ACK預設整合了阿里雲可觀測產品,提供多種可觀測功能,幫您快速構建容器情境的營運體系。您可以通過本文推薦的基礎功能快速搭建容器可觀測體系,也可深入閱讀各章節內容,構建覆蓋ACK叢集基礎設施資料面(Data Plane)、控制面(Control Plane)及業務系統(Application)的完整監控體系,進而提升整體穩定性。
可觀測性介紹
為了保障系統在其環境發生變化時仍能持續穩定地運行並滿足需求,我們需要通過可觀測性來及時觀測和響應故障、預防或(手動、自動)恢複故障,並具備相應的擴充能力。可觀測性提供能夠反映叢集資源的實體狀態、事件的即時資料,例如指標Metrics、日誌Logging、調用鏈路Tracing等,協助保障穩定性、故障快速排查、系統效能調優等。從容器情境來看,可觀測性可以分為4個層次:基礎設施層、作業系統層、容器或叢集層以及應用程式層。
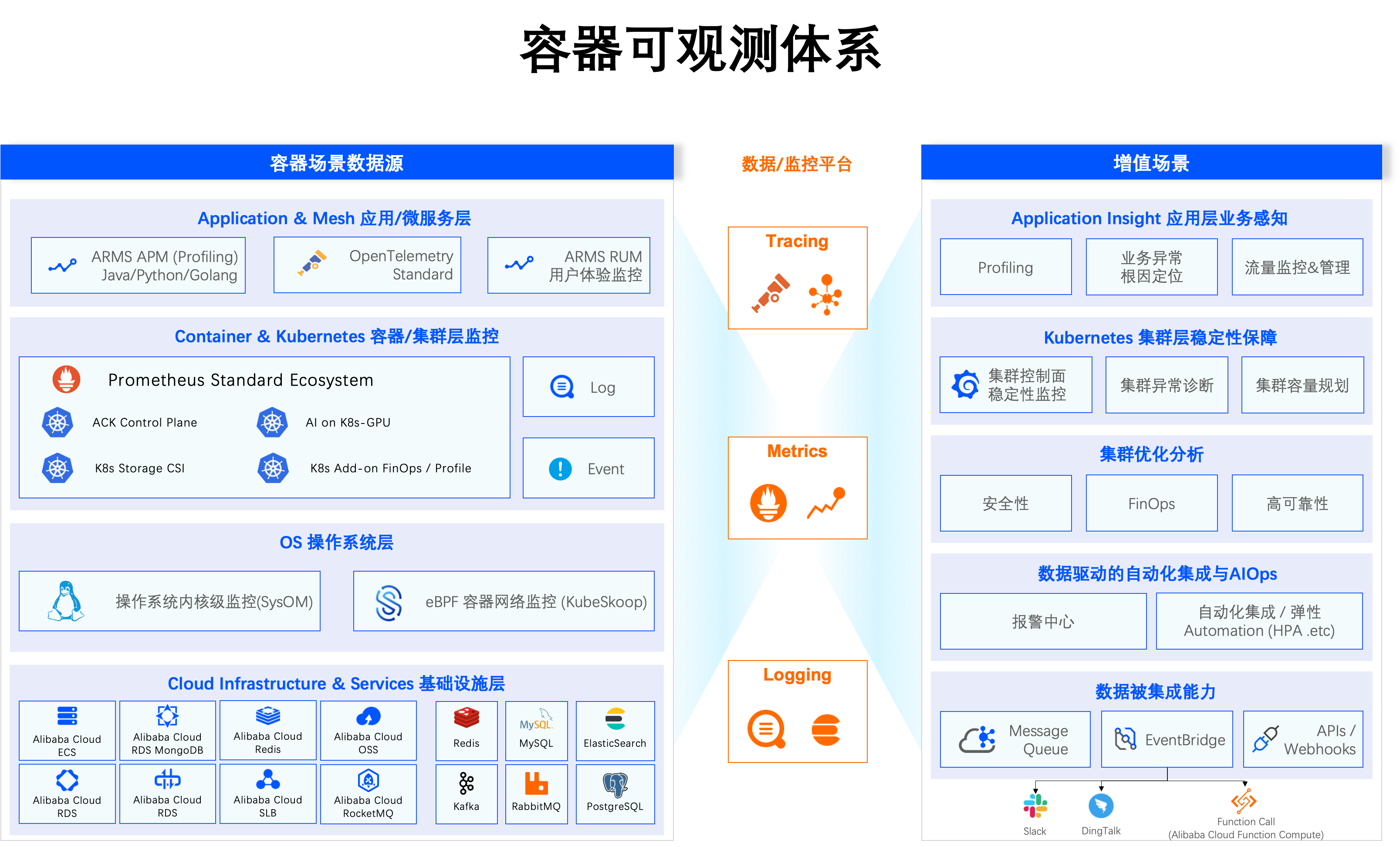
從可觀測性的角度,維護容器叢集的穩定性可以分為以下3個層面。
-
叢集基礎設施控制面(Control Plane)
-
叢集的kube-apiserver 、etcd、kube-scheduler、kube-controller-manager、cloud-controller-manager組件的健康狀態與承載能力。
-
叢集控制面組件提供服務相關的關鍵資源,如 kube-apiserver的SLB頻寬、串連數等。
-
-
叢集基礎設施資料面(Data Plane)
-
叢集節點的健康情況,如節點的異常狀態、資源異常、節點GPU壞卡、節點記憶體水位高等。
-
叢集使用者側組件的穩定性,例如容器儲存群組件或功能、容器網路組件或功能等。
-
-
部署在叢集中的使用者業務系統(Application)
-
應用程式健康情況,例如使用者業務的Pod和應用程式健康情況。常見異常狀態包括Pod的記憶體不足導致的Pod或進程退出(OOM Kills)、Pod未就緒等。
-
推薦啟用的功能列表
本小節介紹ACK提供的開箱即用的可觀測功能,以便快速構建容器情境的營運體系。
通用穩定性情境
-
在ACK叢集中部署ack-node-problem-detector組件,以開啟事件監控功能。關於支援的叢集檢查項,請參見NPD中GPU壞卡事件、NPD支援的問題檢查外掛程式。
-
在ACK叢集中部署Prometheus,包括接入與配置阿里雲Prometheus監控(推薦)和開源Prometheus監控,即時監控叢集和容器的健康情況。部署阿里雲Prometheus後,您可以實現以下資源的監控:
-
ACK託管叢集控制面組件監控
-
基礎容器資源監控,包括Node、Workload、Pod。
-
-
啟用事件監控和Prometheus監控後,建議進一步配置連絡人、連絡人群組為負責叢集或應用的人員,配置對應的警示規則並訂閱對應的通知對象連絡人群組。
-
開啟ECS節點CloudMonitor外掛程式,獲得ECS宿主機層基礎指標監控,如進程監控、網路監控等。
-
將Pod日誌接入至阿里雲Log ServiceSLS。如果業務應用沒有實現記錄檔的拆分,推薦直接使用Pod的
stdout日誌,請參見採集ACK叢集容器日誌。 -
對叢集中使用Ingress進行業務應用的流量路由,開啟Ingress日誌明細監控大盤,請參見採集與分析 Nginx Ingress 訪問日誌。
-
對作業系統層資源進行監控,開啟SysOM容器情境作業系統核心級監控功能,請參見SysOM核心層容器監控。
-
為叢集中部署的重要業務開啟APM應用效能監控功能,按實際應用的開發語言與環境選擇對應合適的APM方案,請參見Java應用監控、Python應用監控、Golang應用監控、什麼是可觀測鏈路 OpenTelemetry 版以及對應的接入指南。
-
對於部署在Container Service中的Web應用、移動端及小程式等終端,如需實現使用者體驗行為監控,建議啟用阿里雲應用即時監控服務(ARMS)中的使用者體驗監控(RUM)功能,該方案支援從頁面載入效能到API請求失敗率的全鏈路追蹤。
