本文介绍使用节点自动伸缩功能时可能遇到的常见问题及解决方案。
索引
分类 | 二级分类 | 跳转链接 |
节点自动伸缩的扩缩容行为 | ||
自定义的扩缩容行为 | ||
cluster-autoscaler组件相关 | ||
已知限制
无法100%精确预估节点可用资源
由于ECS底层系统会占用部分资源,因此实例可用内存会小于实例规格定义(请参见购买实例后查看内存大小,为什么和购买时的实例规格定义不一致?)。受此约束,cluster-autoscaler组件估算的节点可调度资源可能大于实际节点的可调度资源,无法100%精确预估。您在配置Pod Request时,需关注以下注意事项。
配置Pod Request取值时,资源申请总量需小于实例规格定义(包括CPU、内存、磁盘等)。建议Request总量不超过节点资源的70%。
cluster-autoscaler组件在判断节点的资源是否充足时仅会考虑Kubernetes Pod(Pending Pod和DaemonSet Pod)资源。如果节点上存在非DaemonSet的Static Pod,需预先为此类Pod预留资源。
如果Pod资源申请占用的确较大(例如超过节点资源70%时),请提前测试并确认Pod是否可调度到同实例规格的节点上,保证可行性。
支持有限的调度策略
cluster-autoscaler组件仅支持有限的调度策略来判断不可调度Pod能否调度到开启弹性的节点池,详情请参见下文cluster-autoscaler组件使用哪些调度策略来判断不可调度Pod能否调度到开启了弹性的节点池?。
仅支持基于resource类型的Resource Policy
使用Resource Policy自定义弹性资源优先级时,仅支持基于resource类型的策略,请参见自定义弹性资源优先级调度。
apiVersion: scheduling.alibabacloud.com/v1alpha1
kind: ResourcePolicy
metadata:
name: nginx
namespace: default
spec:
selector:
app: nginx
units:
- resource: ecs
- resource: eci配置多实例规格的节点池不支持扩容指定实例规格
如果您的节点池同时配置了多个实例规格,扩容时无法指定扩容某个实例规格。cluster-autoscaler组件会以资源维度在各个实例规格中取最小值,作为资源计算的基准,详情请参见下文如果一个伸缩组内配置了多资源类型的实例规格,弹性伸缩时如何计算这个伸缩组的资源呢?。
依赖特定可用区运行的Pod无法触发多可用区的节点池扩容
如果您的节点池配置了多可用区,且有Pod依赖特定可用区运行,例如Pod使用的PVC指定了位于特定可用区的某个存储卷,或Pod带有特定可用区的nodeSelector,那么cluster-autoscaler组件可能无法弹出对应可用区的节点。更多cluster-autoscaler组件无法弹出节点的场景,请参见下文为什么节点自动伸缩组件无法弹出节点?。
存储约束问题
节点伸缩组件在决策时无法感知Pod对存储资源的特定约束,例如指定使用特定可用区、特定磁盘类型(如ESSD)的PV等。
如应用依赖此类存储,请在启用节点弹性伸缩前配置专用的节点池。通过为节点池预设好可用区、实例规格、磁盘类型等配置,确保新扩容的节点能满足存储挂载要求,以避免Pod因资源不匹配而调度或启动失败。
此外,请确保 Pod 没有引用处于 Terminating 状态的 PVC, Pod 因 PVC Terminating会持续调度失败。这种情况会误导 Cluster Autoscaler 做出错误的扩容或缩容决策(例如驱逐该 Pod)。
扩容行为相关
cluster-autoscaler组件使用哪些调度策略来判断不可调度Pod能否调度到开启了弹性的节点池?
使用的调度策略如下所示。
PodFitsResources
GeneralPredicates
PodToleratesNodeTaints
MaxGCEPDVolumeCount
NoDiskConflict
CheckNodeCondition
CheckNodeDiskPressure
CheckNodeMemoryPressure
CheckNodePIDPressure
CheckVolumeBinding
MaxAzureDiskVolumeCount
MaxEBSVolumeCount
ready
NoVolumeZoneConflict
cluster-autoscaler组件可模拟判断的资源有哪些?
cluster-autoscaler组件已经支持以下资源的模拟和判断:
cpu
memory
sigma/eni
ephemeral-storage
aliyun.com/gpu-mem (仅共享GPU)
nvidia.com/gpu如果需要其他资源类型,请参见开启弹性的节点池如何配置自定义资源?。
为什么节点自动伸缩组件无法弹出节点?
