本文针对AnalyticDB for MySQL中的三种计算资源组类型(Multi-Cluster、Job、Auto-Scaling)进行能力定位说明以及性能测评分析,作为资源组选型时的参考依据。
计算资源组类型简介
Multi-Cluster类型
适用场景:Multi-Cluster类型的资源组支持根据资源组的负载以Cluster为最小单位自动进行资源扩缩,满足资源组内部的资源隔离和高并发场景。主要适用于Interactive类型查询,且单查询资源量不超过一个Cluster资源量的场景。在业务高峰期,以Cluster为单位自动拉起一批计算节点,提升整体的计算资源量来适配业务压力,避免性能受损。在业务低峰期,以Cluster为单位自动缩容计算节点,减少整体计算资源量节约成本。
计费规则:具体参考计费规则。
Job类型
适用场景:Job类型资源组支持为查询临时拉起计算资源,查询结束立即释放计算资源。以BSP方式执行查询,响应时间较慢,通常在秒级或分钟级,具体拉起的资源量大小取决于运行的任务大小。主要适用于对时延不敏感、消耗资源量大的非实时性任务。
计费规则:具体参考计费规则。
Auto-Scaling类型
适用场景:Auto-Scaling类型资源组支持实时感知资源组负载,并以节点为单位动态扩缩计算资源,单条查询最大可使用的资源量与设置的资源组资源量上限相同,并且拉起的计算节点可以先后在多个查询之间共享。Auto-Scaling类型资源组以查询为单位进行资源隔离,避免查询之间相互干扰,减少查询的性能抖动。适用于业务负载中既有对时延敏感的Interactive类型查询,也有消耗资源量大的Batch类型查询的场景。
