本文詳細介紹了如何使用LangStudio構建“意圖識別客服”應用流。該應用流通過整合意圖識別和RAG能力,為模型提供了智能識別使用者意圖的能力,從而在處理使用者輸入的問題時,能夠快速分類和理解使用者需求,實現更高效的客戶服務。開發人員可以基於該模板進行靈活擴充和二次開發,以滿足特定情境的需求。
背景資訊
在現代客戶服務領域,"意圖識別客服" 應用流通過結合先進的自然語言處理技術和深度學習模型,為使用者提供更加智能和高效的客服體驗。通過整合意圖識別和RAG能力,該解決方案能夠準確理解使用者的需求和問題,從預定義的知識庫中擷取標準答案,並迅速提供相關的解決方案;開發人員也可以使用Python進行開發,根據實際需求調整應答策略,從而提升客服的準確性和使用者體驗。在電商、銀行、通訊等需要高效客戶服務的領域中表現尤為出色。開發人員可以基於該應用流的模板進行靈活的擴充和定製化開發,以更好地滿足不同應用情境的需求,從而最佳化客戶體驗和提升服務品質。
前提條件
LangStudio向量資料庫支援使用Faiss或Milvus向量資料庫,若您希望使用Milvus資料庫,您需要先完成Milvus資料庫的建立。
說明Faiss通常用於測試環境,無需額外建立資料庫即可使用。在生產環境中,建議您使用Milvus資料庫,支援處理更大規模的資料。
已將RAG知識庫語料上傳至OSS中。
1. (可選)部署LLM和Embedding模型
意圖識別應用流需要用到LLM和Embedding模型服務,本節將詳細介紹如何通過ModelGallery快速部署所需的模型服務。若您已有符合要求的模型服務,且服務支援OpenAI API,則可跳過此步驟,直接使用現有服務。
