随着物联网、云原生和微服务架构的普及,系统产生的时序数据量呈爆炸式增长。传统的监控和存储方案在面对海量数据的实时写入、快速查询和长期存储时,往往显得力不从心。AnalyticTimeMetrics 作为一款高性能、低成本、高可用的时序数据库,旨在解决大规模指标监控和分析的痛点。
核心特性

AnalyticTimeMetrics 具备以下核心特性:
极致的性能:无论是写入吞吐量还是查询延迟,AnalyticTimeMetrics 都表现出色。它针对时序数据的特点进行了深度优化,能够以极高的速度摄取数据,并支持毫秒级的复杂查询响应。
极高的成本效益:相比同类产品,AnalyticTimeMetrics 在数据压缩方面表现卓越。其高效的压缩算法显著降低了磁盘 I/O 和存储成本,使得长期存储海量历史数据变得经济可行。
高可用部署模式:提供集群版形态,面向超大规模场景,支持水平扩展,无单点故障,可线性扩展写入和查询能力。
Prometheus 兼容性:无缝兼容 Prometheus 的远程读写协议和 PromQL 查询语言,使得现有 Prometheus 生态的用户可以平滑迁移,无需更改现有监控配置。
架构设计
AnalyticTimeMetrics 集群版的核心架构如下:
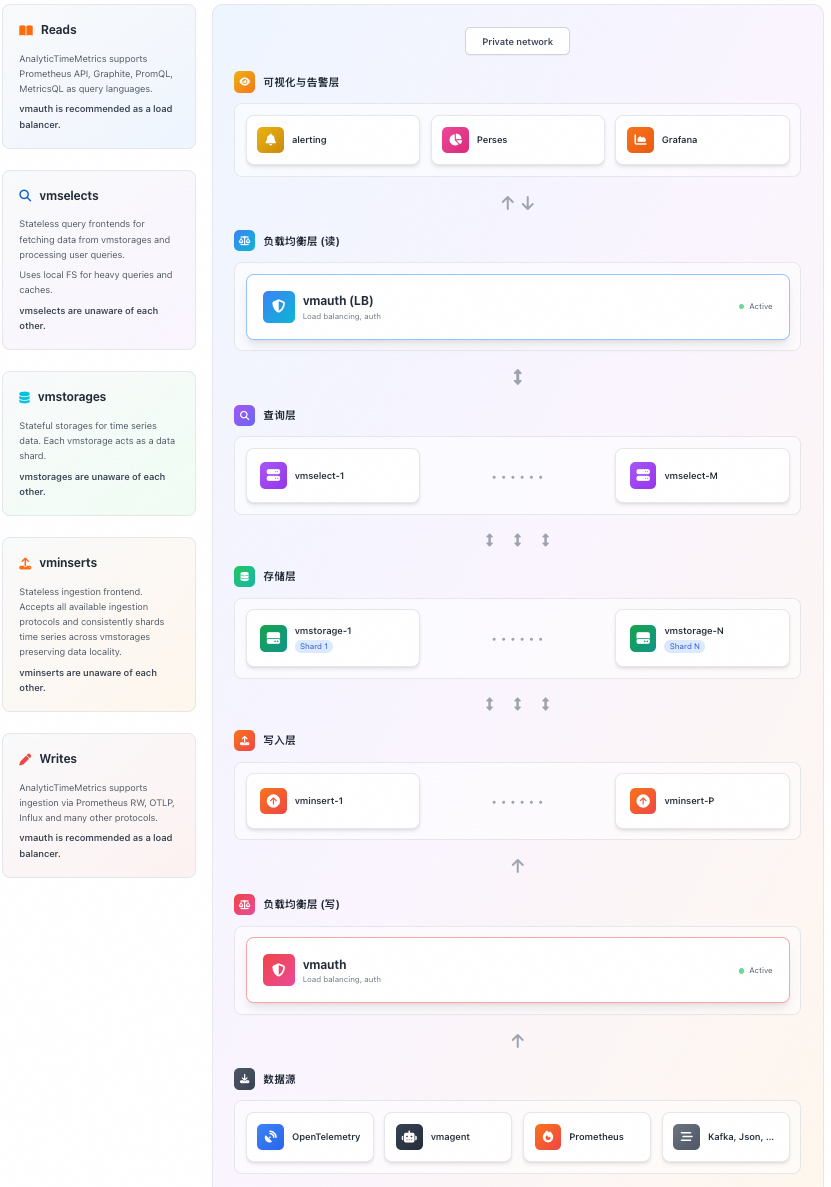
核心组件
组件 | 类型 | 说明 |
vminsert | 写入层 | 接收数据,负责分片和负载均衡。 |
vmstorage | 存储层 | 负责数据的持久化存储,处理数据压缩和索引。 |
vmselect | 查询层 | 接收查询请求,从获取数据并聚合结果。 |
生态组件:
组件 | 说明 |
vmagent | 指标抓取和远程写入。 |
vmalert | 规则计算和告警评估。 |
性能分析
写入性能
AnalyticTimeMetrics的写入性能经过极致优化。在集群版中,写入入口由组件负责。它能够接收来自Prometheus、VMAgent或其他客户端的高并发写入请求。负责数据校验、压缩和分片,并将数据高效分发到后端的存储节点。AnalyticTimeMetrics支持乱序数据写入,并且针对高并发写入场景进行了优化,能够轻松应对每秒数百万甚至上千万的数据点写入。
查询性能
查询入口由组件处理。它接收PromQL或AnalyticTimeMetrics增强的MetricsQL查询请求,将查询分发到相关的存储节点,聚合结果后返回。AnalyticTimeMetrics构建了高效的倒排索引,使得基于标签的过滤和聚合操作非常迅速。同时,查询缓存机制进一步提升了重复查询的响应速度。
vmagent 与 Prometheus 抓取性能对比
以下基准测试展示了 vmagent 相比 Prometheus 原生抓取组件的性能优势。
测试环境:Intel Core i7-6700 CPU,32 GB RAM,1 TB SSD
测试场景:模拟大规模微服务监控环境,配置 10000 个抓取目标,约 100 万个唯一时间序列,抓取间隔 30 秒。
指标 | Prometheus 2.37.0 | vmagent | 对比 |
内存占用(RSS) | 约 1.8 GB | 约 400 MB | vmagent 内存效率约为 Prometheus 的 4 倍以上,极大降低了在资源受限环境(如边缘计算节点)中的部署门槛。 |
CPU 利用率峰值 | 约 70%(单核) | 约 25% | vmagent CPU 占用显著更低,意味着服务器可以将更多计算资源分配给核心业务应用。 |