计费规则:具体参考计费规则。
资源组对比总览
资源组类型 | Interactive查询 | Batch查询 | 弹性扩缩 | 按需付费 | 资源隔离 |
Multi-Cluster | 适用 | 不适用 | Cluster粒度 | 至少需要付1个Cluster的费用 | Cluster粒度 |
Job | 不适用 | 适用 | 节点粒度 | 完全按需付费 | 查询粒度 |
Auto-Scaling | 适用 | 适用 | 节点粒度 | 支持按需付费 | 查询粒度 |
场景化性能评测
为了更直观了解Auto-Scaling类型资源组在不同场景下相对于其他类型资源组的性能表现,本文通过常见的业务场景对三种资源组的性能进行评测。
实时查询—BI查询性能
BI查询是数据仓库中最常见的固定负载类型,一般是通过BI工具(如Tableau、PowerBI、QuickBI等)执行的预定义报表和仪表板查询。这类查询具有明确的业务模式:SQL逻辑固定、执行频率高(定时刷新或高频访问)、结果集规模可控,主要用于日常业务监控、经营日报/周报、KPI仪表板等场景。BI查询对数据库的核心诉求是稳定的并发处理能力和可预测的响应延迟,既要保证早高峰多人同时刷新时不卡顿,又要确保固定报表按时产出,同时对负载隔离有一定要求(避免大查询影响核心报表体验)。
