本文将介绍如何利用AnalyticDB Spark,在 Notebook 环境中通过 PySpark 或 Spark SQL 实现数据仓库与数据湖之间的双向数据交换与 ETL 处理。
背景说明
AnalyticDB for MySQL支持两种数据存储模式:数据仓库表(高性能存储)和数据湖表(低成本存储)。根据数据来源与业务需求,应选择不同的存储模式作为贴源层,在生产环境中,这两种表类型通常并存:
数据仓库表:适用于通过 DTS 同步 MySQL、PolarDB 或 MongoDB 的实时数据。其优势在于高并发更新性能。
数据湖表:适用于从 OSS 或数据库定期批量加载数据。其优势在于高吞吐量及数据共享能力。

准备工作
AnalyticDB for MySQL
AnalyticDB for MySQL集群的产品系列为企业版、基础版或湖仓版。
集群的内核需为3.2.6及以上版本。
说明请在云原生数据仓库AnalyticDB MySQL控制台集群信息页面,配置信息区域,查看和升级内核版本。若集群已是最新默认基线版本但仍需升级,请通过钉钉联系阿里云服务支持处理(钉钉账号:
x5v_rm8wqzuqf)。已创建数据库账号。
如果是通过阿里云账号访问,只需创建高权限账号。
如果是通过RAM用户访问,需要创建高权限账号和普通账号并且将RAM用户绑定到普通账号上。
已开启ENI访问。
重要登录云原生数据仓库AnalyticDB MySQL控制台,在的网络信息区域,打开ENI网络开关。
开启和关闭ENI网络会导致数据库连接中断大约2分钟,无法读写。请谨慎评估影响后再开启或关闭ENI网络。
Notebook工作空间
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
单击。确保已完成如下准备工作,然后单击进入DMS Notebook。

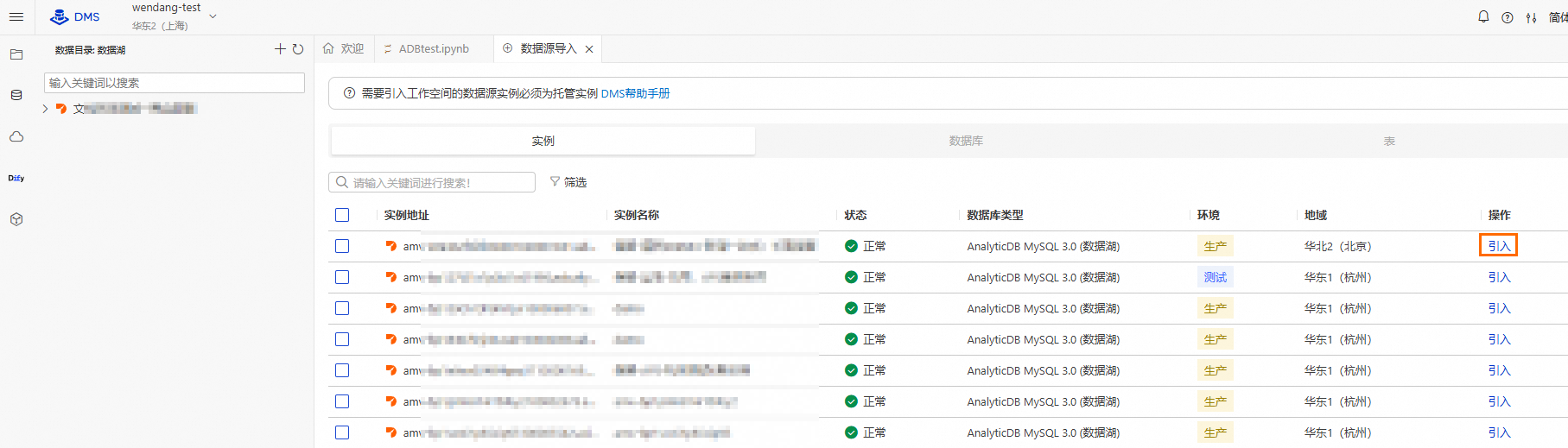
创建Spark集群。
单击
 按钮,进入资源管理页面,单击计算集群。
按钮,进入资源管理页面,单击计算集群。选择Spark集群页签,单击创建集群,并配置如下参数:
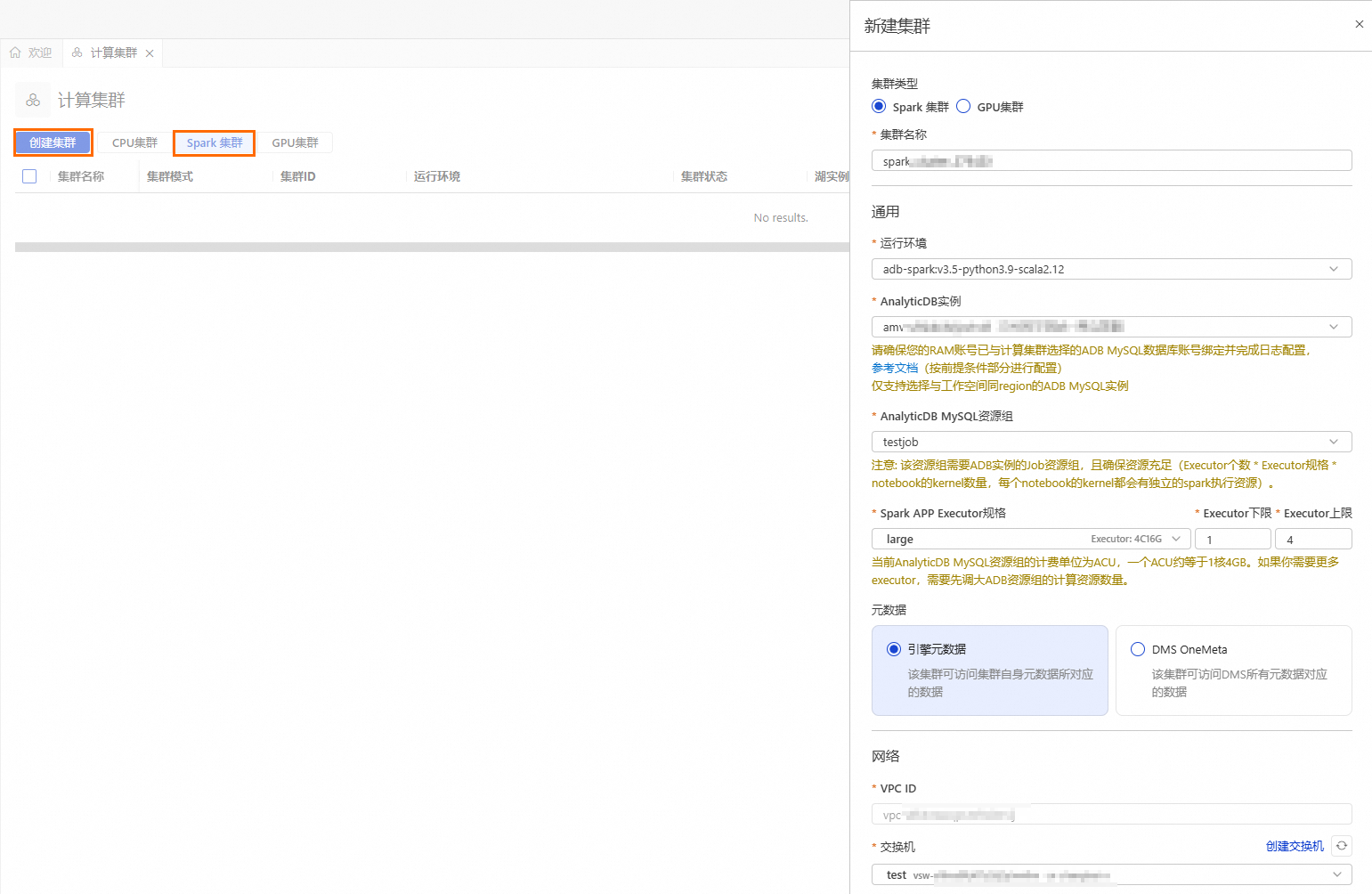
参数
说明
示例值
集群名称
输入便于识别使用场景的集群名称。
spark_test
运行环境
根据需求选择适合的镜像版本。
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB实例
在下拉框中选择AnalyticDB for MySQL集群。
amv-uf6i4bi88****
AnalyticDB MySQL资源组
在下拉框中选择Job型资源组。
testjob
Spark APP Executor规格
选择Spark Executor的资源规格。
不同型号的取值对应不同的规格,详情请参见Spark应用配置参数说明的型号列。
large
交换机
选择当前VPC下的交换机。
vsw-uf6n9ipl6qgo****
创建Notebook会话。
创建并启动Notebook会话时,首次启动需要等待大约5分钟。

参数
说明
示例值
会话名称
您可自定义会话名称。
new_session
所属集群
选择上一步骤创建的Spark集群。
spark_test
镜像
选择镜像规格。
Spark3.5_Scala2.12_Python3.9:1.0.9
规格
kernel的资源规格。
4C16G
配置
profile资源。
您可编辑profile的名称、资源释放时长、数据存储位置、Pypi包管理和环境变量信息。
重要资源释放时长:当资源空闲时间超过设置的时长,则会自动释放。资源释放时长设置为0,表示资源永久不会自动释放。
deault_profile
注意事项
确保 Notebook 绑定的 Spark Cluster 与集群实例位于同一交换机下。