服務網格ServiceMesh情境
服務網格ServiceMesh情境下,推薦啟用以下能力。
-
監控ServiceMesh資料面AccessLog日誌以監控所有訪問請求,請參見使用Log Service採集資料面叢集AccessLog。
-
通過Prometheus監控ServiceMesh資料面的指標請參見整合可觀測監控Prometheus版實現網格監控。
-
開啟網路拓撲監控功能,觀測並評估微服務間調用流量、時延是否符合預期,通過ServiceMesh資料面的Prometheus監控指標作為資料來源,查看相關服務與配置的可視化介面,請參見開啟網格拓撲提高可觀測性。
-
通過定義衡量服務品質SLO等級,以觀測調用的錯誤與延時行為,請參見SLO管理。
-
在應用代碼中接入OpenTelemetry協議,並開啟在ASM中實現分布式跟蹤功能。
多雲混合雲ACK ONE情境
使用ACK One註冊叢集或ACK One多叢集艦隊構建的多雲混合雲情境下,推薦啟用以下能力。
-
ACK One註冊叢集提供和ACK一致的可觀測能力體驗,包括將Log Service接入註冊叢集、將事件中心接入註冊叢集、將警示配置功能接入註冊叢集、將應用即時監控服務ARMS接入註冊叢集、將阿里雲Prometheus接入註冊叢集,請參見具體文檔搭建網路環境並實現監控能力。
-
為ACK One 多叢集艦隊開啟全域監控,獲得統一的監控能力。此外,還可以啟用統一警示管理,保證已下發的警示規則在各個關聯集群中的一致性,詳情請參見多叢集統一警示管理,以及支援單個子叢集的多叢集警示差異化配置。
-
當使用者使用ACK One GitOps時,監控艦隊叢集的核心組件的穩定性和GitOps對全託管的Argo CD的運行和效能情況,請參見艦隊監控 。並推薦開啟GitOps控制面日誌與審計日誌,配置GitOps ArgoCD警示,請參見配置ACK One ArgoCD警示。
下文將從叢集基礎設施控制面(Control Plane)、叢集基礎設施資料面(Data Plane)、使用者業務系統(Application)的穩定性體系層面分別介紹推薦的可觀測具體最佳實務解決方案。
一、叢集基礎設施控制面(Control Plane)

Kubernetes叢集控制面負責叢集的API層、調度、Kubernetes資源管理、雲資源管理、中繼資料存放區等控制面功能,控制面的主要組件包括kube-apiserver、kube-scheduler、kube-controller-manager、cloud-controller-manager和etcd。
ACK託管叢集的控制面由阿里雲完全託管並提供SLA保障(請參見阿里雲Container ServiceKubernetes版服務等級協議)。為提升控制面的可觀測性,協助您更好地管理、配置和調優叢集,您可以參見以下功能即時監控和觀測叢集控制面的負載健康情況並預設配置相關警示,從而預防異常問題的發生,保障業務的持續穩定運行。
開啟控制面組件監控
ACK擴充增強了kube-apiserver組件提供的Kubernetes的RESTful API介面,使得外部客戶端、叢集內的其他組件(如標準的Prometheus採集)可以與ACK叢集互動,從而擷取叢集Control Plane組件的Prometheus指標。
-
如您使用阿里雲Prometheus,您可以在ACK託管叢集Pro版中使用開箱即用的叢集控制面監控大盤,請參見查看叢集控制面組件監控大盤。
-
如您使用自建Prometheus方案,可參見通過自建Prometheus採集控制面組件指標並配置警示進行資料接入。
監控叢集控制面組件日誌
ACK叢集支援將叢集控制面組件日誌收集到您帳號的SLS Project中,請參見採集ACK託管叢集控制面組件日誌。
開啟Container Service警示功能
ACK提供預設警示規則,覆蓋大部分需要高優先順序關注的容器情境異常,您也可自行調整警示規則。
