This document shows how to deploy a model inference service for the Qwen3-32B model on Container Service for Kubernetes (ACK), using the SGLang inference engine with Prefill-Decode Disaggregation.
Background
Qwen3-32B
Qwen3-32B represents the latest evolution in the Qwen series, featuring a 32.8B-parameter dense architecture optimized for both reasoning efficiency and conversational fluency.
Key features:
Dual-mode performance: Excels at complex tasks like logical reasoning, math, and code generation, while remaining highly efficient for general text generation.
Advanced capabilities: Demonstrates excellent performance in instruction following, multi-turn dialog, creative writing, and best-in-class tool use for AI agent tasks.
Large context window: Natively handles up to 32,000 tokens of context, which can be extended to 131,000 tokens using YaRN technology.
Multilingual support: Understands and translates over 100 languages, making it ideal for global applications.
For more information, see the blog, GitHub, and documentation.
SGLang
SGLang is an inference engine that combines a high-performance backend with a flexible frontend, designed for both large language model (LLM) and multimodal workloads.
High-performance backend:
Advanced caching: Features RadixAttention (an efficient prefix cache) and PagedAttention to maximize throughput during complex inference tasks.
Efficient execution: Uses continuous batching, speculative decoding, Prefill-Decode Disaggregation, and multi-LoRA batching to efficiently serve multiple users and fine-tuned models.
Full parallelism and quantization: Supports TP, PP, DP, and EP parallelism, along with various quantization methods (FP8, INT4, AWQ, GPTQ).
Flexible frontend:
Powerful programming interface: Enables developers to easily build complex applications with features such as chained generation, control flow, and parallel processing.
Multimodal and external interaction: Natively supports multimodal inputs (such as text and images) and allows for interaction with external tools, making it ideal for advanced agent workflows.
Broad model support: Supports generative models (Qwen, DeepSeek, Llama), embedding models (E5-Mistral), and reward models (Skywork).
For more information, see SGLang GitHub.
Prefill-Decode Disaggregation
Prefill-Decode Disaggregation is a mainstream optimization for LLM inference. This architecture resolves the conflicting resource demands of the two core stages of the inference process. The LLM inference process has two phases:
Prefill (prompt processing) phase: This phase processes the entire user-provided prompt at once. The attention for all input tokens is calculated in parallel to generate the initial KV cache. This process is compute-bound and requires powerful parallel computing capabilities but runs only once per request.
Decode (token generation) phase: This phase is an autoregressive process where the model generates new tokens one by one based on the existing KV cache. The computation for each step is small, but it requires repeatedly and rapidly loading the massive model weights and KV cache from GPU memory, making it memory-bound.
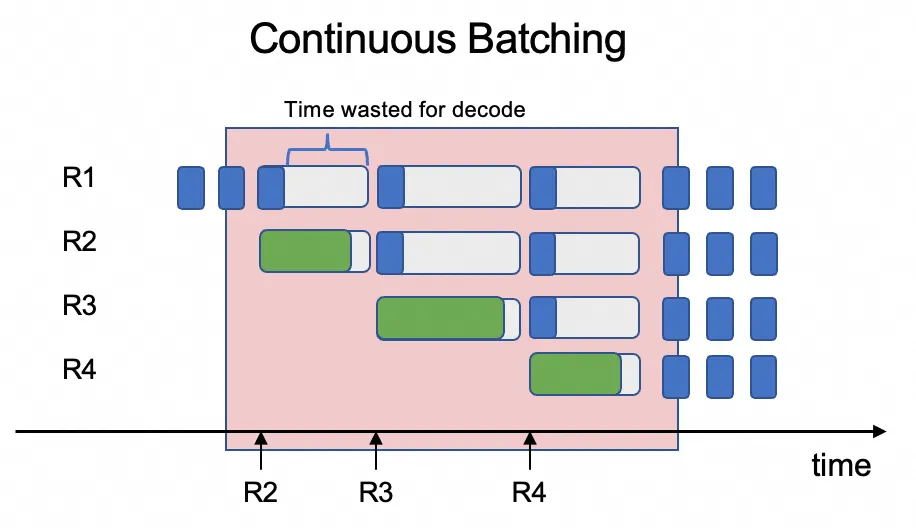
The core problem: Inefficient mixed-workload scheduling
The challenge is that scheduling these two distinct workloads on the same GPU is highly inefficient. Inference engines typically use continuous batching to process multiple user requests concurrently, mixing the prefill and decode stages of different requests within the same batch.