以1T数据规模的TPCH数据集模拟BI查询的业务负载,在不同并发数下,Auto-Scaling资源组和Multi-Cluster资源组的性能表现对比如下。
|
|
|
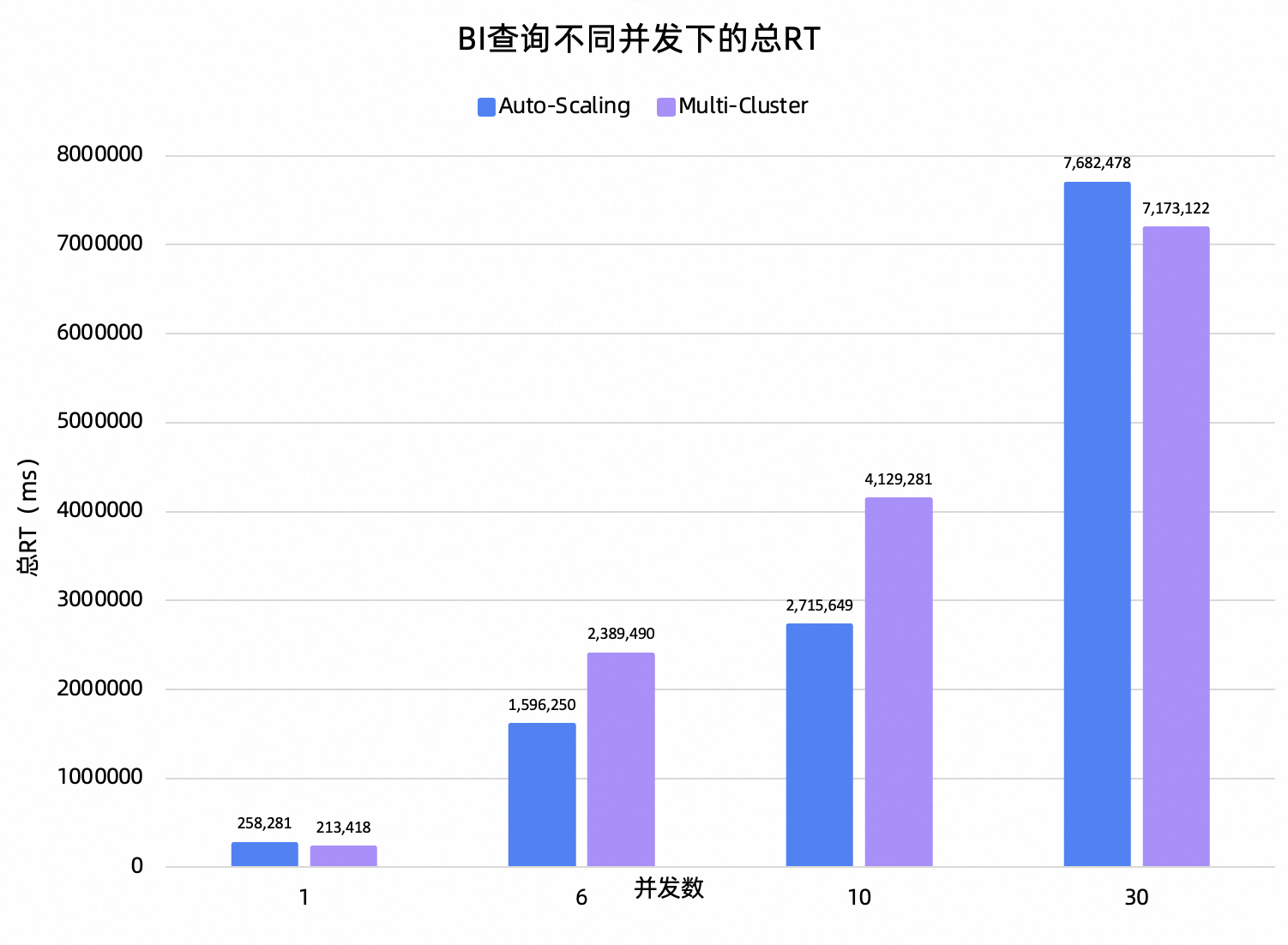
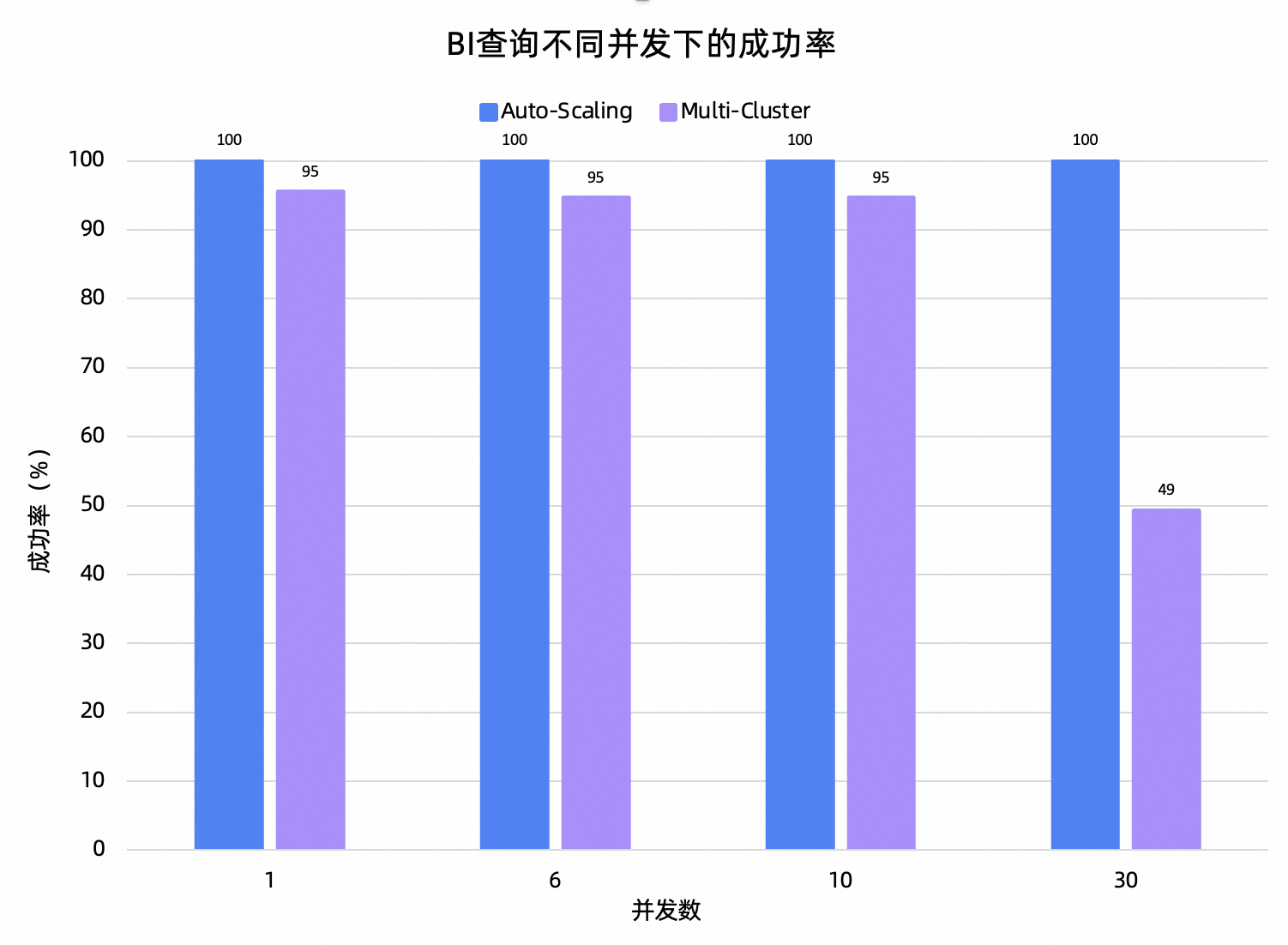
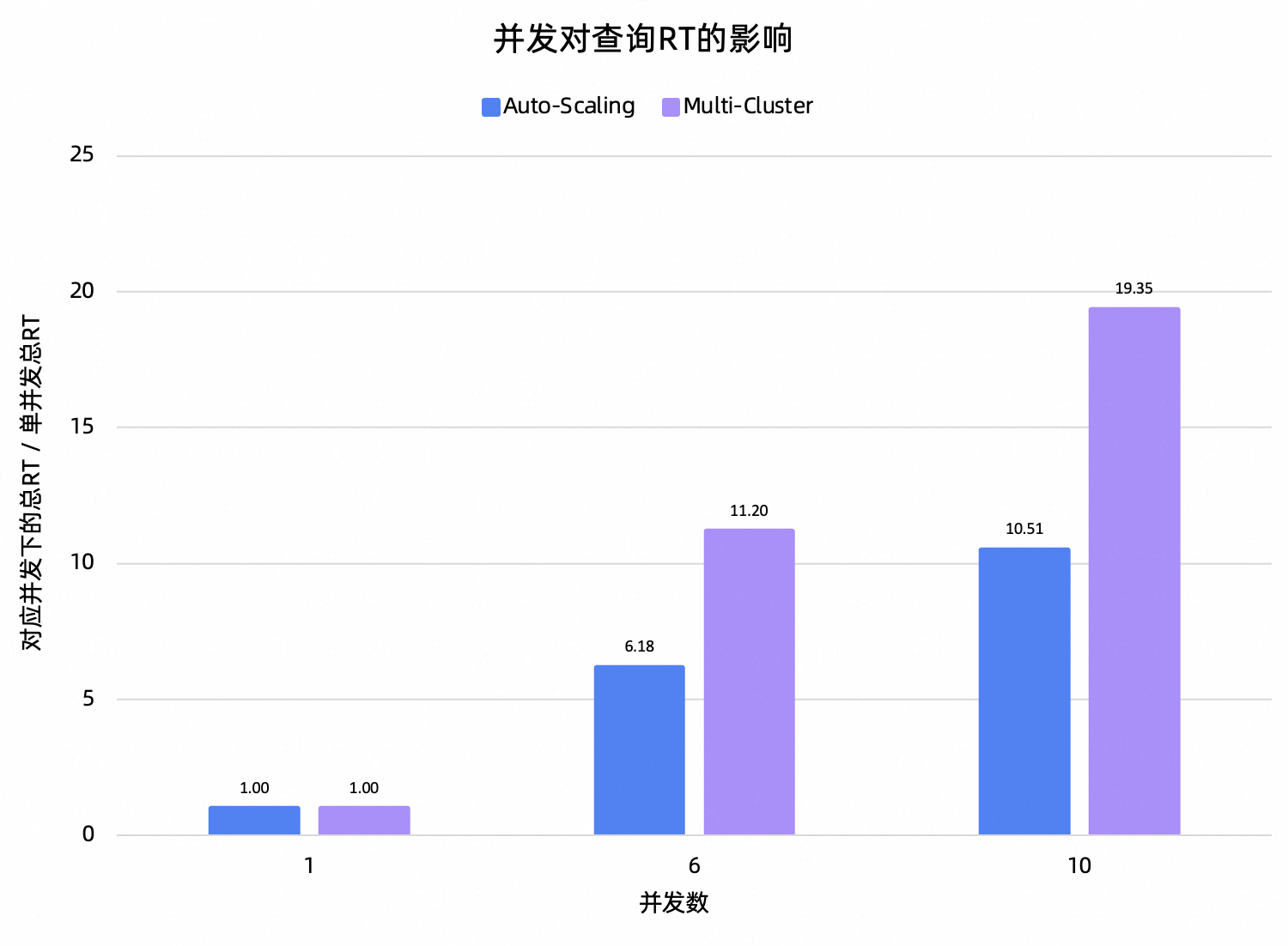
测试结论:Auto-Scaling在所有并发下的查询成功率都是100%,而Multi-Cluster会存在查询失败的情况,甚至在30并发时失败率高达50%+。除去30并发下Multi-Cluster近似不可用外,观察总RT的测试结果,随着并发上升,Auto-Scaling的总RT是近似线性增长的,而Multi-Cluster的性能有严重的退化。
以上测试结果反映了Auto-Scaling以查询作为资源隔离粒度的优势,即使并发数增加,各个查询之间也不会相互干扰,既保证了集群的可用性,又保证了查询的性能。
实时查询—即席查询性能
即席查询(Ad-Hoc)是数据仓库中典型的探索性负载类型,指由数据分析师或业务人员临时发起的非固定模式查询。这类查询具有高度的不确定性:SQL逻辑不固定(常为手写或动态生成)、查询复杂度高(多表关联、嵌套子查询、复杂聚合)、不同的查询执行耗时波动大,主要用于数据探索分析、问题排查归因、临时取数等场景。