阿里雲 Prometheus、阿里雲Log ServiceSLS以及此ACK叢集相關的其他雲資源的CloudMonitor的資料進行警示規則判斷並通知異常,請參見Container Service警示管理。
若您使用自建Prometheus方案,可參見使用Prometheus配置警示規則的最佳實務配置警示。
二、叢集基礎設施資料面(Data Plane)
叢集節點
ACK通過叢集節點來提供業務部署資源環境。保障容器情境的穩定性時,您還需要關注每個節點的異常狀態、資源負載情況等。雖然Kubernetes提供調度、搶佔與驅逐等機制,在一定情況下能容忍部分節點的異常,以保證整體系統可靠性,但從穩定性角度來看,還需要更多對節點異常進行預防、觀測和響應恢複的手段。
使用ack-node-problem-detector組件與事件監控
ack-node-problem-detector組件是ACK提供的用於事件監控功能的組件,相容社區Node-Problem-Detector組件,支援在叢集資料面進行節點環境異常巡檢,並對ACK的節點環境、作業系統、容器引擎進行了適配增強。
ack-node-problem-detector組件提供以下功能:
-
通過組件中的node-problem-detector DaemonSet對叢集節點環境、作業系統相容性、容器引擎等進行了適配增強。
-
增強了節點巡檢項功能,NPD支援的問題檢查外掛程式以外掛程式形式提供,巡檢頻率時效性為1分鐘內,滿足大多數日常節點營運情境。
-
預設持久化事件監控資料至90天,且組件中包含kube-eventer Deployment,負責將所有叢集中的Kubernetes Event上傳至阿里雲SLS的事件中心。預設情況下,叢集內Kubernetes Event儲存在etcd中,且只能查詢最近1小時內事件數目據。ack-node-problem-detector組件提供的持久化方式可以支援生產業務系統對歷史事件的查詢。
當ack-node-problem-detector組件發現節點異常狀態時,您可以通過kubectl describe node ${NodeName}命令查看該節點異常Condition,或者在節點頁面的節點列表查看節點異常狀態。
同時,您還可以在開啟了ACK事件監控功能後,使用Container Service警示管理功能,例如訂閱某關鍵業務Pod的啟動失敗事件、Service的Endpoint不可用等事件。SLS監控服務還支援發送事件警示。
開啟叢集節點ECS進程級監控
ACK叢集的每個節點的宿主機(Host)通常對應一台阿里雲ECS執行個體,推薦為ECS執行個體開啟阿里雲CloudMonitor服務提供的進程監控功能。
CloudMonitorECS監控提供兩方面能力:
-
進程級監控能力:回溯節點記錄點Top5的進程對記憶體、CPU、開啟檔案數等關鍵資源的消耗。
-
ECS宿主機的作業系統層監控能力:監控宿主機CPU、記憶體、網路、磁碟水位、inode數、宿主機網路流量、網路同時串連數等宿主機層面的基礎資源指標。
為節點池開啟CloudMonitor進程監控後,僅針對節點池中後續新增的節點生效。
開啟Container Service警示管理,訂閱節點例外狀況事件、資源水位異常規則
Container Service警示管理支援叢集事件監控,提供節點異常狀態事件以及資源水位異常等警示配置。推薦開啟並訂閱其中多個與節點有關的警示規則集,例如叢集節點異常警示規則集、叢集資源異常警示規則集等。
節點作業系統Journal日誌的監控與持久化
Systemd是Linux系統的一個初始化系統和服務管理員,負責啟動系統後的所有服務。其中,Journal是Systemd的一個組成部分,用於收集和儲存系統日誌。在容器情境下,如需擷取kubelet、作業系統層等涉及節點穩定性的關鍵計量日誌,需通過Systemd Journal日誌資料進行查詢和分析。在對作業系統層、容器引擎層穩定性敏感的情境下(如業務進程使用特權容器模式、需頻繁超賣節點資源等直接使用作業系統資源情境),推薦使用此方式收集作業系統層日誌進行監控。請參見採集叢集節點的Systemd Journal日誌資料採集日誌資料並將日誌儲存至SLS Project中。
