ChatBI是指通過NL2SQL支援人員企業通過自然語言查詢資料產生報表。為了讓您更好地瞭解ChatBI的功能和操作方法,我們將以“阿里香”餐飲管理系統為例,全面串聯ChatBI的各個功能要點,協助您快速上手並高效使用。
開通PolarDB for AI能力
增加AI節點,並設定AI節點的串連資料庫帳號:開啟PolarDB for AI功能。
說明若您在購買叢集時已添加AI節點,則可以直接為AI節點設定串連資料庫的帳號。詳細說明,請參見建立普通帳號。
該帳號應具備讀寫權限,以便讀取和寫入目標資料表,從而順利執行ChatBI轉換過程中涉及的各類資料庫操作。
使用集群地址串連PolarDB叢集:登入PolarDB for AI。
說明使用命令列串連叢集時,需增加
-c選項。DMS預設使用主地址串連叢集,因此您需要手動修改為集群地址。修改後,請關閉原SQL視窗,並重新開啟一個新的SQL視窗執行SQL。
資料準備
“阿里香”是虛構的一家餐飲公司,其賬單管理系統中包含三張表,如下所示。您可點擊下載。
請根據您的表結構詳細資料填寫表和列的注釋,以便大語言模型能夠更好地識別和理解資料。這將有助於提升模型在資料處理和分析過程中的準確性和效率。
CREATE TABLE restaurant_info (
id INT COMMENT '門店ID',
position VARCHAR(128) COMMENT '門店地點',
PRIMARY KEY (id)
) COMMENT='門店表';
CREATE TABLE menu_info (
id INT COMMENT '菜品ID',
name VARCHAR(64) COMMENT '菜品名稱',
type INT COMMENT '菜品類型',
unit_price INT COMMENT '菜品單價',
PRIMARY KEY (id)
) COMMENT='菜品表';
CREATE TABLE bill_info (
id INT COMMENT '賬單ID',
items VARCHAR(512) COMMENT '下單菜品',
actural_amount INT COMMENT '實際付費',
restaurant_id INT COMMENT '就餐門店',
waiter VARCHAR(16) COMMENT '服務員',
diner_count INT COMMENT '就餐人數',
pay_time DATE COMMENT '下單時間',
PRIMARY KEY (id)
) COMMENT='賬單表';使用ChatBI
接下來,您可以使用PolarDB for AI的NL2SQL模型來產生與使用者問題相對應的SQL語句。
建立表結構索引
通過以下SQL語句,您可以建立一個名為schema_index的表結構索引表,以便向大模型提供表結構資訊。
