GPU監控基於NVIDIA DCGM實現對叢集GPU節點的監控。本文將介紹如何查看基於三種不同的GPU申請方式所展現出的監控結果。
前提條件
背景資訊
GPU監控支援對叢集GPU節點進行全方位監控,提供叢集維度、節點維度和應用Pod維度GPU監控大盤。可參見監控面板說明瞭解更多詳細資料。
-
在叢集維度GPU監控大盤,您可以查看叢集或節點池維度相關資訊,例如叢集層面的利用率、顯存使用、XID錯誤偵測等。
-
在節點維度GPU監控大盤,您可以查看節點維度相關資訊,例如節點中GPU詳情、利用率、顯存使用等。
-
在應用Pod維度GPU監控大盤,您可以查看Pod維度相關資訊。例如Pod申請的GPU資源、利用率等。
本文以如下流程為例,介紹三種不同的GPU申請方式所展現出的不同監控結果。
注意事項
-
當前GPU監控指標的採集間隔為15秒,這可能導致Grafana監控儀錶盤展示的資料存在一定延遲。因此可能會出現在監控顯示節點無可用顯存,但實際Pod還能調度到該節點上。出現該現象可能是在兩次監控採集之間(15 秒內)有Pod完成任務並釋放GPU資源,調度器感知後,將處於Pending的Pod調度到這個節點上。
-
監控大盤只支援監控通過在Pod中配置
resources.limits的方式申請的GPU資源。更多資訊,請參見為Pod和容器管理資源。節點使用GPU資源時存在以下情況,可能會導致監控大盤的資料不準確:
-
直接在節點上運行GPU應用。
-
通過
docker run命令直接啟動容器運行GPU應用。 -
在Pod的
env中直接添加環境變數NVIDIA_VISIBLE_DEVICES=all或NVIDIA_VISIBLE_DEVICES=<GPU ID>等,通過環境變數NVIDIA_VISIBLE_DEVICES直接為Pod申請GPU資源,並且運行了GPU程式。 -
在Pod的
securityContext中配置privileged: true,並且運行了GPU程式。 -
在Pod中未設定環境變數
NVIDIA_VISIBLE_DEVICES,但Pod所使用的鏡像在製作時,預設配置環境變數NVIDIA_VISIBLE_DEVICES=all,並且運行了GPU程式。
-
-
GPU卡已指派的顯存和已使用的顯存不一定相同。例如某一張GPU卡共有16 GiB顯存,為某個Pod分配了5 GiB顯存,但Pod的啟動命令為
sleep 1000,即Pod處於Running但需要經過1000秒後才會使用GPU,因此存在GPU卡已指派的顯存為5 GiB,但已使用的顯存為0 GiB的情況。
步驟一:建立節點池
Pod按整張卡方式或顯存維度申請GPU資源(包括申請GPU算力資源),GPU監控大盤均可以展示其相關指標。
本樣本將在叢集中建立三個節點池,展示不同GPU資源申請模式下的Pod調度與資源佔用情況。關於建立節點池的具體步驟,請參見建立節點池。節點池部分資訊如下:
|
配置項 |
說明 |
樣本值 |
|
節點池名稱 |
節點池一的名稱。 |
