
Not long ago, we were invited to the Percona Live 2016 meeting in the USA to share our recent findings on MySQL replication, which is InnoDB-based physical replication. Many friends sent private messages to me after the meeting to complain that the slides I presented focused too much on kernel and were difficult to understand. Therefore, I write this article to further illustrate the content that I shared, hoping that it will help you better understand the content.
Background Knowledge
Before we start, you need to have a basic understanding of the event system of InnoDB. If you have no idea about it, you can read my previous articles on InnoDB, including the transaction subsystem, transaction lock, redo log, undo log, and crash recovery logic of InnoDB. Here, I would like to brief you on some basic concepts:
Transaction ID: It is a sequence number that increases automatically. Each time a read/write transaction is started (or a transaction is converted from the read-only mode to the read/write mode), a new transaction ID greater than the previous one by 1 is assigned to the transaction. After 256 transaction IDs are assigned, the transactions are permanently recorded on the transaction system page of Ibdata.
Each read/write transaction must have a unique transaction ID.
Read View: In InnoDB, a snapshot used for consistent read is called a read view. When consistent read is required, a read view is started to take a snapshot of the current transaction status, including the ID of the active transaction and the high and low watermark values of the ID, to help check data visibility.
Redo Log: It is used to record changes to physical files. All changes to InnoDB physical files must be protected using redo logs to facilitate crash recovery.
Mini Transaction (MTR): It is the minimum atomic operation unit for modifying physical blocks in InnoDB. It is also responsible for generating local redo logs and copying the logs to the global log buffer when committing MTRs.
LSN: It is an ever-increasing log sequence number. In InnoDB, it indicates the total number of logs that have been generated since instance installation. You can leverage the LSN to locate a log in a log file. When a block writes a disk, the last modified LSN is written as well. In this case, the logs generated before the log corresponding to the LSN need not be applied in case of crash recovery.
Undo Log: It is used to store original logs before they are modified. If a log is modified multiple times, a log version chain is generated. The original logs are retained for repeatable read. Along with read view control, undo logs can be used to implement multiversion concurrency control (MVCC) in InnoDB.
Binary Log: It is a unified log format built upon a storage engine. Binary logs record executed SQL statements or modified rows. Basically, a binary log is a logical log. Therefore, it is applicable to all storage engine for data replication.
Advantages and Disadvantages of Native Replication
Two logs must be maintained for each MySQL read/write transaction, including a redo log and a binary log. MySQL uses a two-phase commit protocol. Therefore, transaction persistency is complete only when both the redo and binary log are written to a disk. If only the redo of a transaction is written, the transaction must be rolled back during crash recovery. MySQL uses an XID to associate a transaction and a binary log in InnoDB.
There are significant advantages of native transaction log
replication by MySQL:
First,
compared with redo logs of InnoDB,
binary logs, which record row-level modification, are more readable and sophisticated
binary log parsing tools are available. We can parse binary
logs
and convert them into DML statements to
synchronize data updates to heterogeneous databases. In addition, we can use binary logs to disable front-end caches.
In fact, binary log–based data
flow services are widely used across Alibaba and serve as its most important
infrastructure.
Second, because binary log features a unified log format, it allows you to adopt different storage engines for the master and slave databases. For example, if you need to test a new type of storage engine, you can set up a slave database, run the alter command to apply the new engine to all tables, start data replication, and observe the process.
Moreover, you can build a highly complex replication topology based on binary logs. This advantage is even more significant after GTID is introduced. With an appropriate design, you can create a extremely complex data replication structure, or even a structure that allows data writing at multiple points. Generally speaking, binary log is quite flexible.
Nevertheless, such a log structure may cause some issues. First, MySQL must generate two logs for each transaction, including a redo log and a binary log. Transaction persistency is complete only when both logs are written to a disk using the fsync method. As we all know, that execution of the fsync method requires many resources. Writing a greater number of logs also increases the disk I/O workload. These two issues will affect the response delay and throughput.
Binary log replication also causes a replication delay. We understand that logs are written to binary log files and transferred to the slave database only after transactions are committed to the master database. This means that the slave database needs to wait at least the time taken to execute a transaction. In addition, execution of some operations such as DDL statement and large transaction execution takes a long time. Such an operation will occupy a worker thread for a long time so as to ensure transaction integrity on the slave database. In this case, when the coordinator reaches a synchronization point, it is unable to distribute synchronization tasks to the threads even though they are idle.