/*polar4ai*/CREATE TABLE schema_index(id integer, table_name varchar, table_comment text_ik_max_word, table_ddl text_ik_max_word, column_names text_ik_max_word, column_comments text_ik_max_word, sample_values text_ik_max_word, vecs vector_768,ext text_ik_max_word, PRIMARY key (id));這張表不會直接顯示在資料庫中。如果您需要查看相關資訊,請使用以下SQL語句進行查詢。
/*polar4ai*/SHOW TABLES;接下來,您可以使用以下SQL語句將資料表結構匯入到索引表schema_index中。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;執行時,PolarDB for AI會預設對當前庫下的所有表進行向量化操作,並對列值進行採樣。
執行該語句後,您將獲得背景工作的task_id,例如:bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以使用以下SQL查詢當前任務的狀態。當返回的taskStatus為finish時,表示索引構建已完成。
/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;使用NL2SQL模型回答問題
您可以執行以下SQL語句線上使用基於LLM的NL2SQL。在以下樣本中,使用者提出的問題是這一周的總收入有多少,使用的表結構索引schema_index。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select '這一周的總收入有多少') WITH (basic_index_name='schema_index');資料庫在處理請求時需要等待一段時間以擷取大模型的回複,預期的返回結果如下:
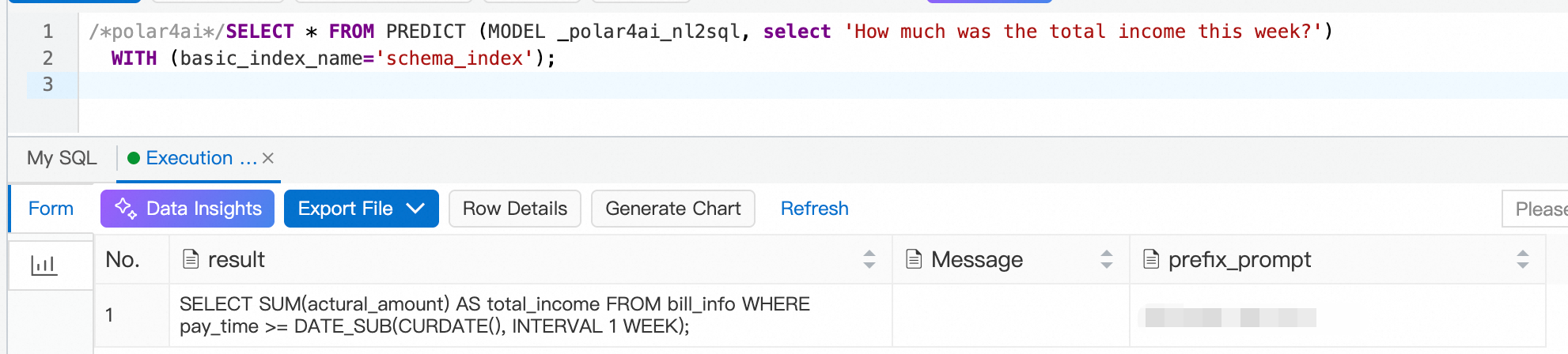
根據上述樣本,我們還可以提出一些典型的問題。這些問題涵蓋了多種情況,包括GROUP BY、多表JOIN、ORDER BY以及公式等。
問題序號 | 使用者問題 | NL2SQL傳回值 |
1 | 每個門店收入情況排序 |
|
2 | 在上海哪家門店收入最高 |
|
3 | 上海平均每個人消費多少 |
|
4 | 這個月菜品下單量前十有哪些 |
|
5 | 這個月比上個月收入的環比增長百分比多少 |
|
6 | 上海的哪家門店人流量最高 |
|
可以看到,基於LLM的NL2SQL模型能夠較好地回答使用者的問題,但有些問題的回複並未達到預期效果。例如,在第二個問題中,使用者希望返回門店名稱。如果重新表述為在上海哪家門店收入最高,請返回店名,模型將返回以下SQL語句:SELECT r.name FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position = '上海' ORDER BY b.actural_amount DESC LIMIT 1;。當然,我們也可以通過對模型進行精細調優來提高其準確率,這些問題將在下文中逐一解決。