exclusive |
|
節點池二的名稱。 |
share-mem |
|
|
節點池三的名稱。 |
share-mem-core |
|
|
執行個體規格 |
節點的執行個體規格,本文以運行Tensorflow Benchmark專案為例,需申請10 GiB顯存,節點規格需大於10GiB。 |
ecs.gn7i-c16g1.4xlarge |
|
期望節點數 |
節點池應該維持的總節點數量。 |
1 |
|
節點標籤(Labels) |
節點池一添加的標籤。表示按整張卡的維度申請GPU資源。 |
無 |
|
節點池二添加的標籤。表示按GPU顯存維度申請GPU資源。 |
ack.node.gpu.schedule=cgpu |
|
|
節點池三添加的標籤。表示按GPU顯存維度申請GPU資源且支援算力申請。 |
ack.node.gpu.schedule=core_mem |
步驟二:部署GPU應用
節點池建立完成後,為了驗證節點GPU相關指標是否正常,需要在節點上運行一些GPU測試工作。可參見開啟調度功能瞭解各任務所需匹配標籤及調度關係。三個任務的部分資訊如下:
|
任務名稱 |
任務啟動並執行節點池 |
申請的GPU資源 |
|
tensorflow-benchmark-exclusive |
exclusive |
nvidia.com/gpu: 1 表示申請1張GPU卡。 |
|
tensorflow-benchmark-share-mem |
share-mem |
aliyun.com/gpu-mem: 10 表示申請10 GiB顯存。 |
|
tensorflow-benchmark-share-mem-core |
share-mem-core |
表示申請10 GiB顯存和1張GPU卡的30%算力。 |
-
建立Job檔案。
-
使用以下YAML內容,建立tensorflow-benchmark-exclusive.yaml檔案。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-exclusive spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-exclusive spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #申請1張GPU卡。 workingDir: /root restartPolicy: Never -
使用以下YAML內容,建立tensorflow-benchmark-share-mem.yaml檔案。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-share-mem spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-share-mem spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: aliyun.com/gpu-mem: 10 #申請10 GiB顯存。 workingDir: /root restartPolicy: Never -