请检查是否存在如下几种场景:
节点自动伸缩仅对设置了自动扩缩容的节点池生效,请确保节点自动伸缩功能已开启,并且已设置节点池的扩缩容模式为自动。具体操作请参见启用节点自动伸缩。
配置伸缩组的实例类型无法满足Pod的资源申请(Request)。ECS实例规格给出的资源大小是实例的售卖规格,实际运行时ACK需要占用一定的节点资源来为系统组件和进程预留资源,从而保证OS内核和系统服务、Kubernetes守护进程的正常运行。这会导致节点的资源总数Capacity与可分配的资源数Allocatable之间存在差异。
cluster-autoscaler组件在进行节点扩容决策时,其内置的资源预留策略在所有ACK集群版本中均保持一致,采用1.28及以下版本的资源预留策略。
如需应用1.28及以上版本的资源预留策略,推荐切换使用启用节点即时弹性(1.28及以上版本内置了新资源预留算法),或手动配置并维护节点池的自定义资源(在节点池中自行定义和维护资源预留值)。
在创建实例的过程中会因虚拟化、操作系统等占用部分资源。更多信息,请参见购买实例后查看内存大小,为什么和购买时的实例规格定义不一致?。
需要占用一定的节点资源来运行相关组件(例如kubelet、kube-proxy、Terway、Container Runtime等)。详细信息,请参见节点资源预留策略。
默认节点会安装系统组件,Pod的申请资源要小于实例的规格。
对可用区有约束的Pod,无法触发配置了多可用区的节点池扩容。
是否完整按照步骤执行了授权操作。授权操作是集群维度的,需要每个集群操作一次。关于授权,请参见前提条件的内容。
开启自动伸缩的节点池中出现如下异常情况。
实例未加入到集群且超时。
节点NotReady且超时。
为保证后续扩缩准确性,弹性组件以阻尼方式处理异常情况,在处理完异常情况节点前,不进行扩缩容。
集群中没有节点,弹性伸缩组件cluster-autoscaler组件无法运行。建议您在创建节点池时至少配置2个节点,以确保集群组件的正常运行。
若您的使用场景为从0节点开始扩容或缩容到0节点,您可以使用节点即时弹性,请参见启用节点即时弹性。
如果一个伸缩组内配置了多资源类型的实例规格,弹性伸缩时如何计算这个伸缩组的资源呢?
对于配置了多个实例规格的伸缩组,弹性伸缩组件以资源维度在各个实例规格中取最小值,作为资源计算的基准。
例如,如果一个伸缩组内配置了两种实例规格,一个是CPU 4核内存32 GB,另一个是CPU 8核内存16 GB。弹性伸缩组件认为这个伸缩组能保证的扩容出的CPU是4核内存16 GB的实例资源。因此如果状态为Pending的Pod的requests资源超出4核或者16 GB,则不会进行扩容。
如果您配置了多实例规格但需要考虑资源预留,请参见为什么节点自动伸缩组件无法弹出节点?。
弹性伸缩时,如何在多个开启弹性的节点池之间进行选择?
在Pod处在无法调度时,会触发弹性伸缩组件的模拟调度逻辑,根据伸缩组配置的标签、污点以及实例规格等信息进行判断。当配置的伸缩组可以模拟调度Pod的时候,就会被选择进行节点弹出。当有多个开启弹性的节点池同时满足模拟调度条件时,节点自动伸缩组件默认采用最少浪费(least-waste)原则,即根据模拟弹出后节点上剩余的资源最小为原则进行选择。
开启弹性的节点池如何配置自定义资源?
通过为开启弹性的节点池配置如下固定前缀的ECS标签(Tag),可以让弹性组件识别到已开启弹性的节点池中可供给的自定义资源,或者识别到指定的某些资源的精确值。
k8s.io/cluster-autoscaler/node-template/resource/{资源名}:{资源大小}示例:
k8s.io/cluster-autoscaler/node-template/resource/hugepages-1Gi:2Gi为什么为节点池设置自动扩缩容失败?