精調模型
配置問題範本
您可以使用一些通用的問題範本,通過引入特定知識來指導模型,從而使其能夠根據特定的知識產生SQL語句。
執行以下SQL,建立問題範本表
polar4ai_nl2sql_pattern。CREATE TABLE `polar4ai_nl2sql_pattern` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `pattern_question` text COMMENT '模板問題', `pattern_description` text COMMENT '模板描述', `pattern_sql` text COMMENT '模板SQL', `pattern_params` text COMMENT '模板參數', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;其中,表名必須以
polar4ai_nl2sql_pattern開頭,表結構中必須包含上述建表語句中的五個列。接下來,建立問題範本的索引表
pattern_index。/*polar4ai*/CREATE TABLE pattern_index(id integer, pattern_question text_ik_max_word, pattern_description text_ik_max_word, pattern_sql text_ik_max_word, pattern_params text_ik_max_word, pattern_tables text_ik_max_word, vecs vector_768, PRIMARY key (id));我們為第二個問題配置模板,以進行精調,目的是返回店面的地址。
請執行以下SQL語句以添加一個新的模式(pattern):
INSERT INTO polar4ai_nl2sql_pattern (id, pattern_question, pattern_description, pattern_sql, pattern_params) VALUES ( 1, "在#{position}哪家門店收入最高", "在【地點】哪家門店收入最高", "SELECT r.position FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position LIKE '%#{position}%' GROUP BY r.position ORDER BY SUM(b.actural_amount) DESC LIMIT 1;", '[{"table_name":"bill_info","param_info":[{"param_name":"#{position}","value":["上海"]}], "explanation": "消費地點"}]' );在模式(pattern)中採用了槽位,以便匹配多個地點。在