Ad-Hoc查询对数据库的核心诉求是复杂查询处理能力、并发能力,并且操作主要以人工为主,所以对响应速度的要求也比较高。
根据TPC数据集,选取如下用于测试的SQL语句:
轻量Ad-Hoc:基于TPC数据集构造了一组耗时约为5s的查询,包括:多表Join取明细、按维度聚合统计(GROUP BY + SUM/COUNT)、窗口函数排名(RANK)、星型模型多维聚合、聚合排序Top-N。整体偏向“快速浏览与汇总”的轻量级分析。
复杂Ad-Hoc:基于TPC数据集构造了一组耗时约为10s的查询,包括:Semi-Join半连接过滤(EXISTS子查询)、窗口函数分组对比(AVG OVER PARTITION BY)、CTE分阶段计算+Top-N回查、星型模型多维聚合、CASE条件分层+COUNT DISTINCT去重。整体偏向“深度探索与分群”的重量级分析。
分别针对2组Ad-Hoc查询,在10/20/50/100并发压力下,分别压测5分钟,Auto-Scaling和Multi-Cluster资源组的性能表现如下。
|
|
|
|
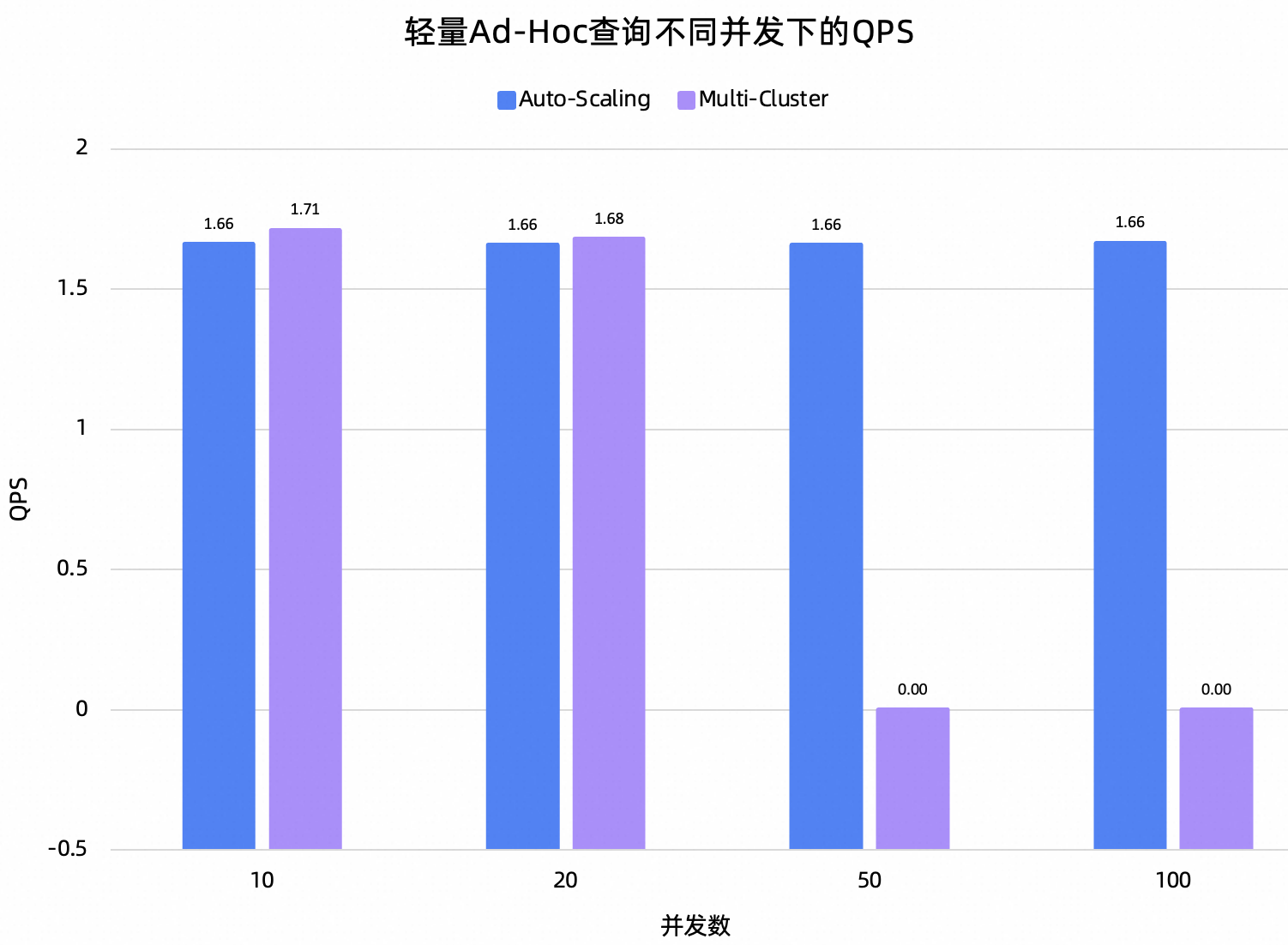
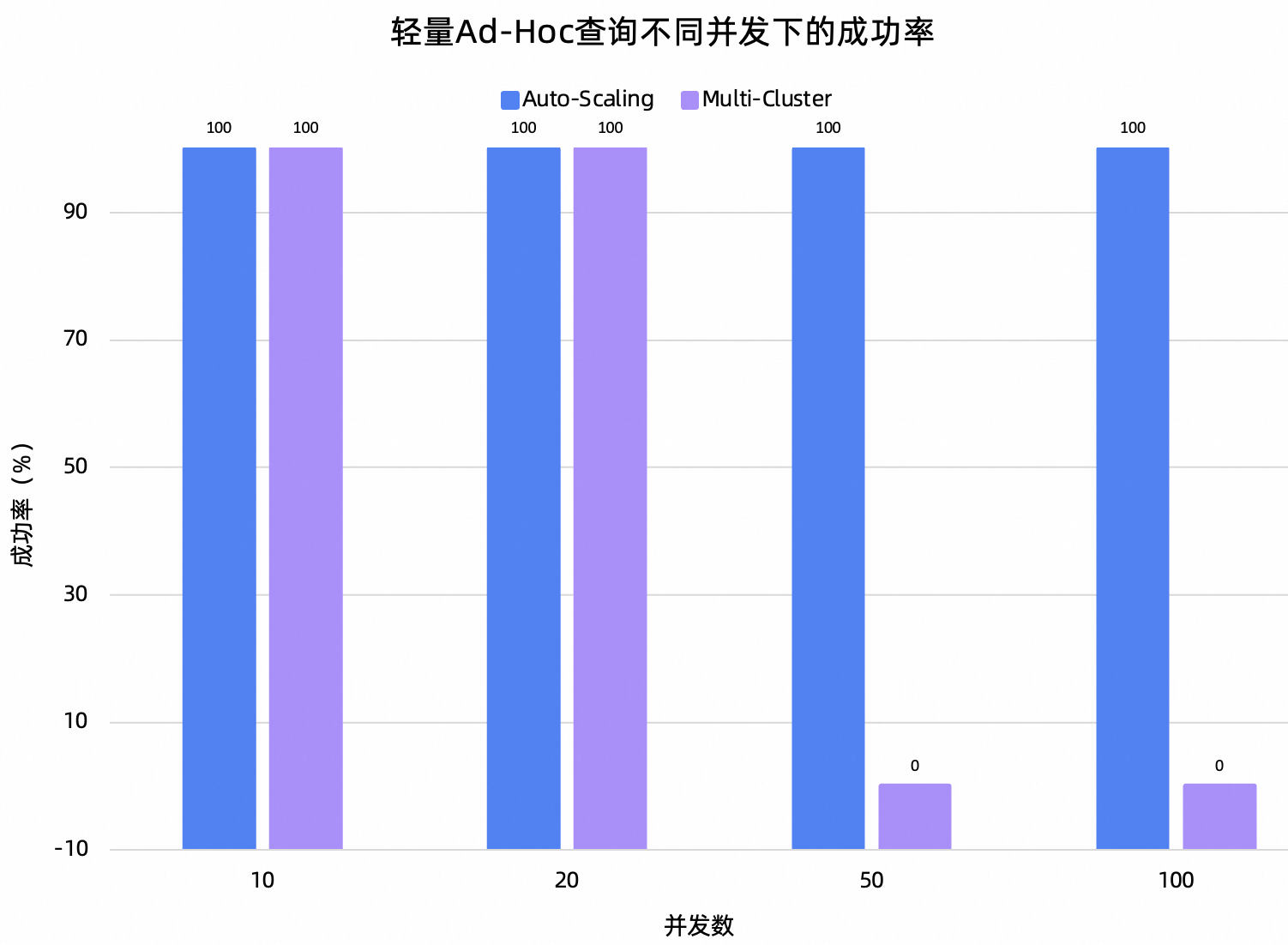
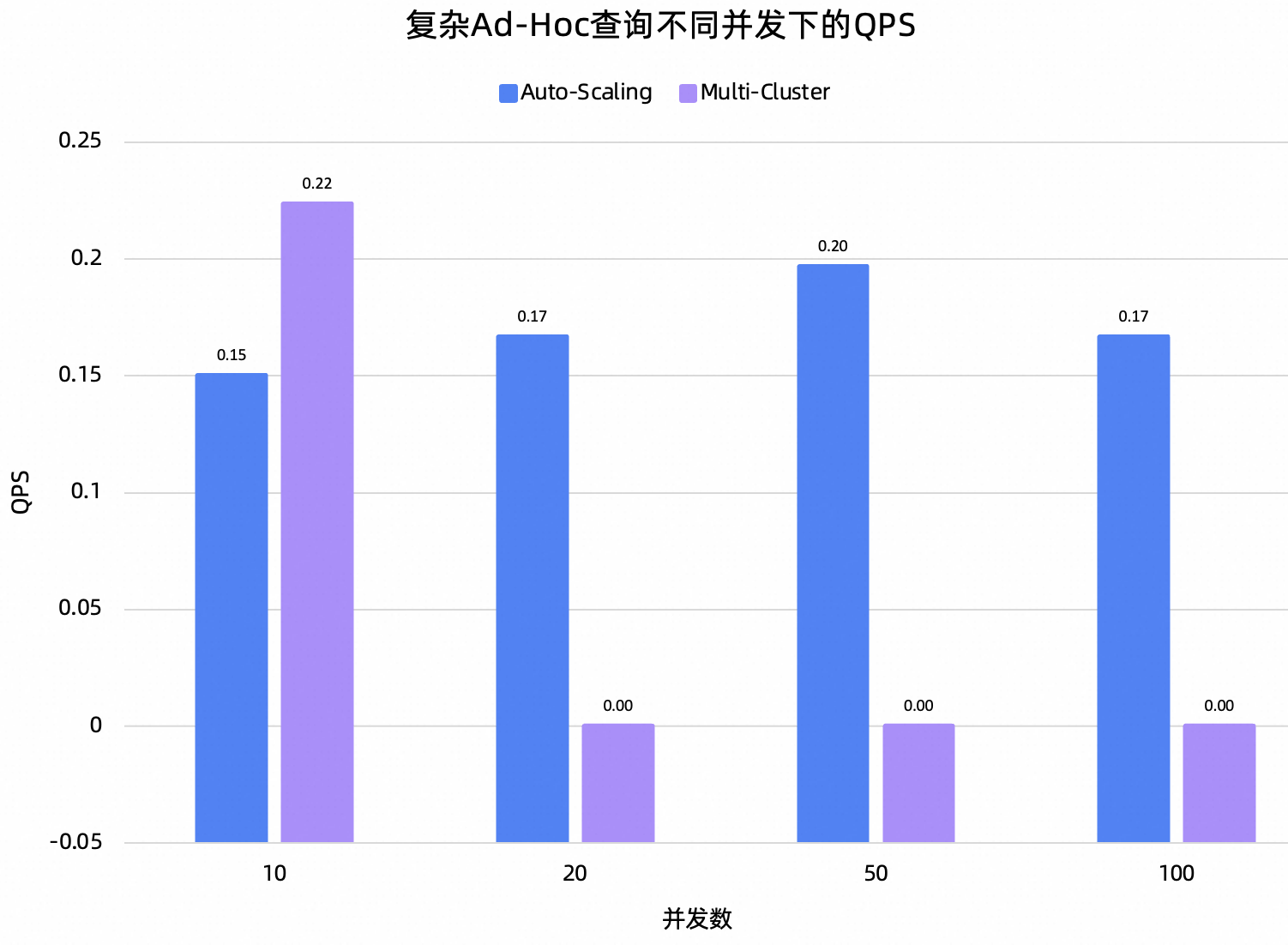
