Arena lets you submit multi-GPU distributed PyTorch training jobs to an ACK cluster and visualize results with TensorBoard — all from the command line.
Prerequisites
Before you begin, ensure that you have:
An ACK cluster with GPU-accelerated nodes. For details, see Create an ACK cluster that contains GPU-accelerated nodes.
Internet access enabled for cluster nodes. For details, see Enable an existing ACK cluster to access the Internet.
The Arena component installed. For details, see Configure the Arena client.
A persistent volume claim (PVC) named
training-datawith the MNIST dataset stored at/pytorch_data. For details, see Configure a shared NAS volume.
Background
This tutorial trains a PyTorch model on the MNIST dataset across two nodes, each using two GPUs — four GPUs in total. The training code runs with torchrun, PyTorch's built-in launcher for distributed jobs.
The workflow pulls training code from a Git repository and reads data from a shared NAS-backed volume (PV/PVC). For reference, see main.py.
Step 1: Check available GPU resources
Run the following command to see the GPUs available in your cluster:
arena top nodeExpected output:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated)
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 0
---------------------------------------------------------------------------------------------------
Allocated/Total GPUs In Cluster:
0/4 (0.0%)The cluster has two GPU-accelerated nodes with two idle GPUs each — four GPUs available for training.
Step 2: Submit a distributed PyTorch training job
Run the following command to submit the job. It creates two worker Pods, each using two GPUs.
Three parameters control the distributed topology:
--workers=2— total number of Pods, including the master Pod--gpus=2— GPUs allocated to each Pod--nproc-per-node=2— torchrun processes started per Pod; each process uses one GPU
arena submit pytorch \
--name=pytorch-mnist \
--namespace=default \
--workers=2 \
--gpus=2 \
--nproc-per-node=2 \
--clean-task-policy=None \
--working-dir=/root \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/pytorch-with-tensorboard:2.5.1-cuda12.4-cudnn9-runtime \
--sync-mode=git \
--sync-source=https://github.com/kubeflow/arena.git \
--env=GIT_SYNC_BRANCH=v0.13.1 \
--data=training-data:/mnt \
--tensorboard \
--logdir=/mnt/pytorch_data/logs \
"torchrun /root/code/arena/examples/pytorch/mnist/main.py --epochs 10 --backend nccl --data /mnt/pytorch_data --dir /mnt/pytorch_data/logs"Expected output:
service/pytorch-mnist-tensorboard created
deployment.apps/pytorch-mnist-tensorboard created
pytorchjob.kubeflow.org/pytorch-mnist created
INFO[0002] The Job pytorch-mnist has been submitted successfully
INFO[0002] You can run `arena get pytorch-mnist --type pytorchjob -n default` to check the job statusHow it works: nodes, roles, and environment variables
Distributed PyTorch jobs in Arena use two parameters that standalone jobs don't need:
--workers— the total number of Pods. One Pod takes themasterrole; the rest areworkerPods.--nproc-per-node— the number of torchrun processes started on each Pod. Each process maps to one GPU.
Pod names follow the <job_name>-<role_name>-<index> pattern. For example, --workers=3 and --nproc-per-node=2 on a job named pytorch-mnist creates three Pods and starts two processes each:
| Environment variable | pytorch-mnist-master-0 | pytorch-mnist-worker-0 | pytorch-mnist-worker-1 |
|---|---|---|---|
MASTER_ADDR | pytorch-mnist-master-0 | — | — |
MASTER_PORT | 23456 | — | — |
WORLD_SIZE | 6 | — | — |
RANK | 0 | 1 | 2 |
PET_MASTER_ADDR | pytorch-mnist-master-0 | — | — |
PET_MASTER_PORT | 23456 | — | — |
PET_NNODES | 3 | — | — |
PET_NODE_RANK | 0 | 1 | 2 |
Arena automatically injects these variables into each Pod. In your training code, use RANK to identify which process should save checkpoints or log metrics. For example, only the process where RANK=0 (the master) writes results, which avoids duplicate output. Use WORLD_SIZE to determine the total number of parallel processes when computing distributed gradients.
