Abstract: It primarily describes best practices for implementing Flink CDC via YAML in Realtime Compute for Apache Flink and is structured into the following five sections:
- What is Flink CDC YAML
- Flink CDC YAML capabilities
- Flink CDC YAML use cases
- Enterprise-grade Flink CDC YAML features
- Hands-on: Build a Flink CDC YAML data pipeline in 10 minutes using free tier Realtime Compute for Apache Flink
Flink CDC YAML is an easy-to-use data integration API provided by Flink CDC [1]. It enables users to rapidly build a robust data pipeline from a simple YAML file, facilitating real-time sync of data and schema changes from databases to downstream systems, including data warehouses and lakehouses. With Flink CDC YAML, users with minimal coding experience or knowledge of Flink can easily develop data replication and ETL applications, efficiently ingesting data to downstream systems for analytics purposes.

Realtime Compute for Apache Flink allows users to define a Flink CDC job in YAML in the console to effectively sync data in the cloud.
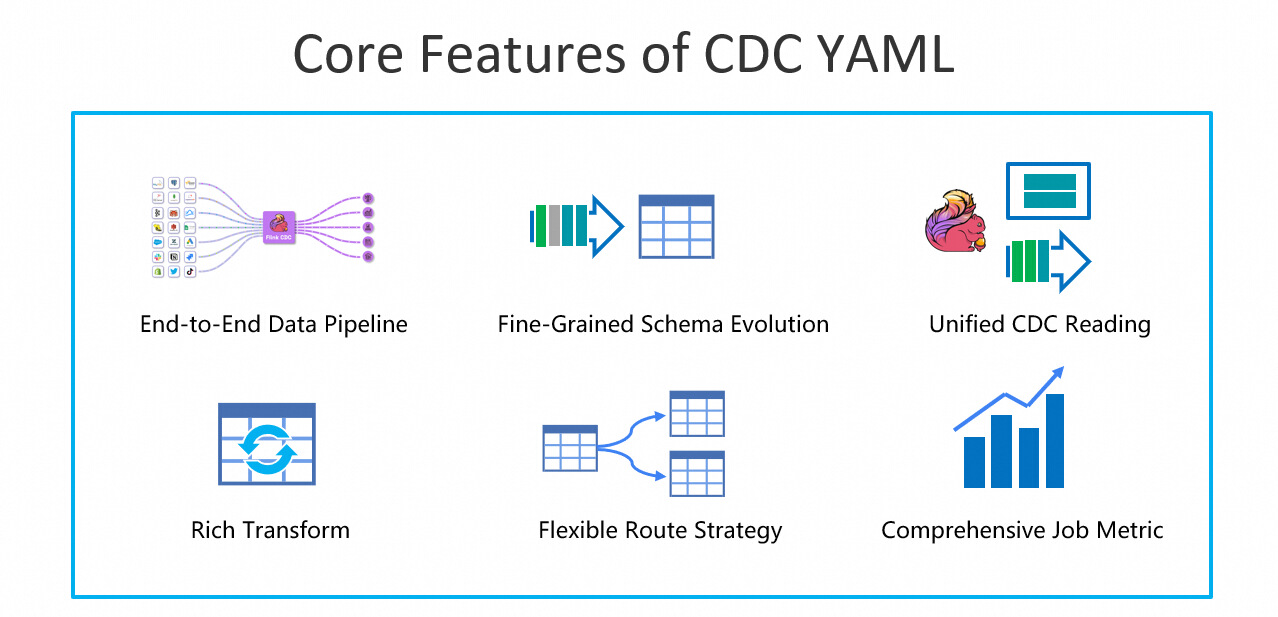
In addition to syncing data across data systems, Flink CDC YAML also supports simple data processing and cleaning. Its key capabilities are as follows:
To meet business needs, Realtime Compute for Apache Flink supports more sources and sinks in Flink CDC YAML jobs, as follows:
| Connector | Source or sink | |
|---|---|---|
| Source | Sink | |
| MySQL | √ | × |
| Kafka | √ | √ |
| Hologres | × | √ |
| Upsert Kafka | × | √ |
| × | √ | |
| StarRocks | × | √ |
| Paimon | × | √ |
Flink offers two levels of APIs for job development: Flink SQL and DataStream API.
