為了使不熟悉SQL語言的使用者能夠方便地從資料庫中進行資料分析,PolarDB for AI推出了自研的基於大語言模型的自然語言到SQL語言轉義(Large Language Model based Natural Language to SQL,簡稱LLM-based NL2SQL)AI模型,作為內建模型供您使用。與傳統的NL2SQL方法相比,LLM-based NL2SQL模型在語言理解能力上更為強大,所產生的SQL語句能夠支援更多的函數,例如日期加減等。該模型甚至能夠理解一些簡單的映射關係,例如有效->isValid=1等。此外,經過適當調整後,還能夠理解您的一些常用SQL搭配,例如在條件中預設選擇datastatus=1等。
效果展示
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '篩選出2個請假次數最多的學生,按照學生的請假次數降序排列,顯示學生的名字和請假次數。') WITH (basic_index_name='schema_index');輸出:SELECT s.student_name, COUNT(sc.id) AS leave_count FROM students s JOIN student_courses sc ON s.id = sc.student_id WHERE sc.status = 0 GROUP BY s.student_name ORDER BY leave_count DESC LIMIT 2;
自然語言到SQL語言轉義全流程
為了協助您能高效實現NL2SQL的落地應用,我們將實施流程分為3個階段:快速啟動階段、最佳化調優階段、生產部署階段。
快速啟動階段:本階段旨在協助使用者從零基礎快速搭建NL2SQL基礎能力。
最佳化調優階段:針對實際業務情境中的具體問題,我們將提供深度最佳化。
生產部署階段:確保NL2SQL系統順利投入生產環境。
前提條件
增加AI節點,並設定AI節點的串連資料庫帳號:開啟PolarDB for AI功能
說明若您在購買叢集時已添加AI節點,則可以直接為AI節點設定串連資料庫的帳號。
AI節點的串連資料庫帳號需具有讀寫許可權,以確保能夠順利讀取和寫入目標資料庫。
使用叢集地址串連PolarDB叢集:登入PolarDB for AI
重要使用命令列串連叢集時,需增加
-c選項。在使用DMS體驗和使用PolarDB for AI功能時,DMS預設使用PolarDB叢集的主地址進行串連,無法將SQL語句路由至AI節點。因此,您需要手動將串連地址修改為叢集地址。
注意事項
提問方式:在提出的問題中,應明確表達出限制條件及相關的實體值。同時,應盡量將條件前置,然後列出需尋找的列值對應的實體,最後提供可能的列名。樣本如下:
SELECT '超過1個房間的“房子”或“公寓”的屬性名稱是什嗎?'其中,超過1個房間是條件,房子和公寓是列值對應的實體,屬性名稱是可能的列名。
查詢結果準確率:LLM-based NL2SQL是一個基於大語言模型的AI模型,其效果與諸多因素有關。為了使查詢結果不脫離預期,總結了下列可能會影響整體準確率的幾個因素:
表和列注釋的豐富程度:每張表及表中的列都添加註釋,會提高查詢的準確率。
使用者問題與表中列注釋的匹配程度:使用者問題中的關鍵詞和列注釋保持一致,語義上越接近,查詢效果越好。
產生的SQL語句長度:SQL語句中涉及的列越少、條件越簡單,查詢會越準確。
SQL語句中的邏輯複雜程度:SQL語句中涉及的進階文法越少,查詢越準確。
使用說明
規範資料表
NL2SQL的前提是需要模型能夠理解表的含義,包括列名代表的意思。因此,在使用LLM-based NL2SQL前,需要為常用的資料表以及表中的列添加註釋。
表注釋
表注釋能夠協助LLM-based NL2SQL模型更好地理解表的基礎資訊,從而能更好地定位SQL語句中涉及的表。注釋應簡潔明了地概述表的主要內容。如訂單、庫存等,且盡量控制在10個字以內,避免引入過多的解釋。
列注釋
列注釋通常由常用的名詞或短語構成,例如訂單編號、日期、店鋪名稱等,這些內容能夠精確體現列名所表達的含義。同時,您可以在列注釋中添加列的範例資料或映射關係。例如,對於列名為
isValid,注釋可以為是否有效。0:否。1:是。。
若原有注釋無法修改,您可以使用進階功能中的自訂表格列注釋能力調整相關注釋。具體資訊,請參見進階使用-自訂表格列注釋。
資料準備
您可以根據實際業務情境準備相應的測試資料。本文採用的測試資料集為:測試資料集.sql。
構建檢索索引表
為了提取資料表中的資料,需要構建資料表的檢索索引表,支援自訂表格名(需符合資料庫規範)。本文以