前往快速開始 > ModelGallery,分別部署以下兩種情境的模型。更多部署詳情,請參見模型部署及訓練。
情境選擇大語言模型,以DeepSeek-R1為例進行部署。更多部署詳情,請參見一鍵部署DeepSeek-V3、DeepSeek-R1模型。
說明為了方便示範,本文建立的應用流中,意圖識別、問題重寫、回答使用者問題這三個節點均採用同一模型串連,因此只需要部署一次DeepSeek-R1即可。在實際生產環境中,您可以根據實際需求分別部署合適的模型,並建立相應的串連,從而確保系統的準確性和高效運行。

情境選擇Embedding,以bge-m3 通用向量模型為例進行部署。

2. 建立串連
2.1 建立LLM服務串連
本文建立的LLM模型服務串連基於快速開始 > Model Gallery中部署的模型服務(EAS服務)。更多其他類型的串連及詳細說明,請參見服務串連配置。
進入LangStudio,選擇工作空間後,在服務串連配置 > 模型服務頁簽下單擊建立串連,建立通用LLM模型服務串連。

關鍵參數說明:
參數 | 說明 |
模型名稱 | 當通過Model Gallery進行模型部署時,可通過模型詳情頁(在Model Gallery頁單擊模型卡片)查看模型名稱的擷取方法,詳情請參見建立串連-模型服務。 |
服務提供者 |
|
2.2 建立Embedding模型服務串連
同2.1 建立LLM服務串連類似,建立通用Embedding模型服務串連。

3. 建立知識庫索引