The following table compares Flink CDC YAML with Flink SQL:
| Flink CDC YAML | Flink SQL |
|---|---|
| Automatic schema detectionFull database sync | Manual creation of CREATE TABLE and INSERT statements |
| Fine-grained control of schema evolution | Data sync only |
| Support for syncing raw changelog data | Destruction of origional changelog data structure |
| Reads and writes of multiple tables | Reads and writes of a single table |
The following table compares Flink CDC YAML with DataStream API:
| Flink CDC YAML | DataStream API |
|---|---|
| Users of any technical background can easily start using Flink CDC YAML, whether they are seasoned Flink specialists or newcomers | Users need to be familiar with Java and distributed systems |
| Easy development, with underlying technical details hidden from users | Users need to have a solid grasp of Flink |
| Easy to understand and learn YAML | Users need tools like Maven to manage projects and dependencies |
| Easy to reuse existing code | Hard to reuse existing code |
Flink CDC YAML is useful in various scenarios, especially for data sync. Here are some typical use cases:
One of the most typical use cases of Flink CDC YAML is syncing data in full from a database to a lakehouse or warehouse for analytics.
For example, the below YAML file syncs data in the app_db MySQL database to Paimon to quickly build a data lakehouse:
source:
type: mysql
name: MySQL Source
hostname: ${secret_values.mysql-hostname}
port: 3306
username: flink
password: ${secret_values.mysql-password}
tables: app_db.\.*
server-id: 18601-18604
sink:
type: paimon
name: Paimon Sink
catalog.properties.metastore: filesystem
catalog.properties.warehouse: oss://test-bucket/warehouse
catalog.properties.fs.oss.endpoint: oss-cn-beijing-internal.aliyuncs.com
catalog.properties.fs.oss.accessKeyId: ${secret_values.test_ak}
catalog.properties.fs.oss.accessKeySecret: ${secret_values.test_sk}If you need to rename the sink table, or process or filter data during database synchronization, add the transform and route modules.
For example, in the transform module, add a computed column named upper to the app_db.customers table, reference the schema_name metadata column as db. In the route module, suffix version numbers to the three sink tables:
source:
type: mysql
name: MySQL Source
hostname: ${secret_values.mysql-hostname}
port: 3306
username: flink
password: ${secret_values.mysql-password}
tables: app_db.\.*
server-id: 18601-18604
transform:
\- source-table: app_db.customers
projection: \*, UPPER(`name`) AS upper, __schema_name__ AS db
route:
\- source-table: app_db.customers
sink-table: app_db.customers_v1
\- source-table: app_db.products
sink-table: app_db.products_v0
\- source-table: app_db.orders
sink-table: app_db.orders_v0
sink:
type: paimon
name: Paimon Sink
catalog.properties.metastore: filesystem
catalog.properties.warehouse: oss://test-bucket/warehouse
catalog.properties.fs.oss.endpoint: oss-cn-beijing-internal.aliyuncs.com
catalog.properties.fs.oss.accessKeyId: ${secret_values.test_ak}
catalog.properties.fs.oss.accessKeySecret: ${secret_values.test_sk}Flink CDC YAML offers a variety of built-in functions, and supports UDFs for complex data processing tasks.
Flink CDC YAML is also compatible with most Flink SQL UDFs, which can be used directly in the script development.
To handle highly concurrent, data-intensive workloads, users may choose to split a whole table in a database into shards and store them across databases. To facilitate data analytics, users want to merge these shards into a single table in the data lakehouse.