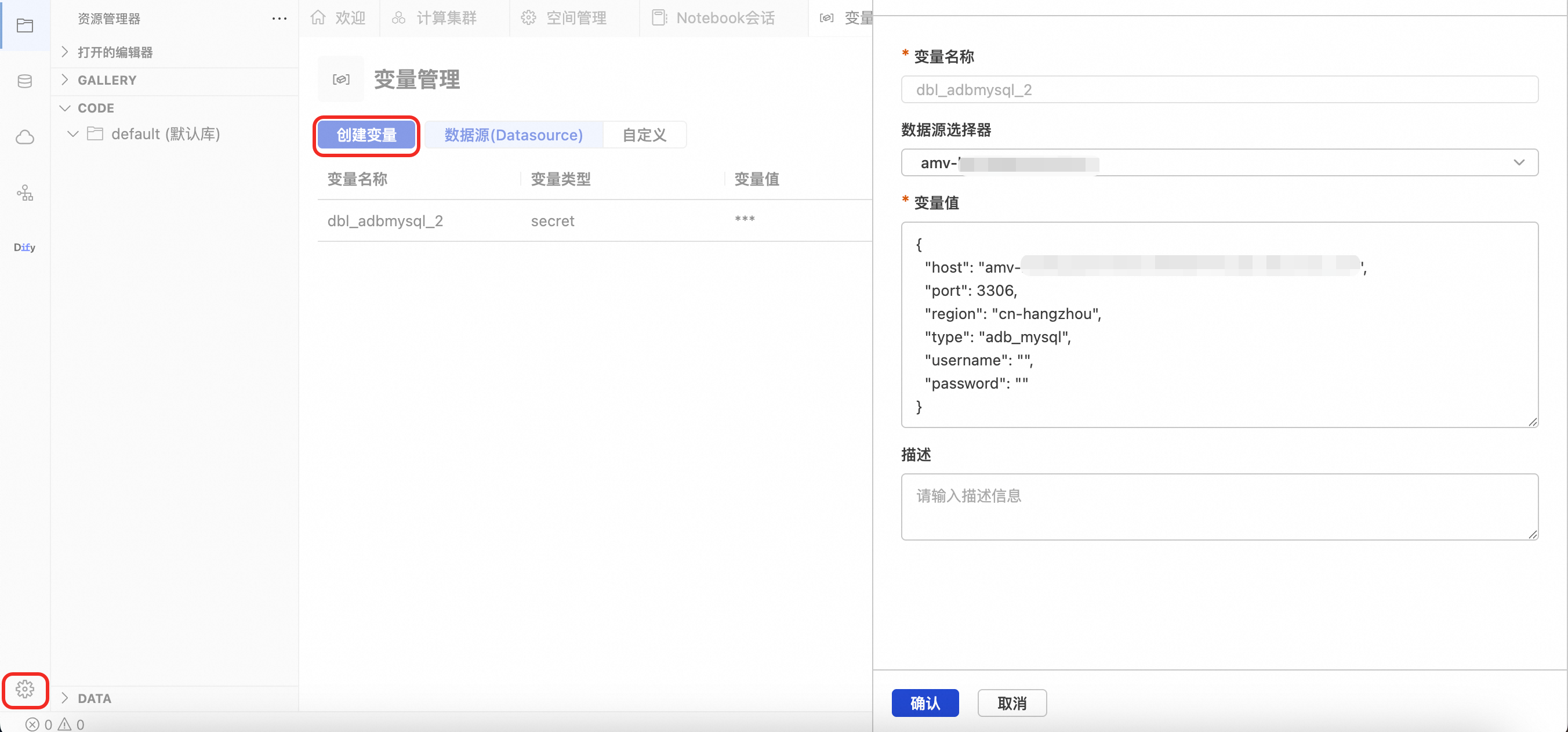
为避免在代码中明文硬编码敏感信息,请在 DMS Notebook 右下角设置中的变量管理,添加数据源变量。
选择数据源后,需填写username与password。
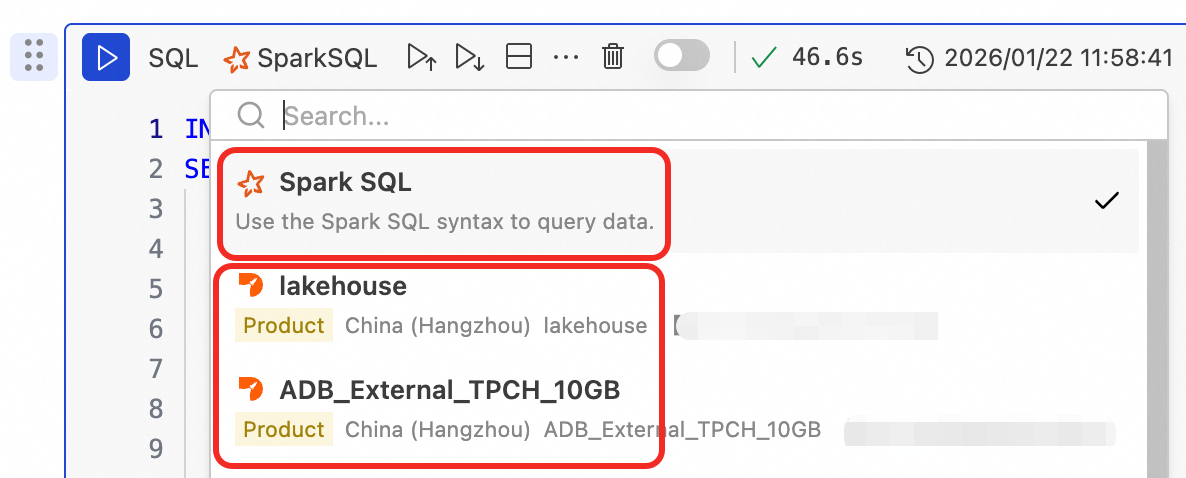
在加工数据的时候,需要在Notebook里切换不同的SQL计算引擎来实现完整的湖仓加工流程。
除Spark SQL外,其余为XIHE引擎(无需特意指定数据库,可在SQL中指定库表名)
湖仓ETL
本案例基于 TPC-H 数据集,演示两种核心场景:
仓转湖:读取实时更新的数据仓库表,加工为宽表写入数据湖,用于数据共享或机器学习。
湖转仓:读取数据湖数据,构建宽表写入数据仓库,支持亚秒级 BI 报表查询。
场景一:读取数仓表,加工宽表并写入数据湖
场景描述
OLTP 数据实时同步至数仓表(贴源层)。Spark 读取贴源层数据,清洗整合成宽表,并存储于数据湖。
步骤一:初始化 Spark Session
在网络信息页面查看交换机ID,可以前往VPC控制台查询该交换机对应的 IPv4 网段,将其加入数据安全-白名单设置并记录。
在ECS 控制台的安全组页面,选择全部类型后,搜索AnalytiDB MySQL实例的集群ID,并记录对应的安全组 ID。
在 Notebook 的 Python 单元格中执行以下代码。请替换:
数据源变量名:
dbl_adbmysql_2交换机ID:
spark.adb.eni.vswitchId安全组ID:
securityGroupId
from pyspark.sql import SparkSession # 获取环境变量 host = dms.get_datasource("dbl_adbmysql_2")['host'] username = dms.get_datasource("dbl_adbmysql_2")['username'] password = dms.get_datasource("dbl_adbmysql_2")['password'] # 初始化 SparkSession,配置 ENI 和 JDBC Catalog spark = SparkSession.builder.appName("FromLakeToWarehouse")\ .config("spark.adb.eni.enabled", "true")\ .config("spark.adb.eni.vswitchId", "vsw-*****")\ .config("spark.adb.eni.securityGroupId", "sg-******") \ .config("spark.sql.catalog.jdbc", "org.apache.spark.sql.execution.datasources.v2.jdbc.JDBCTableCatalog") \ .config("spark.sql.catalog.jdbc.url", f"jdbc:mysql://{host}:3306/?useServerPrepStmts=false&rewriteBatchedStatements=true") \ .config("spark.sql.catalog.jdbc.user", username) \ .config("spark.sql.catalog.jdbc.password", password) \ .getOrCreate()
步骤二:准备数仓源数据
在 SQL 单元格(使用 XIHE 引擎)中执行,模拟数仓中的实时数据。
选择ADB_External_TPCH_10GB执行。
CREATE DATABASE IF NOT EXISTS DATAWAREHOUSE;
# 创建一张非分区表(数据仓库格式)
CREATE TABLE IF NOT EXISTS DATAWAREHOUSE.ORDERS
