Data Transmission Service (DTS) supports one-way synchronization between Redis databases. This feature is applicable to scenarios such as active geo-redundancy and geo-disaster recovery. This topic describes how to synchronize data from a self-managed Redis database connected over Express Connect, VPN Gateway, or Smart Access Gateway to a self-managed Redis database hosted on an Elastic Compute Service (ECS) instance.
Prerequisites
The version of the source Redis database is 2.8, 3.0, 3.2, 4.0, or 5.0.
NoteThe version of the destination Redis database can be 2.8, 3.0, 3.2, 4.0, or 5.0. The version of the destination database must be the same as or later than that of the source database. If you synchronize data between different versions of Redis databases, make sure that the versions of the source and destination databases are compatible.
The available storage space of the destination Redis database is larger than the total size of the data in the source Redis database.
In scenarios where the source Redis database is deployed in a cluster architecture: All nodes of the Redis cluster support the
PSYNCcommand and share the same password.- The timeout period for data replication between the master and replica nodes in the source instance is specified by the repl-timeout parameter. By default, this parameter is set to 60 seconds. We recommend that you run the
config set repl-timeout 600command to set this parameter to 600 seconds. If the source instance stores a large amount of data, you can increase the value of the repl-timeout parameter based on your business requirements. An account that is used for data synchronization is created in the destination database and configured with a password.
Usage notes
DTS uses the resources of the source and destination instances during initial full data synchronization. This may increase the loads on the database servers. If you synchronize a large volume of data or if the server specifications cannot meet your requirements, database services may become unavailable. Before you synchronize data, evaluate the impact of data synchronization on the performance of the source and destination instances. We recommend that you synchronize data during off-peak hours.
If an expiration policy is enabled for specific keys in the source database, these keys may not be deleted at the earliest opportunity after they expire. Therefore, the number of keys in the destination database may be less than that in the source database. You can run the INFO command to view the number of keys in the destination database.
NoteThe number of keys that do not have the expiration policy enabled or have not expired is the same between the source and destination databases.
- If the
bindparameter is configured in the redis.conf file of the source Redis database, you must set the value of this parameter to the internal IP address of the ECS instance. The setting ensures that DTS can connect to the source database. - To ensure the stability of data synchronization, we recommend that you increase the value of the repl-backlog-size parameter in the
redis.conffile of the source Redis database. - To ensure the synchronization quality, DTS adds the following key to the source Redis database:
DTS_REDIS_TIMESTAMP_HEARTBEAT. This key is used to record the time when data is synchronized to ApsaraDB for Redis. - We recommend that you do not run the
FLUSHDBorFLUSHALLcommand in the source database during data synchronization between Redis clusters. If you run one of the commands in the source database during data synchronization between Redis clusters, data inconsistency may occur between the source Redis database and destination ApsaraDB for Redis instance. By default, the maxmemory-policy parameter that specifies how data is evicted is set to volatile-lru for ApsaraDB for Redis instances. If the destination instance has insufficient memory, data inconsistency may occur between the source and destination instances due to data eviction. In this case, the data synchronization task does not stop running.
To prevent data inconsistency, we recommend that you set maxmemory-policy to noeviction for the destination instance. This way, the data synchronization task fails if the destination instance has insufficient memory, but data loss can be prevented for the destination instance.
NoteFor more information about data eviction policies, see What is the default eviction policy of ApsaraDB for Redis?
- During data synchronization, if the number of shards in the self-managed Redis database is increased or decreased, or if you change the database specifications, such as scaling up the memory capacity, you must reconfigure the data synchronization task. To ensure data consistency, we recommend that you clear the data that has been synchronized to the destination instance before you reconfigure the data synchronization task.
- During data synchronization, if the endpoint of the self-managed Redis database is changed, you must reconfigure the data synchronization task.