Assume there are three tables in the app_db database: customers_v0, customers_v1, and customers_v2. The following YAML file merges these tables into a table named customers, syncing all data to it:
source:
type: mysql
name: MySQL Source
hostname: ${secret_values.mysql-hostname}
port: 3306
username: flink
password: ${secret_values.mysql-password}
tables: app_db.customers\.*
server-id: 18601-18604
route:
\- source-table: app_db.customers\.*
sink-table: app_db.customers
sink:
type: paimon
name: Paimon Sink
catalog.properties.metastore: filesystem
catalog.properties.warehouse: oss://test-bucket/warehouse
catalog.properties.fs.oss.endpoint: oss-cn-beijing-internal.aliyuncs.com
catalog.properties.fs.oss.accessKeyId: ${secret_values.test_ak}
catalog.properties.fs.oss.accessKeySecret: ${secret_values.test_sk}In addition to the need for a full data load, users sometimes require raw changelog data rather than just the changed data. In this case, sync the binary log to Kafka is an efficient approach, as it alleviates the bottleneck of reading thebinary log, thereby speeding up data consumption. Subsequently, binary log entries stored in Kafka can be used for data replay, auditing, or real-time monitoring and alerting of certain changes.
In Flink SQL, CDC data is transmitted in the RowData structure, which breaks down a change into separate events. For example, an update is divided into two messages: update before and update after. This segmentation makes it impossible to replicate raw binlog entries. Flink CDC YAML uses SchemaChangeEvent and DataChangeEvent for binary log sync, preserving the integrity of changelog entries while streaming them to Kafka.
The following YAML script syncs the binary log of the app_db MySQL database to Kafka, with changes to the customers, products, and shipments tables being streamed to the respective Kafka topics.
source:
type: mysql
name: MySQL Source
hostname: ${secret_values.mysql-hostname}
port: 3306
username: flink
password: ${secret_values.mysql-password}
tables: app_db.\.*
server-id: 18601-18604
metadata-column.include-list: op_ts
sink:
type: Kafka
name: Kafka Sink
properties.bootstrap.servers: ${secret_values.bootstraps-server}
properties.enable.idempotence: falseMessages emitted from the Kafka sink are stored in either the Debezium JSON format (default) or the Canal JSON format. If you use Debezium or Canal for change data capture, you can seamlessly transition to Flink CDC YAML without modifying the logic of the downstream consumer.
Here's an UPDATE message formatted in Debezium JSON:
{
"before": {
"id": 4,
"name": "John",
"address": "New York",
"phone_number": "2222",
"age": 12
},
"after": {
"id": 4,
"name": "John",
"address": "New York",
"phone_number": "1234",
"age": 12
},
"op": "u",
"source": {
"db": null,
"table": "customers",
"ts_ms": 1728528674000
}
}Here's an UPDATE message formatted in Canal JSON:
{
"old": [
{
"id": 4,
"name": "John",
"address": "New York",
"phone_number": "2222",
"age": 12
}
],
"data": [
{
"id": 4,
"name": "John",
"address": "New York",
"phone_number": "1234",
"age": 12
}
],
"type": "UPDATE",
"database": null,
"table": "customers",
"pkNames": [
"id"
],
"ts": 1728528674000
}Flink CDC YAML supports synchronizing schema changes to a downstream system, such as creating a table, adding a column, renaming a column, changing a column type, dropping a column, and dropping a table. However, the downstream system may not support all these types of changes. For example, when users want to keep all historical data, destructive changes like DELETE or TRUNCATE are not expected.
To accommodate various use cases, Flink CDC YAML offers the following policies:
In addition to the above behaviors, Flink CDC YAML allows users to implement finer-grained control by setting the include.schema.changes and exclude.schema.changes options in the sink block.
The following YAML script enables the EVOLVE mode, syncing all schema changes while ignoring operations that drop tables, truncate tables, or drop columns:
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: holo_test.\.*
server-id: 8601-8604
sink:
type: hologres
name: Hologres Sink
endpoint: ****.hologres.aliyuncs.com:80
dbname: cdcyaml_test
username: ${secret_values.holo-username}
password: ${secret_values.holo-password}
sink.type-normalize-strategy: BROADEN
exclude.schema.changes: [drop, truncate.table]
pipeline:
name: MySQL to Hologres yaml job
schema.change.behavior: EVOLVECompared to data changes, schema changes generally take more time to replicate. This is because for concurrent workloads, it's safe to wait for all data to be written to a downstream system before performing schema changes. Moreover, the downstream sink may not support all schema changes.