AS SELECT * FROM ADB_External_TPCH_10GB.External_orders;
#创建一张分区表(数据仓库格式),再写入数据
CREATE TABLE IF NOT EXISTS DATAWAREHOUSE.LINEITEM(
`l_orderkey` bigint NOT NULL COMMENT '',
`l_partkey` int NOT NULL COMMENT '',
`l_suppkey` int NOT NULL COMMENT '',
`l_linenumber` int NOT NULL COMMENT '',
`l_quantity` decimal(15, 2) NOT NULL COMMENT '',
`l_extendedprice` decimal(15, 2) NOT NULL COMMENT '',
`l_discount` decimal(15, 2) NOT NULL COMMENT '',
`l_tax` decimal(15, 2) NOT NULL COMMENT '',
`l_returnflag` varchar(1) NOT NULL COMMENT '',
`l_linestatus` varchar(1) NOT NULL COMMENT '',
`l_shipdate` date NOT NULL COMMENT '',
`l_commitdate` date NOT NULL COMMENT '',
`l_receiptdate` date NOT NULL COMMENT '',
`l_shipinstruct` varchar(25) NOT NULL COMMENT '',
`l_shipmode` varchar(10) NOT NULL COMMENT '',
`l_comment` varchar(1024) NOT NULL COMMENT '',
`dummy` varchar(1024),
PRIMARY KEY(l_orderkey,l_commitdate)
)
DISTRIBUTED BY HASH(l_orderkey)
PARTITION BY VALUE(DATE_FORMAT(l_commitdate, '%Y%m%d'));
-- 写入数据
INSERT INTO DATAWAREHOUSE.LINEITEM
SELECT * FROM ADB_External_TPCH_10GB.External_lineitem;步骤三:生成数据湖快照
将数仓表的全量快照写入数据湖。以下提供两种等效方案,任选其一。
Spark SQL:从数据仓库表读取小数据量加载到数据湖。
XIHE SQL:推荐用于常规快照生成。
Spark SQL
执行前需创建一个绑定 OSS 路径的数据库,作为数据湖的存储根目录,可以让后续的表自动继承路径。后续建表时无需再次指定路径,可以更好地区分湖仓表(额外声明创建一个库用于管理湖表)。
CREATE DATABASE IF NOT EXISTS LAKEHOUSE_DB LOCATION 'oss://<Bucket>/ORDERS_DATALAKE_SNAPSHOT/';
CREATE TABLE IF NOT EXISTS LAKEHOUSE_DB.ORDERS_DATALAKE_SNAPSHOT
USING ICEBERG
AS SELECT * FROM jdbc.DATAWAREHOUSE.ORDERS;
CREATE TABLE IF NOT EXISTS LAKEHOUSE_DB.LINEITEM_DATALAKE_SNAPSHOT
USING ICEBERG
AS SELECT * FROM jdbc.DATAWAREHOUSE.LINEITEM LIMIT 10000;XIHE SQL
替换LOCATION为OSS实际Bucket。-- 快照 Orders 表