This creates a resource conflict: the compute-intensive prefill stage (processing an entire prompt) dominates the GPU's resources, causing the much lighter decode stage (generating a single token) to wait. This resource contention increases latency for the decode stage, in turn increasing the overall system latency and severely degrading throughput.
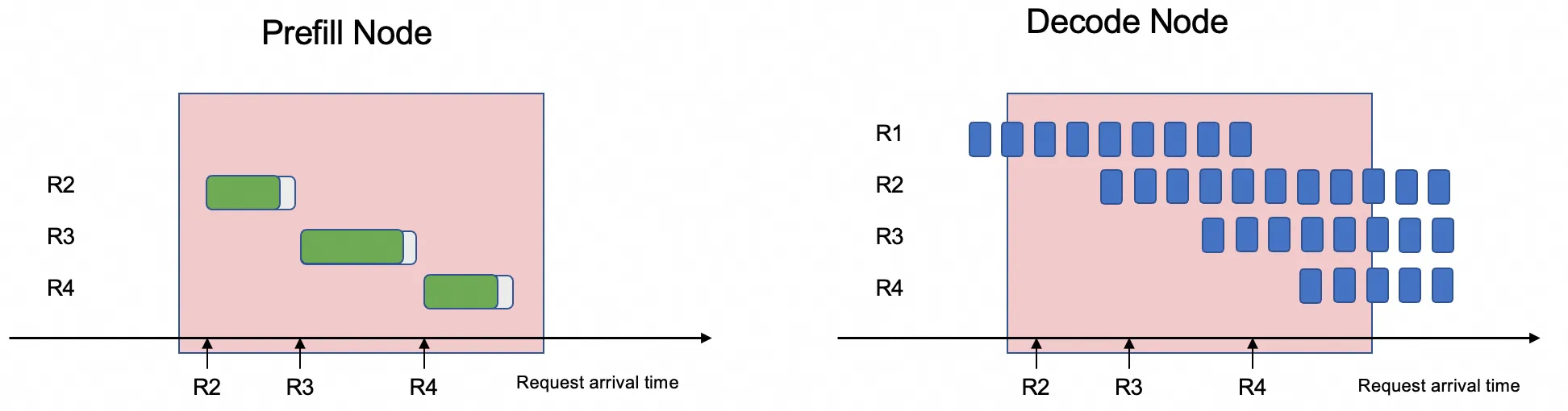
The Prefill-Decode Disaggregation architecture solves this by decoupling these two phases and deploying the Prefill and Decode tasks on different GPUs.
This separation lets the system optimize for the distinct characteristics of each phase, avoiding resource contention and significantly reducing the average Time Per Output Token (TPOT), thereby increasing system throughput.
RoleBasedGroup
The Alibaba Cloud Container Service team designed RoleBasedGroup (RBG), a new Workload, to address the challenges of large-scale deployment and operations of the Prefill-Decode Disaggregation architecture in Kubernetes clusters. This project has been open-sourced. For more information, see the RBG GitHub.
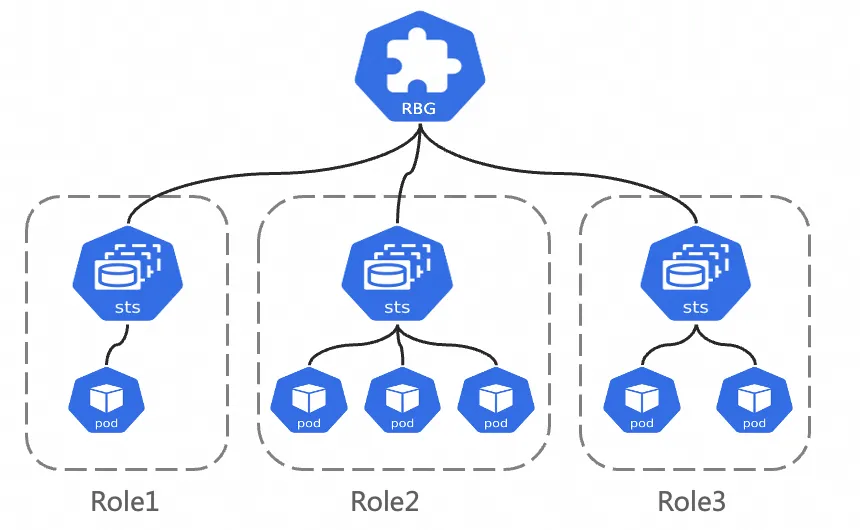
The RBG API design is shown in the figure below. It comprises a group of Roles that form a single unit, where each Role can be built on a StatefulSet, Deployment, or LWS. Key features include:
Flexible multi-role definition: RBG allows you to define any number of Roles with any name, specify dependencies between Roles to start them in a particular order, and elastically scale Roles independently.