In Realtime Compute for Apache Flink, to process schema change events more tolerantly, Flink CDC YAML supports lenient sync in the Hologres sink. To resolve the challenge that Hologres does not accommodate changes to column types, Flink CDC YAML supports the conversion of multiple MySQL data types to wider Hologres types. This approach skips unnecessary type changes, ensuring smooth job running. You can modify the type mapping policy via the sink.type-normalize-strategy option.
In the following YAML configuration script, the sink.type-normalize-strategy option is set to ONLY_BIGINT_OR_TEXT, which converts any MySQL data type to either an INT8 or TEXT in Hologres. For example, if a MySQL data type is changed from INT to BIGINT, the Hologres connector maps both to INT8, without throwing any error.
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: holo_test.\.*
server-id: 8601-8604
sink:
type: hologres
name: Hologres Sink
endpoint: ****.hologres.aliyuncs.com:80
dbname: cdcyaml_test
username: ${secret_values.holo-username}
password: ${secret_values.holo-password}
sink.type-normalize-strategy: ONLY_BIGINT_OR_TEXTAt Flink CDC job startup, there is a list of tables to be captured. At a later point in time when new business modules (membership or points system, etc.) are added, new tables are added to the captured table list; existing tables initially not part of the captured table list may also become necessary to capture.
A running Flink CDC job defined in YAML indistinguishably detects these as new tables, but requires different configurations to capture them:
A running Flink CDC job defined in YAML may exit unexpectedly due to binary log expiration or code parsing errors. These issues may prevent the job from resuming from the binary log position where it left off.
To resolve this, Flink CDC YAML provides the capability to recover from a specific position. This approach, combined with necessary data corrections, enables a Flink CDC job to resume its execution seamlessly.
In addition to the capabilities of open-source Flink CDC, Realtime Compute for Apache Flink supports the following advanced Flink CDC features, helping enterprises effectively process real-time data in the cloud.
The open-source MySQL CDC connector consumes the binary log with a parallelism of 1. To alleviate this bottleneck, Realtime Compute for Apache Flink optimizes the MySQL CDC connector in the following aspects:
Compared to open-source Flink CDC, if the binary log contains changes to a single table, the enterprise-grade Flink CDC job defined in YAML can improve performance by 80% in general; If the binary log records changes to multiple tables but only some tables need to replicate, the performance boost is about 1000%.
A MySQL database maintains only one copy of active binary logs at a given time. If data is updated very frequently, Flink may struggle to consume change events at the same rate as they are produced. Consequently, if a job fails after older binary log files have been purged, it may not be able to resume from the last binary log position it processed.
An ApsaraDB RDS for MySQL instance can send binary logs to OSS, allowing a Flink job to resume from archived binary logs. When processing events from an ApsaraDB RDS for MySQL instance, Flink dynamically retrieves binary logs from either OSS or the database. If a specific timestamp or position is found in the OSS binary log, Flink pulls the relevant binary log into the Flink cluster for processing. If a specific timestamp or position is identified in the database's binary log file, Flink will consume events directly from the database. This approach effectively addresses the challenges of job reruns and data inconsistencies that arise from binary log expiration.
Realtime Compute for Apache Flink offers diverse monitoring metrics to help users determine the progress and status of a Flink CDC job. The metrics are as follows:
In this section, you will be guided to build a data pipeline in YAML from MySQL to Paimon using Alibaba Cloud services on free tier [3], including Realtime Compute for Apache Flink.
Before you start, you need to create an ApsaraDB RDS for MySQL instance, a Realtime Compute for Apache Flink workspace, and an OSS bucket.
OSS is used as the storage component of the data lake. It's also used to store Flink checkpoint data.
Go to Alibaba Cloud Free Trial.
Enter "Object Storage Service" in the search box and click Try Now.

After your application is approved, go to the OSS console, and create a bucket in the Singapore region. Choose the OSS bucket you created. Go to Object Management > Objects, and create a directory named "warehouse" to store data.
You need an ApsaraDB RDS for MySQL instance as the data source.