schema_index為例,構建檢索索引表的SQL語句如下:/*polar4ai*/CREATE TABLE schema_index(id integer, table_name varchar, table_comment text_ik_max_word, table_ddl text_ik_max_word, column_names text_ik_max_word, column_comments text_ik_max_word, sample_values text_ik_max_word, vecs vector_768, ext text_ik_max_word, PRIMARY KEY (id));說明檢索索引表不會直接展示於資料庫中。如需查看相關資訊,請使用SQL語句
/*polar4ai*/SHOW TABLES;進行查詢。如果需要刪除檢索索引表,以
schema_index為例,可以執行此SQL語句/*polar4ai*/DROP TABLE IF EXISTS schema_index;。
將資料表中的資訊匯入檢索索引表
在執行以下SQL語句後,PolarDB for AI預設會對當前資料庫下的所有表執行轉向量操作,並對列值進行取樣。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;參數說明
_polar4ai_text2vec為文本轉向量化模型。INTO後需要填寫之前建立的檢索索引表名,該名稱為步驟1:構建檢索索引表的表名。WITH()內支援配置多個參數,以便對相關行為進行設定:參數
必填
說明
mode
是
資料寫入模式。固定為async,表示為非同步模式。
resource
是
資源類型。固定為schema,表示對資料表資訊進行向量化。
tables_included
否
設定轉向量的表。
預設為
'',表示對所有的表執行轉向量操作。設定時,多個表名之間需要使用英文逗號分隔,並拼接為字串。to_sample
否
設定是否對列值進行取樣。對列值進行取樣會使得匯入檢索索引表的任務時間變長,但在表的列數較少(小於15列)時能提高產生的SQL的品質。取值範圍如下:
0(預設):不對列值取樣
1:對列值取樣
columns_excluded
否
設定不參與LLM-based NL2SQL操作的列。
預設為
'',表示所有參與轉向量的表中的所有列均參與後續LLM-based NL2SQL操作。設定時,需要將所選表中不參與後續LLM-based NL2SQL操作的列按照table_name1.column_name1,table_name1.column_name2,table_name2.column_name1的格式拼接為字串。樣本:以下SQL語句表示對當前資料庫中的
graph_info表、image_info表以及text_info表執行轉向量操作,並對列值進行取樣。同時,graph_info表中的time列和text_info表中的ext列不參與後續的LLM-based NL2SQL操作。/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema', tables_included='graph_info,image_info,text_info', to_sample=1, columns_excluded='graph_info.time,text_info.ext') INTO schema_index;
查看任務狀態
執行完上述匯入檢索索引表的語句後,將返回該任務的
task_id,例如bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以通過以下命令查看匯入狀態,當傳回值顯示為finish時,表示任務已完成。/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;您可以執行以下SQL語句來查看檢索索引資訊:
/*polar4ai*/SELECT * FROM schema_index;
線上使用LLM-based NL2SQL
文法說明
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '<question>') WITH (basic_index_name='<basic_index_name>');參數說明
<question>後是需要輸入待轉換為SQL語句的問題。以下為您展示一些推薦的問句範例:本樣本情境
其他情境
按照老師名字的字母升序排列,顯示老師的名字和安排他們教的課程名稱。
篩選出10個請假次數最多的學生,按照學生的請假次數降序排列,顯示學生的名字和請假次數。
查詢2023年10月1日至2023年10月3日期間開課的課程名稱和上課地點。
統計每個學生選修的課程數量超過2門的學生姓名和課程數量,按課程數量降序排列。
篩選出學生住址包含“北京市”或“上海市”的學生姓名和電話號碼。
進行過兩次或更多次治療的專家的ID、角色和名字是什嗎?
被養最多數量狗的品種名稱是什嗎?
哪一位主人為他或她的狗支付了最多的治療費?列出主人的ID和姓氏。
告訴我花在他或她的狗身上最多治療費的主人的ID和姓氏。
總花費最少的治療類型的描述是什嗎?