CREATE TABLE IF NOT EXISTS DATAWAREHOUSE.ORDERS_DATALAKE_SNAPSHOT
STORED AS ICEBERG
LOCATION 'oss://<Bucket>/ORDERS_DATALAKE_SNAPSHOT/'
AS SELECT * FROM DATAWAREHOUSE.ORDERS;
-- 快照 Lineitem 表
CREATE TABLE IF NOT EXISTS DATAWAREHOUSE.LINEITEM_DATALAKE_SNAPSHOT
STORED AS ICEBERG
LOCATION 'oss://<Bucket>/ORDERS_DATALAKE_SNAPSHOT/'
AS SELECT * FROM DATAWAREHOUSE.LINEITEM;步骤四:生成宽表
(Spark SQL)创建目标 Iceberg 宽表结构。
步骤三采用了Spark SQL方式,额外创建了LAKEHOUSE_DB。如果采用XIHE SQL,请注意后续步骤替换对应数据库名称。
CREATE TABLE IF NOT EXISTS LAKEHOUSE_DB.order_fulfillment_detail (
transaction_id STRING COMMENT '交易流水号',
order_key LONG COMMENT '订单号',
line_number INT COMMENT '明细行号',
order_date DATE COMMENT '下单日期',
ship_date DATE COMMENT '实际发货日期',
commit_date DATE COMMENT '承诺送达日期',
fulfillment_days INT COMMENT '履约耗时(天)',
is_delayed BOOLEAN COMMENT '是否逾期',
ship_mode STRING COMMENT '运输方式',
customer_key LONG COMMENT '客户ID',
clerk_id STRING COMMENT '经手员',
priority STRING COMMENT '优先级',
order_status STRING COMMENT '整单状态',
line_status STRING COMMENT '明细状态',
return_flag STRING COMMENT '退货标记',
quantity DECIMAL(10, 2) COMMENT '数量',
list_amount DECIMAL(18, 2) COMMENT '码价总额',
discount_amount DECIMAL(18, 2) COMMENT '折扣金额',
tax_amount DECIMAL(18, 2) COMMENT '税额',
final_pay_amount DECIMAL(18, 2) COMMENT '实付金额'
)
USING iceberg
PARTITIONED BY (months(order_date));步骤五:写入宽表
选择其中一种方式,将快照数据清洗后写入宽表。
Spark SQL
INSERT OVERWRITE LAKEHOUSE_DB.order_fulfillment_detail
SELECT
CONCAT(CAST(o.o_orderkey AS STRING), '-', CAST(l.l_linenumber AS STRING)) AS transaction_id,
o.o_orderkey AS order_key,
l.l_linenumber AS line_number,
o.o_orderdate AS order_date,
l.l_shipdate AS ship_date,
l.l_commitdate AS commit_date,
DATEDIFF(l.l_shipdate, o.o_orderdate) AS fulfillment_days,
