Tablestore では、Tablestore インスタンスを DataWorks に接続できます。これにより、DataWorks 上でインスタンスのデータを管理および利用できるようになります。インスタンスを DataWorks に接続するには、DataWorks 内に Tablestore データソースを追加する必要があります。Tablestore データソースを追加後、DataWorks でデータ同期タスクを設定して Tablestore データの同期・移行を実行したり、SQL ステートメントを実行して Tablestore データをクエリしたりできます。本トピックでは、Tablestore データソースの追加方法と SQL ステートメントによる Tablestore データのクエリ方法について説明します。
背景情報
DataWorks は、MaxCompute、Hologres、E-MapReduce (EMR)、AnalyticDB、Cloudera Data Platform (CDP) などのビッグデータコンピュートエンジンに基づき、データウェアハウス、データレイク、データレイクハウスのソリューションを提供するエンドツーエンドのビッグデータ開発・ガバナンスプラットフォームです。詳細については、「DataWorks とは」をご参照ください。
利用シーン
Tablestore インスタンスを DataWorks に接続すると、DataWorks 上で効率的にデータを処理・分析し、さまざまなビッグデータシナリオで活用できます。以下に代表的な利用シーンを示します。
大規模データストレージと分析
Tablestore は高スループットを提供し、大量のデータを格納できます。DataWorks はビッグデータ分析をサポートしています。接続後、DataWorks 上で SQL ステートメント、MapReduce タスク、またはカスタムコードを使用して Tablestore データをクエリおよび処理できます。たとえば、ログやユーザー動作の分析が可能です。
リアルタイムデータ処理
DataWorks は Flink タスクなどのリアルタイムコンピューティングタスクをサポートしています。接続後、リアルタイムモニタリング、リアルタイムレポート、リアルタイムレコメンデーションなどのシナリオで、Tablestore データをリアルタイムに消費・処理・分析できます。
オフラインデータ処理およびバッチ処理
DataWorks はタスクスケジューリング機能を提供しています。接続後、Tablestore データを含むバッチ処理タスクがスケジュール通りにトリガーされ実行されます。これらのタスクは、生データを分析に必要な形式に変換する抽出・変換・ロード (ETL) タスクや、データを集計・分析する定期タスクなどです。
データレイクおよびデータウェアハウスの構築
Tablestore は、生データまたは半構造化データを格納するデータレイクのストレージレイヤーとして使用できます。接続後、DataWorks を使用してデータパイプラインを構築し、Tablestore データを処理・クリーンアップしたうえで、MaxCompute または他のデータウェアハウスにインポートして、さらに高度な分析およびマイニングを実施できます。
BI レポートおよびデータビジュアライゼーション (大画面表示)
DataWorks は Quick BI などのビジネスインテリジェンス (BI) レポートツールと統合できます。接続後、DataWorks が直接 Tablestore からデータを読み取り、さまざまな BI レポートおよびダッシュボードを生成し、企業の意思決定を支援できます。
機械学習および AI プロジェクト
トレーニング、モデル、特徴量のデータを Tablestore に格納できます。接続後、DataWorks を使用して Platform for AI (PAI) で作成されたタスクを呼び出し、Tablestore データに基づいてモデルトレーニングおよび予測を実行できます。これにより、データ準備からモデルデプロイまでの一貫した開発が可能になります。
操作手順
Tablestore インスタンスを DataWorks に接続後、SQL クエリ機能を使用して Tablestore データをクエリおよび分析できます。
Tablestore インスタンスを DataWorks に接続できるのは、Wide Column モデルまたは TimeSeries モデルを使用している場合のみです。
前提条件