Runtime: It provides automatic service discovery within the Group, supports multiple restart policies, rolling updates, and Gang Scheduling.
Prerequisites
Create an ACK cluster of version 1.22 or later and add GPU nodes to the cluster. For instructions, see Create an ACK managed cluster and Add GPU-accelerated nodes to a cluster.
This document requires a cluster with at least 6 GPUs, each with 32 GB or more of memory. Because the SGLang Prefill-Decode Disaggregation framework relies on GPU Direct RDMA (GDR) for data transfer, the selected node instance type must support Elastic Remote Direct Memory Access (eRDMA). We recommend the
ecs.ebmgn8is.32xlargeinstance type. For more information on instance types, see ECS Bare Metal Instance types.
Node operating system image: Using eRDMA requires a specific software stack. When creating a node pool, we recommend selecting the
Alibaba Cloud Linux 3 64-bit (pre-installed with the eRDMA software stack)operating system Image from the Marketplace Images. For instructions, see Add an eRDMA node to an ACK cluster.
Install the
ack-erdma-controllercomponent. For instructions, see Accelerate container networks with eRDMA to install and configure theack-erdma-controllercomponent in your cluster.Install the
ack-rbgscomponent. Follow these steps to install the component.Log on to the Container Service Management Console, and in the left-side navigation pane, choose Clusters.
Click the name of your target cluster to go to its details page. Use Helm to install the ack-rbgs component on the target cluster. You do not need to configure the Application Name or Namespace.
Click Next, and in the Confirm dialog box that appears, click Yes to use the default application name (ack-rbgs) and namespace (rbgs-system).
Then, select the latest Chart version and click OK to complete the installation.
Deploy the model
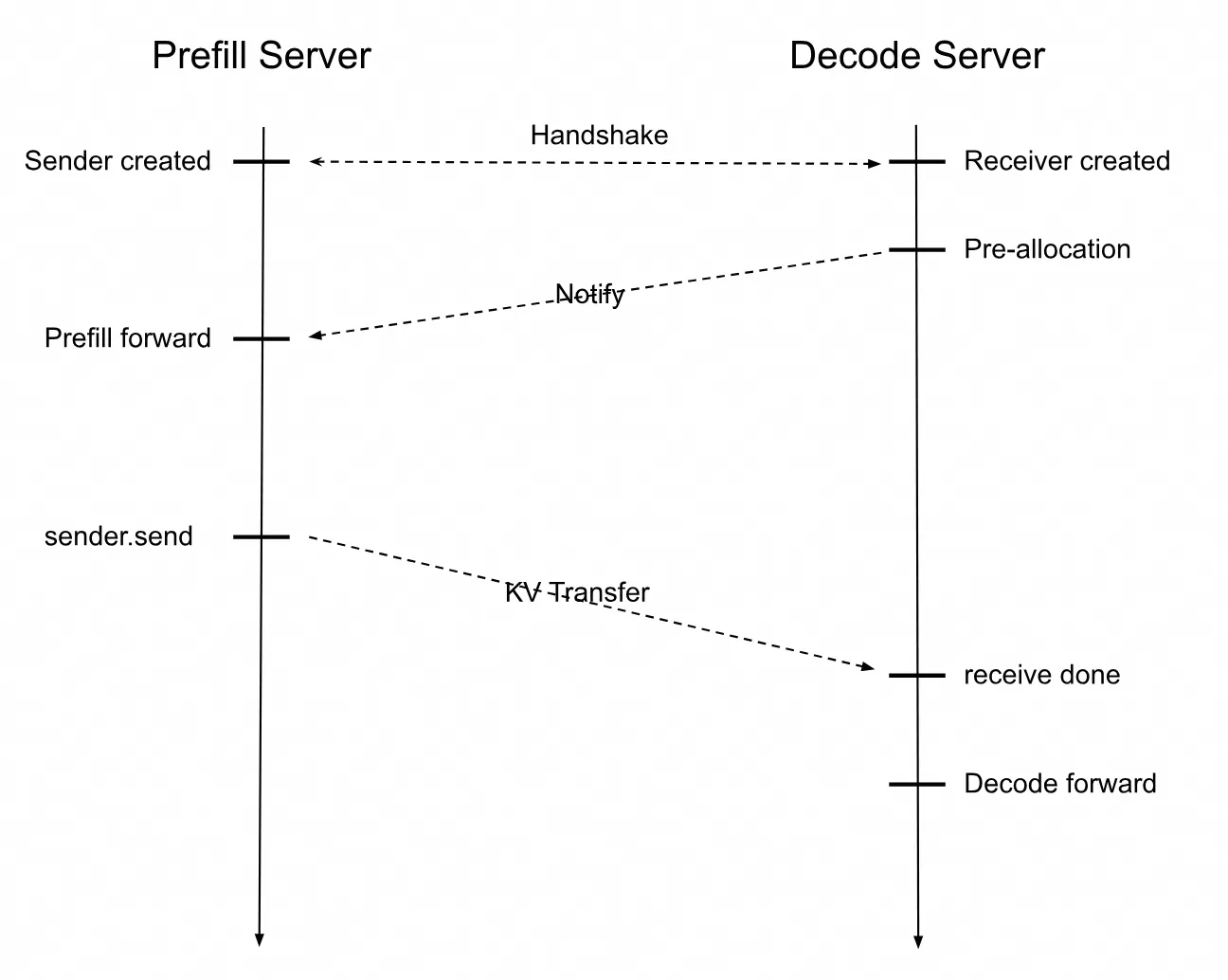
Deploy the inference service with the Prefill-Decode Disaggregation architecture. The figure below shows the interaction sequence diagram for the SGLang Prefill Server and Decode Server.