使用以下YAML內容,建立tensorflow-benchmark-share-mem-core.yaml檔案。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-share-mem-core spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-share-mem-core spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: aliyun.com/gpu-mem: 10 #申請10 GiB顯存。 aliyun.com/gpu-core.percentage: 30 #申請1張卡的30%算力。 workingDir: /root restartPolicy: Never
-
-
執行以下命令,部署Job任務。
kubectl apply -f tensorflow-benchmark-exclusive.yaml kubectl apply -f tensorflow-benchmark-share-mem.yaml kubectl apply -f tensorflow-benchmark-share-mem-core.yaml -
執行以下命令,查看Pod的運行狀態。
kubectl get pod預期輸出:
NAME READY STATUS RESTARTS AGE tensorflow-benchmark-exclusive-7dff2 1/1 Running 0 3m13s tensorflow-benchmark-share-mem-core-k24gz 1/1 Running 0 4m22s tensorflow-benchmark-share-mem-shmpj 1/1 Running 0 3m46s由預期輸出得到,Pod均處於
Running狀態,表示Job任務部署成功。
步驟三:查看GPU監控大盤
查看叢集GPU監控-叢集維度
-
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
-
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
-
在Prometheus監控大盤列表頁面,單擊GPU 監控頁簽,然後單擊叢集GPU監控-叢集維度頁簽。叢集維度監控大盤的資訊如下,更多資訊,請參見叢集維度監控大盤。
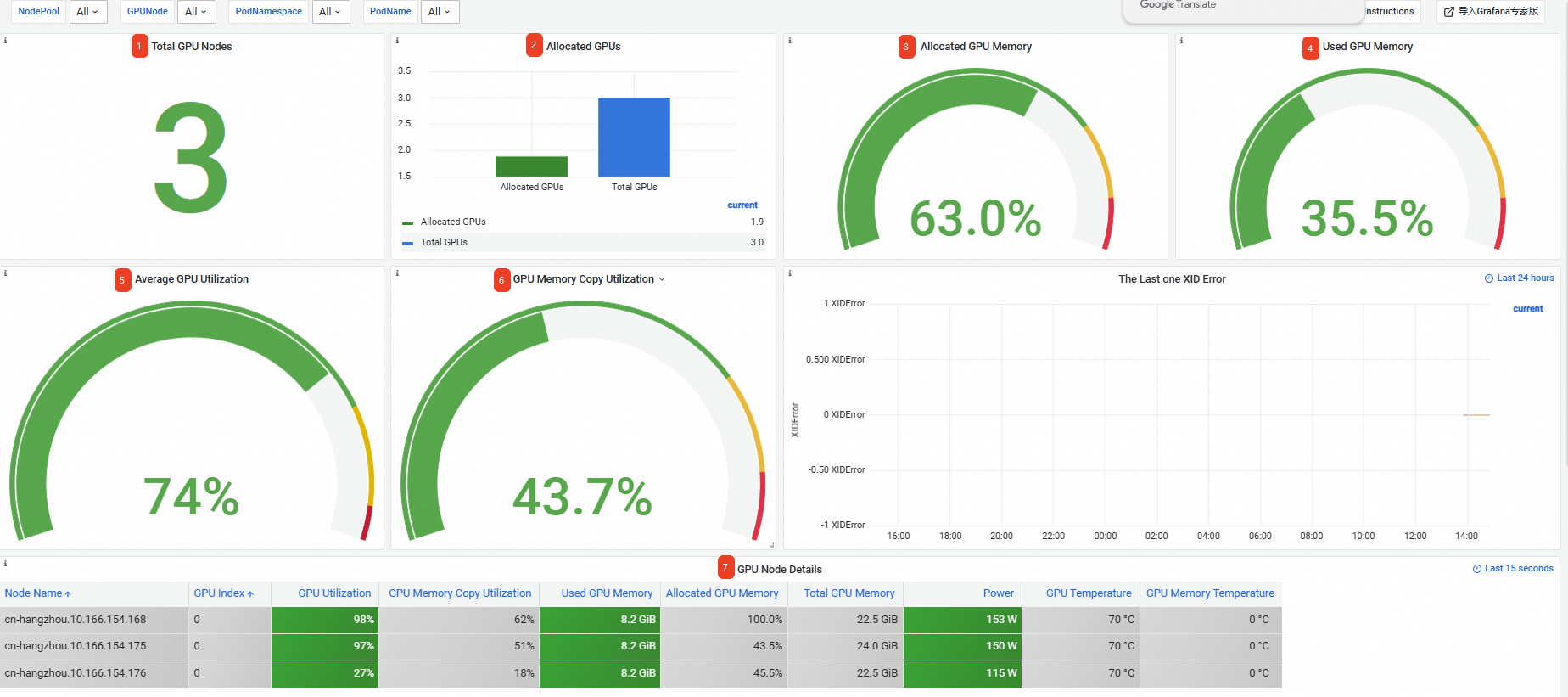
序號
Panel名稱
說明
①
Total GPU Nodes
共有3個GPU節點。
②
Allocated GPUs