Native replication of MySQL is a critical component of the MySQL ecosystem. The provider of MySQL is proactively improving its features. For example, MySQL 5.7 offers much better native replication performance.
Why Phsyical Replication
Now that native replication is sophisticated and advantageous, why physical replication?
The most important reason is performance. With physical replication, we can disable binary log and GTID to greatly reduce the disk writing workload. In this case, calling the fsync method only once can complete transaction persistency. This will significantly improve the overall throughput and response delay.
In addition, it offers better physical replication performance. The redo logs generated during transaction execution can be transferred to the slave database as long as they are written to files. This means that transactions can be executed on the master and slave databases at the same time, and the slave database does not need to wait until transaction execution is complete on the master database.
Concurrent execution can be implemented based on space_id and page_no. Changes made on the same page can be combined and written as a whole for better concurrent processing. Most importantly, physical replication can maximize data consistency between the master and slave databases.
Of course, physical replication is not a silver bullet. This feature supports only the InnoDB storage engine. With this feature, it would be difficult to design a replication topology that allows multiple writing points. Physical replication cannot replace native replication. It is dedicated to special scenarios, such as the scenario where high concurrent DML processing performance is required.
Therefore, pay attention to the following prerequisites before implementing physical replication: 1. The master database must not have any limits. 2. On the slave database, only query operations can be performed and data cannot be changed using user interfaces.
The following description is made based on MySQL with the following features:
Physical replication and native replication use similar basic architectures with independent code. See the figure below:
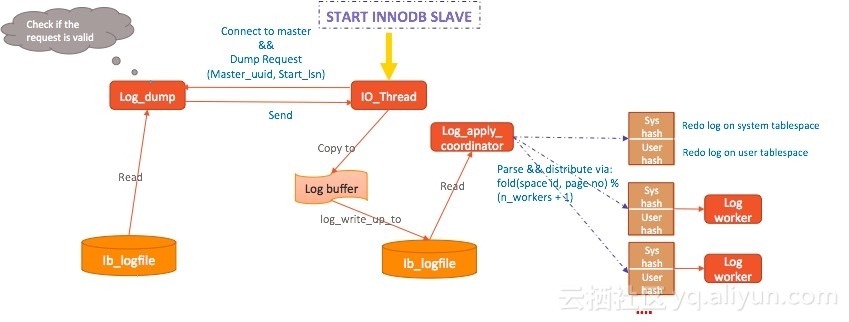
Configure a connection on the slave database and run START INNODB SLAVE. The slave database then starts an I/O thread and InnoDB starts one Log Apply coordinator and multiple worker threads.
The I/O thread sets up a connection to the
master database and sends a dump
request to the master database. The request includes the following content:
master_uuid: server_uuid of the slave
database instance where the initial log is generated recently
start_lsn: point where replication begins
On the master database, a log_dump thread is created. It checks whether the dump request is valid. If yes, it reads logs from the local ib_logfile file and sends the logs to the slave database.
When receiving the logs, the I/O thread of the slave database copies them to the log buffer of InnoDB, and calls log_write_up_to to write the logs to the local ib_logfile file.
The Log Apply coordinator is waked up. It reads the logs from the file, parses the logs, and distributes the logs according to fold(space id ,page no)% (n_workers + 1). System tablespace changes are recorded using the sys hash, while user tablespace changes are recorded using the user hash. After parsing and distributing the logs, the coordinator also helps apply the logs.
Logs are applied first to the system tablespace and then the user tablespace. This is because we must ensure that undo logs are applied with top priority. Otherwise, when an external B-Tree for query user tables tries to use the rollback segment pointer to query undo pages, the undo pages may not be ready yet.
Log File Management
To implement the above-mentioned architecture, InnoDB log files must be rearranged In the logic of native replication, InnoDB writes files in a circular manner. For example, if innodb_log_files_in_group is set to 4, four ib logfile files will be created. When the four files are full, data is written to the first file again. According to the architecture of physical replication, however, the old files must be retained so that they can be used to address network issues. Logs can be used for the backup purpose even though they have not been transferred to the slave database in a timely manner.
A logic similar to the binary log writing logic is adopted, so that when the current log file is full, a new file is generated, and the ID of the new file is greater than the ID of the previous file by 1. To use this logic, the negative impacts of file switchovers on performance must be minimized. To achieve this effect, we introduce independent background threads and allow reuse of cleared files.