建立知識庫索引,將語料經過解析、分塊、向量化後儲存到向量資料庫,從而構建知識庫。其中關鍵參數配置說明如下,其他配置詳情,請參見建立知識庫索引。
參數 | 描述 |
基礎配置 | |
資料來源OSS路徑 | 配置前提條件中RAG知識庫語料的OSS路徑。 |
輸出OSS路徑 | 配置文檔解析產生的中間結果和索引資訊的路徑。 重要 當使用FAISS作為向量資料庫時,應用流會將產生的索引檔案儲存到OSS。若使用PAI預設角色(應用流開發-啟動運行時時設定的執行個體RAM角色),應用流可以預設訪問使用者工作空間的預設儲存Bucket,因此建議將此參數配置為當前工作空間預設儲存路徑所在的OSS Bucket下的任一目錄。如果使用自訂角色,您需要為自訂角色授予OSS的存取權限(建議授予AliyunOSSFullAccess許可權),詳情請參見為RAM角色授權。 |
Embedding模型和資料庫 | |
Embedding類型 | 選擇通用Embedding模型。 |
Embedding串連 | 選擇2.2 建立Embedding模型服務串連中建立的Embedding模型服務串連。 |
向量資料庫類型 | 選擇FAISS。本文以FAISS向量資料庫舉例說明。 |
4. 建立並運行應用流
進入LangStudio,選擇工作空間後,在應用流頁簽下單擊建立應用流,建立意圖識別客服應用流。
啟動運行時:單擊右上方建立運行時並進行配置。註:在進行Python節點解析或查看更多工具時,需要保證運行時已啟動。

關鍵參數說明:
專用網路配置:如果3. 建立知識庫索引中向量資料庫類型為Milvus,則需配置Milvus執行個體相同的專用網路,或確保已選的專用網路和Milvus執行個體所在的專用網路已經互連;如果向量資料庫類型為Faiss,則無需配置專用網路。本文以Faiss向量資料庫舉例說明。
開發應用流。

應用流中的其餘配置保持預設或根據實際需求進行配置,關鍵節點配置如下:
意圖識別:通過大語言模型分析使用者輸入的意圖,並根據識別結果執行相應的分支。
多意圖配置:按需設定意圖,確保每個意圖的描述都清晰明確,並且不同意圖之間不存在語義重疊。本文以預設意圖“關於阿里雲PAI產品的問題”舉例說明。
模型設定:選擇2.1 建立LLM服務串連中建立的串連。
對話歷史:是否啟用對話歷史,將歷史對話資訊作為輸入變數。
問題重寫:調用大語言模型重寫匹配到的意圖資訊。
模型設定:選擇2.1 建立LLM服務串連中建立的串連。
對話歷史:和意圖識別節點配置一致。
知識庫檢索:在知識庫中檢索與使用者問題相關的文本。 更詳細的內容介紹,請參見使用知識庫索引。
知識庫索引名稱:選擇3. 建立知識庫索引中建立的知識庫索引。
Top K:返回Top K條匹配的資料。
回答使用者問題:調用大語言模型回答使用者問題。
模型設定:選擇2.1 建立LLM服務串連中建立的串連。
對話歷史:和意圖識別節點配置一致。
其他意圖:自訂Python代碼,可實現更加複雜的資料處理邏輯。
變數彙總:將使用者佈建的意圖和其他意圖進行整合,確保無論哪個分支被執行,其結果都能通過一個統一的變數來引用和訪問。
關於各節點群組件詳情,請參見附錄:預置組件說明。
