Capacity scheduling lets you define hierarchical resource quotas with guaranteed minimums and flexible maximums, so idle resources can be shared across teams while each team still gets its guaranteed allocation when needed.
The native Kubernetes ResourceQuota enforces fixed resource caps, which often leaves resources idle when some teams use less than their quota. ACK implements capacity scheduling through the scheduling framework extension mechanism, replacing this static model with elastic quota groups: resources are shared when idle and reclaimed automatically when the original owner needs them. This improves overall cluster utilization without compromising resource guarantees.
Prerequisites
Before you begin, ensure that you have:
An ACK managed Pro cluster running Kubernetes 1.20 or later. For upgrade instructions, see Create an ACK managed cluster
Key concepts
ElasticQuotaTree is a CustomResourceDefinition (CRD) that defines a hierarchy of elastic quota groups. Each node in the tree represents a quota boundary. Leaf nodes map to one or more namespaces. Pods in those namespaces are scheduled within the quota limits defined at their leaf node.
The two core fields in each quota node are:
| Field | Meaning |
|---|---|
min | Guaranteed resources. The scheduler always ensures this amount is available to the quota node, reclaiming borrowed resources from other nodes if necessary. |
max | Maximum resources the quota node can use, including idle resources borrowed from other nodes. |
Resource borrowing and reclaiming work as follows:
A pod can be scheduled if the resources it requests, when added to the quota node's current usage, stay within
max.If the quota node's current usage exceeds
min, the excess is borrowed from idle capacity elsewhere in the tree.When another quota node needs its
minresources back, the scheduler selects pods from the borrowing node to evict. The scheduler comprehensively considers factors such as job priority, availability, and creation time when choosing which pods to evict.
Features
Hierarchical quotas: Configure elastic quotas at multiple levels (for example, matching your organization structure). Each leaf node can map to multiple namespaces, but each namespace belongs to only one leaf node.
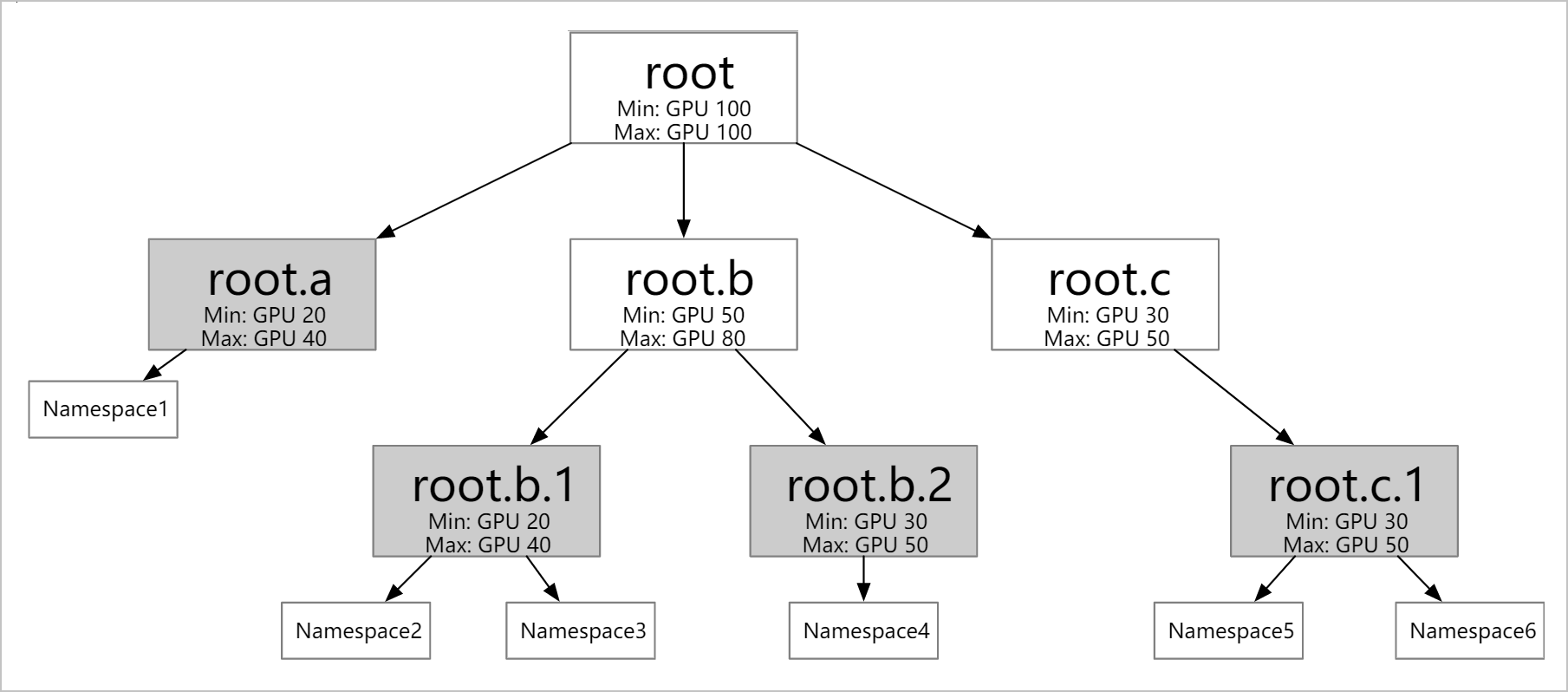
Resource borrowing and reclaiming: Idle
minresources can be borrowed by other quota nodes. Borrowed resources are reclaimed automatically when the original owner needs them.