We
need to clear log files that are no longer required, just like clearing binary logs. An interface can be provided for manually clearing log
files, while a background thread can be provided for automatically checking for
and clearing log files. Both means must meet the following requirements:
1. It
is not allowed to clear files outside the current checkpoint.
2. If
there is a slave database connecting to the master database, log files that
have not been sent to the slave database cannot be cleared.
The following figure shows the file
architecture:
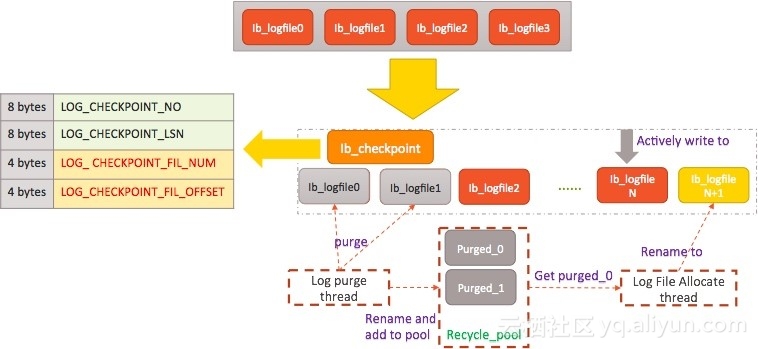
Here, we add a new file ib_checkpoint, because in the logic of native replication, checkpoint information is stored in the ib_logfile0 file, while in the new architecture, the file may be deleted and we need to store the checkpoint in another way. The stored information includes the checkpoint number and checkpoint LSN, as well as the ID of the log file where the LSN resides and the LSN offset in the file.
The background clearing thread is named log purge thread. When being waked up and used to clear log files, it renames the target log file using the prefix purged and stores the renamed file to a recycle pool. If the pool is full, it deletes the log file.
To prevent performance variation during file switchovers for log storage, the log file allocate background thread prepares a file in advance. That is, when file X is being written, the thread is waked up to create file X+1. In this case, a front-end thread only needs to close and open files.
When the log file allocate thread is preparing a file, it first tries to obtain the file from the recycle pool and checks the file to verify that the block number converted from the LSN of the file is not in conflict with file content. If such a file is available, the thread directly obtains the file and renames it to create a new file. If no such files are available in the recycle pool, the thread creates a file and runs the extend command to resize it as required. In this way, we minimize performance variation.
Instance Role
For physical replication, changing data in the slave database is not allowed, which is allowed for native replication, regardless of whether such changes are caused by a database restart or crash. Changes may only result from failovers. A slave database is not converted into a master database when it is restarted.
The server where logs are first generated is called the log source instance. Logs may be transferred through a complex topology to cascading instances. All the slave databases must share the same source instance information. We need to check this information to determine whether a dump request is valid. For example, for a slave database, all dump logs must be generated by the same log source instance, unless a failover occurs in the replication topology.
We have defined three instance states, namely master, slave, and upgradable-slave, where the third is an intermediate state used only when a failover occurs.
Information about these states are stored in the innodb_repl.info file for persistency. In addition, server_uuid of a log source instance is stored separately.
The following figure provides an example:
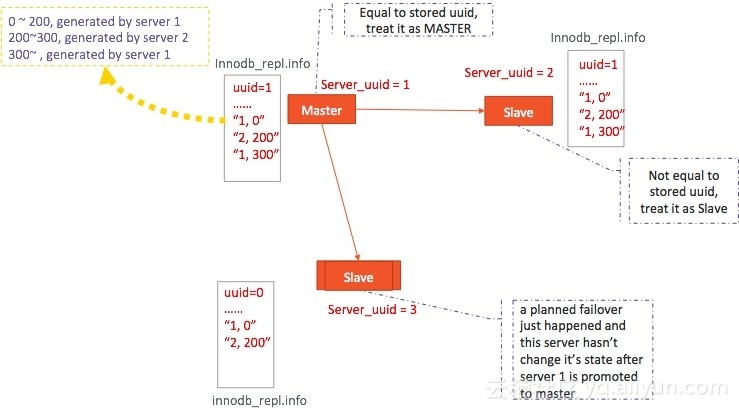
The UUID of server 1is 1, which is the same as the UUID recorded in the file. In this case, the corresponding instance is in master state.
The UUID of server 2 is 2, which is different from the UUID stored in the file. In this case, the corresponding instance is in slave state.