CASE
WHEN l.l_shipdate > l.l_commitdate THEN true
ELSE false
END AS is_delayed,
l.l_shipmode AS ship_mode,
o.o_custkey AS customer_key,
o.o_clerk AS clerk_id,
o.o_orderpriority AS priority,
o.o_orderstatus AS order_status,
l.l_linestatus AS line_status,
l.l_returnflag AS return_flag,
l.l_quantity AS quantity,
l.l_extendedprice AS list_amount,
CAST(l.l_extendedprice * l.l_discount AS DECIMAL(18, 2)) AS discount_amount,
CAST(l.l_extendedprice * (1 - l.l_discount) * l.l_tax AS DECIMAL(18, 2)) AS tax_amount,
CAST(l.l_extendedprice * (1 - l.l_discount) * (1 + l.l_tax) AS DECIMAL(18, 2)) AS final_pay_amount
FROM LAKEHOUSE_DB.ORDERS_DATALAKE_SNAPSHOT o
JOIN LAKEHOUSE_DB.LINEITEM_DATALAKE_SNAPSHOT l
ON o.o_orderkey = l.l_orderkey
WHERE
-- 时间过滤,减少 80% 以上的数据扫描
o.o_orderdate >= '1998-01-01'
-- 状态过滤,只看已下单的活跃订单
AND o.o_orderstatus IN ('O', 'F')
-- 进一步缩小范围(只分析高优先级的订单)
AND o.o_orderpriority IN ('1-URGENT', '2-HIGH');PySpark
from pyspark.sql import SparkSession
from pyspark.sql.functions import (
col, lit, concat, concat_ws, datediff,
when, round, count, sum, avg
)
from pyspark.sql.types import DecimalType
# ==========================================
# 1. 从数据仓库表的Iceberg快照表里,读取源数据 (Reader)
# ==========================================
df_orders = spark.table("LAKEHOUSE_DB.ORDERS_DATALAKE_SNAPSHOT").alias("o")
df_lineitem = spark.table("LAKEHOUSE_DB.LINEITEM_DATALAKE_SNAPSHOT").alias("l")
# ==========================================
# 2. 核心逻辑 (Transformation)
# ==========================================
# 关联逻辑
df_joined = df_orders.join(
df_lineitem,
on=col("o.o_orderkey") == col("l.l_orderkey"),
how="inner")
# 计算与字段映射逻辑
df_result = df_joined.select(