AccessKey ペアが作成済みの Resource Access Management (RAM) ユーザーが存在すること。また、当該 RAM ユーザーには Tablestore を管理する権限を付与するための AliyunOTSFullAccess ポリシーと、DataWorks を管理する権限を付与するための AliyunDataWorksFullAccess ポリシーがアタッチされていること。詳細については、「RAM ユーザーの AccessKey ペアを使用して Tablestore にアクセス」をご参照ください。
使用する Tablestore データモデルに基づき、特定のリソースが作成済みであること。
Wide Column モデルを使用する場合は、データテーブルが作成済みで、データが書き込まれていること。詳細については、「データテーブルの操作」および「データの書き込み」をご参照ください。
TimeSeries モデルを使用する場合は、時系列テーブルが作成済みで、データが書き込まれていること。詳細については、「時系列テーブルの操作」および「時系列データの書き込み」をご参照ください。
次の操作は、DataWorks コンソールで実行されます。
DataWorks が有効化済みで、ワークスペースが作成済みであること。詳細については、「DataWorks の有効化」および「ワークスペースの作成」をご参照ください。
DataWorks のデータ分析サービスで Tablestore データソースをクエリする権限を取得済みであること。詳細については、「データクエリおよび分析コントロール機能の使用」をご参照ください。
使用するアカウントがワークスペースのメンバーとして追加済みで、データアナリスト、モデル開発者、開発、O&M、ワークスペース管理者、またはプロジェクトオーナーのいずれかのロールが割り当てられていること。詳細については、「ワークスペースメンバーの追加およびロールの割り当て」をご参照ください。
ステップ 1:DataWorks に Tablestore データソースを追加
Tablestore データベースをデータソースとして追加するには、以下の手順を実行します。
データ統合ページに移動します。
DataWorks コンソールにログインします。ターゲットリージョンに切り替えた後、左側のナビゲーションウィンドウで をクリックします。ドロップダウンリストから対象のワークスペースを選択し、データ統合に移動 をクリックします。
左側のナビゲーションウィンドウで データソース をクリックします。
データソース ページで、データソースの追加 をクリックします。
データソースの追加 ダイアログボックスで、データソースタイプとして Tablestore を選択します。
Tablestore データソースの追加 ダイアログボックスで、以下の表に従ってデータソースパラメーターを設定します。
パラメーター
説明
Data Source Name
データソースの名前。英字、数字、アンダースコア (_) のみ使用でき、先頭は英字である必要があります。
Data Source Description
データソースの説明。最大 80 文字まで入力できます。
Region
Tablestore インスタンスが配置されているリージョンを選択します。
Tablestore Instance Name
Tablestore インスタンスの名前。
Endpoint
Tablestore インスタンスのエンドポイント。VPC アドレスの使用を推奨します。
AccessKey ID
Alibaba Cloud アカウントまたは Resource Access Management (RAM) ユーザーの AccessKey ID および AccessKey Secret。
AccessKey Secret
リソースグループの接続性をテストします。データソース作成時にこのテストを実施し、同期タスクで使用するリソースグループがデータソースに接続できることを確認してください。接続できない場合、データ同期タスクは正常に実行できません。
接続設定 セクションで、対象のリソースグループの 接続ステータス 列にある ネットワーク接続性のテスト をクリックします。
接続性テストが成功すると、接続ステータス が Connected に変化します。完了 をクリックすると、新しいデータソースがデータソース一覧に表示されます。
説明接続性テストが失敗し、ステータスが Failed になる場合は、接続診断ツールを使用して問題をトラブルシューティングしてください。リソースグループが依然としてデータソースに接続できない場合は、 するか、チケットを送信 してください。
ステップ 2:DataWorks の SQL クエリ機能を使用して Tablestore データをクエリ