GPU或AI訓練情境
如果您在ACK叢集中部署了AI訓練任務、機器學習任務等,ACK提供節點GPU異常狀態、GPU資源的即時指標監控等功能。推薦方案如下。
-
節點GPU壞卡巡檢:推薦安裝並升級ack-node-problem-detector組件版本至 1.2.20及以上。ACK支援巡檢NPD中GPU壞卡事件,詳情請參見NPD中GPU壞卡事件。
關於GPU異常的處理方案,請參見常見GPU故障類型與解決方案進行排查。
-
GPU資源監控:叢集GPU監控提供Pod維度GPU資源消耗情況。通過ACK的ack-gpu-exporter組件,您可以獲得相容Nvidia DCGM標準的GPU監控指標。ACK針對共用GPU和獨佔GPU兩種情境提供Pod層級的GPU監控指標,詳情請參見監控指標說明。
如需瞭解實現對叢集GPU節點的全方位監控的詳細步驟,請參見監控叢集GPU資源最佳實務。
-
Container Service警示管理:開啟事件監控功能,通過Container Service警示管理訂閱節點GPU例外狀況事件警示,並參見常見GPU故障類型與解決方案進行異常處理。
叢集資料面系統組件(容器儲存和容器網路)
容器儲存
ACK叢集中的容器儲存方式包括節點的本機存放區、Secret和ConfigMap,以及外部儲存介質(例如NAS儲存卷、CPFS儲存卷、OSS儲存卷等)。
ACK通過csi-plugin組件統一透出上述容器儲存使用方式的監控指標,再通過阿里雲Prometheus進行統一採集,以提供開箱即用的監控大盤,詳情請參見容器儲存可觀測最佳實務文檔。關於支援和不支援監控功能的容器儲存方式,以及對應的監控方法,請參見容器儲存監控概述。
容器網路
CoreDNS
CoreDNS組件是叢集的DNS服務發現機制的關鍵組件。您需要關注叢集資料面中CoreDNS組件的資源情況、CoreDNS解析異常返回碼(rcode)等關鍵計量(如CoreDNS大盤中的 Responses (by rcode)指標)、DNS解析異常行為(NXDOMAIN、SERVFAIL、FormErr)等,以保障組件穩定性。推薦啟用以下功能。
-
在ACK叢集中使用阿里雲Prometheus,使用開箱即用的CoreDNS監控大盤,請參見CoreDNS組件監控。自建Prometheus可以通過社區CoreDNS監控方式配置指標採集進行監控。
-
建議開啟Container Service警示管理功能,並訂閱如叢集網路例外狀況事件警示規則集,包括CoreDNS修改配置後若配置Load不成功等CoreDNS狀態例外狀況事件警示通知。叢集容器副本異常警示規則集也覆蓋CoreDNS的Pod狀態、資源等問題。
-
查看CoreDNS日誌來分析CoreDNS解析慢、訪問高危請求網域名稱等問題,請參見分析和監控CoreDNS日誌。
Ingress
使用Ingress進行業務應用的對客流量路由時,您需要關注Ingress的流量情況和Ingress的明細調用情況,並在Ingress路由狀態異常時進行警示。推薦啟用以下功能。
-
在ACK叢集中使用阿里雲Prometheus以及阿里雲Container Service的Ingress Controller,使用開箱即用的Ingress流量監控大盤。
-
通過SLS監控Ingress日誌,請參見採集與分析 Nginx Ingress 訪問日誌。
-
使用ACK提供的Ingress鏈路追蹤功能,將Nginx Ingress Controller組件的鏈路資訊上報至可觀測鏈路OpenTelemetry版,對鏈路資訊進行即時彙總計算和持久化,形成鏈路明細、即時拓撲等監控資料,以便進行問題排查與診斷。例如,您可以參見通過AlbConfig開啟Xtrace實現鏈路追蹤觀測ALB Ingress的鏈路追蹤資料。
-