WITH()內支援配置多個參數,以便對相關行為進行設定:參數名稱
必填
說明
basic_index_name
是
當前資料庫內檢索索引表名。
to_optimize
否
是否進行SQL最佳化。取值範圍:
0(預設):不最佳化。
1:執行SQL最佳化操作,PolarDB for AI將會對產生的SQL語句進一步加工成更最佳化的SQL。
basic_index_top
否
召回表的最相近個數。取值範圍:[1,10]。
預設值為3,表示對當前問題只選出最優的3張表。通常設定為1即可。
如果涉及到多張表,可以將該值設定為4或更大,以擴大召回,提高效果。
basic_index_threshold
否
召回表判斷是否相近時所使用的閾值。取值範圍:(0,1]。
預設值為0.1,表示當資料庫表向量匹配超過0.1時才會被選中。
樣本
顯示特定內容,並按照指定順序進行排序。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '按照老師名字的字母升序排列,顯示老師的名字和安排他們教的課程名稱。') WITH (basic_index_name='schema_index');SELECT t.teacher_name, c.course_name FROM teachers t JOIN courses c ON t.id = c.teacher_id ORDER BY t.teacher_name ASC;根據指定條件進行搜尋,展示合格內容,並按照指定順序進行排序。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '篩選出2個請假次數最多的學生,按照學生的請假次數降序排列,顯示學生的名字和請假次數。') WITH (basic_index_name='schema_index');SELECT s.student_name, COUNT(sc.id) AS leave_count FROM students s JOIN student_courses sc ON s.id = sc.student_id WHERE sc.status = 0 GROUP BY s.student_name ORDER BY leave_count DESC LIMIT 2;
進階使用
PolarDB for AI為您提供四種進階使用方法。若您遇到以下問題時,可參考相應的進階使用說明以解決相關問題。
配置問題範本:通過配置通用的問題範本,使模型能夠基於特定知識產生SQL語句。
構建配置表:對問題進行前置處理或對產生SQL語句進行後置處理。
自訂表格列注釋:如果原表或列的注釋無法進行修改,可以為該表及相關列添加新的注釋,以覆蓋原表中的注釋內容。
寬表支援:當表中列數過多或出現
Please use column index to avoid oversize table information.錯誤時,可以通過構建列索引表來使模型支援寬表。
配置問題範本
問題範本是為特定領域知識而制定的,能夠協助模型更好地理解當前問題。您可以配置一些通用的問題範本,通過引入特定知識來指導模型,使得模型能按特定的知識來產生SQL語句。
使用說明
建立問題範本表
問題範本表的名稱必須以
polar4ai_nl2sql_pattern開頭,且表結構必須包含下述建表語句中的五個列。DROP TABLE IF EXISTS `polar4ai_nl2sql_pattern`; CREATE TABLE `polar4ai_nl2sql_pattern` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `pattern_question` text COMMENT '模板問題', `pattern_description` text COMMENT '模板描述', `pattern_sql` text COMMENT '模板SQL', `pattern_params` text COMMENT '模板參數', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;問題範本列說明
列名
說明
模板問題
帶參數的問題,作為輸入提供給LLM-based NL2SQL模型。
在模板問題中,需要按照
#{XXX}格式來寫入參數。模板描述
對模板問題進行提煉,並將一些實體作為參數,例如日期、年份、機構等。這些實體通常對應於表中的特定列。
在模板描述中,需要按照
【XXX】格式來寫入參數,並且需要與模板問題中的參數順序保持一致。模板SQL
與模板問題相對應的正確SQL語句。該SQL語句中需將模板問題中的參數作為變數進行處理。
說明模板問題與模板SQL中的參數可不相同,但需具備關聯關係。例如,參數應具有相同的首碼,並且參數值之間存在一一映射關係。以
#{category}和#{categoryCode}為例,當category的參數值為普通商標、特殊商標和集體商標時,相應的categoryCode值分別為0、1和2。詳細說明,請參見下述樣本。模板參數
模板參數為一個JSON字串,其結構由
table_name、param_info和explanation三個參數組成,具體參數如下:table_name
string:模板SQL中的表名。param_info
array:模板SQL中的參數說明。param_name
string:參數名稱。value
array:參數的取值範例。說明如果參數對應的是有限的枚舉值,則盡量在value中將所有的值列出來。
如果只是範例值,可以列出2~4個值。
如果存在相互對應的參數,則需要通過數組索引來映射。以
#{category}和#{categoryCode}為例,category中的普通商標對應categoryCode中的1,特殊商標對應categoryCode中的2。詳細說明,請參見下述樣本。
explanation
string:補充說明。通常是對產生SQL語句的一些要求。比如,輸出哪些資訊或者對欄位的一些說明。
說明當不需要填寫模板參數時,您可以將模板參數值設定為以下任意一種形式:
NULL
Null 字元串
空的list字串[]
樣本
模板問題
模板描述
模板SQL
模板參數
查詢課程名稱為#{courseName}授課狀態為#{status}的課程
【課程名稱】【授課狀態】的課程有哪些?