Tablestore は Wide Column モデルや TimeSeries モデルなどのデータストレージモデルをサポートしています。SQL クエリ操作は、ご利用のインスタンスのモデルによって異なります。インスタンスのモデルに応じて SQL クエリ操作を実行してください。
DataWorks のデータ分析サービスの SQL クエリ機能は、Tablestore の SQL クエリ機能と同じ機能を提供します。詳細については、「SQL 機能」をご参照ください。
Wide Column モデルのインスタンスでデータをクエリするための SQL ステートメントの実行
-
データ分析ページに移動します。
DataWorks コンソールにプロジェクト管理者としてログインします。
-
左側のナビゲーションウィンドウで、Data Analysis > SQL Query を選択します。
-
SQL Query ページで、ターゲットリージョンおよびワークスペースを選択し、SQL クエリに移動 をクリックします。
-
SQL クエリファイルを作成します。
-
My Files ディレクトリの横にあるプラスアイコンにカーソルを合わせ、Create File を選択します。
-
Create File ダイアログボックスで、ファイル名を入力し、OK をクリックします。
左側のナビゲーションウィンドウで、作成したファイルを確認できます。
-
-
作成したファイルの SQL エディターを開き、クエリ対象のデータソース情報を設定します。
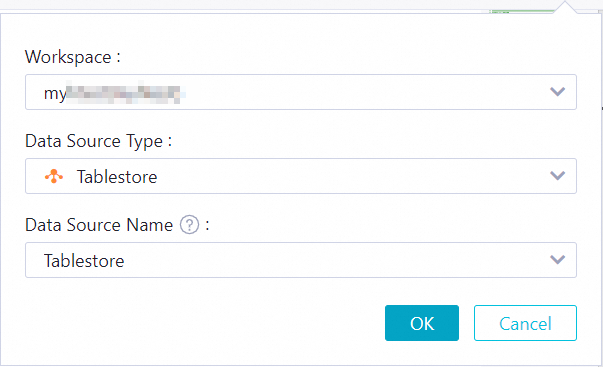
SQL クエリページの左側ナビゲーションウィンドウで、[マイファイル] をクリックし、作成したファイルをクリックします。表示される SQL エディターの右上隅にある
 アイコンをクリックします。
アイコンをクリックします。-
表示されるダイアログボックスで、以下の表に従ってパラメーターを設定します。
パラメーター
説明
Workspace
クエリ対象のワークスペース。ビジネス要件に応じてワークスペースを選択します。
Data Source Type
クエリ対象のデータソースタイプ。Tablestore を選択します。
Data Source Name
クエリ対象のデータソース名。追加済みのデータソースを選択します。クエリ対象のテーブルは、データソースで指定されたインスタンスに属します。
重要[Data Source Name] ドロップダウンリストには、使用権限のあるデータソースのみが表示されます。他のデータソースを使用する場合は、セキュリティセンターで管理者に必要な権限の付与を依頼してください。詳細については、「データクエリおよび分析コントロール機能の使用」をご参照ください。
-
OK をクリックします。
-
テーブルのマッピングテーブルを作成し、SQL ステートメントを実行します。
すでにテーブルのマッピングテーブルが作成済みの場合は、このステップをスキップできます。
重要テーブルのマッピングテーブルを作成する際は、マッピングテーブルのフィールドのデータの型が、テーブルのフィールドのデータの型と一致していることを確認してください。詳細については、「SQL における型マッピング」をご参照ください。
ファイルの SQL エディターで、マッピングテーブルを作成する SQL ステートメントを記述します。詳細については、「テーブルのマッピングテーブルの作成」をご参照ください。
テーブルのマッピングテーブルを作成する際は、マッピングテーブルの名前およびプライマリキー列が、元のテーブルと同一であることを確認してください。
説明データテーブルに検索インデックスが作成されている場合、その検索インデックス用のマッピングテーブルを作成できます。これにより、検索インデックスに基づいて SQL ステートメントを実行してデータをクエリできます。詳細については、「検索インデックス用のマッピングテーブルを作成する」をご参照ください。
以下のサンプル SQL ステートメントは、test_table という名前のテーブルのマッピングテーブルを作成する例です。
CREATE TABLE `test_table` ( `pk` VARCHAR(1024), `long_value` BIGINT(20), `double_value` DOUBLE, `string_value` MEDIUMTEXT, `bool_value` BOOL, PRIMARY KEY(`pk`) );-
SQL ステートメントを選択し、Run をクリックします。
実行結果は、SQL エディターの [Result] タブに表示されます。
-