Limits on synchronizing data from a standalone ApsaraDB for Redis instance to an ApsaraDB for Redis cluster instance: Each command can be run only on a single slot in an ApsaraDB for Redis cluster instance. If you perform operations on multiple keys in the source database and the keys belong to different slots, the following error occurs:
CROSSSLOT Keys in request don't hash to the same slotWe recommend that you perform operations on only one key during data synchronization. Otherwise, the data synchronization task is interrupted.
If the destination instance is deployed in a cluster architecture and the amount of memory used by a shard in the destination instance reaches the upper limit, or if the available storage space of the destination instance is insufficient, the data synchronization task fails due to out of memory (OOM).
To ensure the synchronization quality, Data Transmission Service (DTS) adds a key prefixed with DTS_REDIS_TIMESTAMP_HEARTBEAT to the source database. This key is used to record the time when data is synchronized to the destination database. If the source database is deployed in a cluster architecture, DTS adds this key to each shard. The key is filtered out during data synchronization. After the data synchronization task is complete, the key expires.
If the source database is a read-only database or the source database account that is used to run the data synchronization task does not have the permissions to run the SETEX command, the reported latency may be inaccurate.
- If the transparent data encryption (TDE) feature is enabled for the destination instance, you cannot use DTS to synchronize data.
Billing
| Synchronization type | Task configuration fee |
| Schema synchronization and full data synchronization | Free of charge. |
| Incremental data synchronization | Charged. For more information, see Billing overview. |
Supported synchronization topologies
- One-way one-to-one synchronization
- One-way one-to-many synchronization
- One-way cascade synchronization
For more information, see Synchronization topologies.
Commands that can be synchronized
- APPEND
- BITOP, BLPOP, BRPOP, and BRPOPLPUSH
- DECR, DECRBY, and DEL
- EVAL, EVALSHA, EXEC, EXPIRE, and EXPIREAT
- GEOADD and GETSET
- HDEL, HINCRBY, HINCRBYFLOAT, HMSET, HSET, and HSETNX
- INCR, INCRBY, and INCRBYFLOAT
- LINSERT, LPOP, LPUSH, LPUSHX, LREM, LSET, and LTRIM
- MOVE, MSET, MSETNX, and MULTI
- PERSIST, PEXPIRE, PEXPIREAT, PFADD, PFMERGE, and PSETEX
- RENAME, RENAMENX, RESTORE, RPOP, RPOPLPUSH, RPUSH, and RPUSHX
- SADD, SDIFFSTORE, SELECT, SET, SETBIT, SETEX, SETNX, SETRANGE, SINTERSTORE, SMOVE, SPOP, SREM, and SUNIONSTORE
- ZADD, ZINCRBY, ZINTERSTORE, ZREM, ZREMRANGEBYLEX, ZUNIONSTORE, ZREMRANGEBYRANK, and ZREMRANGEBYSCORE
- SWAPDB and UNLINK. These two commands can be synchronized only if the engine version of the source database is Redis 4.0.
- The PUBLISH command cannot be synchronized.
- If you run the EVAL or EVALSHA command to call Lua scripts, DTS cannot identify whether these Lua scripts are executed on the destination database. This is because the destination database does not explicitly return the execution results of Lua scripts during incremental data synchronization.
- When DTS runs the SYNC or PSYNC command to transfer data of the LIST type, DTS does not clear the existing data in the destination database. As a result, the destination database may contain duplicate data records.
Procedure
Purchase a data synchronization instance. For more information, see Purchase a data synchronization instance.
NoteOn the buy page, set both the Source Instance and Destination Instance parameters to Redis.
Log on to the DTS console.
NoteIf you are navigated to the DMS console from the DTS console, you can move the pointer over the
 icon in the lower-right corner and click the
icon in the lower-right corner and click the  icon to return to the DTS console.
icon to return to the DTS console. If the new version of the DTS console appears after the logon, you can click the
 icon in the lower-right corner to return to the previous version.
icon in the lower-right corner to return to the previous version.
In the left-side navigation pane, click Data Synchronization.
In the upper part of the Data Synchronization Tasks page, select the region in which the destination instance resides.
Find the data synchronization instance and click Configure Task in the Actions column.