開啟Container Service警示管理功能,並訂閱如叢集網路例外狀況事件警示規則集,訂閱Ingress路由的異常狀態事件警示。
基礎容器網路流量監控
ACK叢集通過節點kubelet透出了社區標準的容器監控指標,包括基本的容器網路流量指標,可以滿足大多數情境下的網路流量監控需求,包括容器Pod的出入流量、異常網路流量、網路包監控等。
但當應用Pod定義為HostNetwork模式時,Pod將會繼承宿主機的進程網路行為,導致基礎的容器監控指標無法準確反映Pod維度網路流量。推薦啟用以下功能。
-
使用阿里雲Prometheus或者自建Prometheus方案監控kubelet監控指標,以獲得基本的容器網路流量情況。使用阿里雲Prometheus時,ACK提供開箱即用的基本網路流量監控能力,支援在Pod監控大盤中查看。
-
監控宿主機ECS的網路流量時,可參見查看執行個體監控資訊在ECS控制台查看監控資料。
三、使用者業務系統(Application)
ACK提供容器副本Pod監控、容器應用日誌監控等手段,用於觀測叢集上部署的業務應用的穩定性。
應用程式容器副本Pod監控
叢集上部署的業務應用以Pod的形式在叢集中運行。Pod的狀態和資源負載情況直接影響其上啟動並執行應用效能。推薦啟用以下功能。
-
通過Prometheus監控容器Pod狀態、資源水位:通過阿里雲Prometheus或自建Prometheus方案採集ACK叢集通過節點kubelet透出的社區標準的容器監控指標,並結合kube-state-metrics組件(包含在阿里雲Prometheus組件或ACK提供的社區prometheus-operator組件Helm Chart)透出的Kubernetes對象的狀態資料,監控完整的Pod容器監控,包括Pod的CPU、Memory、儲存、基礎容器網路流量等監控資料。ACK叢集結合阿里雲Prometheus提供了開箱即用的Pod容器監控大盤。
-
通過事件監控監控容器Pod的異常狀態:Pod狀態發生變化時會產生事件。當Pod出現異常狀態時,推薦開啟事件監控監控異常資訊。
您可以在控制台的事件中心頁面查看時間監控,並將事件持久化至SLS事件中心,以查看歷史90天的監控事件。您也可以根據Pod的事件監控大盤查看由Pod Event串聯的整個Pod生命週期時間軸,從而觀察Pod的異常狀態。
-
訂閱應用工作負載和容器副本的異常狀態事件警示:啟用Container Service警示和管理和事件監控後,推薦同時開啟並訂閱其中多個與工作負載和容器副本Pod有關的警示規則集,包括叢集應用工作負載警示規則集、叢集容器副本異常警示規則集等。具體操作,請參見使用Prometheus配置警示規則的最佳實務。
-
自訂Prometheus警示規則,訂閱資源警示:由於應用部署有多樣性需求,如不同業務應用需要保持不同的水位、對不同的關鍵資源有特殊需求等,推薦按照實際業務應用的需求配置自訂的Prometheus指標警示。
您可以在控制台的Prometheus 監控頁面右上方跳轉至對應的叢集Prometheus執行個體並建立警示規則,請參見建立Prometheus警示規則。您也可以通過Prometheus標準的PromQL自訂的警示規則,請參見容器副本異常,也可以參考其中關於工作負載異常、容器副本異常等內容的範例警示規則,修改PromQL以自訂Prometheus的警示規則。
容器應用日誌監控
叢集中的業務系統會產生業務日誌,記錄關鍵業務過程。監控這些業務日誌有助於異常診斷排查和業務行為狀態判斷。
ACK提供Kubernetes日誌功能,以便排查和診斷問題。ACK叢集提供了無侵入的方式進行應用的日誌管理,您可以參見採集ACK叢集容器日誌採集應用日誌,並使用SLS提供的多種日誌統計分析功能。
應用進程的細粒度記憶體資源監控
Kubernetes中,容器記憶體即時使用量(Pod Memory)通過Working Set Size工作記憶體(WSS)來表示,是Kubernetes調度機制判斷容器副本記憶體資源分派的關鍵計量。WSS包含多個作業系統Kernel的記憶體成分(不包含Inactive(anno)),以及多個細緻的作業系統層記憶體成分。當您的應用進程使用不同細分記憶體成分(如寫入檔案系統時產生的額外pagecache記憶體等)時,可能遇到內部記憶體“黑洞”問題,在生產系統中需要重點監控。