The UUID of server 3is 3, while the UUID recorded in the file is 0. This indicates that a failover has occurred recently (between server 1 and server 2) but the failover log has not be obtained yet. In this case, the corresponding instance is in upgradable-slave state.
The innodb_repl.info file records all replication and failover state information. Obviously, if we want to create a new instance through restoration in an existing topology, the related innodb_repl.info file must be copied.
Background Thread
Some background threads may change data, so we need to disable these threads on the slave database.
1. Do
not enable the Purge
thread.
2. The master thread
is not allowed to perform tasks that must be performed by other threads such as
ibuf merge,
but can only regularly perform the lazy checkpoint
operation.
3. The dict_stats
thread can only update statistics of tables in memory and cannot trigger physical
storage of statistics.
In addition, the cleaning algorithm of the page cleaner thread must be adjusted so that it does not affect log application.
Server-Layer Data Replication by the MySQL
File Operation and Replication
To implement the Server-Engine architecture, MySQL adds redundant metadata to the server layer so as to set unified standards above the storage engine. This metadata involves files such as FRM, PAR, DB.OPT, TRG, and TRN, as well as directories that indicate databases. Operating these files and directories is not recorded in redo logs.
To perform operations on the file layer, we need to record file changing operations to logs. Therefore, three types of log file are added:
MLOG_METAFILE_CREATE: [FIL_NAME | CONTENT]
MLOG_METAFILE_RENAME: [ORIGINAL_NAME | TARGET_NAME]
MLOG_METAFILE_DELETE: [FIL_NAME]
The operations include creating, renaming, and deleting files. Note that file modification is not recorded in the logs, because on the server layer, metadata is updated by deleting an old file and creating a new one.
DDL Replication
When MySQL executes a DDL statement to modify metadata, it cannot access tablespaces. Otherwise, various exceptions and errors may occur. MySQL uses an exclusive MDL lock to block user access. This must also be applied to the slave database. To achieve this purpose, start and end points of the metadata modified must be identified. We introduce two types of log for such identification.
|
MLOG_METACHANGE_BEGIN |
Written before metadata is modified and the MDL lock is obtained |
To obtain an explicit exclusive MDL lock from a table and disable all the table cache objects of the table |
|
MLOG_METACHANGE_END |
Written before the MDL lock is released |
To release the MDL lock of a table |
The following is a brief example:
Run: CREATE TABLE t1 (a INT PRIMARY KEY, b INT);
The logs generated on the server layer include:
* MLOG_METACHANGE_START
* MLOG_METAFILE_CREATE (test/t1.frm)
* MLOG_METACHANGE_END
Run: ALTER TABLE t1 ADD KEY (b);
The logs generated on the server layer include:
* Prepare Phase
MLOG_METACHANGE_START
MLOG_METAFILE_CREATE (test/#sql-3c36_1.frm)
MLOG_METACHANGE_END
* In-place build…slow part of DDL
* Commit Phase
MLOG_METACHANGE_START
MLOG_METAFILE_RENAME(./test/#sql-3c36_1.frm to ./test/t1.frm)
MLOG_METACHANGE_END
The logs corresponding to the start and end points of metadata modification are not atomic logs. This means that if the master database crashes when metadata is modified on it, the end point is lost. In this case, the slave database will be unable to release the MDL lock of the table. To address this issue, a special log is generated each time the master database is recovered to notify all the slave databases connected to the master database to release all their exclusive MDL locks.
There is another issue concerning a slave database. If, for example, a checkpoint is made after MLOG_METACHANGE_START is executed and the database crashes before receiving MLOG_METACHANGE_END, the database must be able to retain the MDL lock to block user access after it is recovered.
To retain the MDL lock, first ensure that the checkpoint LSN is before the latest start point of all unfinished metadata changes. Then, names of tables related to the unfinished metadata changes must be collected during the restart and the exclusive MDL lock must be applied to the tables in order after the database is recovered.
Cache Disabling
Some cache structures are maintained on the server layer. Nevertheless, data changes are implemented on the physical layer. After applying redo logs, a slave database must be able to identify the caches that need to be updated. Currently, the following situations exist:
1. Permission-related
operation. Assignment of new permissions takes effect only after the ACL Reload operation is performed on a slave database.
2. Stored
procedure–related operation. For example, during stored procedure addition or
deletion, a slave database must increase a version number to notify user threads
to reload caches.