SELECT course_name, course_time, course_location FROM courses WHERE course_name=#{courseName} AND status=#{statusCode}[{"table_name":"courses","param_info":[{"param_name":"#{courseName}","value":["數學","物理","化學","英語","歷史","地理","生物","電腦科學","藝術","音樂","體育","編程","文學","心理學","哲學","經濟學","社會學","物理學實驗","化學實驗","生物學實驗"]},{"param_name": "#{status}", "value": ["未開課","授課中"]},{"param_name": "#{statusCode}","value": [0,1]}], "explanation": "輸出課程名稱course_name、課程時間course_time、課程地點course_location。註:status為常量映射類型。變數映射欄位:statusCode。"}]
查詢年份為#{issueDate}年專案狀態為#{projectStat}狀態計劃發布的國家標準有哪些?
【年份】【專案狀態】計劃發布的國家標準有哪些?
SELECT DISTINCT planNum, projectCnName, projectStat FROM sy_cd_me_buss_std_gjbzjh WHERE `planNum` IS NOT NULL AND `dataStatus` != 3 AND `isValid` = 1 AND projectStat=#{projectStat} AND DATE_FORMAT(`issueDate`, '%Y')=#{issueDate}[{"table_name":"sy_cd_me_buss_std_gjbzjh","param_info":[{"param_name":"#{issueDate}","value":[2009,2010,2011,2012]},{"param_name":"#{projectStat}","value":["正在徵求意見","發行","正在審查"]}],"explanation":"輸出標準名稱projectCnName、計劃號、專案狀態"}]
查詢商標類型為#{category}國際分類為#{intCls}類型的商標有哪些?
【商標類型】【國際分類】的商標有哪些?
SELECT DISTINCT tmName, regNo, status FROM sy_cd_me_buss_ip_tdmk_new WHERE dataStatus!=3 AND isValid = 1 AND category=#{categoryCode} AND intCls=#{intClsCode}[{"table_name":"sy_cd_me_buss_ip_tdmk_new","param_info":[{"param_name":"#{intCls}","value":["化學原料","顏料油漆","日化用品","燃料油脂","醫藥"]},{"param_name":"#{category}","value":["普通商標","特殊商標","集體商標"]},{"param_name":"#{intClsCode}","value":[1,2,3,4,5]},{"param_name":"#{categoryCode}","value":[0,1,2]}],"explanation":"輸出商標名稱tmName、regNo申請號/註冊號、status商標狀態。註:category為常量映射類型。變數映射欄位:categoryCode。intCls為常量映射類型。變數映射欄位:intClsCode。"}]
以本文樣本情境為例,建立上述表格中第一條模板問題。執行SQL如下:
INSERT INTO `polar4ai_nl2sql_pattern` (`pattern_question`,`pattern_description`,`pattern_sql`,`pattern_params`) VALUES ('查詢課程名稱為#{courseName}授課狀態為#{status}的課程','【課程名稱】【授課狀態】的課程有哪些?','SELECT course_name, course_time, course_location FROM courses WHERE course_name=#{courseName} AND status=#{statusCode}','[{"table_name":"courses","param_info":[{"param_name":"#{courseName}","value":["數學","物理","化學","英語","歷史","地理","生物","電腦科學","藝術","音樂","體育","編程","文學","心理學","哲學","經濟學","社會學","物理學實驗","化學實驗","生物學實驗"]},{"param_name": "#{status}", "value": ["未開課","授課中"]},{"param_name": "#{statusCode}","value": [0,1]}], "explanation": "輸出課程名稱course_name、課程時間course_time、課程地點course_location。註:status為常量映射類型。變數映射欄位:statusCode。"}]');建立問題範本索引表