Enter "ApsaraDB RDS for MySQL" in the search box, and click Try Now.

After the free trial application is approved, go to the ApsaraDB for RDS console, and create an ApsaraDB RDS for MySQL instance in the China (Hangzhou) region.
Click the instance you created. Choose Accounts in the left-side navigation pane, and create a privileged account.
Choose Databases in the left-side navigation pane and create a test database.
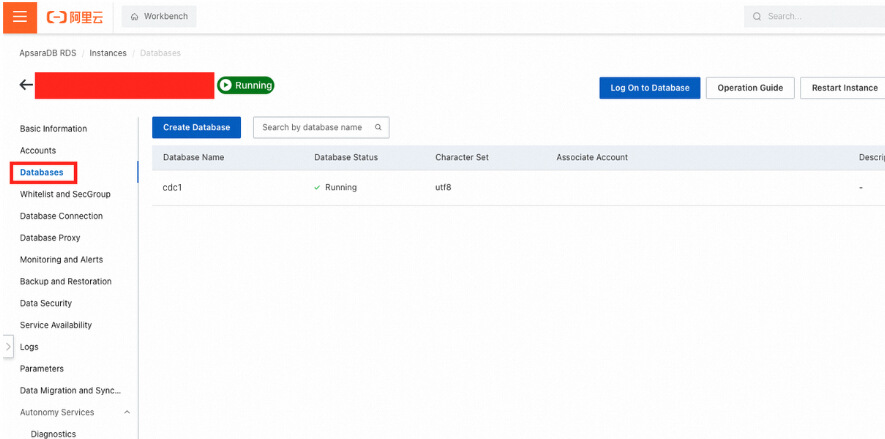
Click Log On to Database, and log on with the account you created. Create the products and users tables, and insert five rows into the tables.

Return to the instance page. In the left-side navigation pane, click Whitelist and SecGroup. Then, click All IP Addresses. Note that this configuration has been used to serve test purposes. Make sure you properly configure the IP whitelist in your production environment for security.
On the Free Trial page, enter "flink" in the search box, and click Try Now.