GPU總數為3,已指派GPU數為1.9。
說明如果是按整張卡維度申請GPU,一張卡分配的比例為1;如果是共用GPU調度,分配比例為某張卡已指派的顯存與這張卡總顯存的比例。
③
Allocated GPU Memory
已指派63.0%的顯存。
④
Used GPU Memory
已使用35.5%的顯存。
⑤
Average GPU Utilization
所有卡的平均利用率為74%。
⑥
GPU Memory Copy Utilization
所有卡的平均記憶體複製利用率為43.7%。
⑦
GPU Node Details
叢集中GPU節點的資訊,包括節點名稱、GPU卡索引號、GPU利用率、記憶體控制器利用率等。
查看叢集GPU監控-節點維度
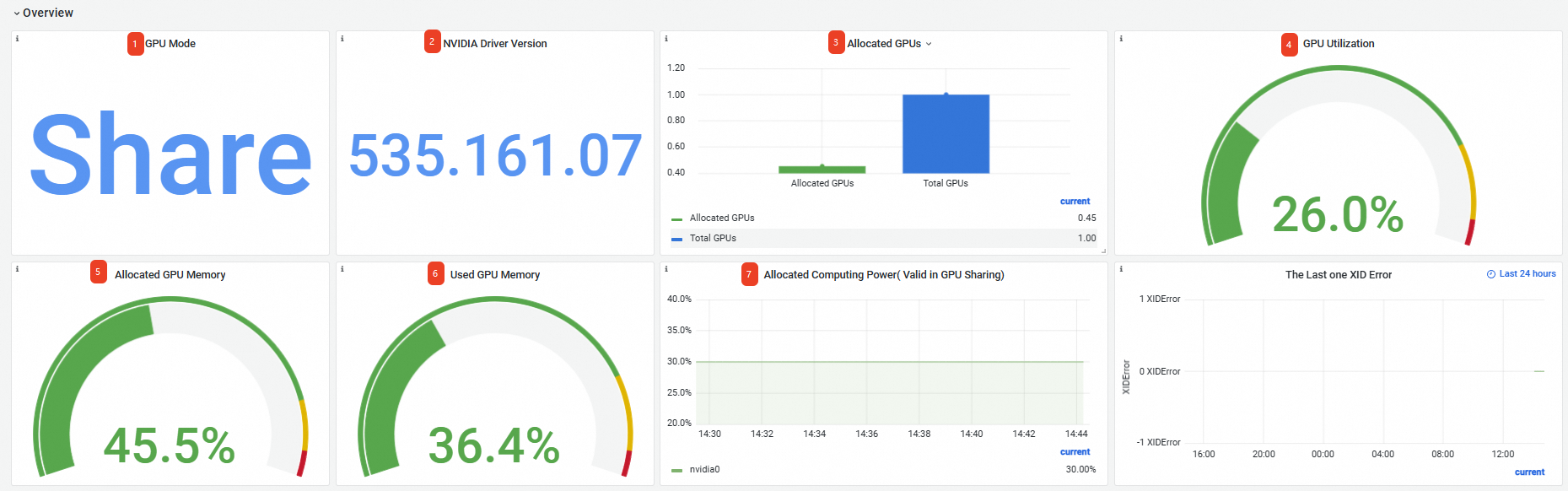
在Prometheus監控大盤列表頁面,單擊GPU 監控頁簽,然後單擊叢集GPU監控-節點維度頁簽,選擇GPUNode為目標節點,本文以cn-hangzhou.10.166.154.xxx為例。節點維度監控大盤的資訊如下:

GPU Process Details 面板表格中除 Pod 資訊外,還提供 Container Name、Allocate Mode、Process Id、Process Name、Process Type、GPU Index、Used GPU Memo、SM Utilization、GPU Memory Copy Util、Decode Utilization 和 Encode Utilization 指標列。
|
Panel組 |
序號 |
Panel名稱 |
說明 |
|
Overview |
① |
GPU Mode |
GPU模式為共用模式,按顯存和算力維度申請GPU資源。 |
|
② |
NVIDIA Driver Version |
安裝的GPU驅動版本為535.161.07。 |
|
|
③ |
Allocated GPUs |
總GPU個數為1,已指派GPU個數為0.45。 |
|
|
④ |
GPU Utilization |
GPU的平均利用率為26%。 |
|
|
⑤ |
Allocated GPU Memory |
已指派的GPU顯存值佔總顯存值的45.5%。 |
|
|
⑥ |
Used GPU Memory |
當前使用的GPU顯存值佔總顯存值的36.4%。 |
|
|
⑦ |
Allocated Computing Power |
0號GPU卡已指派30%算力。 說明
只有在節點開啟算力分配的情況下,節點已指派的算力比例(Allocated Computing Power)才有資料顯示,因此本文樣本的三個節點,只有包含 |
|
|
Utilization |
⑧ |
GPU Utilization |
0號GPU卡利用率最小值為0%,最大值為33%,平均值為12%。 |
|
⑨ |
Memory Copy Utilization |