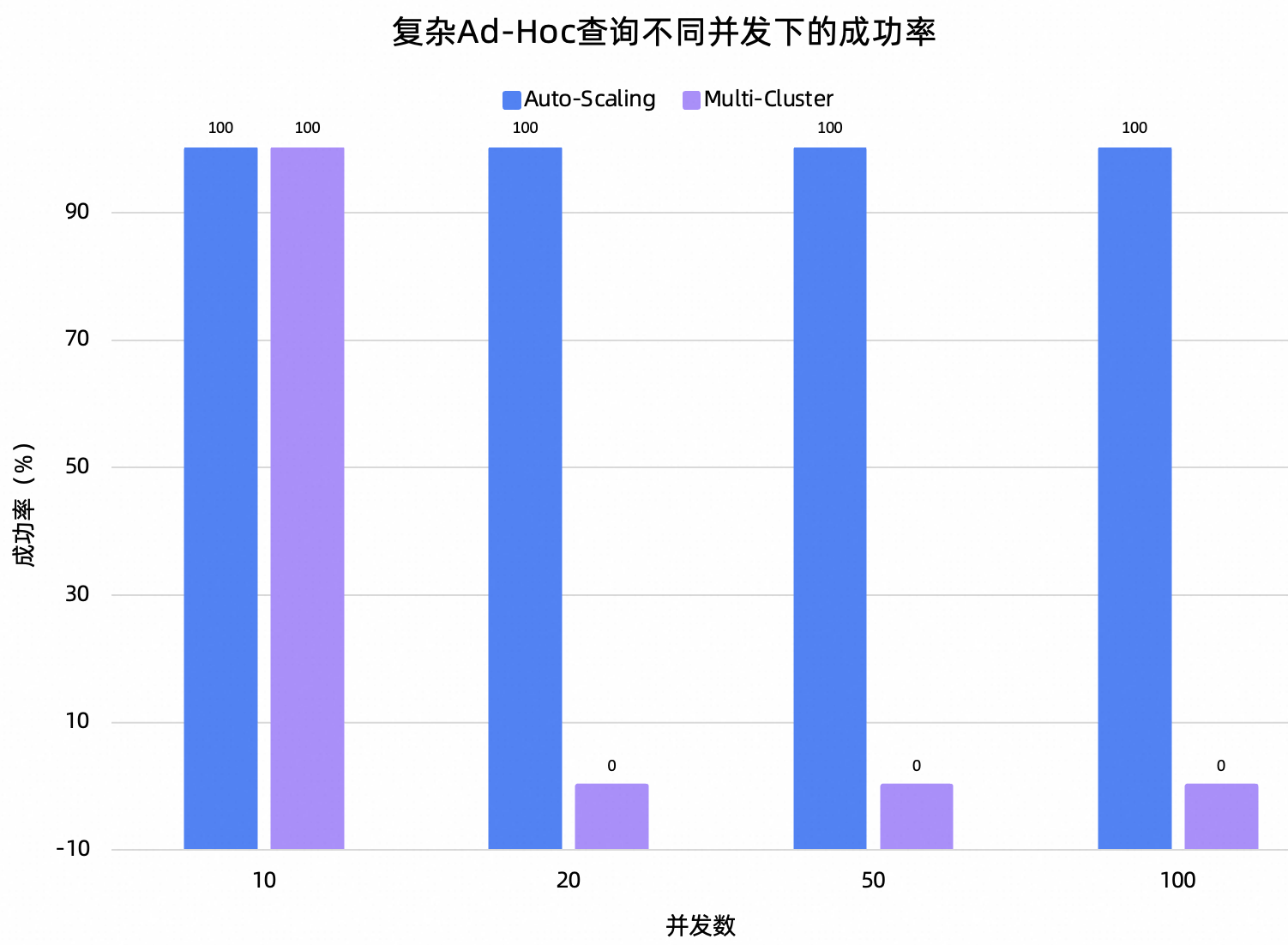
测试结论:在这项测试中,最直观的结果就是Auto-Scaling在多并发下的可用性明显优于Multi-Cluster。50并发开始,Multi-Cluster在5分钟内无法完成任意一个轻量Ad-Hoc查询。对于复杂的Ad-Hoc查询,Multi-Cluster在20并发开始就无法正常处理。再从QPS的角度观察,Auto-Scaling在不同并发下,QPS基本维持稳定。这再次证明了Auto-Scaling对于查询间的资源隔离处理得很好。
实时查询—小查询性能
小查询是业务场景中最频繁的一类查询,这类查询消耗资源量少,并且对延迟和吞吐十分敏感。基于TPC数据集,构造了2类具有代表性的小查询:1)分布键点查;2)复杂小查询。
复杂小查询是指通过高选择性过滤条件精确定位少量行,但后续计算逻辑复杂,包含多表关联、多维聚合统计分析。这类查询用于模拟线上典型的用户级实时画像分析场景。
以下是2种小查询负载在不同并发下分别使用Auto-Scaling和Multi-Cluster资源组的测评结果。
|
|
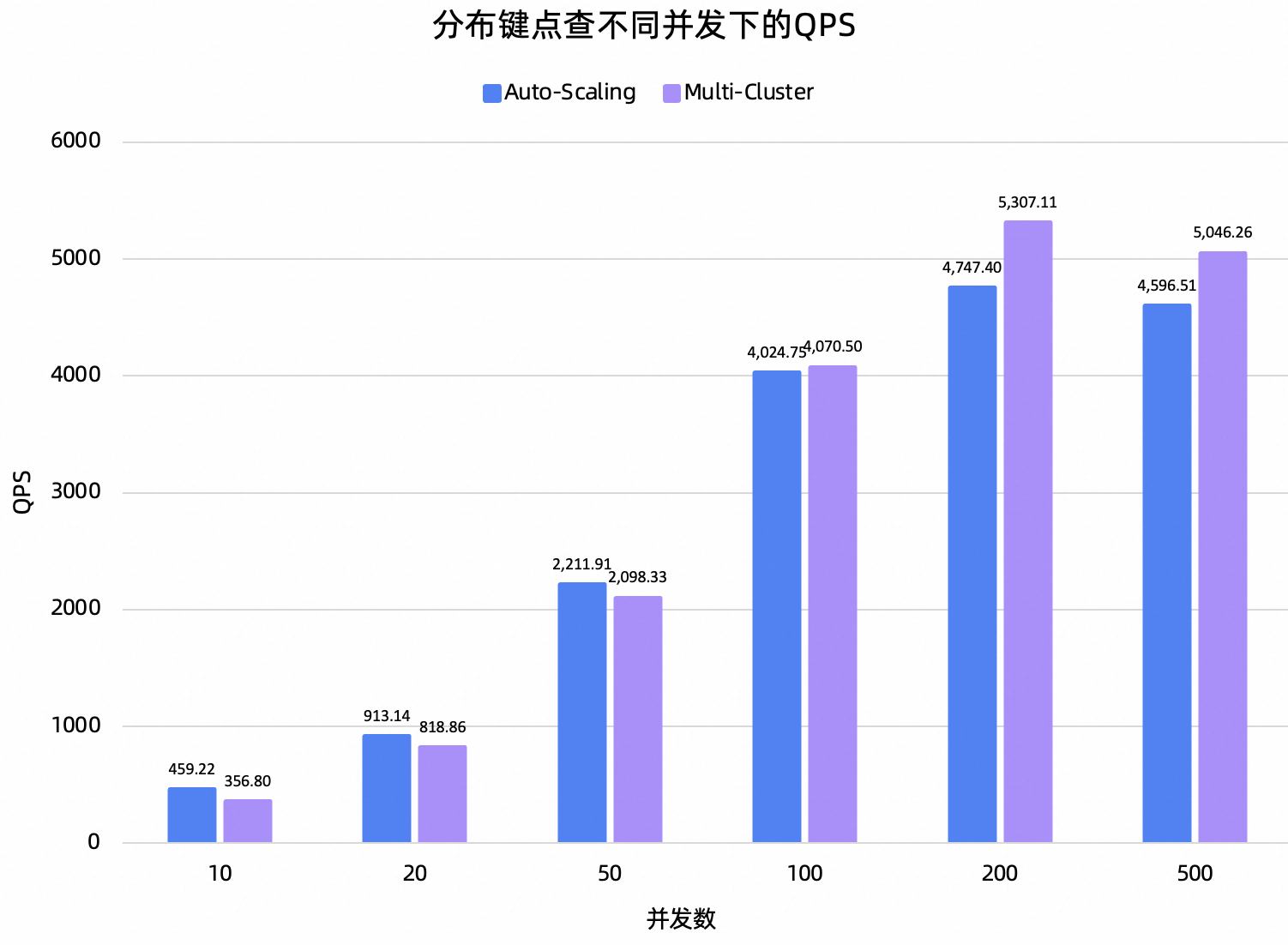
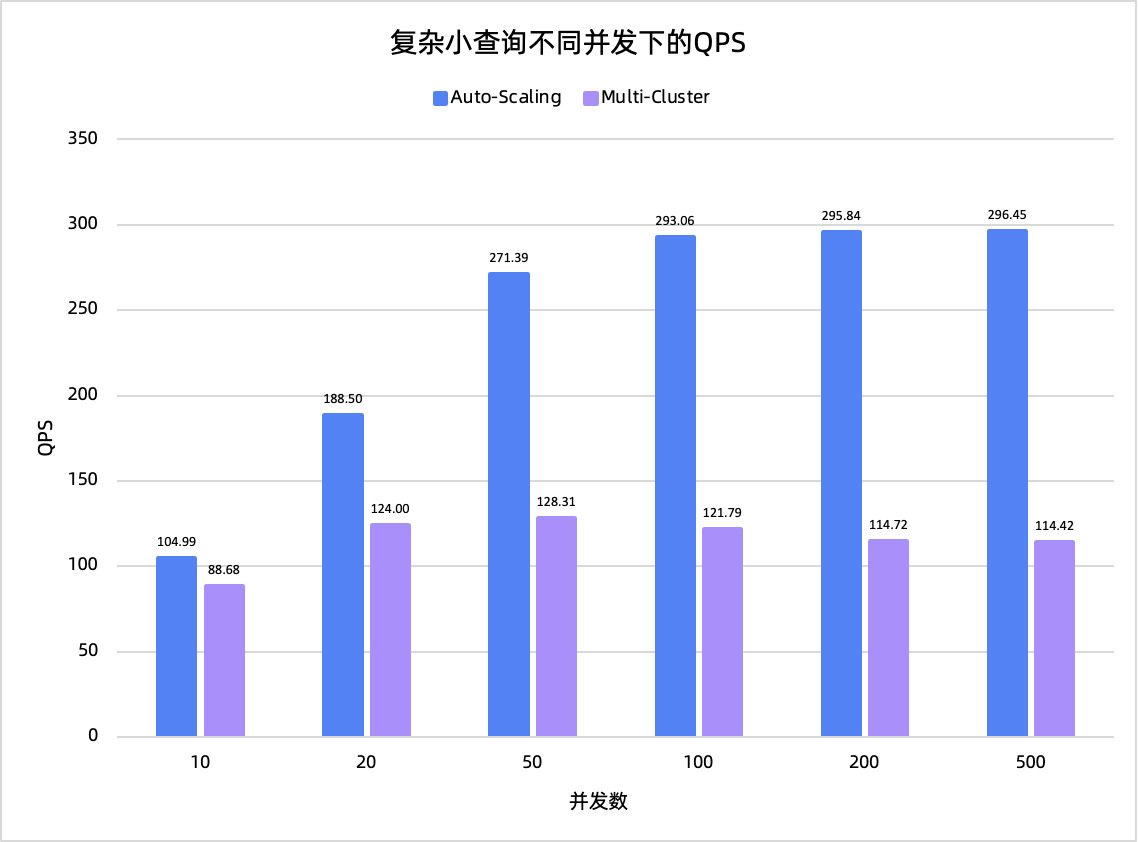
测试结论:在分布键点查场景下,Auto-Scaling性能略差于Multi-Cluster,而在复杂小查询场景下,Auto-Scaling在高并发时表现出明显的优势。