pattern_sql列中填寫正確的SQL語句,並在槽位置用#{}進行標記。pattern_params列用於表資訊的額外後置處理補充,但在此可以忽略。接下來,將問題範本的資訊匯入索引表。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern') INTO pattern_index;與
schema_index構建索引表的過程類似,這裡也會返回一個任務ID。您可以通過執行/*polar4ai*/show task 'xxx-xxx-xxx'來查看當前任務的狀態。說明如果
polar4ai_nl2sql_pattern表中的資料發生更新,則需要重新建立pattern_index並進行匯入操作。可以使用以下 SQL 陳述式刪除舊錶:/*polar4ai*/DROP TABLE pattern_index;讓我們重新執行產生問題的SQL,並附上
pattern_index提示。/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select '在上海哪家門店收入最高') WITH (basic_index_name='schema_index',pattern_index_name='pattern_index');
構建配置表
若您希望對問題進行前置處理,或者對最終產生的SQL進行後置處理時,可以使用配置表進行配置。
詞彙含義提示
在第六個問題中,由於“大模型”無法準確理解“人流量”這一詞彙的含義,因此可以通過配置polar4ai_nl2sql_llm_config表進行預先處理。
CREATE TABLE `polar4ai_nl2sql_llm_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`is_functional` int(11) NOT NULL DEFAULT '1' COMMENT '是否生效',
`text_condition` text COMMENT '文本條件',
`query_function` text COMMENT '查詢處理',
`formula_function` text COMMENT '公式資訊',
`sql_condition` text COMMENT 'SQL條件',
`sql_function` text COMMENT 'SQL處理',
PRIMARY KEY (`id`)
);插入相關的配置項,告知大模型將“人流量”或“客流量”統計為“就餐人數”。
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
