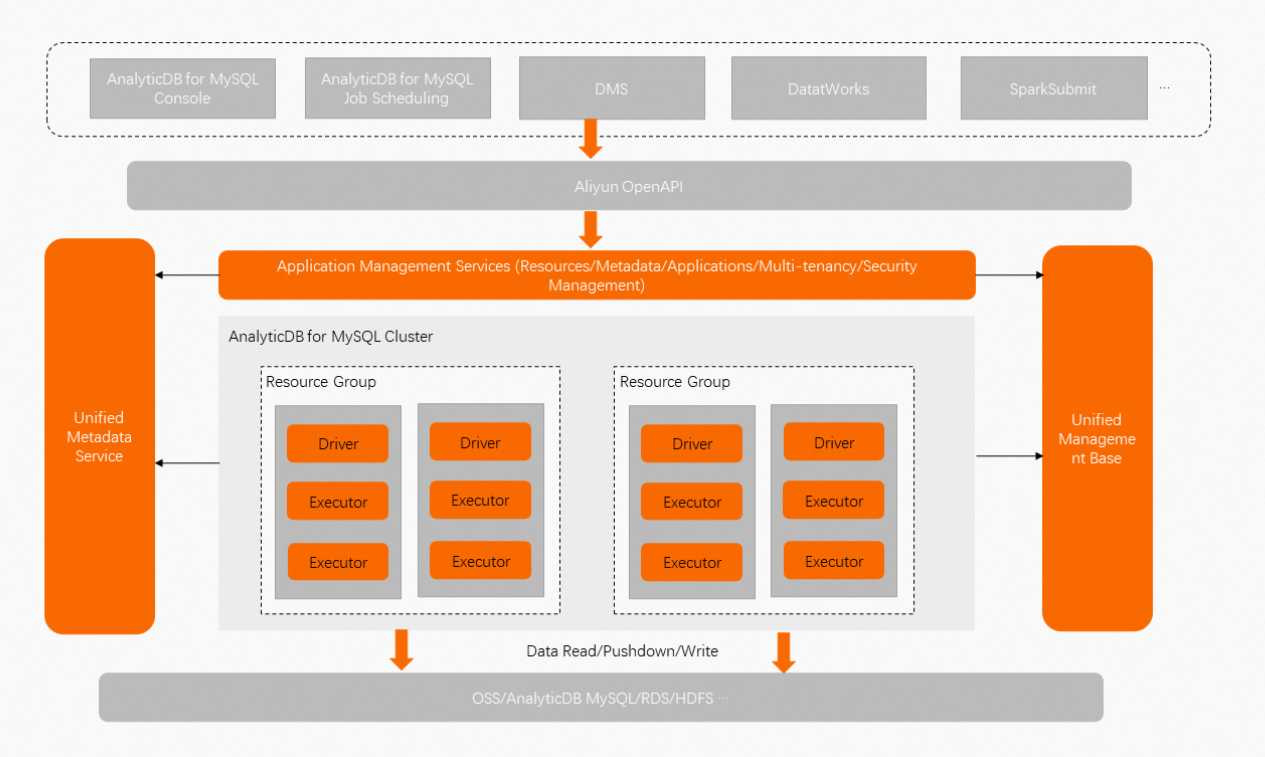
How it works
Apache Spark is an open source distributed processing system for big data workloads. It supports SQL and DataFrames across multiple programming languages, and covers SQL, batch processing, stream processing, machine learning, and graph computing.
Serverless Spark integrates Apache Spark with serverless and cloud-native technologies. The AnalyticDB for MySQL team provides in-depth customization on top of the open source engine — including native integration with AnalyticDB for MySQL data warehouses and optimized access to Object Storage Service (OSS).
Key concepts
| Term | Description |
|---|---|
| Spark job | A unit of work submitted to Serverless Spark. Each job runs independently with its own allocated resources. |
| Driver | The Spark driver process that coordinates job execution. |
| Executor | Spark executor processes that run the actual computation tasks. |
Advantages
| Feature | Description |
|---|---|
| Ease of use | Submit jobs through APIs, scripts, or the console — the same workflow as Apache Spark, without configuring any underlying components. |
| O&M-free | No server setup, Hadoop configuration, or manual resource scaling. AnalyticDB for MySQL manages the infrastructure. |
| Job-level scalability | Allocate resources independently for the driver and executor of each job. Resources scale up within seconds. |
| Reduced costs | Pay only for the resources a job uses. No charges when no resources are in use. |
| Enhanced performance | In typical scenarios, OSS data access runs at up to 5x the speed of standard Apache Spark. Connection performance reaches up to 6x that of a Java Database Connectivity (JDBC) connection. A zero-ETL solution is available for direct integration between AnalyticDB for MySQL and Apache Spark. |
Use cases
| Use case | Description |
|---|---|
| Large-scale ETL | Process and transform high-volume datasets without provisioning a dedicated Spark cluster. |
| Machine learning | Run MLlib-based training jobs with on-demand resources that scale to workload size. |
| Stream processing | Handle real-time data pipelines using Structured Streaming on a fully managed runtime. |
| Ad hoc analytics | Submit batch SQL or DataFrame jobs interactively without cluster pre-allocation. |