离线查询性能
离线查询是数据仓库中面向批量数据处理的负载类型,通常用于T+1报表、数据仓库分层加工、历史数据归档、大规模数据分析等非实时场景。这类查询具有明确的任务边界:TB~PB级数据量、小时级的执行时长、逻辑复杂(多表Join、窗口函数、聚合计算)、对延迟不敏感但对稳定性要求高。
以10T数据规模的TPC数据集模拟离线查询,对比Auto-Scaling和Job资源组的性能表现。
|
|
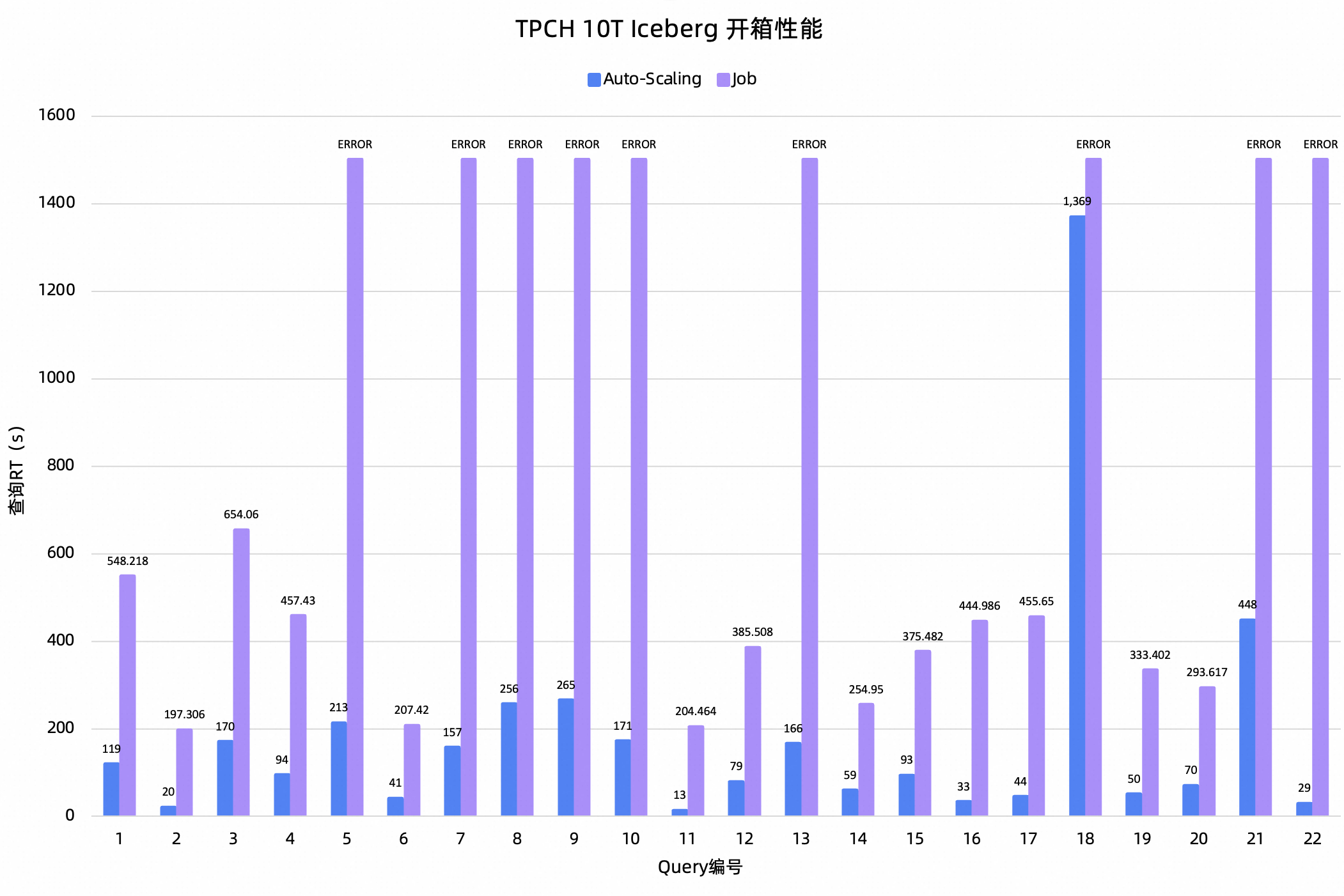
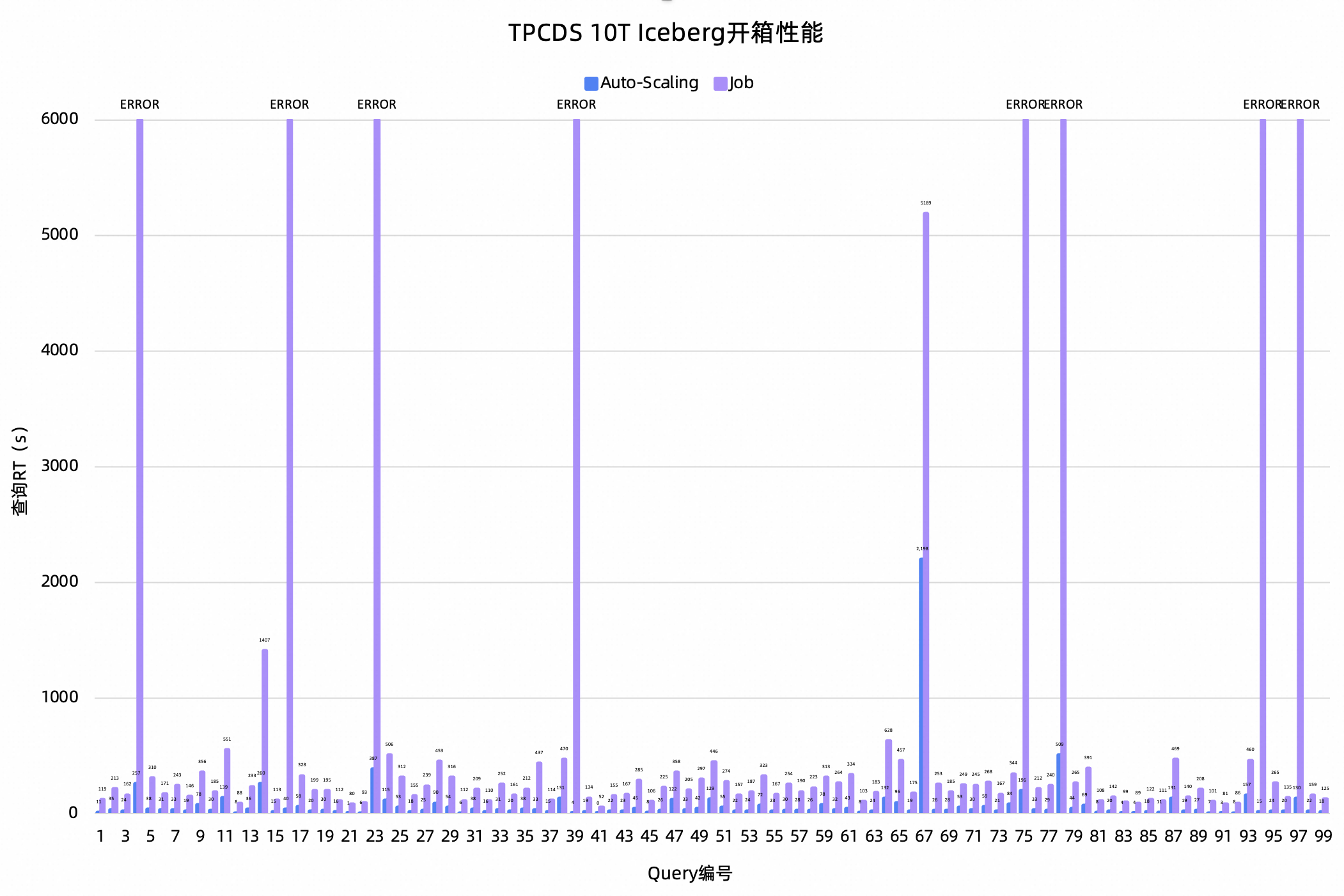
测试结论:TPCH 10T开箱测试中,Auto-Scaling整体性能相对于Job提升了443.44%,并且Auto-Scaling的成功率是100%,而Job成功率只有59%。在TPCDS 10T开箱中,Auto-Scaling整体性能相对于Job提升了355.17%,成功率方面也是Auto-Scaling全都成功,而Job成功率是92%。所以,在离线查询场景下,Auto-Scaling无论是查询性能还是稳定性都显著优于Job。
综合评估与结论
能力矩阵总览
下表汇总了三种资源组在各评估维度上的表现:
评估维度 | 评估项 | Multi-Cluster | Job | Auto-Scaling |