# --- 唯一标识 ---
# 使用 concat_ws (With Separator) 拼接主键,比 SQL 的 concat 更优雅
concat_ws("-", col("o.o_orderkey"), col("l.l_linenumber")).alias("transaction_id"),
col("o.o_orderkey").alias("order_key"),
col("l.l_linenumber").alias("line_number"),
# --- 时间与履约 ---
col("o.o_orderdate").alias("order_date"),
col("l.l_shipdate").alias("ship_date"),
col("l.l_commitdate").alias("commit_date"),
# 履约耗时 (Datediff)
datediff(col("l.l_shipdate"), col("o.o_orderdate")).alias("fulfillment_days"),
# 是否逾期 (Boolean 逻辑)
(col("l.l_shipdate") > col("l.l_commitdate")).alias("is_delayed"),
col("l.l_shipmode").alias("ship_mode"),
# --- 业务属性 ---
col("o.o_custkey").alias("customer_key"),
col("o.o_clerk").alias("clerk_id"),
col("o.o_orderpriority").alias("priority"),
col("o.o_orderstatus").alias("order_status"),
col("l.l_linestatus").alias("line_status"),
col("l.l_returnflag").alias("return_flag"),
# --- 财务指标 (注意类型转换) ---
col("l.l_quantity").cast(DecimalType(10, 2)).alias("quantity"),
col("l.l_extendedprice").cast(DecimalType(18, 2)).alias("list_amount"),
# 折扣金额 = Price * Discount
(col("l.l_extendedprice") * col("l.l_discount"))
.cast(DecimalType(18, 2)).alias("discount_amount"),
# 税额 = Price * (1 - Discount) * Tax
(col("l.l_extendedprice") * (1 - col("l.l_discount")) * col("l.l_tax"))
.cast(DecimalType(18, 2)).alias("tax_amount"),
# 实付金额 = Price * (1 - Discount) * (1 + Tax)
(col("l.l_extendedprice") * (1 - col("l.l_discount")) * (1 + col("l.l_tax")))
.cast(DecimalType(18, 2)).alias("final_pay_amount")
)
# ==========================================
# 3. 写入数据到数据湖 (Writer)
# ==========================================
TARGET_TABLE = "LAKEHOUSE_DB.order_fulfillment_detail"
print(f"正在写入表: {TARGET_TABLE} ...")