Configure the source and destination Redis database.
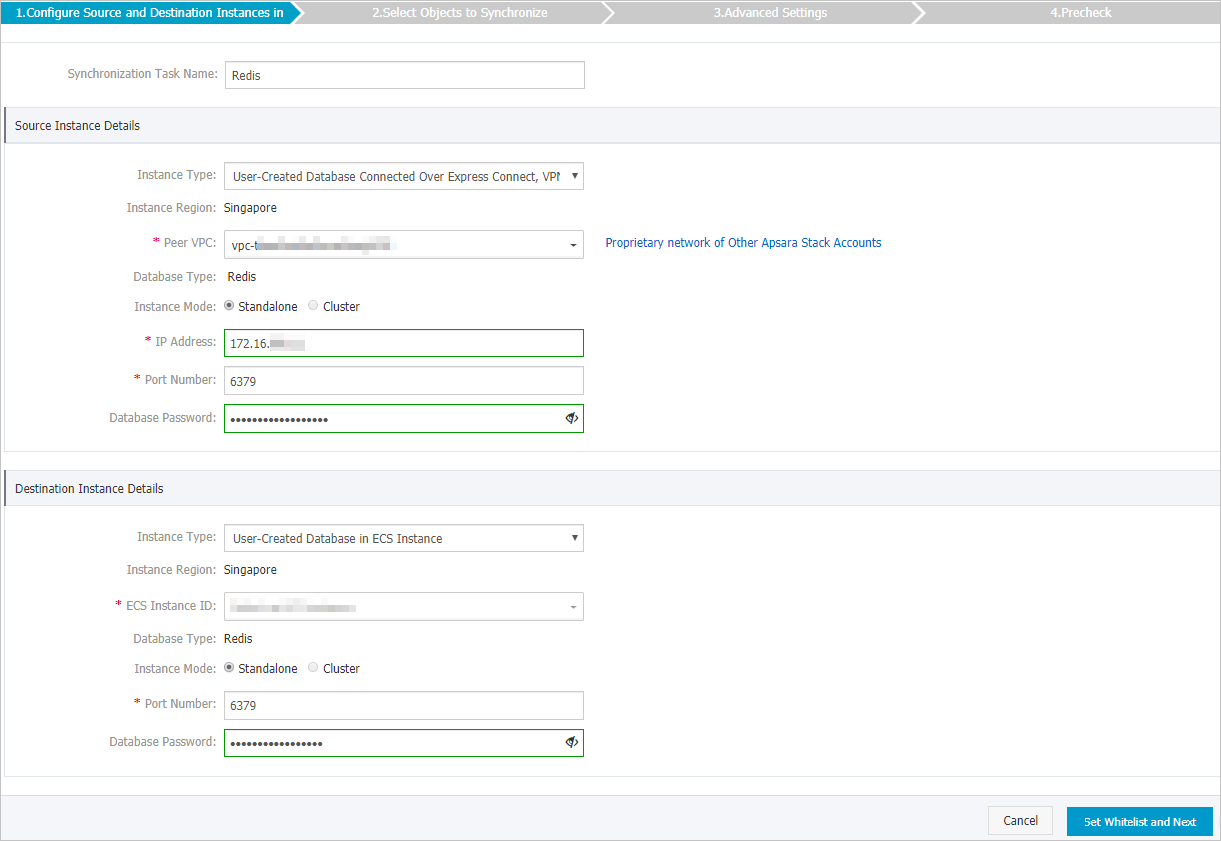
Section
Parameter
Description
N/A
Synchronization Task Name
The task name that DTS automatically generates. We recommend that you specify a descriptive name that makes it easy to identify the task. You do not need to use a unique task name.
Source Instance Details
Instance Type
The access method of the source database. Select User-Created Database Connected Over Express Connect, VPN Gateway, or Smart Access Gateway.
Instance Region
The source region that you selected on the buy page. You cannot change the value of this parameter.
Peer VPC
The ID of the virtual private cloud (VPC) that is connected to the self-managed Redis database.