支援自訂索引表名(需符合資料庫規範)。本文以
pattern_index為例,建立問題範本索引表的SQL語句如下:/*polar4ai*/CREATE TABLE pattern_index(id integer, pattern_question text_ik_max_word, pattern_description text_ik_max_word, pattern_sql text_ik_max_word, pattern_params text_ik_max_word, pattern_tables text_ik_max_word, vecs vector_768, PRIMARY KEY (id));說明問題範本索引表不會直接展示於資料庫中。如需查看相關資訊,請使用SQL語句
/*polar4ai*/SHOW TABLES;進行查詢。如果需要刪除問題範本索引表,以
pattern_index為例,可以執行此SQL語句/*polar4ai*/DROP TABLE IF EXISTS pattern_index;。
將問題範本表中資訊匯入索引表
說明問題範本表中的資訊不得為空白。在執行匯入索引表的SQL語句之前,您需至少添加一條記錄。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern') INTO pattern_index;參數說明
_polar4ai_text2vec為文本轉向量化模型。INTO後需要填寫之前建立的問題範本索引表名,該名稱為步驟2:建立問題範本索引表的表名。WITH()內支援配置多個參數,以便對相關行為進行設定:參數
必填
說明
mode
是
資料寫入模式。固定為async,表示為非同步模式。
resource
是
資源類型。固定為pattern,表示對問題範本資訊進行向量化。
pattern_table_name
否
設定轉向量的問題範本表的表名,該名稱為步驟1:建立問題範本表中的表名。
預設為
polar4ai_nl2sql_pattern,表示對polar4ai_nl2sql_pattern表執行轉向量操作。設定時,需填寫以polar4ai_nl2sql_pattern開頭的問題範本表的表名。若您希望為不同情境或業務維護不同的問題範本索引表,可以在建立問題範本索引表時指定不同的表名。例如,為使用者相關情境建立
polar4ai_nl2sql_pattern_user表,隨後在第二步建立問題範本索引時,將索引名設定為pattern_index_user。在將資訊匯入索引表時,使用如下SQL語句:/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern', pattern_table_name='polar4ai_nl2sql_pattern_user') INTO pattern_index_user;
查看任務狀態
執行完上述匯入索引表的語句後,將返回該任務的
task_id,例如bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以通過以下命令查看匯入狀態,/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;當傳回值顯示為
finish時,表示任務已完成。問題範本資訊可被模型引用。您可以執行以下SQL語句來查看問題範本索引資訊:/*polar4ai*/SELECT * FROM pattern_index;說明如果
polar4ai_nl2sql_pattern表中的資料發生了變更,則需要重新執行步驟3:將問題範本資訊匯入索引表。線上使用問題範本
您可以執行以下SQL語句來線上使用LLM-based NL2SQL和問題範本:
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '查詢課程名稱為數學,授課狀態為授課中的課程') WITH (basic_index_name='schema_index', pattern_index_name='pattern_index');SELECT course_name, course_time, course_location FROM courses WHERE course_name='數學' AND status=1;參數說明
SELECT後需要輸入待轉換為SQL語句的問題。