Extended resource support: In addition to CPU and memory, capacity scheduling supports GPU (
nvidia.com/gpu) and any other Kubernetes-supported resource types.Node affinity via ResourceFlavor: Attach a ResourceFlavor to a quota node to restrict pods in that quota to specific nodes. See ResourceFlavor configuration example.
Configure capacity scheduling
This example uses a cluster with ecs.sn2.13xlarge nodes (56 vCPUs, 224 GiB of memory each).
Step 1: Create namespaces
kubectl create ns namespace1
kubectl create ns namespace2
kubectl create ns namespace3
kubectl create ns namespace4Step 2: Create an ElasticQuotaTree
Create the ElasticQuotaTree in the kube-system namespace. The following example defines a two-level hierarchy with four leaf quota nodes.
ElasticQuotaTree only takes effect when created in the kube-system namespace.apiVersion: scheduling.sigs.k8s.io/v1beta1
kind: ElasticQuotaTree
metadata:
name: elasticquotatree
namespace: kube-system
spec:
root:
name: root
max:
cpu: 40
memory: 40Gi
nvidia.com/gpu: 4
min:
cpu: 40
memory: 40Gi
nvidia.com/gpu: 4
children:
- name: root.a
max:
cpu: 40
memory: 40Gi
nvidia.com/gpu: 4
min:
cpu: 20
memory: 20Gi
nvidia.com/gpu: 2
children:
- name: root.a.1
namespaces:
- namespace1
max:
cpu: 20
memory: 20Gi
nvidia.com/gpu: 2
min:
cpu: 10
memory: 10Gi
nvidia.com/gpu: 1
- name: root.a.2
namespaces:
- namespace2
max:
cpu: 20
memory: 40Gi
nvidia.com/gpu: 2
min:
cpu: 10
memory: 10Gi
nvidia.com/gpu: 1
- name: root.b
max:
cpu: 40
memory: 40Gi
nvidia.com/gpu: 4
min:
cpu: 20
memory: 20Gi
nvidia.com/gpu: 2
children:
- name: root.b.1
namespaces:
- namespace3
max:
cpu: 20
memory: 20Gi
nvidia.com/gpu: 2
min:
cpu: 10
memory: 10Gi
nvidia.com/gpu: 1
- name: root.b.2
namespaces:
- namespace4
max:
cpu: 20
memory: 20Gi
nvidia.com/gpu: 2
min:
cpu: 10
memory: 10Gi
nvidia.com/gpu: 1The ElasticQuotaTree must satisfy all of the following constraints:
Within each quota node:
min≤maxFor each parent node: sum of children's
minvalues ≤ parent'sminvalueFor the root node:
min=max≤ total cluster resourcesEach namespace belongs to exactly one leaf node; a leaf node can contain multiple namespaces
Step 3: Verify the ElasticQuotaTree
kubectl get ElasticQuotaTree -n kube-systemExpected output:
NAME AGE
elasticquotatree 68sObserve resource borrowing and reclaiming
The following scenarios walk through how the scheduler handles borrowing and reclaiming as workloads are deployed across the four namespaces.
ResourceFlavor configuration example
ResourceFlavor is a Kubernetes CRD from the Kueue project. It binds an elastic quota node to specific nodes by matching node labels, so pods in that quota are only scheduled to the matching nodes.
Prerequisites
Before you begin, ensure that you have:
Installed ResourceFlavor by applying the ResourceFlavor CRD. ACK Scheduler does not install it by default
A scheduler version higher than 6.9.0. See the kube-scheduler release notes and Components for upgrade instructions
Only the nodeLabels field is effective in the ResourceFlavor resource.Create a ResourceFlavor
The following example creates a ResourceFlavor named spot that targets nodes with the label instance-type: spot.
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: "spot"
spec:
nodeLabels:
instance-type: spotAssociate a ResourceFlavor with an elastic quota
To bind a ResourceFlavor to a quota node, declare it in the ElasticQuotaTree using the attributes.resourceflavors field.
apiVersion: scheduling.sigs.k8s.io/v1beta1
kind: ElasticQuotaTree
metadata:
name: elasticquotatree
namespace: kube-system
spec:
root:
name: root
max:
cpu: 999900
memory: 400000Gi
nvidia.com/gpu: 100000
min:
cpu: 999900
memory: 400000Gi
nvidia.com/gpu: 100000
children:
- name: child
namespaces:
- default
attributes:
resourceflavors: spot
max:
cpu: 99
memory: 40Gi
nvidia.com/gpu: 10
min:
cpu: 99
memory: 40Gi
nvidia.com/gpu: 10After applying this configuration, pods in the child quota node (namespace default) are only scheduled to nodes with the instance-type: spot label.
What's next
For kube-scheduler release notes, see kube-scheduler.
kube-scheduler also supports gang scheduling, which requires all pods in an associated group to be scheduled at the same time — if any pod cannot be scheduled, none are. This is suited for big data workloads such as Apache Spark and Apache Hadoop. See Work with gang scheduling.