df_result.writeTo(TARGET_TABLE) \
.overwritePartitions() # 或者 .overwrite() 视需求而定
print(">>> ETL 完成!")步骤六:查询数据
Spark SQL查询。
SELECT * FROM LAKEHOUSE_DB.order_fulfillment_detail;场景二:从数据湖加载数据到数据仓库
场景描述
将数据湖中的原始数据(Part 和 Partsupp)加工成宽表,写入数据仓库(Hot Storage),以支持高性能查询。
步骤一:初始化 Spark Session
在网络信息页面查看交换机ID,可以前往VPC控制台查询该交换机对应的 IPv4 网段,将其加入数据安全-白名单设置并记录。
在ECS 控制台的安全组页面,选择全部类型后,搜索AnalytiDB MySQL实例的集群ID,并记录对应的安全组 ID。
在 Notebook 的 Python 单元格中执行以下代码。请替换:
数据源变量名:
dbl_adbmysql_2交换机ID:
spark.adb.eni.vswitchId安全组ID:
securityGroupId
from pyspark.sql import SparkSession # 获取环境变量 host = dms.get_datasource("dbl_adbmysql_2")['host'] username = dms.get_datasource("dbl_adbmysql_2")['username'] password = dms.get_datasource("dbl_adbmysql_2")['password'] # 初始化 SparkSession,配置 ENI 和 JDBC Catalog spark = SparkSession.builder.appName("FromLakeToWarehouse")\ .config("spark.adb.eni.enabled", "true")\ .config("spark.adb.eni.vswitchId", "vsw-*****")\ .config("spark.adb.eni.securityGroupId", "sg-******") \ .config("spark.sql.catalog.jdbc", "org.apache.spark.sql.execution.datasources.v2.jdbc.JDBCTableCatalog") \ .config("spark.sql.catalog.jdbc.url", f"jdbc:mysql://{host}:3306/?useServerPrepStmts=false&rewriteBatchedStatements=true") \ .config("spark.sql.catalog.jdbc.user", username) \ .config("spark.sql.catalog.jdbc.password", password) \ .getOrCreate()
步骤二:准备湖仓源数据
(Spark SQL)在 LAKEHOUSE 中创建 Iceberg 格式的源表。
CREATE DATABASE IF NOT EXISTS LAKEHOUSE LOCATION 'oss://<bucket>/iceberg/';
CREATE TABLE IF NOT EXISTS LAKEHOUSE.Part
USING ICEBERG
AS SELECT * FROM ADB_External_TPCH_10GB.External_Part;
CREATE TABLE IF NOT EXISTS LAKEHOUSE.partsupp
USING ICEBERG
PARTITIONED BY (bucket(64, ps_partkey))
AS SELECT * FROM ADB_External_TPCH_10GB.External_Partsupp;步骤三:创建目标数仓表
(XIHE SQL)在数据仓库中预先创建目标表。
CREATE DATABASE IF NOT EXISTS DATAWAREHOUSE;
CREATE TABLE IF NOT EXISTS DATAWAREHOUSE.product_inventory_analysis (
`sku_id` varchar NOT NULL COMMENT 'SKU唯一标识(PartKey-SuppKey)',
`part_key` bigint NOT NULL COMMENT '商品ID',
`supplier_key` bigint NOT NULL COMMENT '供应商ID',
`part_name` varchar NOT NULL COMMENT '商品名称',
`brand` varchar NOT NULL COMMENT '品牌',
`type` varchar NOT NULL COMMENT '类型',
`size` int NOT NULL COMMENT '尺寸',
`container` varchar NOT NULL COMMENT '包装方式',
`stock_qty` int NOT NULL COMMENT '当前库存数量',
`supply_cost` decimal(18, 2) NOT NULL COMMENT '进货成本(单价)',
`retail_price` decimal(18, 2) NOT NULL COMMENT '建议零售价',
`total_inv_cost` decimal(18, 2) NOT NULL COMMENT '库存总资金占用 (数量*进货价)',
`potential_revenue` decimal(18, 2) NOT NULL COMMENT '库存潜在营收 (数量*零售价)',
`unit_margin_amt` decimal(18, 2) NOT NULL COMMENT '单件潜在毛利 (零售价-进货价)',
`margin_rate` decimal(10, 4) NOT NULL COMMENT '潜在毛利率 ((零售-进货)/零售)',
`is_underwater` boolean NOT NULL COMMENT '是否价格倒挂 (进货价 > 零售价)'
) DISTRIBUTE BY HASH (`sku_id`);步骤四:写入数据仓库
通过JDBC连接器写入仓表,目标表名必须包含jdbc.前缀。即jdbc.DATAWAREHOUSE.product_inventory_analysis。
Spark SQL
INSERT INTO jdbc.DATAWAREHOUSE.product_inventory_analysis
SELECT
-- 1. 生成SKU主键
CONCAT(CAST(p.p_partkey AS STRING), '-', CAST(ps.ps_suppkey AS STRING)) AS sku_id,
p.p_partkey AS part_key,
ps.ps_suppkey AS supplier_key,
-- 2. 商品维度
p.p_name AS part_name,
p.p_brand AS brand,
p.p_type AS type,
p.p_size AS size,
p.p_container AS container,
-- 3. 基础度量
ps.ps_availqty AS stock_qty,
ps.ps_supplycost AS supply_cost,
p.p_retailprice AS retail_price,