3. Table
statistics. On a master database, the number of rows updated is used to trigger
an update of table statistics. However, all changes on a slave database are
implemented on the block level, and it is unable to calculate the number of
rows changed. Therefore, a log is added to the redo log file each time the
master database updates statistics. The log is used to notify slave databases
to update statistics in memory.
MVCC by a Slave Database
Read View Control
To implement consistent read on a slave database, a user thread must be unable to detect the changes made by unfinished transactions on the master database. In other words, if some transaction changes has not been committed on the master database when a read view is started on a slave database, the changes must be invisible to the read view.
In
this regard, the start and end points of a transaction must be identified.
Therefore, we add two types of log for this purpose:
MLOG_TRX_START: After a transaction ID is
assigned to a read/write transaction on the master database, a log recording
the ID is generated. Because the log is generated with the trx_sys->mutex lock, the transaction IDs written
to a redo log are sequential.
MLOG_TRX_COMMIT: When a transaction is committed, a log recording the corresponding transaction ID is generated after the undo status is changed to commit.
On a slave database, we use these two types of log to recreate transaction scenarios. The global transaction status is updated only after a batch of logs are applied.
1. When
a batch of logs are applied, the maximum
value of MLOG_TRX_START+1 is
used to update trx_sys->max_trx_id.
2. IDs
of all unfinished transactions are added to a global transaction array.
See the figure below:

Under
the initial state, the largest unassigned transaction ID (trx_sys->max_trx_id)
is 11 and the active transaction ID array is empty.
When the first batch of logs are applied, all user request read views share the same structure. That is, low_limit_id = up_limit_id = 11 and the local trx_ids is empty.
After
the first batch of logs are applied, max_trx_id is updated to
12 + 1
and the unfinished transaction ID 12 is added to the global active transaction ID array.
This
rule applies to the other batches of logs. This solution balances between
replication efficiency and data visibility.
Note that when a master database crashes, a transaction may lose its end point. Therefore, a special log is generated after the master database is recovered to notify all slave databases to check all undo slots and reinitialize the global transaction status.
Purge Control
In order to maintain the MVCC feature, undo logs, a critical part of consistent read, must be controlled, so that the undo logs that may be referenced by read views will not be cleared. You can choose between the following solutions:
Solution 1: controlling Purge on a slave database
When a master database performs the Purge operation, the latest snapshot of the current Purge read view is written to a redo log. After obtaining the snapshot, a slave database checks whether it noticeably overlaps with the latest active read view on the current instance. If yes, the slave database waits until the read view is closed. We also provide a timeout option. When the timeout interval expires, the database directly updates the local Purge read view and an error code DB_MISSING_HISTORY is sent to the threads using the read view.
The disadvantage of this solution is obvious. When the slave database has a heavy load or query traffic, replication may be delayed.
Solution 2: Controlling Purge on a master database
A slave database regularly sends feedback to the instance to which it connects. The feedback contains the current minimum ID applicable to a safe Purge operation. See the figure below: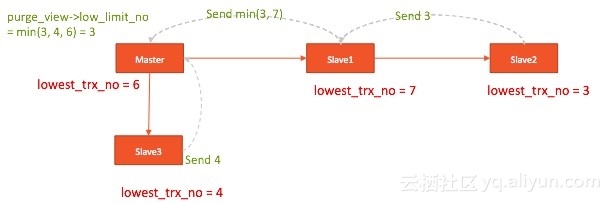
The disadvantage of this solution is that it leads to a lower Purge efficiency on the master database. On the entire replication topology, the size of undo logs on the master database may increase as long as there is a read view open for a long time.
Replication in Case of a B-TREE Structure Change
When a B-TREE structure change occurs, such as page combination or division, user threads must be prevented from searching the B-TREE.
The solution is simple. When an MTR is committed on a master database with an exclusive lock of a table with an index, and the change in the MTR involves less than one page, the involved index ID is written to a log. When parsing the log, a slave database generates a synchronization point, where it applies the parsed log, obtains the index X lock, applies a log group, and releases the index X lock.
Change Buffer Merging by a Slave Database
Change buffer is a special buffer of InnoDB. Basically, it is a B-TREE in an ibdata file. When the level-2 index page of a user tablespace is modified, if the corresponding page is not stored in the memory, the operation may be recorded to the change buffer. This reduces the random I/O workload related to the level-2 index and achieves the data merging and updating effect.