basic_index_name為當前資料庫檢索索引表名稱。pattern_index_name為問題範本索引表名稱。WITH()內支援配置多個參數,以便對相關行為進行設定(其他參數說明請參見線上使用LLM-based NL2SQL):參數名稱
參數描述
取值範圍
pattern_index_top
召回問題範本的最相近個數。
取值範圍:[1,10]。
預設值為2,表示對當前問題範本只選出最優的2條模板。
pattern_index_threshold
召回問題範本是否相近時所使用的閾值。
取值範圍:(0,1]。
預設值為0.85,表示當問題範本向量匹配超過0.85時才會被選中。
構建配置表
若您希望對問題進行前置處理,或對最終產生的SQL進行後置處理,可以通過配置表進行相應配置。
適用情境
情境一:對問題中的確定性詞語進行替換,如人名、行業用語、商品名替換等。
例如:對於所有涉及
張三的問題,將張三替換為ZS001。在此情況下,對於問題張三上個月的銷售額是多少?和張三今年的總銷售額是多少?,在最終調用大模型之前,可以通過配置表將其全部預先處理為ZS001上個月的銷售額是多少?和ZS001今年的總銷售額是多少?。情境二:對包含特定詞語的問題補充額外資訊。
例如,對於所有涉及
總銷售額的問題,應補充總銷售額的計算公式:總銷售額 = SUM(銷售額)。在最終調用大型模型之前,可以通過配置表添加此類資訊,當問題滿足相應條件時進行補充。情境三:對特定表或列的值進行映射替換。
例如:對所有最終涉及
student_courses表的SQL,將其中的status = '請假'替換為status = 0,以作為一種列值對應的兜底措施。
文法說明
構建配置表的SQL語句如下,表名polar4ai_nl2sql_llm_config固定不可變。
DROP TABLE IF EXISTS `polar4ai_nl2sql_llm_config`;
CREATE TABLE `polar4ai_nl2sql_llm_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`is_functional` int(11) NOT NULL DEFAULT '1' COMMENT '是否生效',
`text_condition` text COMMENT '文本條件',
`query_function` text COMMENT '查詢處理',
`formula_function` text COMMENT '公式資訊',
`sql_condition` text COMMENT 'SQL條件',
`sql_function` text COMMENT 'SQL處理',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;當polar4ai_nl2sql_llm_config表中的資料發生變更時,您無需進行任何操作,變更的資料將立即生效。
參數說明
列名 | 說明 | 取值範圍 | 樣本 |
is_functional | 表示該行配置是否生效。 當配置表存在時,預設每次進行NL2SQL時均採用。若存在不希望採用又暫時不想刪除的配置項,可將is_functional置為0。使該配置行不生效。 |
|
|
text_condition | 前置處理:對問題進行文本條件判斷。 如果判斷為匹配,則使用query_function和formula_function兩列進行處理,反之則不使用。 |
| 若text_condition為 例如:
|
query_function | 前置處理:對問題進行處理。 當text_condition判斷為匹配時使用。 |
| 若query_function為 例如:
|
formula_function | 前置處理:在問題中補充與具體業務/概念相關的計算公式資訊或其他資訊。 當text_condition判斷為匹配時使用。 | - | 若formula_function為 |
sql_condition | 後置處理:對模型產生的SQL進行條件判斷。 如果判斷為匹配,則使用sql_function對SQL進行處理,反之則不使用。 |
| 若sql_condition= 例如:
|
sql_function | 後置處理:對SQL進行處理,可用於對商務邏輯中的值對應進行強制處理。 當sql_condition判斷為匹配時使用。 |
| 若sql_function= |
樣本
is_functional | text_condition | query_function | formula_function | sql_condition | sql_function |
1 |
|
| |||
1 |
| ||||
1 |
|
|
未添加配置表前,執行以下SQL語句:
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '篩選出2個請假次數最多的學生,按照學生的請假次數降序排列,顯示學生的名字和請假次數。') WITH (basic_index_name='schema_index');SELECT s.student_name, COUNT(sc.id) AS leave_count FROM students s JOIN student_courses sc ON s.id = sc.student_id WHERE sc.status = 0 GROUP BY s.student_name ORDER BY leave_count DESC LIMIT 2;按照文法說明構建配置表。
添加配置記錄。如果表
students或表student_courses在SQL中,且表courses不在SQL中時,將status = 0替換成status = 10。INSERT INTO `polar4ai_nl2sql_llm_config` (`is_functional`,`sql_condition`,`sql_function`) VALUES (1,'students||student_courses&&!!courses','{"replace":{"status = 0":"status = 10"}}');執行步驟1的SQL語句。可以看出產生的SQL語句已將
status的值進行了替換。/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '篩選出2個請假次數最多的學生,按照學生的請假次數降序排列,顯示學生的名字和請假次數。') WITH (basic_index_name='schema_index');SELECT s.student_name, COUNT(sc.id) AS leave_count FROM students s JOIN student_courses sc ON s.id = sc.student_id WHERE sc.status = 10 GROUP BY s.student_name ORDER BY leave_count DESC LIMIT 2;
自訂表格列注釋
若您在規範資料表的過程中發現原有資料表或列的注釋無法修改,您可在polar4ai_nl2sql_table_extra_info表中為該表及相關列添加新的注釋。在使用LLM-based NL2SQL時,該表中的注釋將覆蓋原表中的注釋內容。
文法說明
建立自訂表格列注釋表的SQL語句如下,表名polar4ai_nl2sql_table_extra_info固定不可變。
DROP TABLE IF EXISTS `polar4ai_nl2sql_table_extra_info`;
CREATE TABLE `polar4ai_nl2sql_table_extra_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`table_name` text COMMENT '表名稱',
`table_comment` text COMMENT '表說明',
`column_name` text COMMENT '列名稱',
`column_comment` text COMMENT '列說明',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;當polar4ai_nl2sql_table_extra_info表中的資料發生變更時,需重新執行步驟:將資料表中的資訊匯入檢索索引表,才可使polar4ai_nl2sql_table_extra_info表中變更的資料生效。
樣本
建立自訂表格列注釋表。
對
student_courses表中status列的注釋進行修改。此處,為status列新增了一個選項說明:2-缺勤。INSERT INTO `polar4ai_nl2sql_table_extra_info` (`table_name`,`table_comment`,`column_name`,`column_comment`) VALUES ('student_courses','課程學生資訊表','status','學生狀態 0-請假,1-正常,2-缺勤。');重新執行步驟:將資料表中的資訊匯入檢索索引表。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;查看任務狀態。
執行完上述匯入檢索索引表的語句後,將返回該任務的
task_id,例如bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以通過以下命令查看匯入狀態,當taskStatus顯示為finish時,表示任務已完成。/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;線上使用LLM-based NL2SQL。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '篩選出2個缺勤次數最多的學生,按照學生的缺勤次數降序排列,顯示學生的名字和缺勤次數。') WITH (basic_index_name='schema_index');SELECT s.student_name, COUNT(sc.id) AS absence_count FROM student_courses sc JOIN students s ON sc.student_id = s.id WHERE sc.status = 2 GROUP BY s.student_name ORDER BY absence_count DESC LIMIT 2;從上述輸出結果中可以看出,LLM-based NL2SQL模型已經將缺勤對應為