After you have finished RAM authorizations, create a Flink workspace in the same zone within the China (Hangzhou) region as your ApsaraDB RDS for MySQL instance.
An AccessKey pair is required to allow Paimon to access OSS. For information about how to create one, see Create an AccessKey pair[4].
Now you're ready to build a data pipeline from MySQL to Paimon using Flink CDC YAML.
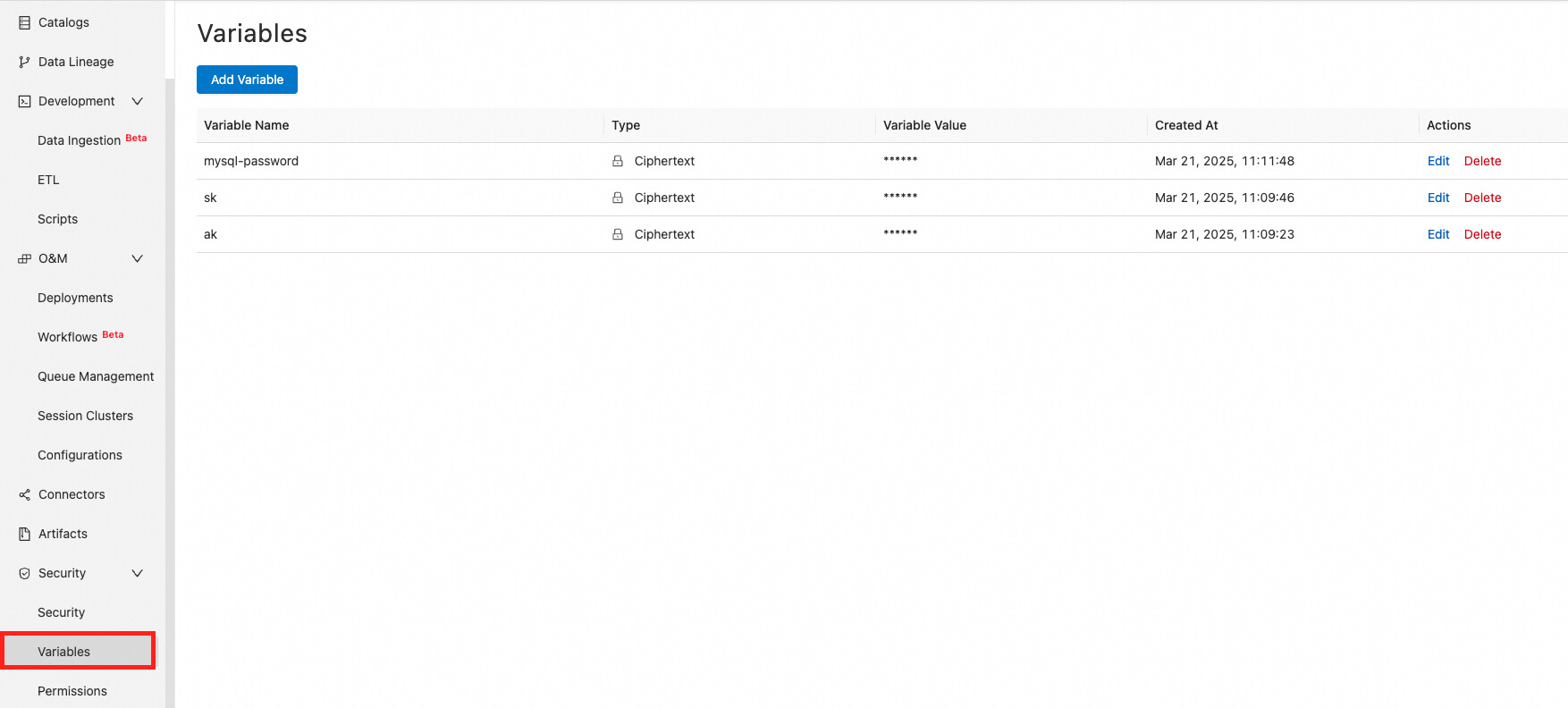
In the Realtime Compute for Apache Flink development console, go to Security > Variables. For data security, use variables instead of plaintext credentials.
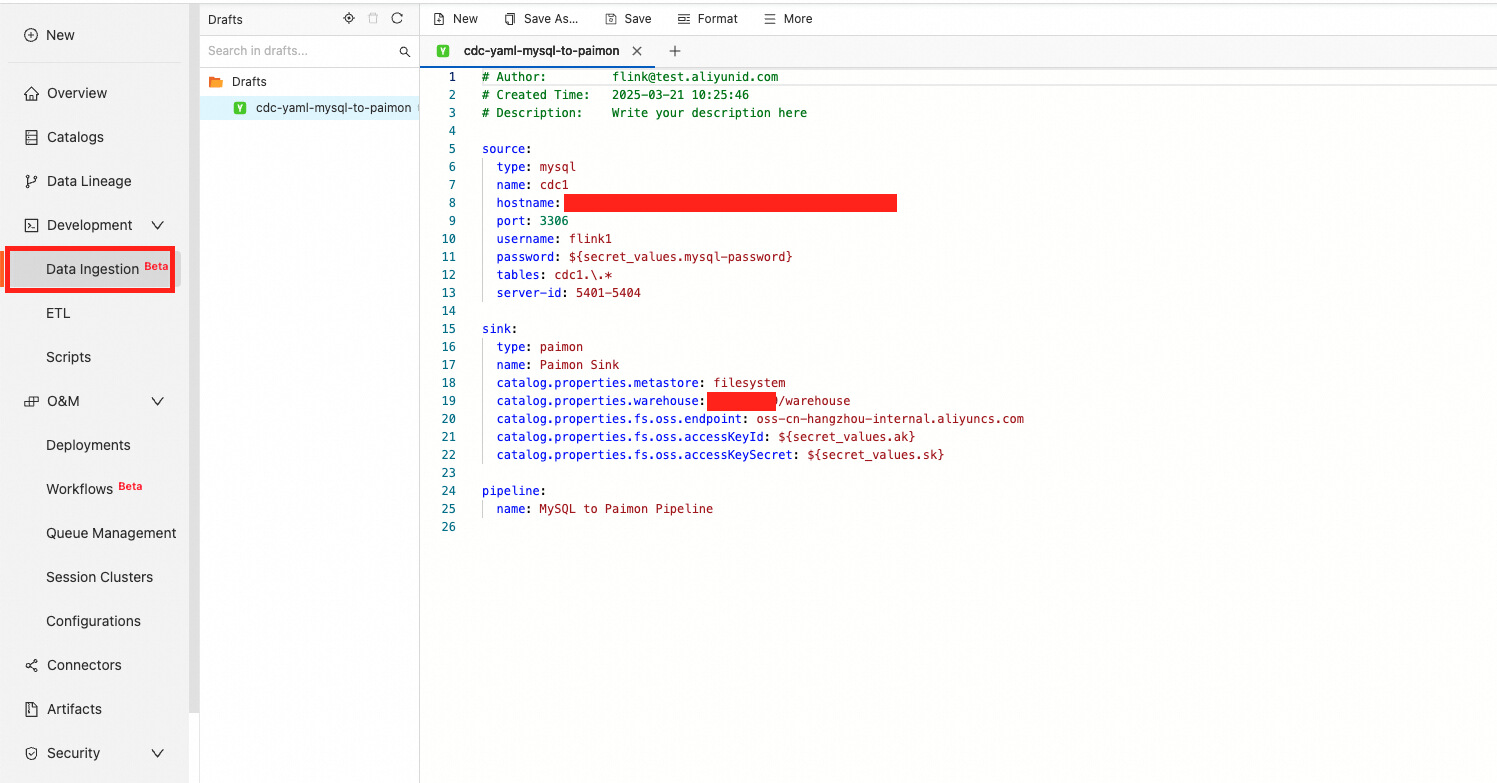
After you've configured variables, go to Development > Data Ingestion. Click New to create a data ingestion draft, write code, and deploy the draft.
Go to O&M > Deployments. Find the deployment you created, and start it.
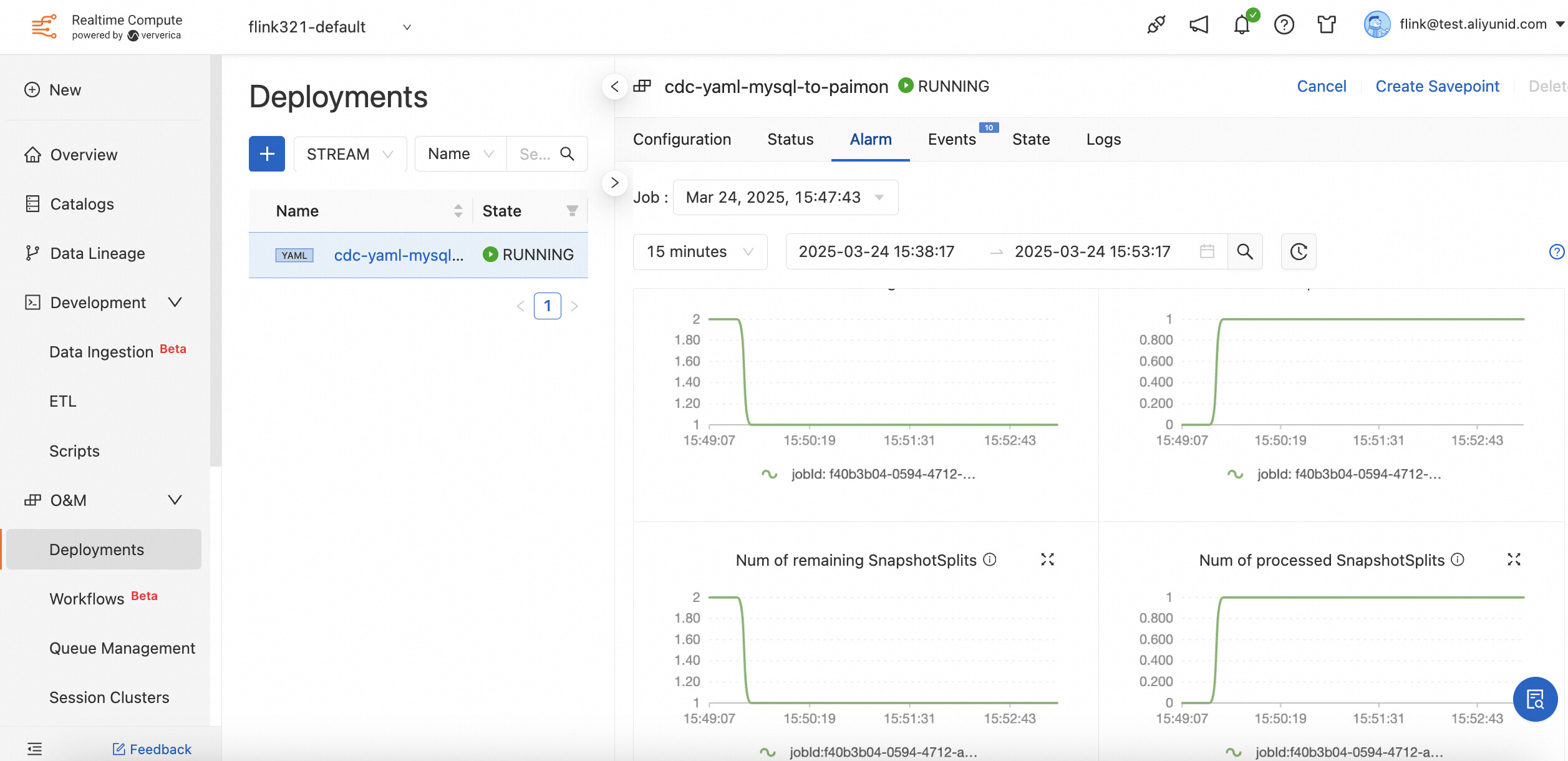
After the deployment starts, click the deployment, and switch to the Alarm tab. Expand the Data Ingestion section, and you can see the job's progress. The following figures show that the job has entered the incremental phase, two tables and shards have been replicated, and five rows in each table have been synced in the snapshot phase.