1,
1,
"人流量||客流量",
"",
"人流量或客流量使用就餐人數總和進行統計",
"",
""
);其中,is_functional為1表示該配置項有效。欄位text_condition的值為“人流量||客流量”,用於在問題中匹配含有“人流量”或者“客流量”的情況。formula_function中的內容則是通過文字(或公式)向大模型解釋專業詞彙的含義。
在此情況下,無需構建索引表和進行向量化處理,可以直接執行SQL產生,結果如下。

模糊比對提示
在第3個問題中,地名匹配使用=操作符進行檢索將導致失敗。因此,我們需要提示在進行地名匹配時應使用模糊搜尋,可以添加以下配置項。
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
2,
1,
"",
"",
"門店地點position的匹配需要使用模糊搜尋",
"",
""
);其中,text_condition為空白,表示該配置項將全域生效(請謹慎使用)。
結果如下圖所示。可以看到,地點的匹配成功地使用了模糊搜尋。

同理,在第5個問題中,“環比”和“同比”的計算公式也可以錄入到polar4ai_nl2sql_llm_config配置表中,以提高產生SQL的精確度。您可以自行進行挑戰嘗試。
圖表輸出
在使用NL2SQL產生SQL語句後,通常希望獲得該SQL查詢的結果,並同時展示一些更直觀的視覺效果,如柱狀圖、折線圖和餅圖等。PolarDB的NL2Chart方案可以根據您的問題和SQL語句執行並最終返回相應的報表(支援柱狀圖、餅狀圖、折線圖)。
假設您在NL2SQL中的語句如下:
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select '商戶類型統計') WITH (basic_index_name='schema_index',pattern_index_name='pattern_index');並產生了相應SQL語句(請檢查SQL語句運行結果有意義且不是空值):
SELECT merchtype AS 商戶類型,COUNT(*) AS 商品數量 FROM hkrt_merchant_info GROUP BY merchtype;使用NL2Chart:
文法說明
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, <SQL語句>) WITH (usr_query = <usr_query>, result_type = <result_type>);參數說明
參數名稱
參數說明
樣本值
usr_query
使用者輸入的問題描述,用於明確統計圖表的產生需求。
"2023年各季度銷售額統計"
result_type
指定返回結果的類型,當前僅支援
'IMAGE'。'IMAGE'SQL語句
由 NL2SQL 模組產生的 SQL 查詢語句,用於擷取資料。
