當您在嘗試如 Prompt 工程、外掛程式調用等最佳化方法後,模型表現仍然不及預期時,請使用阿里雲百鍊的模型調優。模型調優作為改進模型表現的核心策略,可以很好地提升模型在特定行業/業務的表現,對齊人類偏好,降低輸出延遲。模型調優包含模型微調(SFT)、繼續預訓練(CPT)、模型偏好訓練(DPO)三種模型訓練方式。
模型調優介紹
模型調優作為重要的模型效果最佳化方式,可以:
提升模型在特定行業/業務表現
降低模型輸出延遲
抑制模型幻覺
對齊人類的價值觀或偏好
使用調優後的輕量級模型替代規模更大的模型
模型在調優過程中,會學習訓練資料中的知識、語氣、表達習慣、自我認知等業務/情境特徵。也由於已經在訓練過程中學習到了大量特定行業/情境的範例,訓練後模型 One-Shot 或者 Zero-Shot 的 Prompt 效果會比訓練前 Few-Shot 效果更好,這樣可以節省大量輸入 token,從而降低模型輸出延遲。
模型調優流程
詳情參見:
支援的模型
計費說明
計費方式 | 按訓練的資料量計費 |
計費公式 | 模型訓練費用 = (訓練資料 Token 總數 + 混合訓練資料 Token 總數)× 迴圈次數 × 訓練單價(最小計費單位:1 token) 您可以查看模型調優控制台底部的預估訓練費用,並單擊计算详情,查看訓練 Token 總數、迴圈次數和訓練單價。 |
模型調優前必讀
文本產生模型調優雖然能在特定業務/情境取得非常好的效果,但有以下限制:
阿里雲百鍊推薦您在考慮使用文本產生模型調優前先嘗試使用的 Prompt 工程(Prompt Engineering)或外掛程式調用(Function Calling)定製化您的應用,模型調優也通常作為改進模型表現“最後的手段”。因為:
在許多任務中,模型最初可能表現不佳,但通過應用正確的 Prompt 技巧可以改進結果,不一定需要使用模型調優。
迭代最佳化 Prompt、外掛程式,比模型調優的迭代更敏捷、成本更低,因為模型調優的迭代可能需要重新收集資料、清洗最佳化資料、收集 bad case、發起客戶調研等。
即使最後一定要進行模型調優,最初的 Prompt 工程、外掛程式迭代最佳化相關工作也不會浪費。您的這些前期工作可以充分地在構建調優資料集時複用(用於構建資料集的輸入)。
快速開始
使用控制台進行模型調優
調優步驟 | 控制台截圖 |
步驟一:在模型調優頁面點擊创建训练任务。 |
|
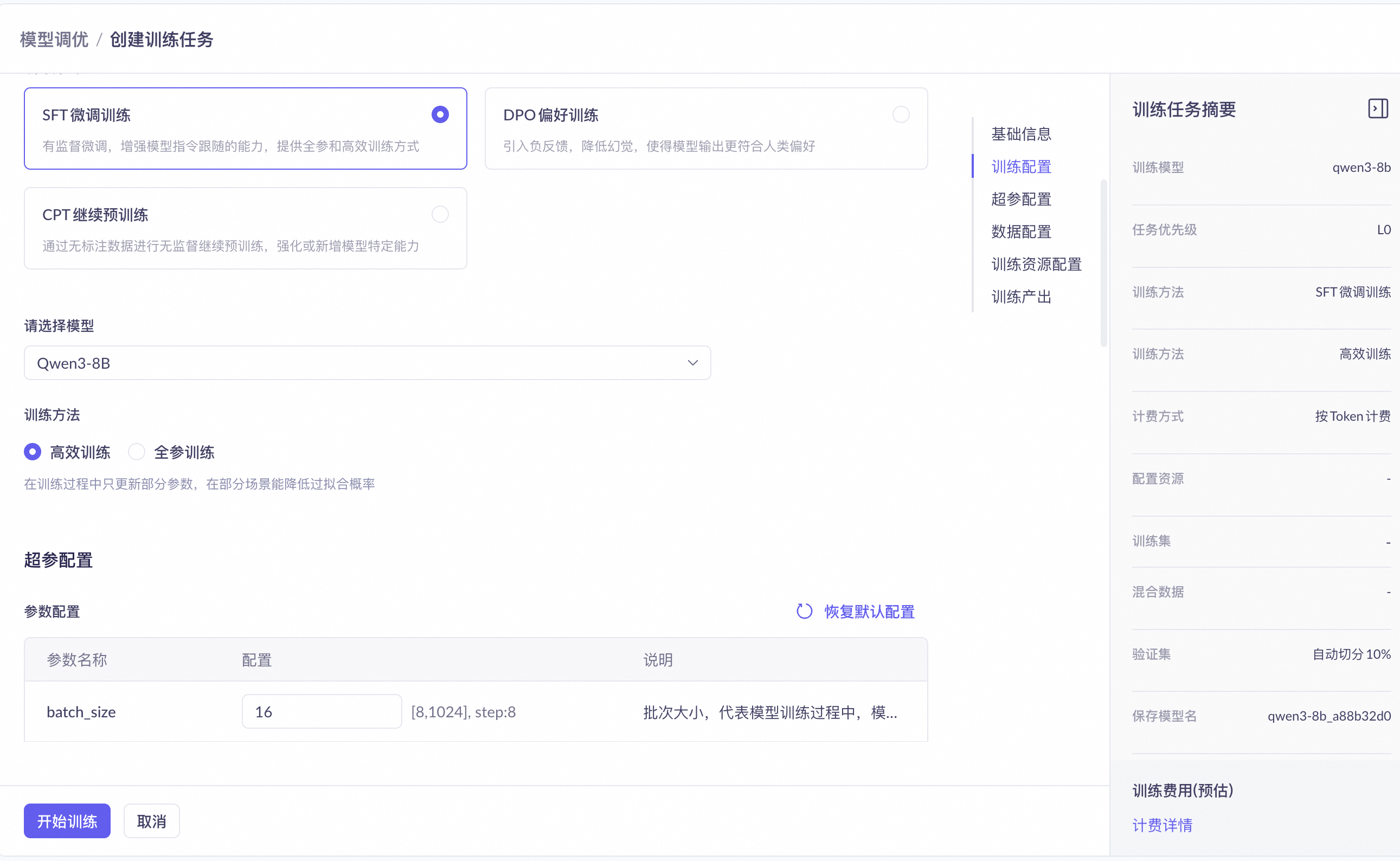
步驟二:訓練配置
這個組合訓練時間短,資料要求低。 | |
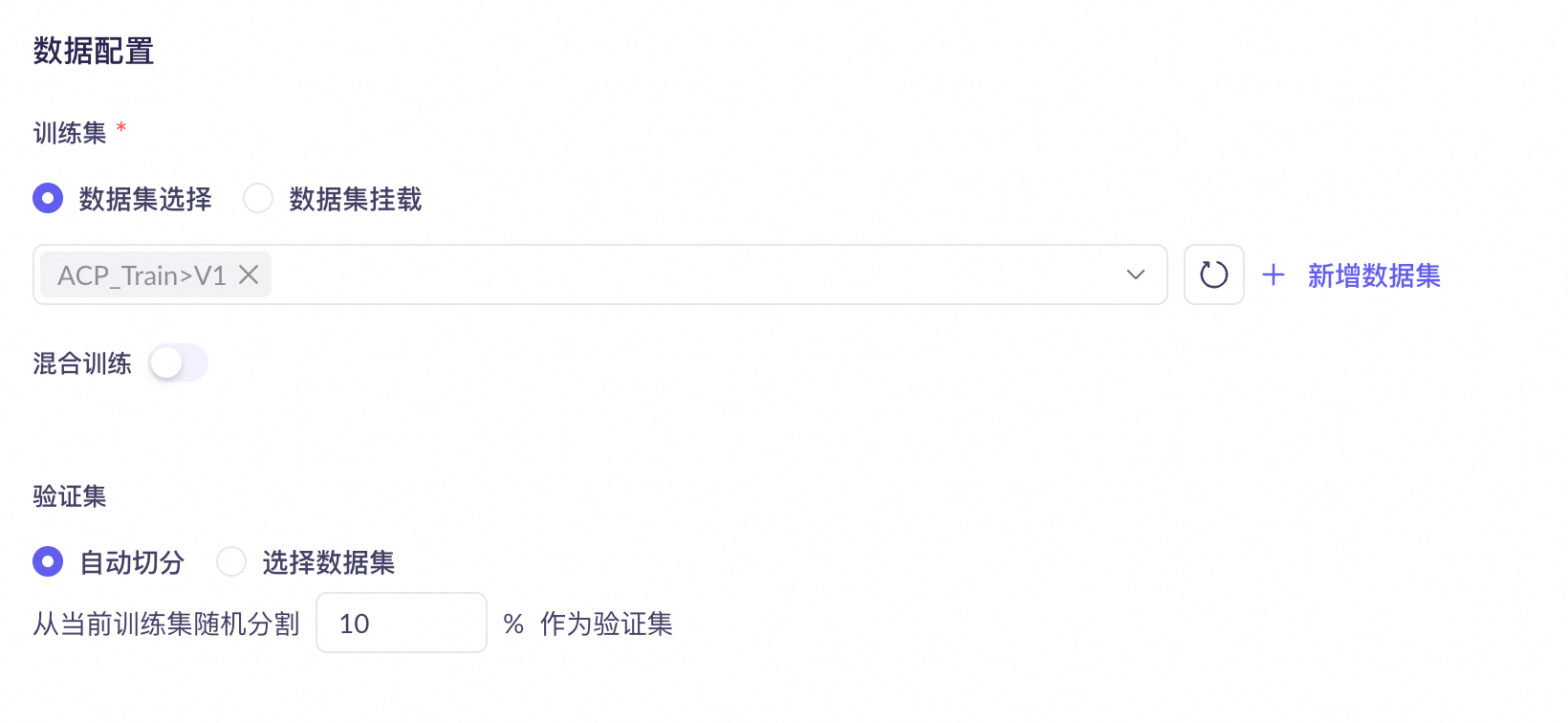
步驟三:資料配置
|
|
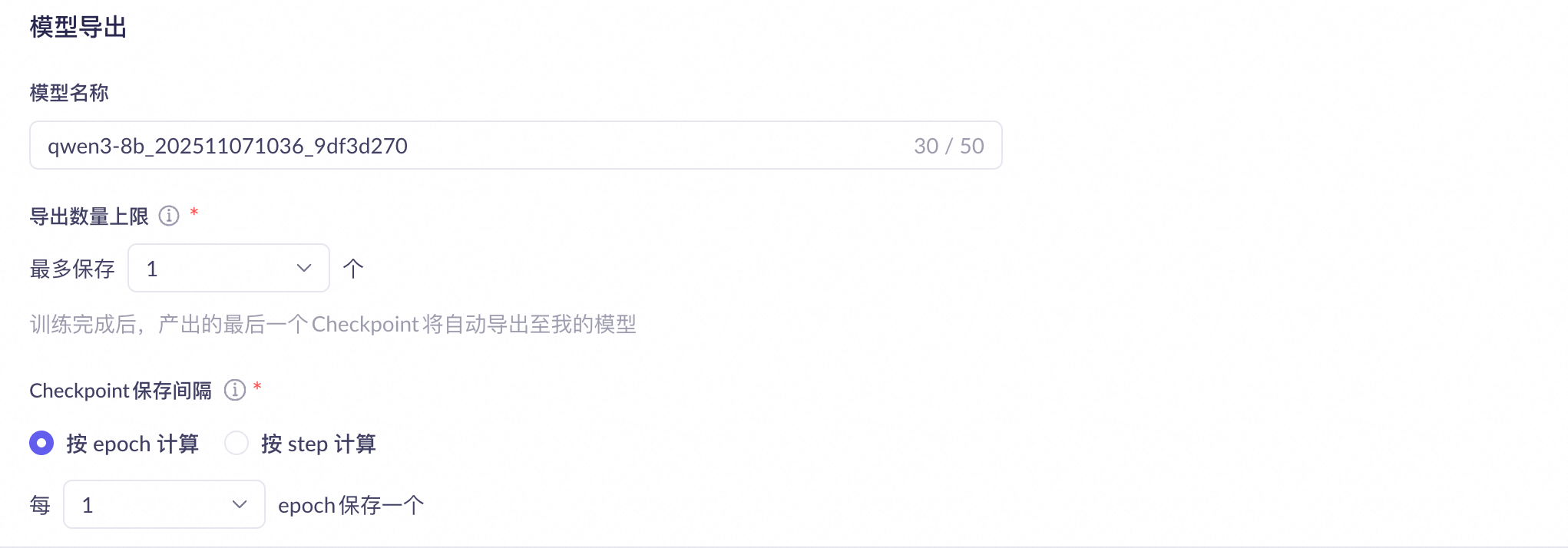
步驟四:配置模型參數快照(Checkpoint)儲存參數
說明 在百鍊平台上,模型調優完成後可以匯出參數快照,匯出後才能基於此版本的參數快照在百鍊上進行模型部署。 匯出的參數快照儲存在雲端儲存中,暫不支援訪問或下載。 |
|
步驟五:點擊“開始訓練”後,等待模型訓練完畢。 | |
步驟六:使用阿里雲百鍊的模型部署功能部署訓練好的自訂模型,部署好後就可以對調優好的模型進行評測。模型部署相關資訊請參見模型部署簡介。 | |
典型的調優流程