Parameter reference
| Parameter | Required | Description | Default |
|---|---|---|---|
--name | Yes | Job name, globally unique | — |
--namespace | No | Kubernetes namespace | default |
--workers | No | Total number of worker Pods, including master. For example, --workers=3 creates one master Pod and two worker Pods | 0 |
--gpus | No | GPUs allocated to each worker Pod | 0 |
--working-dir | No | Directory where the training command runs | /root |
--image | Yes | Container image used for the runtime | — |
--sync-mode | No | Source code sync mode: git or rsync | — |
--sync-source | No | Repository URL for source code sync. Code is downloaded to code/ under --working-dir (for example, /root/code/arena) | — |
--data | No | Mounts a PVC to the Pod as <pvc-name>:<mount-path>. Run arena data list to view available PVCs | — |
--tensorboard | No | Enables TensorBoard visualization. Requires --logdir | — |
--logdir | No | Path where TensorBoard reads event files. Use together with --tensorboard | /training_logs |
Use a private Git repository
If your code is in a private repository, pass credentials as environment variables:
arena submit pytorch \
...
--sync-mode=git \
--sync-source=https://github.com/kubeflow/arena.git \
--env=GIT_SYNC_BRANCH=v0.13.1 \
--env=GIT_SYNC_USERNAME=<username> \
--env=GIT_SYNC_PASSWORD=<password> \
"torchrun /root/code/arena/examples/pytorch/mnist/main.py --epochs 10 --backend nccl --data /mnt/pytorch_data --dir /mnt/pytorch_data/logs"Arena uses git-sync to pull source code, so all environment variables defined in the git-sync project are available.
Can't pull code due to network issues?
If the GitHub repository is unreachable, manually download the code to the NAS volume. Place it at code/github.com/kubeflow/arena inside the NAS — this maps to /mnt/code/github.com/kubeflow/arena after the volume is mounted. Then submit without --sync-mode:
arena submit pytorch \
--name=pytorch-mnist \
--namespace=default \
--workers=2 \
--gpus=2 \
--nproc-per-node=2 \
--clean-task-policy=None \
--working-dir=/root \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/pytorch-with-tensorboard:2.5.1-cuda12.4-cudnn9-runtime \
--data=training-data:/mnt \
--tensorboard \
--logdir=/mnt/pytorch_data/logs \
"torchrun /mnt/code/github.com/kubeflow/arena/examples/pytorch/mnist/main.py --epochs 10 --backend nccl --data /mnt/pytorch_data --dir /mnt/pytorch_data/logs"Step 3: Monitor the training job
After submitting, the job passes through several stages before logs appear:
Pending — Kubernetes is scheduling Pods onto GPU nodes.
Preparing — Pods pull the container image and sync the Git repository. Logs are not yet available.
Running — torchrun starts and training begins. Logs are available at this stage.
Use the following commands to track progress.
List all jobs:
arena list -n defaultExpected output:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE
pytorch-mnist RUNNING PYTORCHJOB 48s 4 4 192.168.xxx.xxxCheck GPU usage by job:
arena top job -n defaultExpected output:
NAME STATUS TRAINER AGE GPU(Requested) GPU(Allocated) NODE
pytorch-mnist RUNNING PYTORCHJOB 55s 4 4 192.168.xxx.xxx
Total Allocated/Requested GPUs of Training Jobs: 4/4Check cluster-level GPU allocation:
arena top nodeExpected output:
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated)
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 0 0
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 2
cn-beijing.192.168.xxx.xxx 192.168.xxx.xxx <none> Ready 2 2
---------------------------------------------------------------------------------------------------
Allocated/Total GPUs In Cluster:
4/4 (100.0%)All four GPUs are now allocated.
Get detailed job information:
arena get pytorch-mnist -n defaultExpected output:
Name: pytorch-mnist
Status: RUNNING
Namespace: default
Priority: N/A
Trainer: PYTORCHJOB
Duration: 1m
CreateTime: 2025-02-12 13:54:51
EndTime:
Instances:
NAME STATUS AGE IS_CHIEF GPU(Requested) NODE
---- ------ --- -------- -------------- ----
pytorch-mnist-master-0 Running 1m true 2 cn-beijing.192.168.xxx.xxx
pytorch-mnist-worker-0 Running 1m false 2 cn-beijing.192.168.xxx.xxx
Tensorboard:
Your tensorboard will be available on:
http://192.168.xxx.xxx:32084The job has one master Pod and one worker Pod, each using two GPUs. The TensorBoard URL is shown only when --tensorboard is enabled.