-- 4. 资金占用 (Inventory Value)
CAST(ps.ps_availqty * ps.ps_supplycost AS DECIMAL(18, 2)) AS total_inv_cost,
-- 5. 潜在营收 (Potential GMV)
CAST(ps.ps_availqty * p.p_retailprice AS DECIMAL(18, 2)) AS potential_revenue,
-- 6. 单件毛利 (Unit Margin)
CAST(p.p_retailprice - ps.ps_supplycost AS DECIMAL(18, 2)) AS unit_margin_amt,
-- 7. 毛利率 (Margin Rate)
CAST(
CASE
WHEN p.p_retailprice = 0 THEN 0
ELSE (p.p_retailprice - ps.ps_supplycost) / p.p_retailprice
END
AS DECIMAL(10, 4)) AS margin_rate,
-- 8. 倒挂风险判断
CASE
WHEN ps.ps_supplycost > p.p_retailprice THEN true
ELSE false
END AS is_underwater
FROM LAKEHOUSE.part p
JOIN LAKEHOUSE.partsupp ps
ON p.p_partkey = ps.ps_partkey;PySpark
from pyspark.sql import SparkSession
from pyspark.sql.functions import (col, lit, concat, when, cast)
from pyspark.sql.types import DecimalType, BooleanType
df_part = spark.table("LAKEHOUSE.part").alias("p")
df_partsupp = spark.table("LAKEHOUSE.partsupp").alias("ps")
df_joined = df_part.join(
df_partsupp,
on=col("p.p_partkey") == col("ps.ps_partkey"),
how="inner"
)
# 核心计算与转换逻辑
df_result = df_joined.select(
# --- 1. 生成 SKU 主键 ---
# SQL: CONCAT(CAST(p.p_partkey AS STRING), '-', CAST(ps.ps_suppkey AS STRING))
concat(
col("p.p_partkey").cast("string"),
lit("-"),
col("ps.ps_suppkey").cast("string")
).alias("sku_id"),
col("p.p_partkey").alias("part_key"),
col("ps.ps_suppkey").alias("supplier_key"),
# --- 2. 商品维度 ---
col("p.p_name").alias("part_name"),
col("p.p_brand").alias("brand"),
col("p.p_type").alias("type"),
col("p.p_size").alias("size"),
col("p.p_container").alias("container"),
# --- 3. 基础度量 ---
col("ps.ps_availqty").alias("stock_qty"),
col("ps.ps_supplycost").alias("supply_cost"),
col("p.p_retailprice").alias("retail_price"),
# --- 4. 资金占用 (Inventory Value) ---
# SQL: CAST(ps.ps_availqty * ps.ps_supplycost AS DECIMAL(18, 2))
(col("ps.ps_availqty") * col("ps.ps_supplycost"))
.cast(DecimalType(18, 2)).alias("total_inv_cost"),
# --- 5. 潜在营收 (Potential GMV) ---
# SQL: CAST(ps.ps_availqty * p.p_retailprice AS DECIMAL(18, 2))
(col("ps.ps_availqty") * col("p.p_retailprice"))
.cast(DecimalType(18, 2)).alias("potential_revenue"),
# --- 6. 单件毛利 (Unit Margin) ---
# SQL: CAST(p.p_retailprice - ps.ps_supplycost AS DECIMAL(18, 2))
(col("p.p_retailprice") - col("ps.ps_supplycost"))
.cast(DecimalType(18, 2)).alias("unit_margin_amt"),
# --- 7. 毛利率 (Margin Rate) ---
# 必须处理分母为 0 的情况
# SQL: CASE WHEN p.p_retailprice = 0 THEN 0 ELSE (P-C)/P END
when(col("p.p_retailprice") == 0, lit(0))
.otherwise(
(col("p.p_retailprice") - col("ps.ps_supplycost")) / col("p.p_retailprice")
).cast(DecimalType(10, 4)).alias("margin_rate"),
# --- 8. 倒挂风险判断 ---
# SQL: CASE WHEN cost > price THEN true ELSE false END
when(col("ps.ps_supplycost") > col("p.p_retailprice"), lit(True))
.otherwise(lit(False))
.alias("is_underwater")
)
# ==========================================
# 写入数据仓库表 (DATAWAREHOUSE 层)
# ==========================================
# 根据 SQL 的 INSERT INTO jdbc.DATAWAREHOUSE... 映射目标表
TARGET_TABLE = "jdbc.DATAWAREHOUSE.product_inventory_analysis"
print(f"正在准备写入数据至: {TARGET_TABLE} ...")
try:
df_result.write \
.format("adb") \
.mode("append") \
.saveAsTable(TARGET_TABLE)
print(">>> ETL 任务执行完成!数据已成功存入仓库。")
except Exception as e:
print(f">>> ETL 任务失败,报错原因: {str(e)}")
步骤五:查询数据
Spark SQL查询。
SELECT * FROM DATAWAREHOUSE.product_inventory_analysis LIMIT 1000;