百鍊提供的三種調優方式並不互斥,而是遞進的、相輔相成的。
CPT(可選)→ SFT → DPO(可選)
CPT (持續預訓練)- 補知識 (通用模型知識的“廣度”和“淺度”,無法滿足專業領域的“深度”和“精度”要求)
金融模型:
學金融術語醫學模型:
記藥品病理法律模型:
懂法條判例
SFT (監督微調)- 學做事
客服機器人:
學客服流程代碼助手:
學編程範式工具調用 (Agent):
學使用 MCP
DPO (直接偏好最佳化)- 做得更好
安全與責任感:
拒有害建議簡潔與有效性:
答乾脆利落客觀與中立:
評公正客觀
調優資料格式
SFT 訓練集
SFT ChatML(Chat Markup Language)格式訓練資料,支援多輪對話和多種角色設定。
不支援OpenAI 的name、weight參數,所有的 assistant 輸出都會被訓練。
# 一行訓練資料(json 格式),展開後典型結構如下:
{"messages": [
{"role": "system", "content": "系統輸入1"},
{"role": "user", "content": "使用者輸入1"},
{"role": "assistant", "content": "期望的模型輸出1"},
{"role": "user", "content": "使用者輸入2"},
{"role": "assistant", "content": "期望的模型輸出2"}
...
]}system/user/assistant 區別請參見概述,訓練資料集範例:SFT-ChatML格式樣本.jsonl、SFT-ChatML格式樣本.xlsx(xls、xlsx 格式只支援單輪對話)。