Database Type
The value of this parameter is set to Redis.
Instance Mode
The architecture of the source Redis database. Select Standalone or Cluster.
IP Address
The server IP address of the source Redis database.
NoteIf the source Redis database is deployed in a cluster architecture, enter the IP address of the server to which a master node belongs.
Port Number
The service port number of the source Redis database. Default value: 6379.
NoteIf the source Redis database is deployed in a cluster architecture, enter the service port number of a master node.
Database Password
The password of the source Redis database.
NoteThis parameter is optional and can be left empty if no database password is set.
Destination Instance Details
Instance Type
The access method of the destination database. Select User-Created Database in ECS Instance.
Instance Region
The destination region that you selected on the buy page. You cannot change the value of this parameter.
ECS Instance ID
The ID of the ECS instance that hosts the destination Redis database.
NoteIf the destination Redis database is deployed in a cluster architecture, select the ID of the ECS instance on which a master node resides.
Instance Mode
The architecture of the destination Redis database. Select Standalone or Cluster.
Port Number
The service port number of the destination Redis database. Default value: 6379.
NoteIf the destination Redis database is deployed in a cluster architecture, enter the service port number of a master node.
Database Password
The password of the destination Redis database.
NoteThis parameter is required. If this parameter is left empty, an error is reported during the precheck.
In the lower-right corner of the page, click Set Whitelist and Next.
NoteYou do not need to modify the security settings for Alibaba Cloud database instances, such as ApsaraDB RDS for MySQL and ApsaraDB for MongoDB, or self-managed databases that are hosted on ECS instances. DTS automatically adds the CIDR blocks of DTS servers to the whitelists of Alibaba Cloud database instances or the security group rules of ECS instances. For more information, see Add the CIDR blocks of DTS servers to the security settings of on-premises databases.
After data synchronization is complete, we recommend that you remove the CIDR blocks of DTS servers from the whitelists or security group rules.
- Select the processing mode of conflicting tables, and the objects to be synchronized.
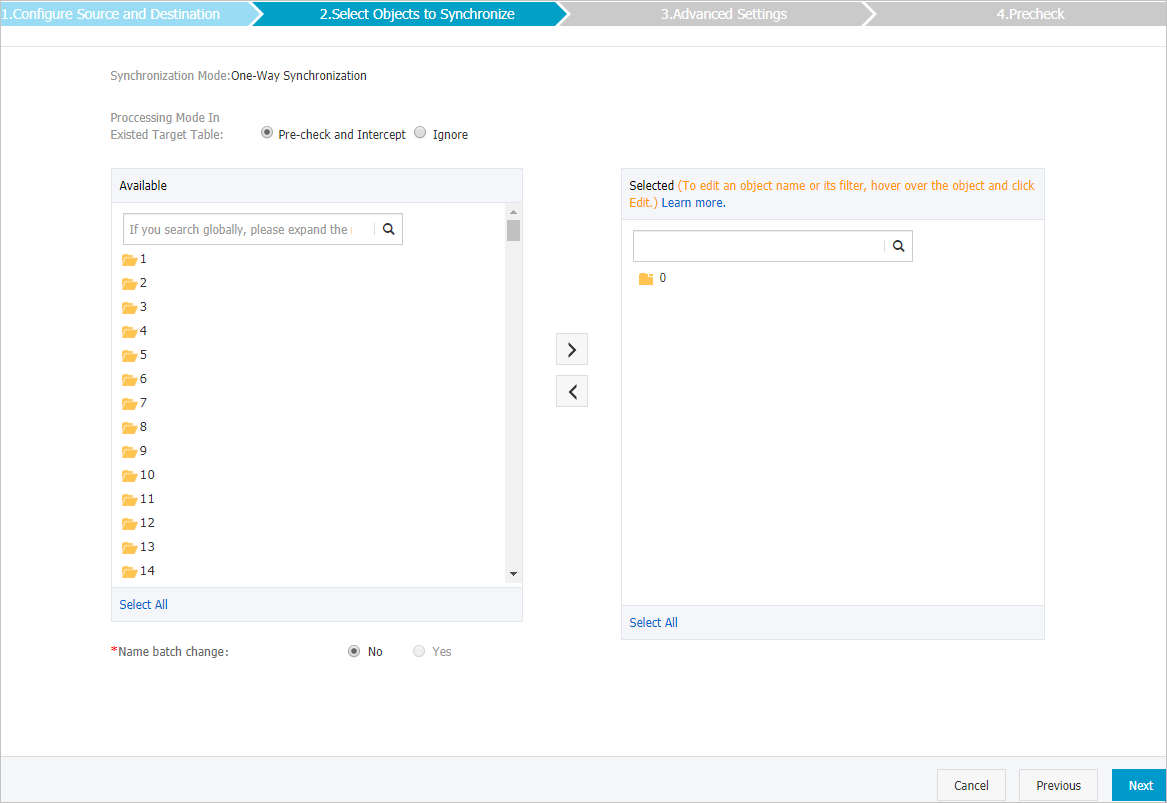
Setting Description Select the processing mode of conflicting tables - Pre-check and Intercept: checks whether the destination instance is empty. If the destination instance is empty, the precheck is passed. If the destination instance is not empty, an error is returned during the precheck, and the data synchronization task cannot be started.
- Ignore: skips the check for empty destination instances. Warning If you select Ignore, data records in the source instance overwrite the data records that have the same keys in the destination instance. Proceed with caution.
Select objects to be synchronized - Select one or more databases from the Available section and click the
 icon to add the databases to the Selected section.