SELECT quarter, sales FROM sales_data WHERE year = 2023樣本:將輸出的SQL語句的查詢結果轉化為圖表
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, SELECT merchtype AS 商戶類型, COUNT(*) AS 商戶數量 FROM hkrt_merchant_info GROUP BY merchtype) WITH (usr_query = '商戶類型統計', result_type='IMAGE');返回結果如下:
說明返回的連結為圖片地址,有效時間為90分鐘,過時將失效。
http://db4ai-xxx-xx-xxxx-xxx-xxxx.aliyuncs.com/pc-bpze47ma2c515087l6/OSSAccessKeyId=xxxxxxx&Expires=1716130199&Signature=KvPFzfMebIEmqxPIXURurwwbsXM%3D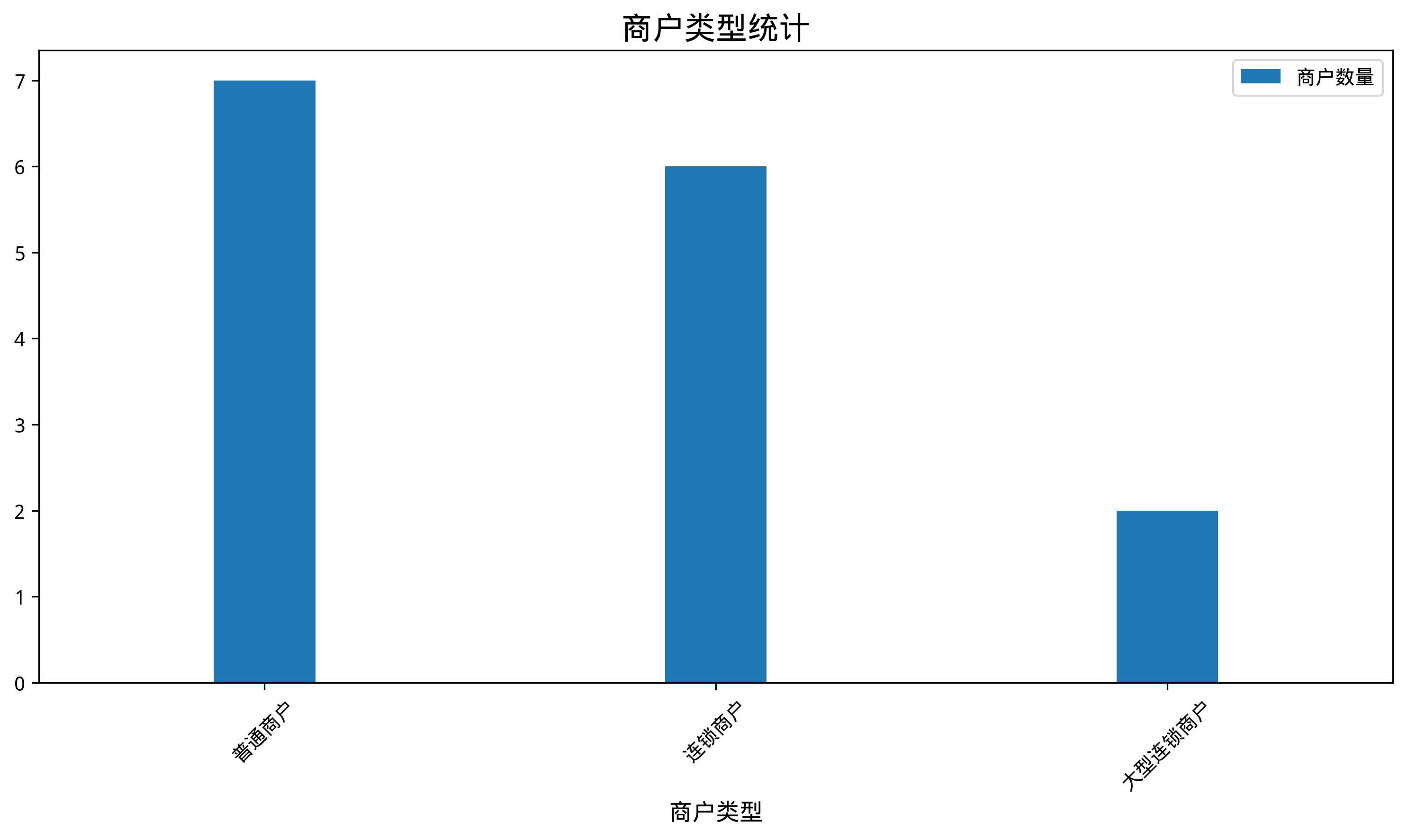
(可選)圖表類型選擇與強制選擇
模型會基於對使用者問題和資料的理解選擇合適的圖表,推薦選擇使用者問題引導模型畫圖。
以下是問題類型與圖表類型對應參考表:
問題類型
圖表類型
使用者問題樣本
說明
數量統計
柱狀圖
"請統計各城市銷售額"
展示不同類別之間的數值對比,如數量、總量、頻次等。
趨勢變化
折線圖
"請展示過去一年的使用者增長趨勢"
展示資料隨時間或有序類別變化的趨勢,強調連續性。
佔比分布
餅狀圖
"請展示各產品線的銷售佔比"
適用於展示整體中各部分的比例關係,需資料為分類且總和明確。
通過修改
usr_query參數強制指定圖表類型,在usr_query參數末尾加上補充命令即可:-- 將輸出的sql輸入 nl2chart 畫折線圖 /*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, SELECT merchtype AS 商戶類型, COUNT(*) AS 商戶數量 FROM hkrt_merchant_info GROUP BY merchtype ) WITH (usr_query = '商戶類型統計,畫折線圖', result_type='IMAGE');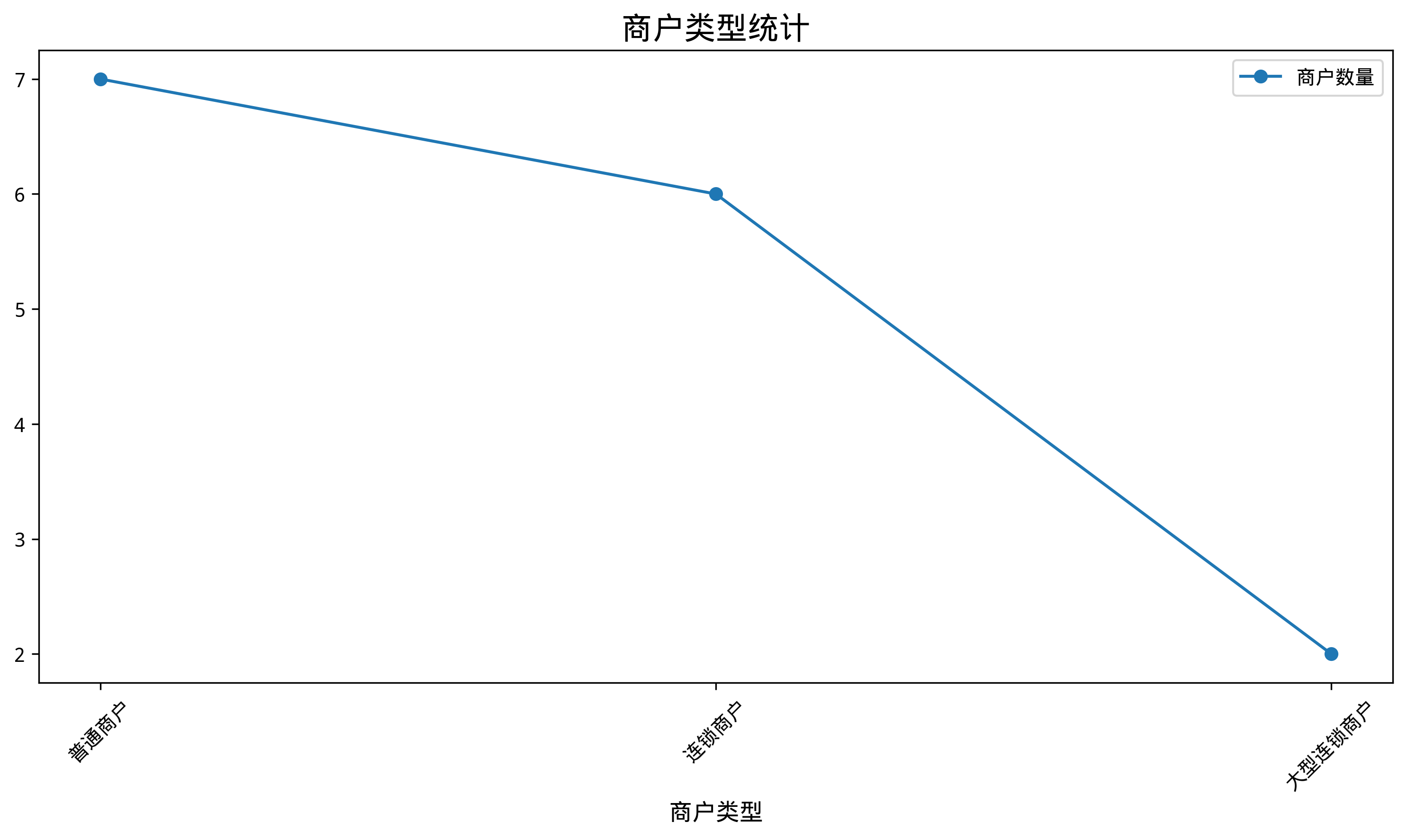
-- 將輸出的sql輸入 nl2chart 畫餅狀圖 /*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, SELECT merchtype AS 商戶類型, COUNT(*) AS 商戶數量 FROM hkrt_merchant_info GROUP BY merchtype ) WITH (usr_query = '商戶類型統計,畫餅狀圖', result_type='IMAGE');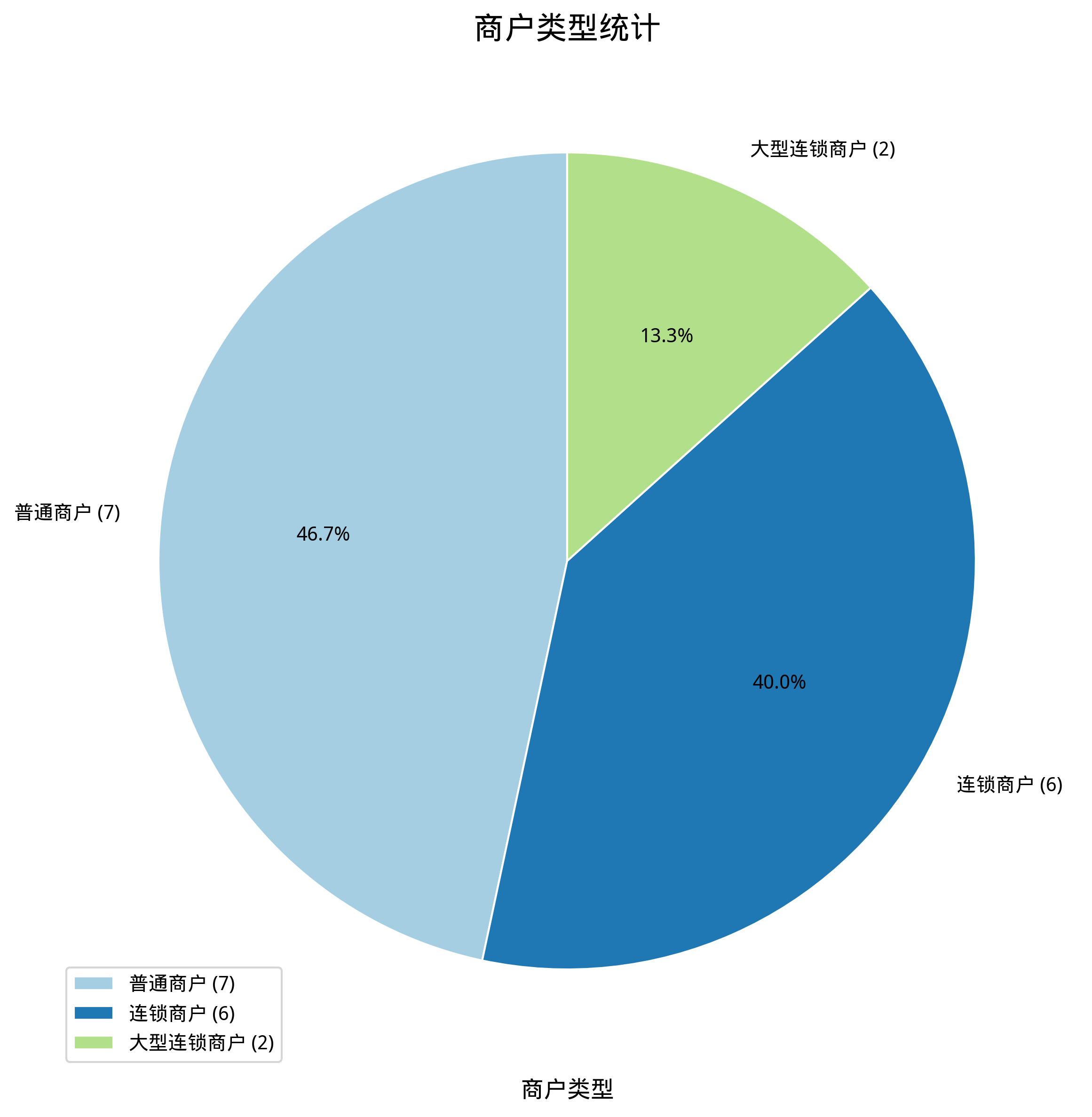