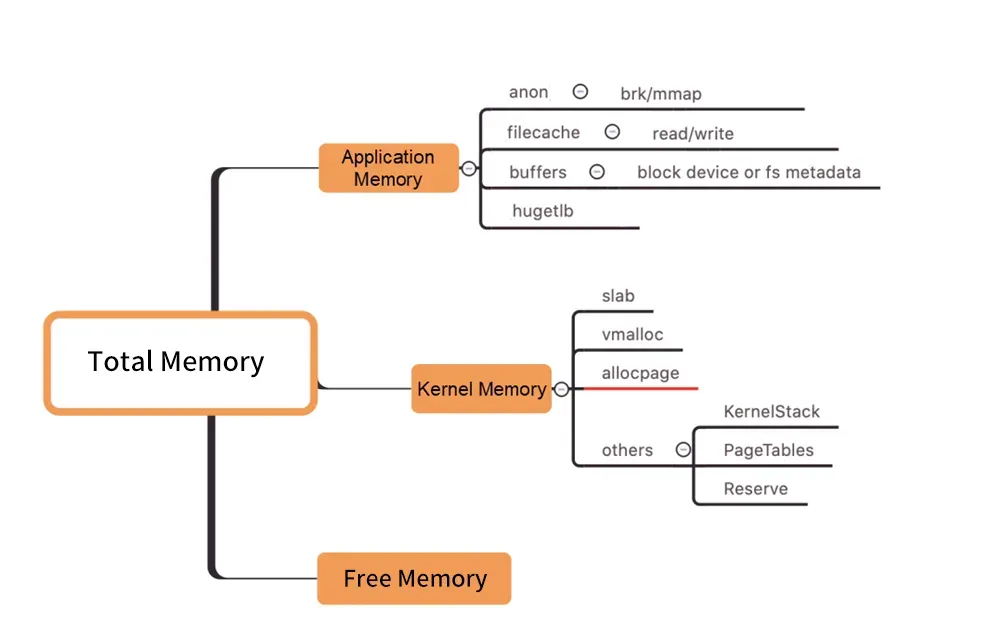
當您使用 Pod 記憶體的其他各成分不符合預期,都有可能最終造成 WorkingSet 工作負載升高,繼而導致PodOOMKilling或者整個節點記憶體水位過高,出現節點驅逐等現象。例如,在容器環境中運行Java應用程式時,在某些通用配置下,Log4J和Logback等日誌架構會預設使用NIO(New I/O)和mmap(記憶體對應檔)技術來處理日誌輸出,這可能導致額外的匿名記憶體使用量。這種模式在處理大量日誌時會頻繁地進行記憶體的讀寫操作,併產生額外的匿名記憶體等,繼而在容器環境中引發記憶體配置黑洞的問題。
為解決因容器引擎層的不透明性而導致的故障排查困難問題,ACK提供作業系統核心層的容器監控可觀測能力,使得容器引擎層更為可視化,以便進行容器化遷移。您可以參見SysOM核心層容器監控在ACK叢集中啟用SysOM監控功能,並參見使用SysOM定位容器記憶體問題通過SysOM功能觀測與收斂容器記憶體問題。
應用業務指標接入Prometheus監控,並繪製自訂業務大盤
如果您對業務應用邏輯有一定開發能力,推薦使用Prometheus Client監控應用來暴露業務應用本身的指標,並通過Prometheus監控系統配置採集接入,繪製統一的監控大盤。您可以對團隊不同角色(如Infra團隊、負責業務應用團隊)繪製不同視角的監控大盤,以應對日常定性保障,或出現異常時快速處理恢複情境,提供低MTTR快速響應能力。
接入應用效能監控APM和Tracing能力
應用效能監控(Application Performance Monitoring,簡稱APM)是監控領域監控應用進程本身效能的通用解決方案。阿里雲ARMS提供多種APM形態的產品能力,您可以根據開發語言選擇對應方式。
-
Java應用的無侵入APM監控(無侵入式):您可以參見Java應用監控實現無侵入APM監控,即在不改動代碼的情況下接入Java應用監控功能。接入後,您可以實現自動探索應用拓撲、自動產生3D拓撲、自動探索並監控介面、JVM資源監控、捕獲異常事務和慢事務等監控功能,大幅提升線上問題診斷的效率。
-
Python應用的APM監控(侵入式,需調整容器鏡像構建Dockerfile):對於部署在ACK叢集中的Python應用(例如使用Django、Flask、FastAPI架構構建的Web應用或基於LlamaIndex、Langchain等開發的AI、LLM應用),可以安裝ack-onepilot組件並調整Dockerfile,以實現應用效能監控,包括應用拓撲、鏈路追蹤、介面調用分析、異常檢測等功能以及針對大型模型互動過程中的細緻追蹤記錄,請參見Python應用監控。
-
Golang應用的APM監控(侵入式,需構建容器鏡像時通過編譯工具編譯應用的Golang二進位檔案):對於運行在ACK叢集中的Golang應用,可以通過安裝ack-onepilot組件,並在構建應用的容器鏡像時通過編譯工具instgo編譯應用的Golang二進位檔案。完成部署後,可以在ARMS中查看對應應用的應用拓撲、介面調用、資料庫分析等監控資料,請參見Golang應用監控。
-
容器中應用通過OpenTelemetry協議接入(侵入式,需代碼支援或接入OpenTelemetry協議):可觀測鏈路 OpenTelemetry 版為分布式應用的開發人員提供了完整的調用鏈路還原、調用請求量統計、鏈路拓撲、應用依賴分析等工具,以便快速分析和診斷分布式應用架構下的效能瓶頸,提高微服務時代的開發診斷效率。OpenTelemetry協議有多種資料接入方式,出於對穩定性和方案成熟度等級等方面的考慮,您可以參見接入指南,根據不同開發語言選擇應用的OpenTelemetry接入方式。
前端Web行為監控RUM