テーブル内のデータをクエリする SQL ステートメントを実行します。
ファイルの SQL エディターで、データをクエリする SELECT ステートメントを記述します。詳細については、「データのクエリ」をご参照ください。
以下のサンプル SQL ステートメントは、test_table テーブルから最大 20 行のデータを取得する例です。
SELECT `pk`, `long_value`, `double_value`, `string_value`, `bool_value` FROM test_table LIMIT 20;-
SQL ステートメントを選択し、Run をクリックします。
実行結果は、SQL エディターの [Result] タブに表示されます。
TimeSeries モデルのインスタンスでデータをクエリするための SQL ステートメントの実行
-
データ分析ページに移動します。
DataWorks コンソールにプロジェクト管理者としてログインします。
-
左側のナビゲーションウィンドウで、Data Analysis > SQL Query を選択します。
-
SQL Query ページで、ターゲットリージョンおよびワークスペースを選択し、SQL クエリに移動 をクリックします。
-
SQL クエリファイルを作成します。
-
My Files ディレクトリの横にあるプラスアイコンにカーソルを合わせ、Create File を選択します。
-
Create File ダイアログボックスで、ファイル名を入力し、OK をクリックします。
左側のナビゲーションウィンドウで、作成したファイルを確認できます。
-
-
作成したファイルの SQL エディターを開き、クエリ対象のデータソース情報を設定します。
SQL クエリページの左側ナビゲーションウィンドウで、[マイファイル] をクリックし、作成したファイルをクリックします。表示される SQL エディターの右上隅にある
アイコンをクリックします。-
表示されるダイアログボックスで、以下の表に従ってパラメーターを設定します。
パラメーター
説明
Workspace
クエリ対象のワークスペース。ビジネス要件に応じてワークスペースを選択します。
Data Source Type
クエリ対象のデータソースタイプ。Tablestore を選択します。
Data Source Name
クエリ対象のデータソース名。追加済みのデータソースを選択します。クエリ対象のテーブルは、データソースで指定されたインスタンスに属します。
重要[Data Source Name] ドロップダウンリストには、使用権限のあるデータソースのみが表示されます。他のデータソースを使用する場合は、セキュリティセンターで管理者に必要な権限の付与を依頼してください。詳細については、「データクエリおよび分析コントロール機能の使用」をご参照ください。
-
OK をクリックします。
-
テーブルのマッピングテーブルを作成し、SQL ステートメントを実行します。
時系列テーブルを作成後、システムが自動的に単一値モデルのマッピングテーブルおよび時系列メタデータのマッピングテーブルを作成します。単一値モデルのマッピングテーブル名は、時系列テーブル名と同じです。時系列メタデータのマッピングテーブル名は、時系列テーブル名にサフィックス
::metaを付けたものになります。時系列テーブルの時系列データをマルチ値モデルのマッピングテーブルを使用してクエリする場合は、マルチ値モデルのマッピングテーブルを作成する必要があります。マルチ値モデルのマッピングテーブルを使用しない場合は、作成不要です。
重要テーブルのマッピングテーブルを作成する際は、マッピングテーブルのフィールドのデータの型が、テーブルのフィールドのデータの型と一致していることを確認してください。詳細については、「SQL における型マッピング」をご参照ください。時系列テーブルのマッピングテーブルのフィールドのデータの型に関する詳細については、「SQL における時系列テーブルのマッピングテーブル」をご参照ください。
ファイルの SQL エディターで、マッピングテーブルを作成する SQL ステートメントを記述します。詳細については、「SQL における時系列テーブルのマッピングテーブル」をご参照ください。
以下のサンプル SQL ステートメントは、時系列テーブルのマルチ値モデルのマッピングテーブル