可能原因如下:
节点池类型为默认节点池,不支持设置节点自动伸缩功能。
节点池中已有通过手动添加的节点,您需要先移除手动添加的节点。建议您创建新的开启自动扩缩容的节点池。
节点池中有包年包月的实例。节点自动伸缩功能不支持包年包月付费类型的节点。
缩容行为相关
为什么cluster-autoscaler组件无法缩容节点?
请检查是否存在如下几种场景:
节点Pod的资源申请(Request)阈值高于设置的缩容阈值。
节点上运行kube-system命名空间的Pod。
节点上的Pod包含强制的调度策略,导致其他节点无法运行此Pod。
节点上的Pod拥有PodDisruptionBudget,且到达了PodDisruptionBudget的最小值。
您可以在开源社区得到更多关于节点自动伸缩组件的常见问题与解答。
如何启用或禁用特定DaemonSet的驱逐?
cluster-autoscaler组件会根据是否开启 Daemonset Pod 排水配置决定是否驱逐DaemonSet Pods,这些配置是集群维度的,对集群中的DaemonSet Pods通用。更多信息,请参见步骤一:为集群开启节点自动伸缩功能。如果想要对某个DaemonSet Pod指定是否需要被驱逐,可以对这个DaemonSet Pod添加Annotation"cluster-autoscaler.kubernetes.io/enable-ds-eviction":"true"。
类似的,DaemonSet Pod的Annotation中如果有"cluster-autoscaler.kubernetes.io/enable-ds-eviction":"false",则会显示禁止Cluster Autoscaler驱逐这个DaemonSet Pod。
如果未开启DaemonSet Pod排水,此Annotation仅对非空节点的DaemonSet Pod有效。如果想开启空节点DaemonSet Pod,需要先开启DaemonSet Pod排水。
此Annotation需要在DaemonSet Pod上指定,而不是DaemonSet对象本身。
此Annotation对不属于任何DaemonSet的Pod没有影响。
默认情况下,Cluster Autoscaler对DaemonSet Pod的驱逐是非阻塞模式的,即不等待DaemonSet Pod驱逐完成后,就会执行后续流程。如需要Cluster Autoscaler等待指定DaemonSet Pod驱逐完成后再执行后续缩容流程,除以上启用配置外,请为相应Pod添加Annotation
"cluster-autoscaler.kubernetes.io/wait-until-evicted":"true"。
什么类型的Pod可以阻止cluster-autoscaler组件移除节点?
当Pod不是由原生Kubernetes Controller创建的Pod(例如非Deployment、ReplicaSet、Job、StatefulSet等对象创建的Pod),或者当节点上的Pod不能被安全地终止或迁移时,cluster-autoscaler组件可能会阻止移除这个节点。详细信息,请参见什么类型的Pod可以阻止CA移除节点?。
拓展支持相关
cluster-autoscaler组件是否支持CRD?
cluster-autoscaler组件目前仅支持Kubernetes标准对象,暂时不支持Kubernetes CRD。
通过Pod控制扩缩容行为
如何延迟cluster-autoscaler组件对不可调度Pod的扩容反应时间?
可以通过Annotationcluster-autoscaler.kubernetes.io/pod-scale-up-delay为每个Pod设置延迟扩容时间。如果Kubernetes没有在该延迟结束时调度它们,那么CA可能会考虑对它们进行扩展。Annotation示例:"cluster-autoscaler.kubernetes.io/pod-scale-up-delay": "600s"。
如何通过Pod Annotation影响cluster-autoscaler组件的节点缩容?
您可以指定Pod阻止或不阻止节点被cluster-autoscaler组件缩容。
阻止节点被缩容:为Pod添加Annotation
"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"。不阻止节点被缩容:为Pod添加Annotation
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true"。
通过节点控制扩缩容行为
如何指定节点不被cluster-autoscaler组件缩容?
为目标节点配置Annotation "cluster-autoscaler.kubernetes.io/scale-down-disabled": "true",使其不被cluster-autoscaler缩容。添加Annotation的命令示例如下。
kubectl annotate node <nodename> cluster-autoscaler.kubernetes.io/scale-down-disabled=truecluster-autoscaler组件相关
如何升级cluster-autoscaler组件至最新版本?