單條訓練資料的所有 assistant 行都支援"loss_weight"參數,用於設定該行在訓練時的相對重要性。(設定範圍0.0 ~ 1.0,數值越大,重要性越高)
該參數屬於邀測參數,如需使用,請聯絡您的商務經理。
{"role": "assistant", "content": "期望的模型輸出1", "loss_weight": 1.0},
{"role": "assistant", "content": "期望的模型輸出2", "loss_weight": 0.5}資料集構建技巧
資料集的規模要求
對於CPT來說,資料集最少需要五千萬Token優質預訓練資料;對於 SFT 來說,資料集最少需要上千條優質調優資料;對於 DPO 來說,資料集一般需要上百條人類偏好資料。如果資料調優後的模型評測結果不佳,最簡單的改進方法是收集更多資料進行訓練。
如果您缺乏資料,建議構建智能體應用,使用知識庫索引來增強模型能力。當然在很多複雜的業務情境,可以綜合採用模型調優和知識庫檢索結合的技術方案。
以客服情境為例,可以藉助模型調優解決客服回答的語氣、表達習慣、自我認知等問題,情境涉及的專業知識可以結合知識庫,動態引入到模型上下文中。
阿里雲百鍊推薦您可以先構建 RAG 應用試運行,在收集到足夠的應用資料後再通過模型調優繼續提升模型表現。
您也可以採用以下策略擴充資料集:
讓大模型類比產生特定業務/情境的相關內容,輔助您產生更多用於調優資料。(產生模型建議選取表現優異、規模更大的模型)
通過應用情境收集、網路爬蟲、社交媒體和線上論壇、公開資料集、夥伴與行業資源、使用者貢獻等各種方式,人工擷取更多資料。