timeseries_table::muti_modelを作成する例です。マッピングテーブルのメトリックは cpu、memory、disktop です。サンプル SQL ステートメント:CREATE TABLE `timeseries_table::muti_model` ( `_m_name` VARCHAR(1024), `_data_source` VARCHAR(1024), `_tags` VARCHAR(1024), `_time` BIGINT(20), `cpu` DOUBLE(10), `memory` DOUBLE(10), `disktop` DOUBLE(10), PRIMARY KEY(`_m_name`,`_data_source`,`_tags`,`_time`) );-
SQL ステートメントを選択し、Run をクリックします。
実行結果は、SQL エディターの [Result] タブに表示されます。
-
テーブル内のデータをクエリする SQL ステートメントを実行します。
ファイルの SQL エディターで、データをクエリする SELECT ステートメントを記述します。詳細については、「SQL の使用例」をご参照ください。
単一値モデルのマッピングテーブルを使用したデータのクエリ
以下のサンプル SQL ステートメントは、時系列データテーブル内でメトリクスタイプが basic_metric のデータをクエリする例です。
SELECT * FROM timeseries_table WHERE _m_name = "basic_metric" LIMIT 10;時系列メタデータのマッピングテーブルを使用したデータのクエリ
以下のサンプル SQL ステートメントは、時系列メタデータのマッピングテーブル内でメトリック名が basic_metric の時系列をクエリする例です。
SELECT * FROM `timeseries_table::meta` WHERE _m_name = "basic_metric" LIMIT 100;マルチ値モデルのマッピングテーブルを使用したデータのクエリ
以下のサンプル SQL ステートメントは、マルチ値モデルのマッピングテーブルを使用して、cpu 値が 20.0 を超える時系列のメトリック情報をクエリする例です。
SELECT cpu,memory,disktop FROM `timeseries_table::muti_model` WHERE cpu > 20.0 LIMIT 10;
-
SQL ステートメントを選択し、Run をクリックします。
実行結果は、SQL エディターの [Result] タブに表示されます。
課金ルール
Tablestore 料金
DataWorks を使用して SQL で Tablestore にアクセスしても、SQL ステートメント自体に対して追加料金は発生しません。ただし、クエリ実行中に実施されるテーブルスキャンやインデックスルックアップなどの基盤となる操作に対して課金されます。詳細については、「SQL クエリのメータリングおよび課金」をご参照ください。
その他のリソース料金
DataWorks ツールを使用する際は、特定の機能およびリソースに対して料金が発生します。詳細については、「購入ガイド」をご参照ください。
参考資料
Tablestore コンソール、Tablestore CLI、Tablestore SDK、Java Database Connectivity (JDBC)、または Go 向け Tablestore ドライバーを使用して、SQL ステートメントでデータをクエリすることもできます。詳細については、「SQL クエリの使用方法」をご参照ください。
Tablestore インスタンスを Data Management (DMS) に接続し、その後 SQL ステートメントを実行して Tablestore データをクエリおよび分析することもできます。詳細については、「Tablestore を DMS に接続」をご参照ください。
MaxCompute、Spark、Hive、HadoopMR、Function Compute、Realtime Compute for Apache Flink、PrestoDB などのコンピュートエンジンを使用して、テーブル内のデータを計算および分析できます。詳細については、「概要」をご参照ください。
SQL ステートメントを実行してデータクエリおよび計算を高速化したい場合は、セカンダリインデックスまたは多次元インデックスを作成できます。詳細については、「インデックス選択ポリシー」および「計算プッシュダウン」をご参照ください。
DataWorks のデータ統合機能を使用して、MySQL、Oracle、Kafka、HBase、MaxCompute、PolarDB-X 2.0、Tablestore などのデータソースから Tablestore へデータを移行できます。詳細については、「データ統合」をご参照ください。