更多詳細資料請參考自然語言產生智能圖表NL2Chart。
重新微調訓練模型
若模型無法滿足您的業務需求,您可以重新訓練模型,並對模型內部參數進行微調,以達到更佳的效果。
限制條件
僅支援AI節點規格為16核125 GB+一張GU100(polar.mysql.x8.2xlarge.gpu)的叢集使用該功能。
當前一次只能訓練一個模型。
目前只能部署一個模型。
使用說明
訓練模型
/*polar4ai*/CREATE MODEL udf_qwen14b WITH (model_class='qwen-turbo', model_parameter=(basic_index_name='schema_index', pattern_index_name='pattern_index',training_type='efficient_sft')) as (SELECT '')參數說明
參數名 | 說明 | 預設值 | 可選值/範圍 |
model_class | 模型類型,當前支援{'qwen-14b-chat', 'qwen-turbo'}。 | 無 | {'qwen-14b-chat', 'qwen-turbo'} |
model_parameter | 模型參數配置,包括必需和選擇性參數。 | 無 | 無 |
basic_index_name | 訓練資料中的資料庫資訊采自的索引表名稱,此處需為資料庫索引表。 | 無 | 無 |
pattern_index_name | 訓練資料中的問題範本資訊采自的索引表名稱,此處需為問題範本索引表。 | 無 | 無 |
training_type | 訓練類型,允許值{'efficient_sft', 'sft'}。'efficient_sft'表示高效訓練,一般為LoRa方式;'sft'表示全參數訓練。 | 無 | {'efficient_sft', 'sft'} |
n_epochs | 迴圈次數,模型訓練過程中學習資料集的次數。建議範圍為1-3遍,可依據需求進行調整。 | 3 | [1, 200] |
learning_rate | 學習率,表示每次更新資料的增量參數權重。學習率越大,則參數變化越大,對模型影響越大。 | '3e-4' | 無 |
batch_size | 批次大小,代表模型更新參數的資料步長。建議的批次大小為16或32。 | 16 | {8, 16, 32} |
lr_scheduler_type | 學習率策略,動態改變訓練過程中更新權重時採用的學習率大小。 | 'linear' | {'linear', 'cosine', 'cosine_with_restarts', 'polynomial', 'constant', 'constant_with_warmup', 'inverse_sqrt', 'reduce_lr_on_plateau'} |