对于已开启集群自动弹性伸缩的集群,可通过以下方式升级cluster-autoscaler组件。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
单击节点伸缩右侧的编辑,然后在面板下方单击确定,即可升级组件至最新版本。
哪些操作会触发cluster-autoscaler组件自动更新?
为保证cluster-autoscaler组件配置的实时性、版本与集群的兼容性,以下操作会触发cluster-autoscaler组件自动更新:
更新自动伸缩配置。
创建、删除、更新开启弹性节点池。
成功升级集群。
ACK托管集群已经完成了角色授权,但节点伸缩活动仍然无法正常运行?
可能是集群kube-system命名空间下保密字典内不存在addon.aliyuncsmanagedautoscalerrole.token而导致的。ACK默认通过WorkRole实现相关能力,请参见下方流程为手动集群WorkerRole添加AliyunCSManagedAutoScalerRolePolicy的权限。
在ACK集群列表页面,单击目标集群名称,在集群详情页左侧导航栏,选择。
在节点池页面,单击节点伸缩后方的去配置。
按照页面提示,完成KubernetesWorkerRole角色授权和AliyunCSManagedAutoScalerRolePolicy系统策略的授权,入口如下所示。
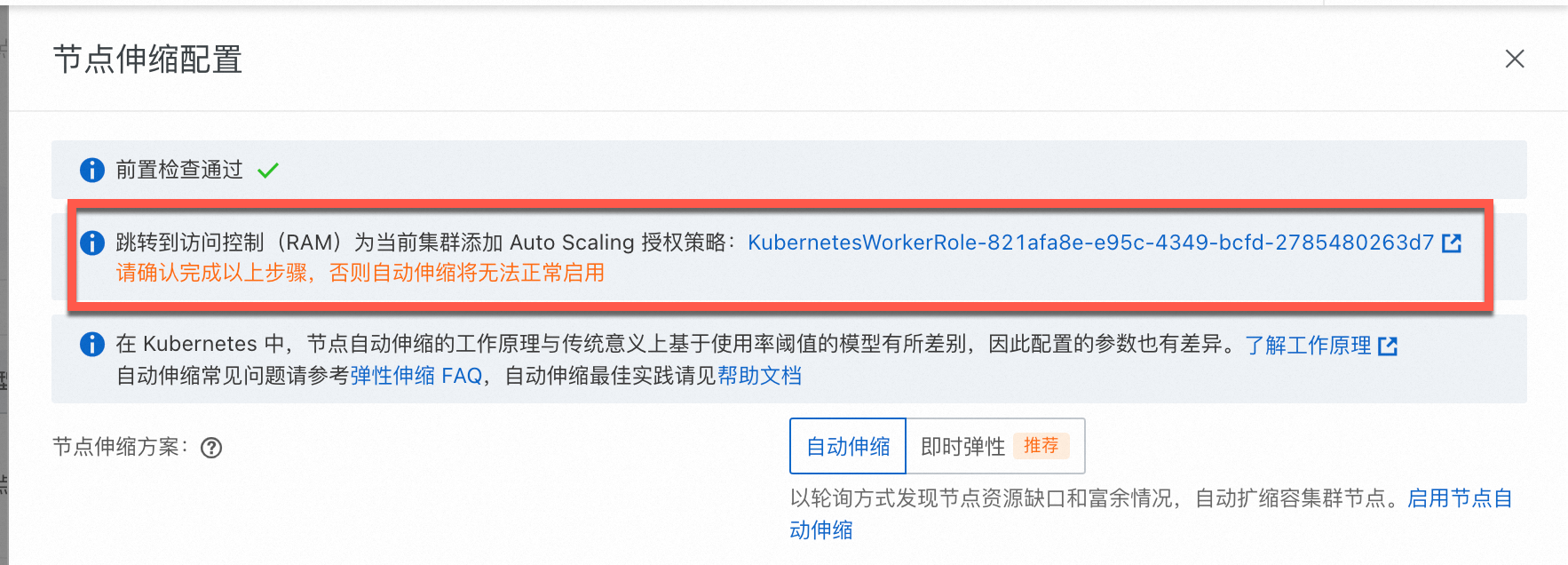
手动重启kube-system命名空间下的Deployment cluster-autoscaler(节点自动伸缩)或ack-goatscaler(节点即时弹性),以便权限立即生效。