當您在叢集中的業務系統對外部使用者暴露Web前端頁面時,前端頁面需要穩定和連續保障。ARMS提供的使用者體驗監控RUM功能專註於Web情境、App行動裝置 App情境和小程式情境的監控,以使用者體驗為切入點,完整再現使用者操作過程,從頁面開啟速度(測速)、請求服務調用(API)和故障分析(JS錯誤、網路錯誤等)、穩定性(JS錯誤、崩潰、ANR等)方面監測前端應用效能表現情況,並支援日誌資料查詢,協助您快速跟蹤定位故障原因。詳情請參見接入應用選擇接入方式。
基於服務網格ServiceMesh實現對服務行為的可觀測
阿里雲服務網格ASM提供一個全託管式的服務網格平台,相容社區Istio開源服務網格,用於簡化服務的治理,包括服務調用之間的流量路由與拆分管理、服務間通訊的認證安全以及網格可觀測能力,從而極大地減輕開發與營運的工作負擔。
ASM在進行微服務治理時可以通過增強可觀測能力感知業務系統的穩定性保障,如Day0系統上線階段的流量配置狀態、Day1各微服務間流量的分布觀測、通過定義SLO指標對Day2系統運行階段的穩定性保障等。ASM提供了統一標準化的ServiceMesh可觀測能力,為您提供一種收斂後的可觀測資料產生與採集配置模式,以更好地支援雲原生應用的可觀測性。
-
監控ServiceMesh控制平面日誌以確保流量路由配置正確:通過使用ASM網格診斷手動檢測當前可能影響服務網格功能正常啟動並執行異常項,通過警示處理建議即時觀測流量路由策略配置是否正常運行,並通過配置即時異常日誌警示即時處理異常情況。
-
監控ServiceMesh資料平面AccessLog日誌以監控所有訪問請求:ServiceMesh訪問日誌監控功能可供快捷查看日誌,還可以對這些日誌進行收集、檢索或建立Dashboard,請參見使用Log Service採集資料面叢集AccessLog。
-
通過Prometheus監控ServiceMesh資料平面的指標:將資料平面指標採集到阿里雲Prometheus中後,可從網關狀態、網格全域、網格服務等級、網格工作負載等多個維度實現全面監控,發現潛在的問題並及時調整和最佳化,請參見將監控指標採集到可觀測監控Prometheus版、整合可觀測監控Prometheus版實現網格監控。
-
通過網路拓撲監控觀測並評估微服務間調用流量、時延是否符合預期:將資料平面的Prometheus監控指標作為資料來源,可直觀觀測並評估微服務間調用流量、時延是否符合預期。詳情請參見開啟網格拓撲提高可觀測性。
-
衡量服務品質SLO等級,以觀測調用的錯誤與延時行為:SLO提供了一種通過定義具體量化監控指標的方式來描述、衡量和監控微服務應用程式的效能、品質和可靠性,可作為衡量服務水平品質以及持續改進的參考,詳情請參見服務等級目標SLO概述。
-
啟用分布式鏈路追蹤,使用完整的調用鏈路還原、調用請求量統計、鏈路拓撲、應用依賴分析等能力:在應用代碼中接入OpenTelemetry協議,並開啟在ASM中實現分布式跟蹤功能。
多雲混合雲情境的統一觀測
分布式雲容器平台ACK One是阿里雲面向混合雲、多叢集、分散式運算、容災等情境推出的企業級雲原生平台。ACK One可以串連並管理您任何地區、任何基礎設施上的Kubernetes叢集,並提供一致的管理和社區相容的API,支援對計算、網路、儲存、安全、監控、日誌、作業、應用、流量等進行統一營運管控。
主要的情境包括:
-
混合云:使用ACK One註冊叢集實現雲下IDC自建Kubernetes叢集接入雲端構建混合雲,並支援按需在雲上伸縮計算資源和應用。
-
多云:使用ACK多叢集艦隊,納管多個ACK叢集或ACK註冊叢集,構建多雲同城容災、統一應用配置分發、多叢集離線調度等。
針對多雲混合雲常見推薦啟用的可觀測能力如下。
-
為ACK One註冊叢集接入ACK可觀測能力:ACK One註冊叢集提供和ACK一致的可觀測能力體驗,包括將Log Service接入註冊叢集、將事件中心接入註冊叢集、將警示配置功能接入註冊叢集、將應用即時監控服務ARMS接入註冊叢集、將阿里雲Prometheus接入註冊叢集。但由於接入的網路環境、許可權體系不同均需要額外的網路打通以及授權步驟。