When the Prefill Server receives a user's inference request, it creates a Sender object, and the Decode Server creates a Receiver object.
The Prefill and Decode servers establish a connection through a handshake. The Decode server first allocates a GPU memory address to receive the KV cache. After the Prefill Server completes its computation, it sends the KV cache to the Decode Server. The Decode Server then uses the received KV cache to compute subsequent tokens until the inference request is complete.
Step 1: Prepare the Qwen3-32B model files
Run the following command to download the Qwen3-32B model from ModelScope.
If the
git-lfsplugin is not installed, runyum install git-lfsorapt-get install git-lfsto install it. For more installation methods, see Installing Git Large File Storage.git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/Qwen3-32B.git cd Qwen3-32B/ git lfs pull
Log on to the OSS console and record the name of your bucket. If you haven't created one, see Create a bucket. Create a directory in Object Storage Service (OSS) and upload the model to it.
For more information about how to install and use ossutil, see Install ossutil.
ossutil mkdir oss://your-bucket-name/Qwen3-32B ossutil cp -r ./Qwen3-32B oss://your-bucket-name/Qwen3-32BCreate a persistent volume (PV) named
llm-modeland a persistent volume claim (PVC) for your cluster. For detailed instructions, see Create a PV and a PVC.
Console
Create a PV
Log on to the ACK console. In the left navigation pane, click Clusters.
On the Clusters page, find the cluster you want and click its name. In the left navigation pane, choose .
On the Persistent Volumes page, click Create in the upper-right corner.
In the Create Persistent Volume dialog box, configure the parameters.
The following table describes the basic configuration for the example PV.
Parameter
Description
PV Type
In this example, select OSS.
Volume Name
In this example, enter llm-model.
Access Certificate
Configure the AccessKey ID and AccessKey secret used to access the OSS bucket.
Bucket ID
Select the OSS bucket you created in the preceding step.