eval_steps | 模型驗證的間隔步長,用於階段性評估訓練準確率及損失。 | 50 | [1, 2147483647] |
sequence_length | 訓練資料的序列長度,單個樣本的最大長度,超出長度將自動截斷。 | 2048 | [500, 2048] |
lr_warmup_ratio | warmup佔總訓練步數的比例。 | 0.05 | (0, 1) |
weight_decay | L2正則化,協助減少過擬合問題。 | 0.01 | (0, 0.2) |
gradient_checkpointing | 開啟或關閉gradient checkpointing,用於節省顯存。 | 'True' | {'True', 'False'} |
use_flash_attn | 是否使用Flash Attention。 | 'True' | {'True', 'False'} |
lora_rank | LoRa訓練中的秩大小,影響訓練中資料對模型的作用程度。 | 8 | {2, 4, 8, 16, 32, 64} |
lora_alpha | LoRa訓練中的縮放係數,用於調整初始化訓練權重。 | 32 | {8, 16, 32, 64} |
lora_dropout | 訓練過程中隨機丟棄神經元的比率,防止過擬合,提高模型泛化能力。 | 0.1 | (0, 0.2) |
lora_target_modules | 選擇模型的特定模組進行微調最佳化。 | 'ALL' | {'ALL', 'AUTO'} |
查看模型
/*polar4ai*/SHOW model udf_qwen14b刪除模型
/*polar4ai*/DROP model udf_qwen14b查看所有模型
/*polar4ai*/SHOW models模型部署
訓練完成的模型只有在經過部署後,才能在NL2SQL中使用。
/*polar4ai*/deploy model udf_qwen14b查看部署
/*polar4ai*/SHOW deployment udf_qwen14b刪除部署
/*polar4ai*/DROP deployment udf_qwen14b查看所有部署
/*polar4ai*/SHOW deployments使用部署的模型進行自然語言轉SQL
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT 'id為1的內容是什嗎?') WITH (basic_index_name='schema_index', llm_model='udf_qwen14b')參數說明
參數 | 描述 |
basic_index_name | 不可為空白,需填寫當前問題關聯的資料庫資訊索引表。 |
llm_model | 可為空白。如果不填寫,將調用未經微調的模型進行自然語言轉SQL;如果填寫,請確保填寫已部署且狀態為“serving”的部署名稱。未完成部署的模型無法在此使用。 |