实时查询 | BI查询并发能力 | ✅ | ❌ | ✅ |
Ad-Hoc高并发支持 | ✅(低并发) | ❌ | ✅ | |
小查询吞吐 | ✅ | ❌ | ✅ | |
离线查询 | 大任务处理能力 | ❌ | ✅ | ✅ |
弹性能力 | 弹性扩缩粒度 | Cluster粒度 | 节点粒度 | 节点粒度 |
计费模式 | 按需付费 | 至少1 Cluster费用 | 完全按需 | 支持按需 |
资源隔离 | 隔离粒度 | Cluster粒度 | 查询粒度 | 查询粒度 |
测评结论汇总
场景类型 | 对比资源组 | Auto-Scaling性能表现 | 核心优势 |
BI查询 | Multi-Cluster | 高并发下RT更优且稳定,成功率100% vs 95%。 | 查询级资源隔离,并发稳定性好。 |
轻量Ad-Hoc | Multi-Cluster | 100并发仍可用,Multi-Cluster在50并发已不可用。 | 资源隔离好,QPS稳定。 |
复杂Ad-Hoc | Multi-Cluster | 100并发仍可用,Multi-Cluster 20并发已不可用。 | 高并发下可用性优势明显。 |
分布键点查 | Multi-Cluster | 性能持平Multi-Cluster。 | - |
复杂小查询 | Multi-Cluster | 高并发时表现更优。 | 资源隔离好,单机计划节约分布式开销。 |