OSS Path
Enter the path where the model is located, such as
/Qwen3-32B.
Create a PVC
On the Clusters page, click the name of the target cluster. In the left-side navigation pane, choose Volumes > Persistent Volume Claims.
On the Persistent Volume Claims page, click Create in the upper-right corner.
On the Create Persistent Volume Claim page, configure the parameters.
The following table describes the basic configuration of the sample PVC.
Parameter | Description |
PVC Type | OSS |
Name | llm-model |
Allocation Mode | Select Existing Volumes. |
Existing Volumes | Click the Select PV link and select the PV you created. |
kubectl
Create an
llm-model.yamlfile. This YAML file contains configurations for a Secret, a static PV, and a static PVC. The following is a sample YAML file.apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: your-oss-ak # The AccessKey ID used to access the OSS bucket. akSecret: your-oss-sk # The AccessKey secret used to access the OSS bucket. --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: your-bucket-name # The bucket name. url: your-bucket-endpoint # The endpoint, such as oss-cn-hangzhou-internal.aliyuncs.com. otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: your-model-path # In this example, the path is /Qwen3-32B/. --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-modelCreate the Secret, static PV, and static PVC.
kubectl create -f llm-model.yaml
Step 2: Deploy the SGLang inference service with Prefill-Decode Disaggregation
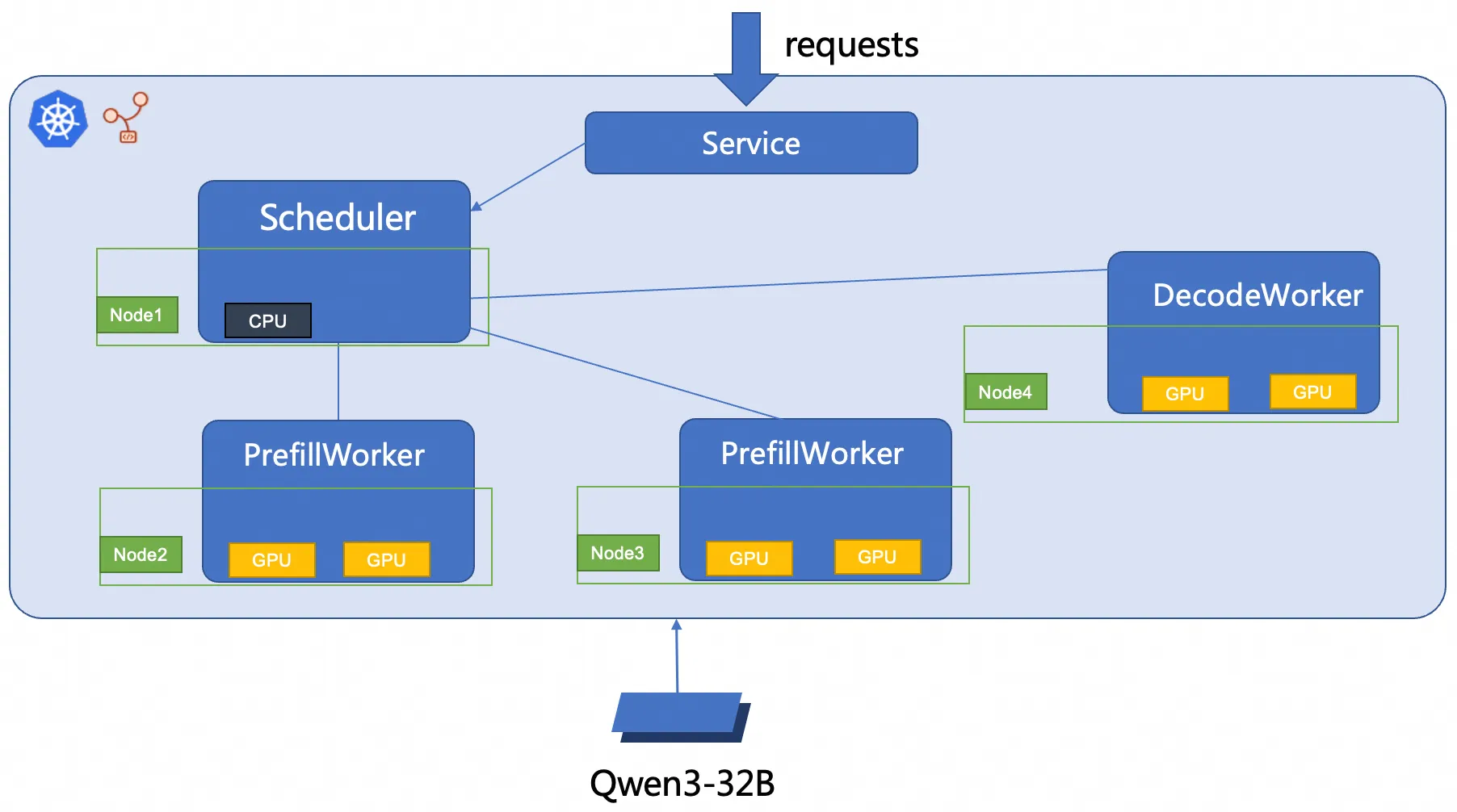
This document uses RBG to deploy a 2P1D (2 Prefill, 1 Decode) SGLang inference service. The figure below shows the deployment architecture.