When the corresponding page is read to the memory, the Merge operation is performed once and the Master background thread regularly perform the Merge operation. This article does not elaborate on the change buffer. For more details, refer to the monthly report I prepared some time ago.
Changing data in the slave database is not allowed. Reading data must not impose any negative impacts on the physical data. To meet this requirement, we adopt the following method:
1. When
a page is read to the memory and it requires
the ibuf merge operation, assign a shadow page to it to save the unchanged data page.
2. The
data in the change buffer is added to
the data page and the redo log of the MTR is
disabled. In this case, the changed page will not be added to the flush list.
3. The bitmap page in the change buffer and the page
in the change buffer B-Tree must not be
changed.
4. When
the data page is removed from the buffer pool or
request by the log
apply thread, the shadow page is
released.
There is another issue where the master and salve databases may have different memory states. For example, if a page resides on the master database but has not been read to the memory, it is saved to the change buffer. However, this page exists in the buffer pool. To ensure data consistency, we need to add the latest data in the change buffer to the page on the slave database.
Specifically, when the slave database detects a new change buffer entry and the page corresponding to the entry exists in the memory, the database adds a label to the page. Then, when a user thread accesses this page, the unchanged page is obtained from the shadow page(if any) and the change buffer merging operation is performed again.
Change Buffer Merging for Replication
One change buffer merge operation involves the ibuf bitmap page, level-2 index page, and change buffer B-Tree, which are in a sequential order. On a slave database, however, logs are applied concurrently instead of sequentially. To ensure that a user thread is unable to access, during the merging process, a data page being modified, we add the following types of log:
MLOG_IBUF_MERGE_START : It is written before the ibuf merge operation is performed on a master database. When detecting this log, a slave database applies all parsed logs, obtains the corresponding block, and adds an exclusive lock. If a shadow page is available, the slave database obtains unchanged data from the shadow page and releases the shadow page.
MLOG_IBUF_MERGE_END: It is written after the corresponding bits on the ibuf bitmap page is cleared on a master database. When detecting this log, a slave database applies all parsed logs and releases the block lock.
Obviously, this solution creates a performance bottleneck, which may lower the replication performance. We will try to figure out a better solution.
Failover
Planned Failover
When a scheduled failover is performed, follow the specified procedure to ensure that all instances are consistent during the failover. The procedure consists of the following four steps:
Step 1: Perform the downgrade operation on the master database to change the status from MASTER to UPGRADABLE-SLAVE. In this case, the database stops all read/write transactions, suspends or stops the background threads that may change data, and writes a MLOG_DEMOTE log to the redo log file.
Step 2: After reading the MLOG_DEMOTE log, a slave database connected to the master database enters the UPGRADALE-SLAVE state.
Step 3: Select an instance from the replication topology and convert it into a master database. Initialize various memory status values, and create a MLOG_PROMOTE log.
Step 4: When detecting the MLOG_PROMOTE log, a slave database connected to the master database changes its status from UPGRADABLE-SLAVE to SLAVE.
Unplanned Failover
In most cases, a failover is triggered by an accident. To reduce the service interruption time, we need to choose a slave database to quickly take over user services. In this scenario, we need to ensure that the original master database is recovered to a state consistent with the new master database. Specifically, if some logs have not been transferred from the original master database to the new master database, this inconsistency must be handled.
To address this issue, we adopt the overwrite method as follows:
1. Block all access attempts including query attempts on the original master database, and change the original master database to a slave database.
2. Obtain
the LSN generated during the failover that involves the new master database.
Check all the redo logs generated after the LSN on the original master database
to identify all affected space IDs and page numbers.
If a DDL operation is detected, the
recovery fails and you need to use a third-party tool to perform
synchronization or recreate the instance.
3. Obtain
the pages from the new master database and use them to overwrite the local
ones.
4. After
they are overwritten, truncate the unnecessary redo
logs
from disks and update the checkpoint information.
5. Restore
replication and enable read requests.