調試/運行:單擊右上方運行,開始執行應用流。關於應用流程執行時的常見問題,請參見常見問題。
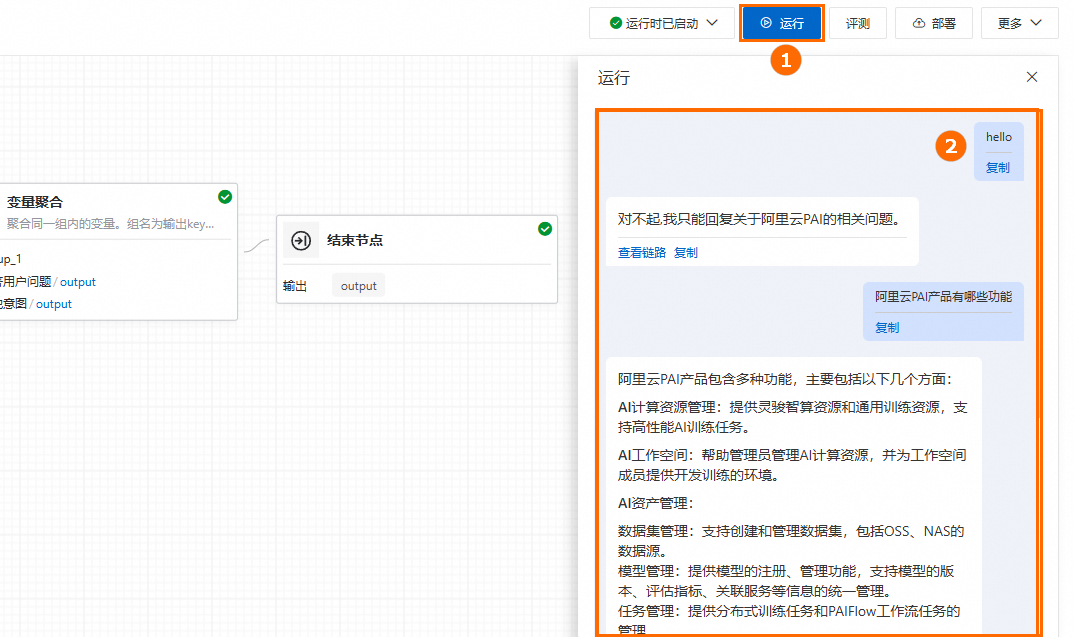
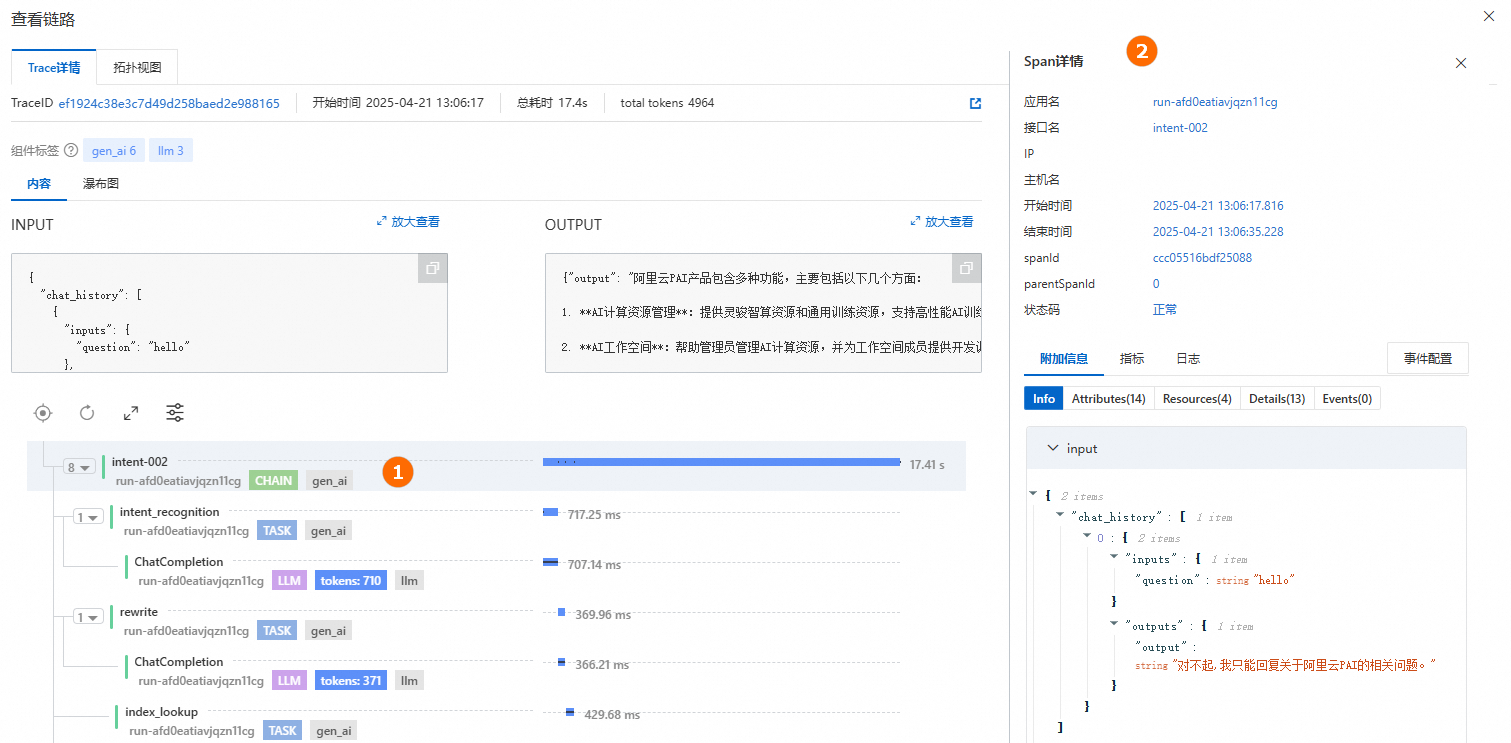
查看鏈路:單擊產生答案下的查看鏈路,查看Trace詳情或拓撲視圖。
5. 部署應用流
在應用流開發頁面,單擊右上方部署,將應用流部署為EAS服務。部署參數其餘配置保持預設或根據實際需求進行配置,關鍵參數配置如下:
資源部署 > 執行個體數:佈建服務執行個體數。本文部署僅供測試使用,因此執行個體數配置為1。在生產階段,建議配置多個服務執行個體,以降低單點故障的風險。
專用網路 > VPC:如果3. 建立知識庫索引中向量資料庫類型為Milvus,則需配置Milvus執行個體相同的專用網路,或確保已選的專用網路和Milvus執行個體所在的專用網路已經互連;如果向量資料庫類型為Faiss,則無需配置專用網路。本文以FAISS向量資料庫舉例說明。
更多部署詳情,請參見應用流部署。
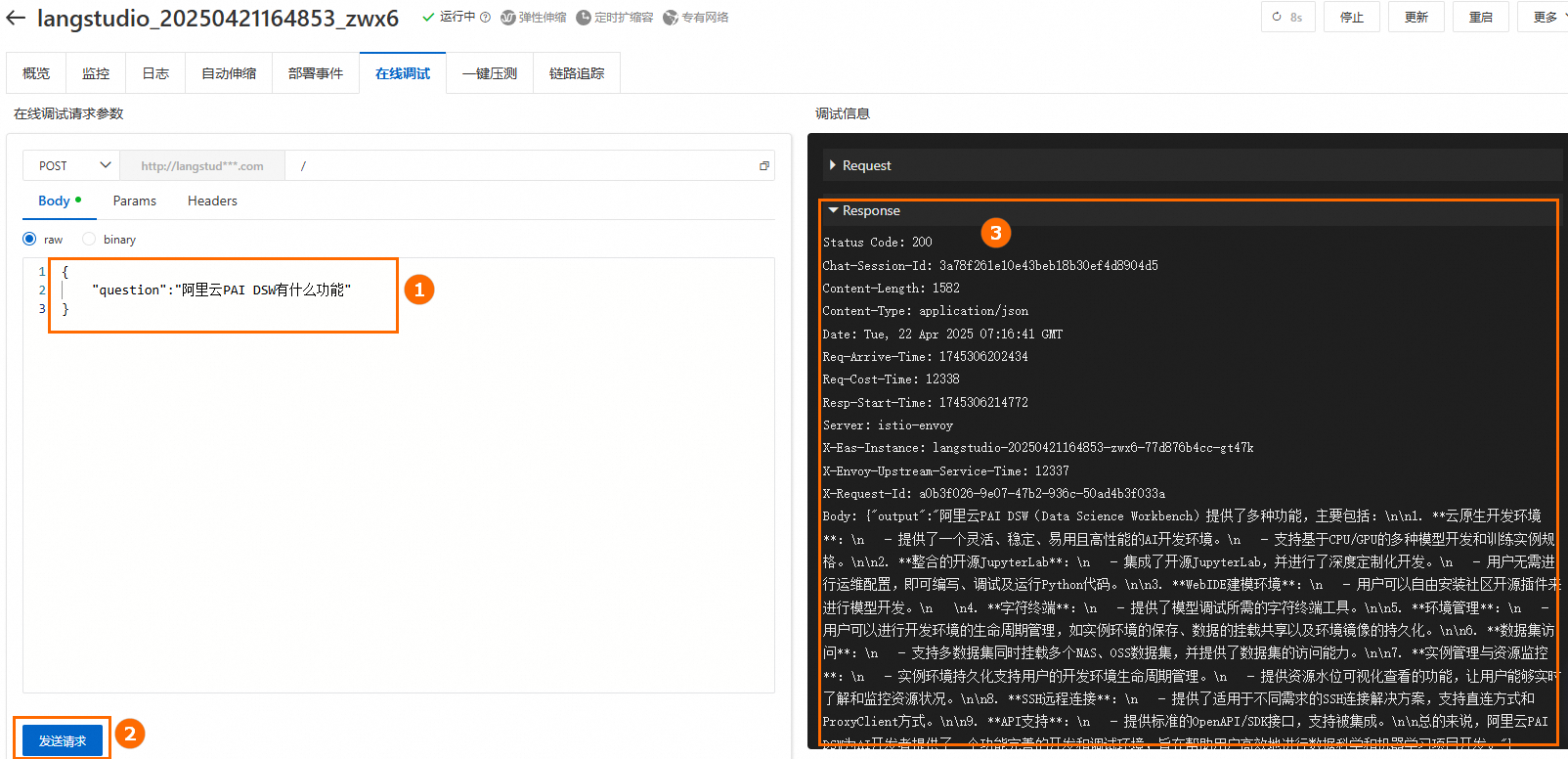
6. 調用服務
部署成功後,跳轉到PAI-EAS,在線上調試頁簽下配置並發送請求。請求Body中的Key與應用流中“開始節點”中的參數"對話輸入"欄位一致,本文使用預設欄位question。
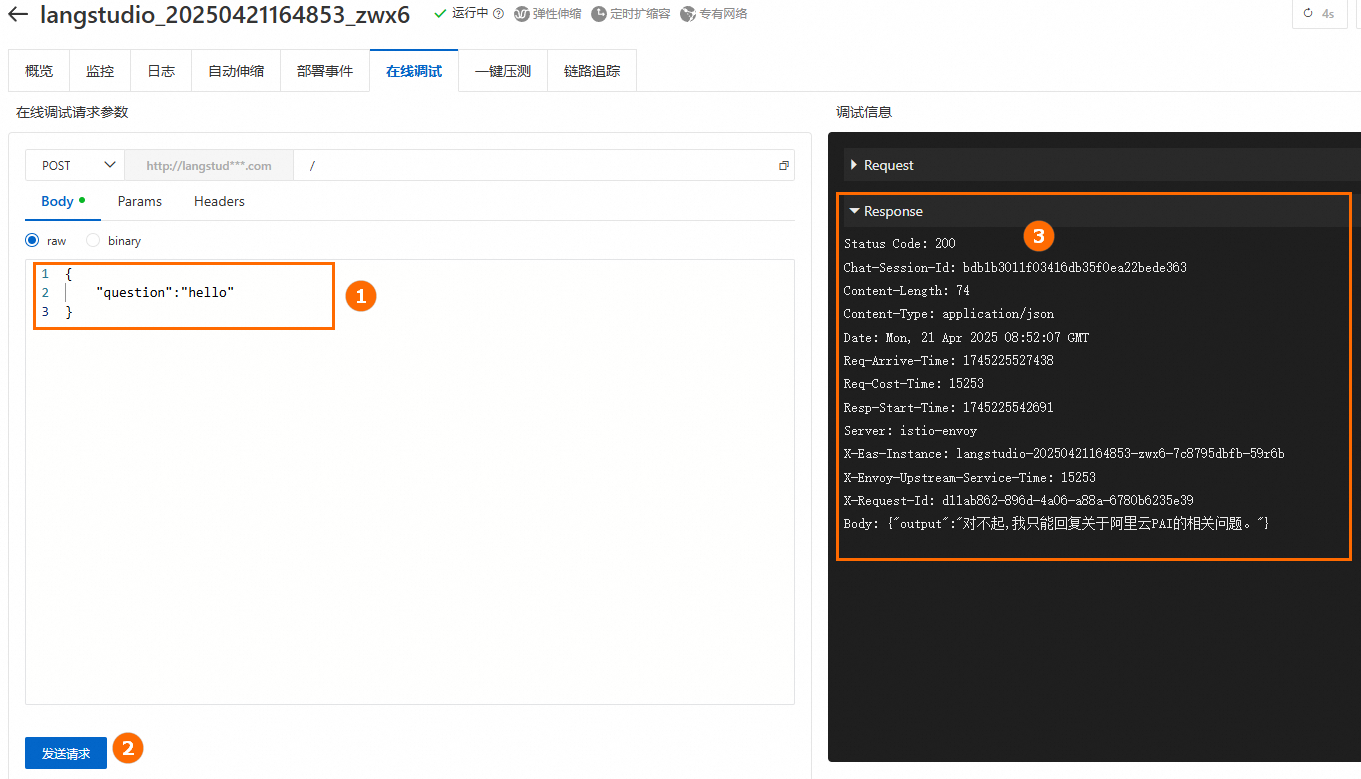
更多調用方式(如API調用)及詳細說明,請參見應用流部署-調用服務。