Create an
sglang_pd.yamlfile.Deploy the SGLang inference service with Prefill-Decode Disaggregation.
kubectl create -f sglang_pd.yaml
Step 3: Verify the inference service
Run the following command to set up port forwarding between the inference service and your local environment.
ImportantPort forwarding established by
kubectl port-forwardlacks production-grade reliability, security, and scalability. It is suitable for development and debugging purposes only and should not be used in production environment. For production-ready network solutions in Kubernetes clusters, see Ingress management.kubectl port-forward svc/sglang-pd 8000:8000Expected output:
Forwarding from 127.0.0.1:8000 -> 8000 Forwarding from [::1]:8000 -> 8000Run the following command to send a sample inference request to the model inference service.
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "/models/Qwen3-32B", "messages": [{"role": "user", "content": "test"}], "max_tokens": 30, "temperature": 0.7, "top_p": 0.9, "seed": 10}'Expected output:
{"id":"29f3fdac693540bfa7808fc1a8701758","object":"chat.completion","created":1753695366,"model":"/models/Qwen3-32B","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\nOkay, the user wants me to do a test. I need to first confirm their specific needs. Maybe they want to test my functions, such as answering questions or generating content.","reasoning_content":null,"tool_calls":null},"logprobs":null,"finish_reason":"length","matched_stop":null}],"usage":{"prompt_tokens":10,"total_tokens":40,"completion_tokens":30,"prompt_tokens_details":null}}This output shows that the model generated a response to the given input.
References
Configure Prometheus monitoring for LLM inference services
In a production environment, monitoring the health and performance of your LLM service is critical for maintaining stability. By integrating with Managed Service for Prometheus, you can collect detailed metrics to:
Detect failures and performance bottlenecks.
Troubleshoot issues with real-time data.
Analyze long-term performance trends to optimize resource allocation.
Accelerate model loading with Fluid distributed caching
Large model files (>10 GB) stored in services like OSS or File Storage NAS can cause slow pod startups (cold starts) due to long download times. Fluid solves this problem by creating a distributed caching layer across your cluster's nodes. This significantly accelerates model loading in two key ways:
Accelerated data throughput: Fluid pools the storage capacity and network bandwidth of all nodes in the cluster. This creates a high-speed, parallel data layer that overcomes the bottleneck of pulling large files from a single remote source.
Reduced I/O latency: By caching model files directly on the compute nodes where they are needed, Fluid provides applications with local, near-instant access to data. This optimized read mechanism eliminates the long delays associated with network I/O.
Implement intelligent routing and traffic management by using Gateway with Inference Extension
ACK Gateway with Inference Extension is a powerful ingress controller built on the Kubernetes Gateway API to simplify and optimize routing for AI/ML workloads. Key features include:
Model-aware load balancing: Provides optimized load balancing policies to ensure efficient distribution of inference requests.
Intelligent model routing: Routes traffic based on the model name in the request payload. This is ideal for managing multiple fine-tuned models (e.g., different LoRA variants) behind a single endpoint or for implementing traffic splitting for canary releases.
Request prioritization: Assigns priority levels to different models, ensuring that requests to your most critical models are processed first, guaranteeing quality of service.