0號GPU卡記憶體複製利用率最小值為0%,最大值為22%,平均值為8%。 |
|
|
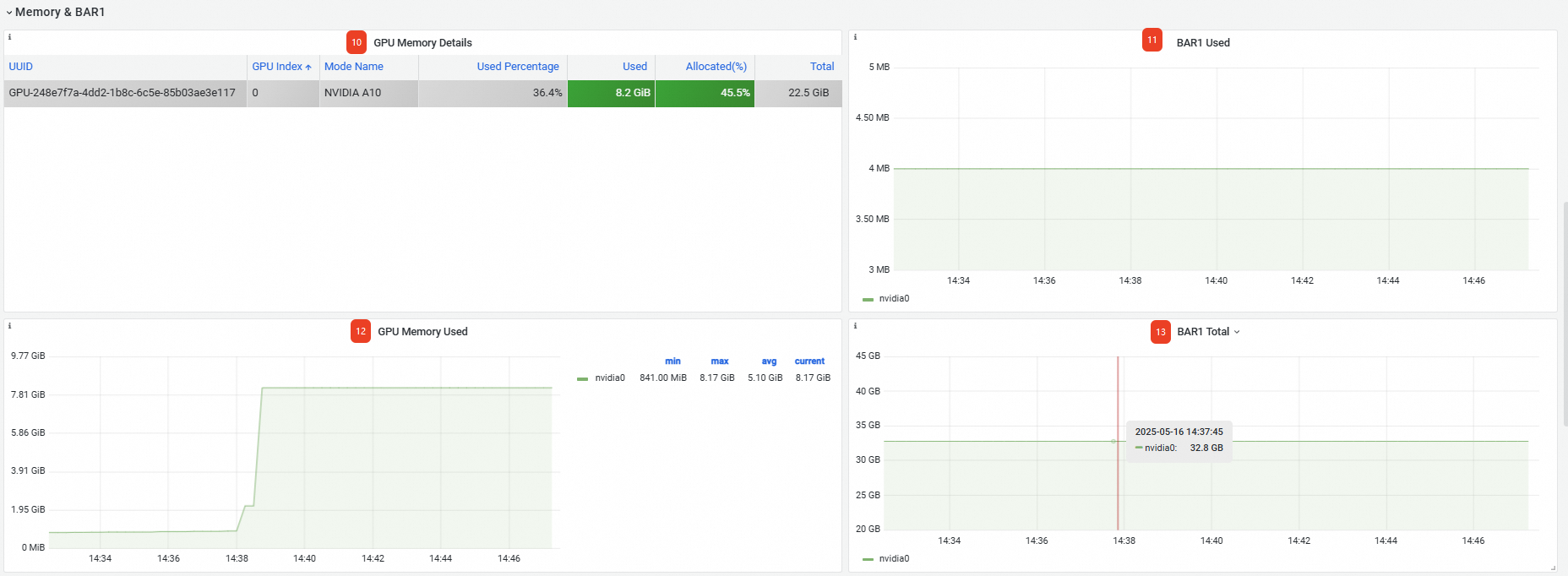
Memory&BAR1 |
⑩ |
GPU Memory Details |
GPU記憶體資訊,包括GPU卡的UUID、索引號、卡型號等。 |
|
⑪ |
BAR1 Used |
已使用BAR1為4 MB。 |
|
|
⑫ |
Memory Used |
GPU卡已使用的顯存大小為8.17 GB。 |
|
|
⑬ |
BAR1 Total |
總BAR1為32.8 GB。 |
|
|
GPU Process |
⑭ |
GPU Process Details |
GPU線程詳細資料,包括Process所屬的Pod命名空間、Process所屬的Pod名稱等。 |
也可在下方查看更多進階指標,詳情請參見叢集GPU監控-節點維度。
進階指標包括 GPU Process(2 panels)、Profiling(12 panels)、Temperature & Energy(4 panels)、Clock(6 panels)、Retired Pages(2 panels)和 Violation(6 panels)共六個 Panel 組,預設處於摺疊狀態,可單擊展開查看詳情。
查看叢集GPU監控-應用Pod維度
在Prometheus監控大盤列表頁面,單擊GPU 監控頁簽,然後單擊叢集GPU監控-應用Pod維度頁簽。Pod維度監控大盤的資訊如下:該面板以表格形式展示各 Pod 的 GPU 指標,除下文說明的欄位外,還包含 Pod Source、Allocated Mode(exclusive 或 share)、SM Utilization、GPU Memory Copy Utilization、Decode Utilization 和 Encode Utilization 等列。
|
序號 |
Panel名稱 |
說明 |
|
① |
GPU Pod Details |
叢集申請GPU資源的Pod資訊,包括Pod所在的命名空間、Pod名稱、節點名稱、已使用的顯存等。 說明
|
也可在下方查看更多進階指標,詳情請參見叢集GPU監控-應用Pod維度。
進階指標面板分組包括:Pod Metrics(GPU Device)(6 panels)、Pods Metrics(Host Resource)(8 panels)、GPU Utilization(Associated with Pod)(4 panels)、GPU Memory & BAR1(Associated with Pod)(5 panels)、GPU Profiling(Associated with Pod)(12 panels)、GPU Temperature & Energy(Associated with Pod)(4 panels)和 GPU Clock(Associated with Pod)(6 panels)。