-
ACK多叢集艦隊全域監控:隨著業務的開展,企業需要構建多個Kubernetes叢集來滿足隔離、高可用、容災等需求,但現有的監控系統往往針對單個Kubernetes叢集。ACK One 多叢集艦隊提供全域監控功能,基於阿里雲Prometheus全域彙總執行個體將多個叢集的Prometheus監控指標彙總到一個統一的監控大盤,簡化了多叢集營運中的監控和問題診斷流程,避免頻繁切換和手動對比各叢集的監控指標。您可以在接入ACK多叢集艦隊後開啟全域監控功能,並關聯子叢集至此多叢集艦隊中,請參見全域監控。
-
ACK多叢集艦隊統一警示管理:通過多叢集統一警示管理能力,在Fleet執行個體中配置或修改警示規則。由Fleet執行個體將警示規則統一下發到指定的關聯集群中,且保證已下發的警示規則在各個關聯集群中的一致性。同時,Fleet執行個體可以對新關聯的叢集自動同步警示規則,請參見多叢集統一警示管理、多叢集警示差異化配置。
-
ACK One GitOps情境:在ACK One多叢集艦隊中提供了艦隊的核心組件(APIServer、ETCD)監控和GitOps監控,監控艦隊及全託管的Argo CD的運行和效能情況,請參見艦隊監控 。還可以開啟GitOps日誌,請參見開啟GitOps控制面日誌與審計日誌,配置GitOps ArgoCD警示,請參見配置ACK One ArgoCD警示。
監控Argo Workflows工作流程中的應用
Argo Workflows是一個強大的雲原生工作流程引擎,廣泛應用於批量資料處理、機器學習Pipeline、基礎設施自動化以及CI/CD等情境。在ACK中使用Argo Workflows工作流程部署應用或使用分布式工作流程Argo叢集部署工作流程應用時,建議啟用以下可觀測能力,以確保應用的穩定性和可維護性。
-
使用Log Service持久化Argo Workflows中的應用日誌:工作流程完成時,通常需要配置工作流程和Pod的回收策略,以清理相應的資源,避免叢集控制面和工作流程控制器資源的線性增長。然而,原生的叢集在Pod清理後無法查看Pod或工作流程日誌,因此工作流程叢集整合了SLS,用來收集工作流程運行過程中Pod產生的日誌,並上報至SLS Project。您可以通過Argo CLI或Argo UI便捷地查看工作流程的日誌,請參見使用Log Service。
-
在工作流程叢集中使用Prometheus監控服務:工作流程叢集整合阿里雲Prometheus,提供完善的可觀測能力,以查看工作流程健全狀態和叢集的健康情況,請參見使用Prometheus監控服務。
觀測通過Knative架構部署的應用
Knative是一款基於Kubernetes的Serverless架構,支援基於請求的自動彈性、在沒有流量時將執行個體數量自動縮容至零、版本管理與灰階發布等能力。在完全相容社區Knative和Kubernetes API的基礎上,ACK Knative進行了多維度能力增強,例如通過保留執行個體降低冷啟動時間、基於AHPA(Advanced Horizontal Pod Autoscaler)實現彈性預測等。您可以通過Knative的可觀測能力實現服務監控、日誌接入監控能力,詳情請參見Knative可觀測性。
-
在Knative上實現日誌採集:如需採集Knative服務的容器文本日誌,可以通過DaemonSet的方式,在每個節點上自動運行一個日誌代理,以提升營運效率。ACK叢集已相容Log ServiceSLS,支援無侵入式採集日誌,請參見在Knative上實現日誌採集。
-
通過阿里雲Prometheus查看Knative服務監控大盤:在Knative中部署業務應用後,可以將Knative服務的監控資料接入Prometheus,通過Grafana大盤即時查看Knative的Pod擴縮容趨勢、響應延遲、請求並發數、CPU和記憶體資源用量等資料,詳情請參見查看Knative服務監控大盤。