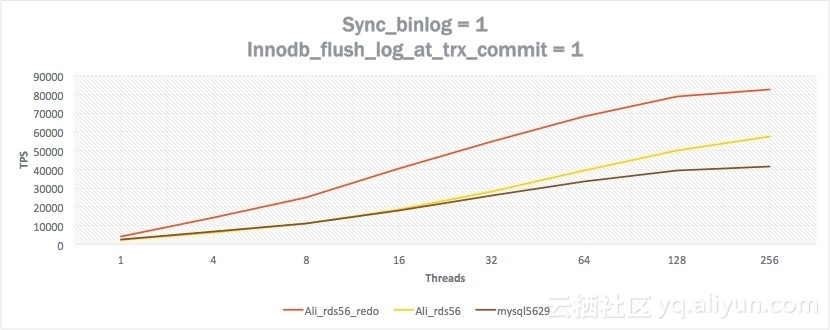
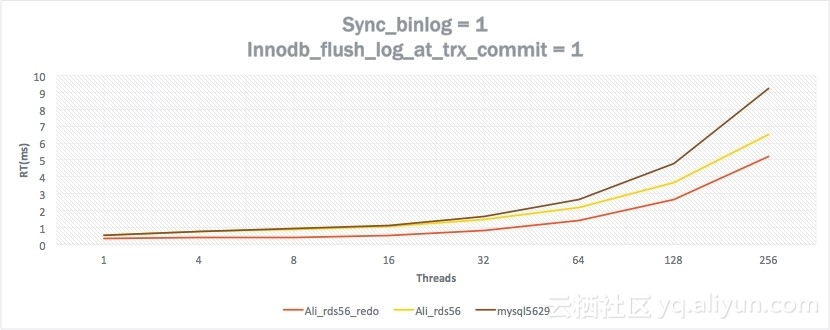
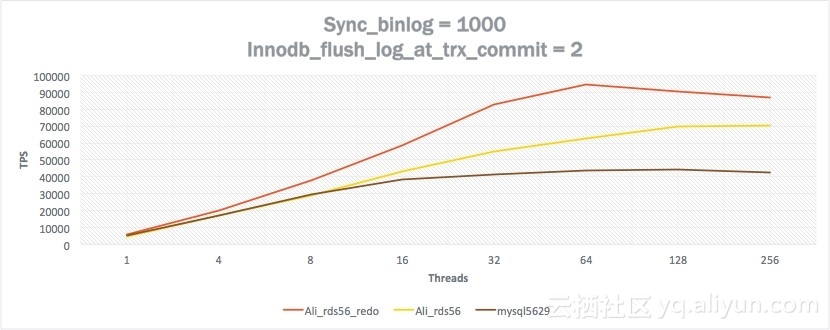
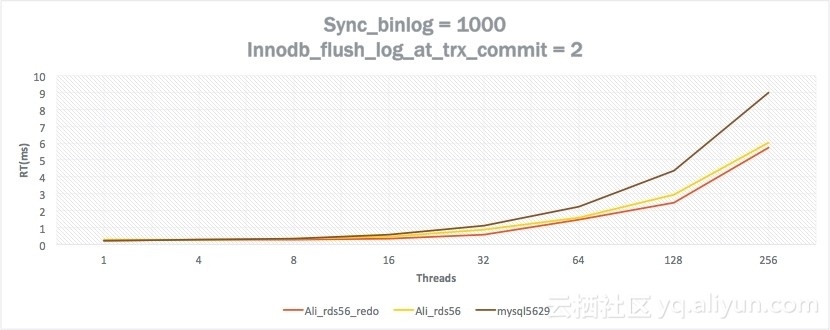
Test and Performance
We have tested the performance of the following three versions:
Test environment:
Leveraging IoT Data in the Cloud: Why Your Business is More at Risk

2,593 posts | 793 followers
FollowMorningking - September 26, 2023
Alibaba Clouder - August 26, 2021
ApsaraDB - September 10, 2025
Alibaba Cloud Community - May 2, 2024
ApsaraDB - October 17, 2024
ApsaraDB - January 17, 2024
2,593 posts | 793 followers
Follow PolarDB for MySQL
PolarDB for MySQL
Alibaba Cloud PolarDB for MySQL is a cloud-native relational database service 100% compatible with MySQL.
Learn More AnalyticDB for MySQL
AnalyticDB for MySQL
AnalyticDB for MySQL is a real-time data warehousing service that can process petabytes of data with high concurrency and low latency.
Learn More ApsaraDB RDS for MySQL
ApsaraDB RDS for MySQL
An on-demand database hosting service for MySQL with automated monitoring, backup and disaster recovery capabilities
Learn More Database for FinTech Solution
Database for FinTech Solution
Leverage cloud-native database solutions dedicated for FinTech.
Learn MoreMore Posts by Alibaba Clouder