To query the test data, follow these steps:
To start with, go to Catalogs, and create a Paimon catalog.

Then, create a session cluster, choosing an engine version that supports data ingestion.
Go to Development > ETL. Create a new draft, and use a SELECT statement to query data. Click Debug. In the pop-up dialog box, choose the session cluster you just created from the Session Cluster dropdown list, and click Next and then Confirm. The results are displayed.

Now you've built a CDC data pipeline in YAML from MySQL to Paimon and queried the transferred data. Next, you can update data in your ApsaraDB RDS for MySQL instance, and re-execute the SELECT statement in the Flink console to query updates synced to Paimon.
[1] https://nightlies.apache.org/flink/flink-cdc-docs-stable/
[3] https://www.alibabacloud.com/en/free
[4] https://www.alibabacloud.com/help/en/ram/user-guide/create-an-accesskey-pair
Flash: A Next-gen Vectorized Stream Processing Engine Compatible with Apache Flink
Apache Flink FLIP-3: Developer-Friendly Documentation Redesign for Better Learning Experience

207 posts | 58 followers
FollowApache Flink Community - August 14, 2025
Apache Flink Community - March 14, 2025
Alibaba Cloud Community - January 4, 2026
Apache Flink Community - May 9, 2025
Alibaba Cloud Indonesia - March 23, 2023
Apache Flink Community - May 28, 2024
207 posts | 58 followers
Follow Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More .COM Domain
.COM Domain
Limited Offer! Only $4.90/1st Year for New Users.
Learn More API Gateway
API Gateway
API Gateway provides you with high-performance and high-availability API hosting services to deploy and release your APIs on Alibaba Cloud products.
Learn More Message Queue for Apache Kafka
Message Queue for Apache Kafka
A fully-managed Apache Kafka service to help you quickly build data pipelines for your big data analytics.
Learn MoreMore Posts by Apache Flink Community