student_courses表中status列的列值2。
寬表支援
若資料表中存在列數較多的寬表,或在使用LLM-based NL2SQL過程中收到Please use column index to avoid oversize table information.的錯誤訊息時,可以使用以下流程以支援寬表。
線上使用LLM-based NL2SQL時,WITH()中的basic_index_name和pattern_index_name均可使用相同的column_index_name。與schema或pattern不同,這裡僅為資訊精簡。
對於絕大多數請求而言,column_index_name參數不會造成影響,僅在觸發長度限制的NL2SQL請求中,需要通過column_index_name對錶資訊進行精簡。這可能導致一定程度的準確度損失,但有效避免了因提示(Prompt)過長而引發LLM-based NL2SQL模型錯誤的問題。
構建列索引表。
支援自訂欄索引表名(需符合資料庫規範),但該表名不得與當前資料庫中已存在的表名相同。此外,一個資料庫中只需存在一張列索引表即可。建表語句如下:
/*polar4ai*/CREATE TABLE column_index(id integer, table_name varchar, table_comment text_ik_max_word, column_name text_ik_max_word, column_comment text_ik_max_word, is_primary integer, is_foreign integer, vecs vector_768, ext text_ik_max_word, PRIMARY KEY (id));說明列索引表不會直接展示於資料庫中。如需查看相關資訊,請使用SQL語句
/*polar4ai*/SHOW TABLES;進行查詢。如果需要刪除列索引表,以
column_index為例,可以執行此SQL語句/*polar4ai*/DROP TABLE IF EXISTS column_index;。
將資料表中的資訊以列為粒度匯入列索引表。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, select '') WITH (mode='async', resource='column') into column_index;查看任務狀態。
執行完上述匯入列索引表的語句後,將返回該任務的
task_id,例如bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以通過以下命令查看匯入狀態,當taskStatus顯示為finish時,表示任務已完成。/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;線上使用LLM-based NL2SQL寬表。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '按照老師名字的字母升序排列,顯示老師的名字和安排他們教的課程名稱。') WITH (basic_index_name='schema_index', column_index_name='column_index');
常見問題
使用DMS執行SQL時,報錯:文法有誤
若您在DMS體驗或使用PolarDB for AI功能時,執行AI SQL(即SQL語句前添加/*polar4ai*/的SQL)出現以下錯誤:You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'xxx' at line xxx,請檢查DMS的串連地址是否為PolarDB叢集的叢集地址。
PolarDB for AI功能需在AI節點上執行,而DMS預設使用PolarDB叢集的主地址進行串連。因此,您需要按照以下流程修改DMS的串連地址。
通過DMS串連叢集後,在左側導覽列的列表中,選擇目的地組群,單擊右鍵選擇編輯執行個體。
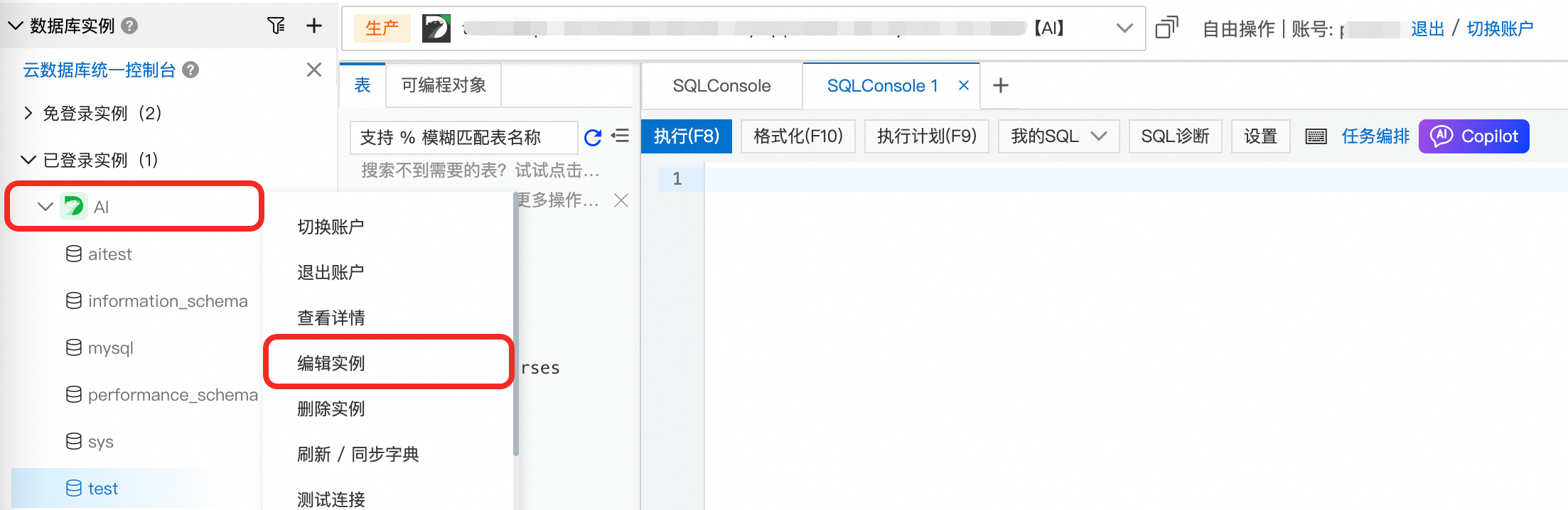
在編輯執行個體彈窗中,將修改為串連串地址,並填入叢集的叢集地址。單擊儲存。
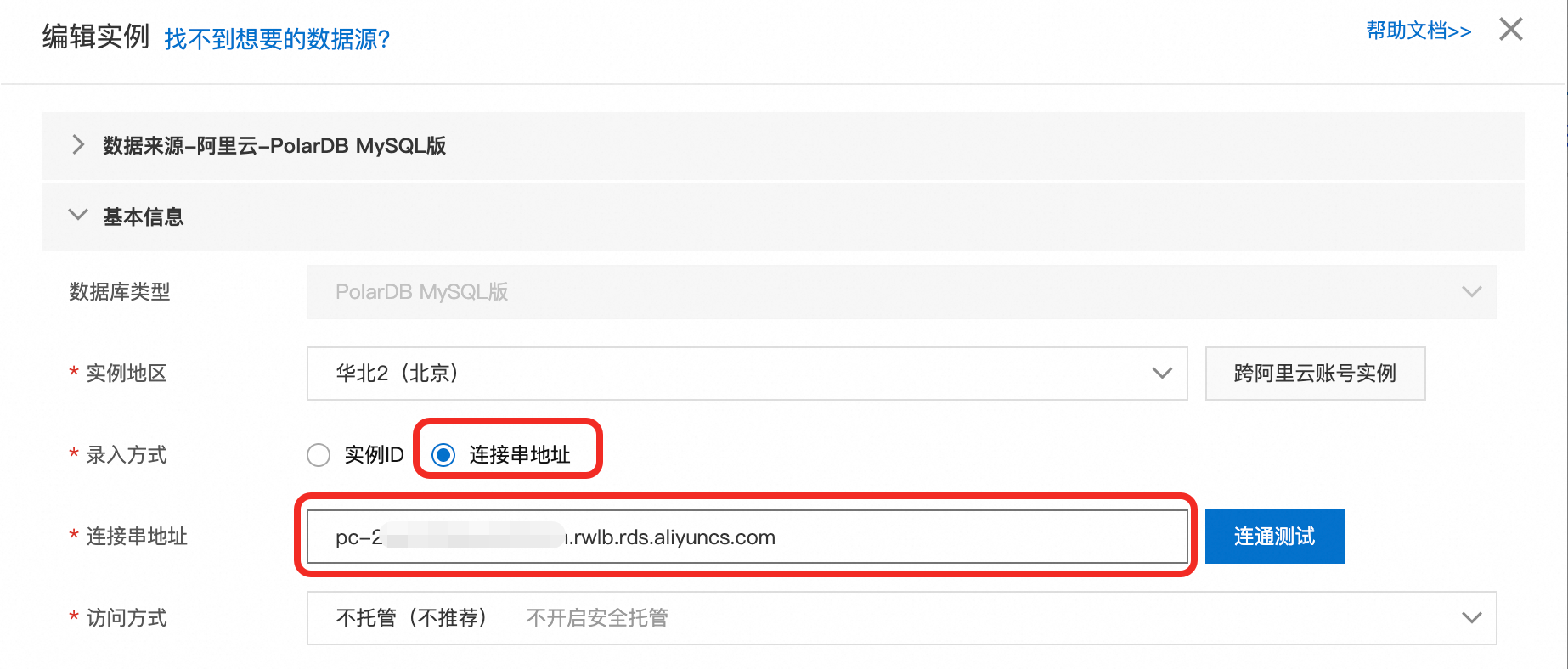
由於原SQL視窗使用的是主地址串連叢集,因此在修改串連串地址後,請關閉原SQL視窗,並重新開啟一個新的SQL視窗執行SQL。