离线查询 | Job | 成功率100%,而Job两组测试的成功率分别是59%和92%,性能也是Auto-Scaling占优。 | 性能和稳定性相比Job具有压倒性的优势。 |
核心结论
Auto-Scaling在实时查询场景全面对标Multi-Cluster:在BI查询、Ad-Hoc查询、复杂小查询等高并发场景下,Auto-Scaling凭借查询粒度的资源隔离能力,表现出更优的并发稳定性和查询成功率。Multi-Cluster在高并发下查询失败率显著上升,而Auto-Scaling始终保持100%成功率。
Auto-Scaling在离线查询场景对标Job:在离线查询场景下,Auto-Scaling无论从查询性能角度还是从查询稳定性角度,相比于Job都具有压倒性的优势。
Auto-Scaling的核心优势:
查询级资源隔离:以查询为单位进行资源分配和隔离,避免查询间相互干扰,高并发下性能稳定。
完全按需付费:相比Multi-Cluster至少需要支付1个Cluster的费用,Auto-Scaling按实际使用量计费。
节点级弹性伸缩:相比Multi-Cluster的Cluster级扩缩容,Auto-Scaling以节点为单位,弹性更细粒度。
一套资源覆盖多场景:同时支持Interactive和Batch查询,无需维护多套资源组。
选型建议:推荐Auto-Scaling,混合负载场景(同时有实时+离线查询)、高并发实时查询场景、成本敏感场景。