icon to add the databases to the Selected section. - You can select only databases as the objects to be synchronized. You cannot select keys as the objects to be synchronized.
Rename Databases and Tables The objects to be synchronized. In this scenario, you cannot rename the objects. Replicate Temporary Tables When DMS Performs DDL Operations If you use DMS to perform online DDL operations on the source database, you can specify whether to synchronize temporary tables generated by online DDL operations.
Yes: DTS synchronizes the data of temporary tables generated by online DDL operations.
NoteIf online DDL operations generate a large amount of data, the data synchronization task may be delayed.
No: DTS does not synchronize the data of temporary tables generated by online DDL operations. Only the original DDL data of the source database is synchronized.
NoteIf you select No, the tables in the destination database may be locked.
Retry Time for Failed Connections By default, if DTS fails to connect to the source or destination database, DTS retries within the next 720 minutes (12 hours). You can specify the retry time based on your needs. If DTS reconnects to the source and destination databases within the specified time, DTS resumes the data synchronization task. Otherwise, the data synchronization task fails.
NoteWhen DTS retries a connection, you are charged for the DTS instance. We recommend that you specify the retry time based on your business needs. You can also release the DTS instance at your earliest opportunity after the source and destination instances are released.
- In the lower-right corner of the page, click Next.
- Select the initial synchronization types. The value is set to Include full data + incremental data and cannot be changed.
 Note
Note- DTS synchronizes historical data from the source instance to the destination instance. Then, DTS synchronizes incremental data.
- If a version-related error message appears, you can upgrade the source instance to a specified version. For more information about how to upgrade the version, see Upgrade the major version and Update the minor version of an instance.
In the lower-right corner of the page, click Precheck.
NoteBefore you can start the data synchronization task, DTS performs a precheck. You can start the data synchronization task only after the task passes the precheck.
If the task fails to pass the precheck, you can click the
 icon next to each failed item to view details.
icon next to each failed item to view details. You can troubleshoot the issues based on the causes and run a precheck again.
If you do not need to troubleshoot the issues, you can ignore failed items and run a precheck again.
- Close the Precheck dialog box after the The precheck is passed. message is displayed in the Precheck dialog box. Then, the data synchronization task starts.
- Wait until initial synchronization is complete and the data synchronization task enters the Synchronizing state.
 Note You can view the state of the data synchronization task on the Synchronization Tasks page.
Note You can view the state of the data synchronization task on the Synchronization Tasks page.