抓取延迟与稳定性(面对目标数量突增或 scrape interval 波动) | 错误率约 0.5%(偶发抓取超时或样本丢失) | 错误率低于 0.01% | vmagent 凭借异步非阻塞架构,稳定性与可靠性极高,确保了监控数据的完整性。 |
成本优势
存储成本
AnalyticTimeMetrics采用列式存储,以极低的成本存储海量数据(通常压缩比可达 10:1 到 50:1,甚至更高),将时间戳、数值和标签分开存储,并针对每种数据类型应用了不同的压缩策略。
数据类型 | 核心算法 | 原理 | 效果 |
时间戳 | Delta-of-Delta(DoD) | 对“差值的差值”进行编码 | 将时间戳转化为极小的整数,几乎接近 0。 |
浮点数值 | Gorilla(XOR) | 异或运算存储变化位 | 波动小的数值压缩率极高。 |
整型数值 | ZSTD / LZ4 | 通用压缩算法 | 快速且高压缩比。 |
标签/元数据 | 字典编码 + ZSTD | 全局去重 + 压缩 | 消除重复字符串,大幅减小索引体积。 |
硬件成本
AnalyticTimeMetrics 的高资源利用效率使其可以在较低配置的硬件上运行,或在相同硬件上处理更多数据,降低总体拥有成本。
默认采用高效云盘ESSD(PL1 等级)。如有极高读写要求,可提交工单升级到 PL2 或 PL3 等级。
高可用性
高可用架构
AnalyticTimeMetrics 集群版采用无单点故障设计,核心组件均可水平扩展:
单可用区,多副本部署:建议每个服务至少运行两个节点,以实现高可用。
故障转移:当某个节点不可用时,写入和查询自动路由到其他健康节点,剩余节点分担负载,保证服务不中断。
数据安全
数据复制:AnalyticTimeMetrics 原生不提供跨节点数据复制(以简化架构),推荐在同一子网内部署集群,并利用云服务的存储复制功能或外部工具保证数据安全。
一致性:通过精确的配置,可处理重复和乱序数据,保证数据一致性。
运维建议
同子网部署:将集群所有组件部署在同一高带宽、低延迟的子网内,提升性能和可用性,避免跨可用区网络不稳定性。
小而多的存储节点:相比少数大容量节点,推荐运行多个小容量节点,这样在节点故障时,剩余节点的负载增加更平缓。
易用性
丰富的组件生态
AnalyticTimeMetrics 提供了一整套工具,覆盖了监控的各个环节:
vmagent:高性能的抓取组件,可作为 Prometheus 的替代,支持服务发现和远程写入。
vmalert:负责执行告警规则和记录规则,从数据源拉取指标进行计算。
vmalertmanager:兼容 Prometheus Alertmanager,负责告警的路由、分组、静默和通知(支持邮件、钉钉、飞书等)。
直观的可视化
强大的内置可视化界面:AnalyticTimeMetrics 内置了可视化 UI,这是一个基于 Web 的轻量级界面,旨在为用户提供便捷的查询与可视化体验,无需依赖外部工具即可完成日常的数据探索。
可视化查询与探索:支持在查询框中输入 MetricsQL/PromQL 语句,并提供自动补全功能。查询结果可以直观地以图表或表格形式展示,支持图表的缩放、滚动和拖动,方便用户查看不同时间范围的数据趋势。
生产排错利器:在排查生产环境问题时,提供了 Raw Query 功能,允许用户查看原始样本数据,这对于调试意外的查询结果非常有效。同时,它还能展示 Top Queries 和 Active Queries,帮助运维人员识别高频或耗时的查询,从而优化系统性能。
高基数治理助手:针对时序数据中常见的高基数问题(即指标标签过多导致数据膨胀),可视化 UI 提供了专门的工具来辅助发现基数过大的指标。通过它,用户可以快速定位设计不合理的标签,进行周期性巡检和治理,从而有效控制数据量,提升查询效率并节省存储资源。