資料的多樣性與均衡性
模型調優有不同情境,針對具體業務情境時,專業性更重要;而針對問答情境時通用性更重要。您需要根據模型負責的業務模組或使用情境進行資料用例設計。因此訓練效果好壞並不是僅取決於資料量,更需要考慮針對情境的專業性和多樣性。
這裡以智能 AI 對話情境為例,介紹一個專業、多樣的資料集應該包含的各種業務情境:
具體業務 | 多樣化情境/業務 |
電商客服 | 活動推送、售前諮詢、售中引導、售後服務、售後回訪、投訴處理等。 |
金融服務 | 貸款諮詢、投資理財顧問、信用卡服務、銀行賬戶管理等。 |
線上醫學 | 病症諮詢、挂號預約、就診須知、藥品資訊查詢、健康小建議等。 |
AI 秘書 | IT 資訊、行政資訊、HR 資訊、員工福利解答、公司日曆查詢等。 |
旅遊出行助手 | 旅行規劃、出入境指南、旅行保險諮詢、目的地風土人情介紹等。 |
企業法律顧問 | 合約審核、智慧財產權保護、合規性檢查、勞動法律答疑、跨境交易諮詢、個案法律分析等。 |
還請特別注意的是各個情境/業務的資料數量應相對均衡,資料比例符合實際情境比例,避免某一類資料過多導致模型偏向於學習該類特徵,影響模型的泛化能力。
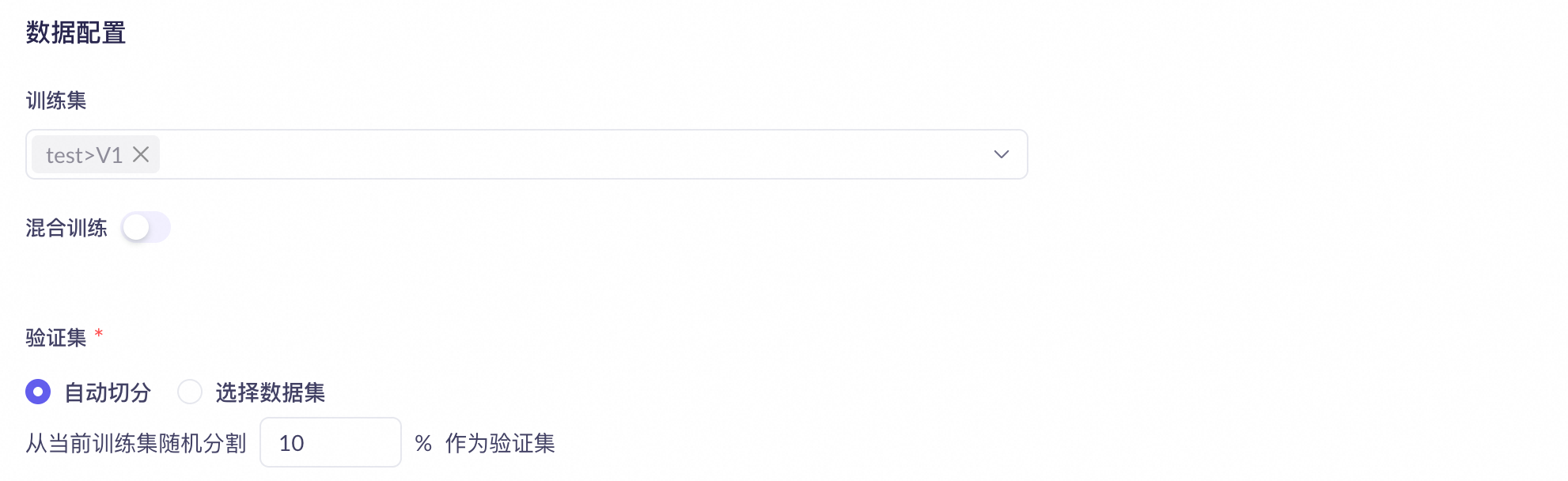
訓練集與驗證集拆分
當您使用控制台進行模型調優時,支援
自動將一個完整訓練資料集拆分,隨機抽取少量資料群組成驗證集。
選擇獨立上傳資料集。
控制台可以在訓練時及時方便地顯示驗證集 Loss 和 Token Accuracy。
常見問題
是否支援調優自己的模型呢?
百鍊不支援調優和上傳自己的模型,也不支援匯出下載後的模型。