Step 4: View training results in TensorBoard
kubectl port-forward is for development and debugging only. It is not reliable, secure, or scalable for production. For production networking in ACK clusters, see Ingress management.
Forward TensorBoard's port to your local machine:
kubectl port-forward -n default svc/pytorch-mnist-tensorboard 9090:6006Open
http://127.0.0.1:9090in a browser.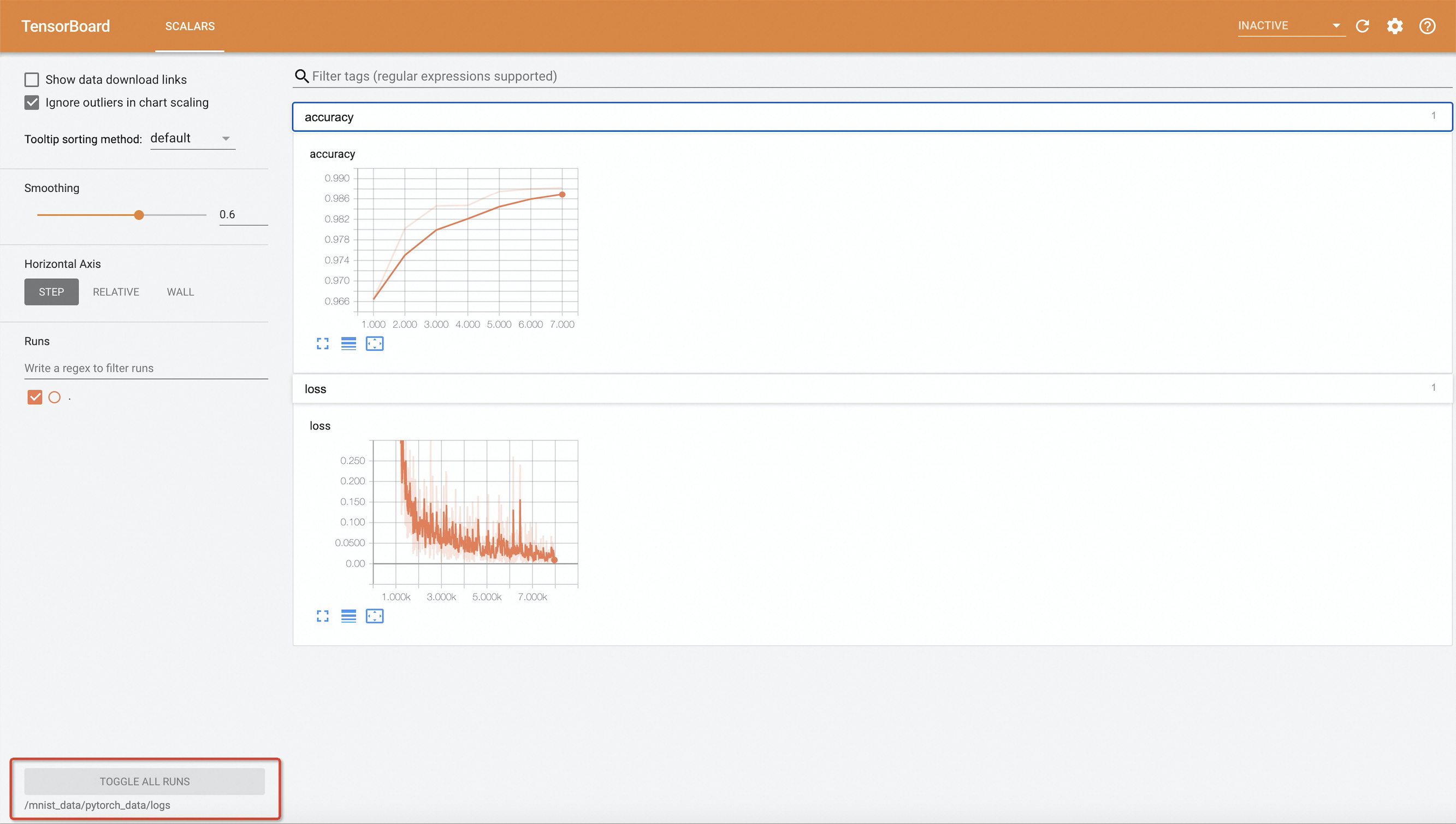
The example training code writes events every 10 epochs. If you change --epochs, set it to a multiple of 10 — otherwise no events are written and TensorBoard shows no data.Step 5: View training logs
View master Pod logs:
arena logs -n default pytorch-mnistExpected output:
{'PID': 40, 'MASTER_ADDR': 'pytorch-mnist-master-0', 'MASTER_PORT': '23456', 'LOCAL_RANK': 0, 'RANK': 0, 'GROUP_RANK': 0, 'ROLE_RANK': 0, 'LOCAL_WORLD_SIZE': 2, 'WORLD_SIZE': 4, 'ROLE_WORLD_SIZE': 4}
{'PID': 41, 'MASTER_ADDR': 'pytorch-mnist-master-0', 'MASTER_PORT': '23456', 'LOCAL_RANK': 1, 'RANK': 1, 'GROUP_RANK': 0, 'ROLE_RANK': 1, 'LOCAL_WORLD_SIZE': 2, 'WORLD_SIZE': 4, 'ROLE_WORLD_SIZE': 4}
Using cuda:0.
Using cuda:1.
Train Epoch: 1 [0/60000 (0%)] Loss: 2.283599
Train Epoch: 1 [0/60000 (0%)] Loss: 2.283599
...
Train Epoch: 10 [59520/60000 (99%)] Loss: 0.007343
Train Epoch: 10 [59520/60000 (99%)] Loss: 0.007343
Accuracy: 9919/10000 (99.19%)
Accuracy: 9919/10000 (99.19%)View a specific worker Pod's logs:
arena logs -n default -i pytorch-mnist-worker-0 pytorch-mnistExpected output:
{'PID': 39, 'MASTER_ADDR': 'pytorch-mnist-master-0', 'MASTER_PORT': '23456', 'LOCAL_RANK': 0, 'RANK': 2, 'GROUP_RANK': 1, 'ROLE_RANK': 2, 'LOCAL_WORLD_SIZE': 2, 'WORLD_SIZE': 4, 'ROLE_WORLD_SIZE': 4}
{'PID': 40, 'MASTER_ADDR': 'pytorch-mnist-master-0', 'MASTER_PORT': '23456', 'LOCAL_RANK': 1, 'RANK': 3, 'GROUP_RANK': 1, 'ROLE_RANK': 3, 'LOCAL_WORLD_SIZE': 2, 'WORLD_SIZE': 4, 'ROLE_WORLD_SIZE': 4}
Using cuda:0.
Using cuda:1.
Train Epoch: 1 [0/60000 (0%)] Loss: 2.283599
Train Epoch: 1 [0/60000 (0%)] Loss: 2.283599
...
Train Epoch: 10 [58880/60000 (98%)] Loss: 0.051877Train Epoch: 10 [58880/60000 (98%)] Loss: 0.051877
Train Epoch: 10 [59520/60000 (99%)] Loss: 0.007343Train Epoch: 10 [59520/60000 (99%)] Loss: 0.007343
Accuracy: 9919/10000 (99.19%)
Accuracy: 9919/10000 (99.19%)Useful log flags:
-f— stream logs in real time-t N/--tail N— show the last N linesarena logs --help— see all options
(Optional) Step 6: Clean up
Delete the training job when you no longer need it. This removes the Pods and the associated TensorBoard deployment, freeing up GPU resources in your cluster.
arena delete pytorch-mnist -n defaultExpected output:
INFO[0001] The training job pytorch-mnist has been deleted successfullyWhat's next
To learn more about Arena commands, run
arena --helpor visit the Arena documentation.To run a standalone PyTorch training job for comparison, see the standalone PyTorch tutorial.
For production-grade networking to expose TensorBoard, see Ingress management.