AnalyticDB for MySQL integrates with Apache Hudi to deliver a data lakehouse solution on Object Storage Service (OSS). After creating a cluster, you can start ingesting data into Hudi tables on OSS — no complex Spark setup required.
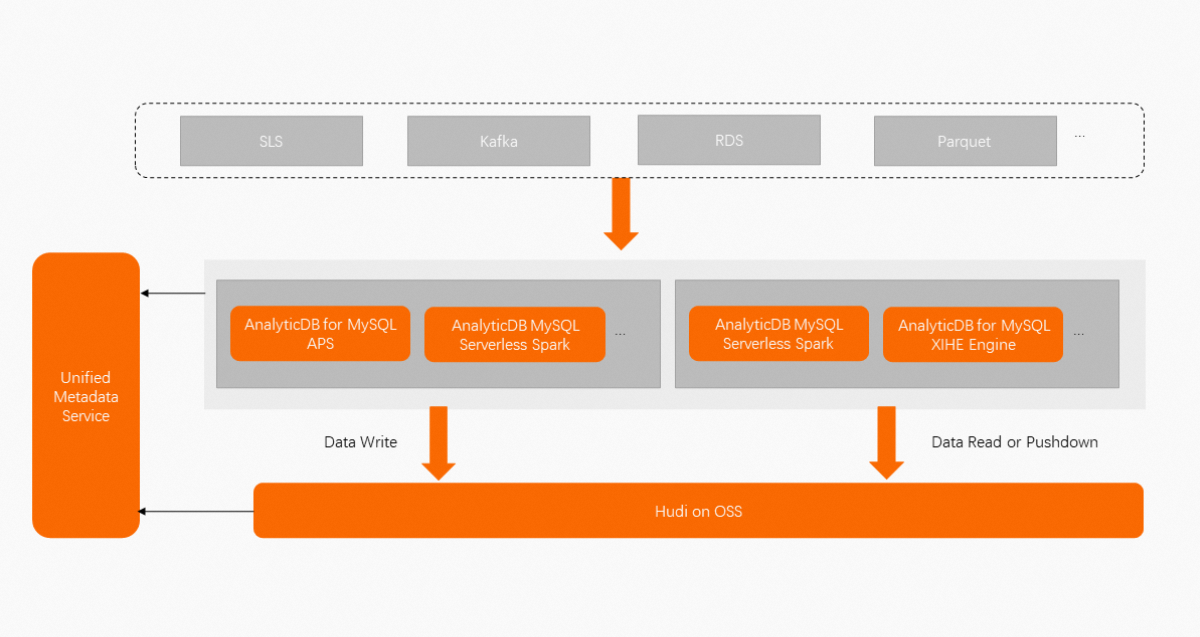
How it works
Data flows through three stages:
Ingest: Use AnalyticDB Pipeline Service (APS) to stream log data from Kafka or Log Service into Hudi tables in near real time. Alternatively, use the Serverless Spark engine to load structured data from ApsaraDB RDS or Parquet files in batches.
Store: Data lands in Hudi tables on OSS. The system automatically merges small files, manages partition lifecycles, and runs table services such as clustering — all asynchronously and isolated from the write path.
Query: Both the Serverless Spark engine and the XIHE engine can read data directly after it is written. Metadata is synchronized automatically, so no manual table registration is needed.
Apache Hudi capabilities
Apache Hudi provides the storage foundation:
Support for multiple versions of file management protocols
Real-time incremental writes with ACID (atomicity, consistency, isolation, and durability) transaction guarantees
Automatic small-file merging and optimization
Schema evolution and metadata verification
High-efficiency columnar formats with index optimization
Support for super-large partitioned tables
AnalyticDB for MySQL enhancements
AnalyticDB for MySQL adds the following capabilities on top of the open source Hudi foundation:
High-performance writes
The OSS write path is optimized to deliver more than twice the write throughput compared to open source Hudi in most logging workloads. Hot data is distributed evenly across partitions automatically, eliminating data skew and improving write stability.
Partitioned lifecycle management
Control the retention of partition data by number of partitions, data volume, or expiration time. Multiple lifecycle policies can run concurrently to further reduce storage costs.
Asynchronous table services
Table services such as clustering run completely independently of the write path. In most workloads, clustering improves query performance by up to more than 40%.
Automatic metadata synchronization
Metadata is managed centrally. After data is written to a Hudi table, both the Serverless Spark engine and the XIHE engine can access it without the need to manually synchronize the table metadata. One copy of ingested data is readable by multiple compute engines.
Ease of use
Configure data ingestion through the APS graphical console. No Spark configuration files are needed.
Use cases
Near-real-time log ingestion: Stream application logs from Kafka or Log Service into Hudi tables on OSS with low latency, while keeping storage costs in check through lifecycle management.
Batch data migration: Load structured data from ApsaraDB RDS or Parquet files into the lakehouse using Serverless Spark, then query the data with either Serverless Spark or XIHE without duplicating it.
Multi-engine analytics: Ingest data once and make it available to multiple compute engines through centralized metadata management, eliminating redundant copies and reducing storage overhead.