TimeSeries モデルは、時系列データの特性に基づいて設計されています。このモデルは、IoT デバイスのモニタリングなどのシナリオに適しており、デバイスによって収集されたデータやマシンのモニタリングデータを保存するために使用できます。 TimeSeries モデルは、時系列メタデータの自動インデックス作成と、複合条件に基づく時系列取得をサポートしています。 TimeSeries モデルは、時系列テーブルを使用して時系列データを保存します。これにより、アプリケーションはペタバイト単位のデータを同時に書き込みおよび読み取りでき、ストレージ コストを削減できます。 SQL 文を実行して、時系列データのクエリと分析を行うことができます。
概要
TimeSeries モデルは、時系列データの特性に基づいて設計されています。このモデルは、IoT デバイスのモニタリングなどのシナリオに適しており、デバイスによって収集されたデータやマシンのモニタリングデータを保存するために使用できます。
Tablestore の TimeSeries モデルでは、2 次元時系列テーブルを使用して時系列データを保存します。各行は、時系列の特定の時点におけるデータを表します。時系列識別子とタイムスタンプは、行のプライマリキー列であり、タイムスタンプ以下の時系列のデータポイントは、行のデータ列です。 1 つの行に複数のデータ列を含めることができます。プライマリキー列とデータ列のスキーマを事前に定義する必要はありません。時系列テーブルにデータを書き込むときに、特定のデータ列の名前を指定するだけで済みます。
時系列テーブルには、異なるメトリック タイプの時系列データを保存できます。次の図では、時系列テーブルに温度と湿度の 2 つのメトリック タイプのデータが保存されています。
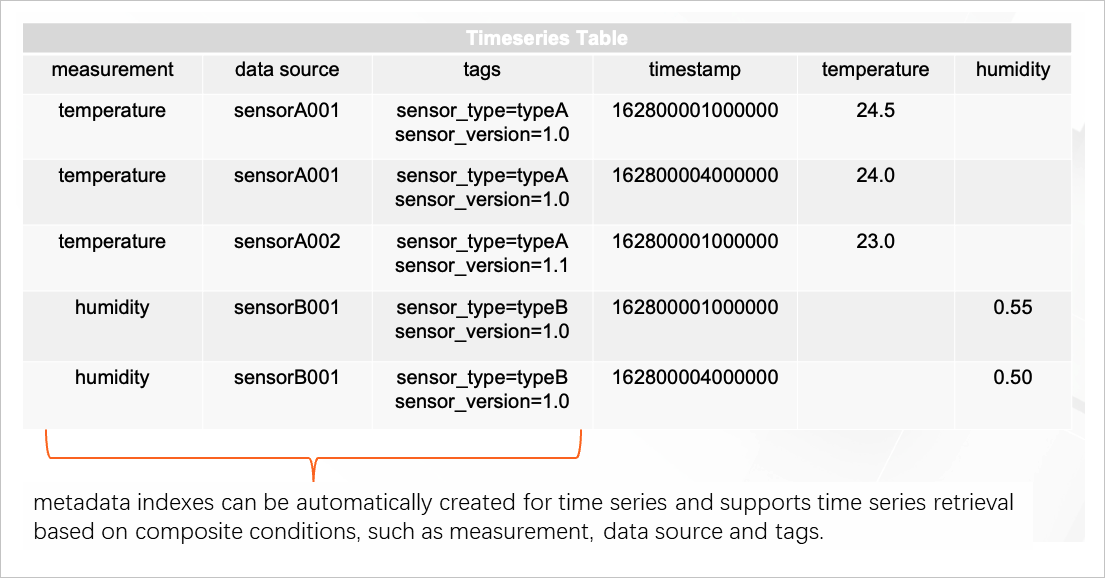
図では、時系列識別子は、測定値、データソース、およびタグで構成されています。 API 操作を呼び出して、時系列のメタデータのプロパティを更新できます。プロパティを使用して、時系列を取得できます。
時系列テーブルにデータが書き込まれると、システムは時系列のメタデータを自動的に抽出し、メタデータ インデックスを自動的に作成します。メトリック名、データソース、およびタグの組み合わせに基づいて、時系列を取得できます。
TimeSeries モデルの利点は次のとおりです。
時系列データの統一された共通モデリング メソッドを提供するため、テーブル スキーマを事前に定義する必要がありません。
時系列のメタデータ インデックスを自動的に作成でき、複合条件に基づく時系列取得をサポートします。
SQL を使用したクエリと集約をサポートします。
サービス機能の自動スケールアウト、高並列書き込みとクエリ、ペタバイト単位のデータの低コスト ストレージをサポートします。
用語
用語 | 説明 |
時系列データ | 時系列データは複数の時系列で構成されます。各時系列は、時系列に並べられたデータポイントのセットです。時系列を識別するにはメタデータが必要です。したがって、時系列データはメタデータとデータで構成されます。
|
時系列メタデータ | 時系列メタデータには、時系列の識別子とプロパティが含まれています。識別子は、時系列を一意に識別するために使用されます。プロパティは変更可能で、時系列を取得するために使用できます。 |
時系列識別子 | 時系列識別子は、時系列を一意に識別するために使用されます。 Tablestore の TimeSeries モデルでは、時系列識別子は、メトリック名、データソース、およびタグの 3 つの部分で構成されます。 |
メトリック名 | 時系列データの物理量またはメトリックの名前。たとえば、CPU 使用率またはネットワーク使用率を示す cpu または net などです。 |
データソース | 時系列のデータソースの識別子。このパラメータは空のままにすることができます。 |
タグ | 時系列のタグ。文字列型のキーと値のペアを複数指定できます。 |
プロパティ | プロパティは時系列メタデータの一部であり、時系列の変更可能なプロパティ情報を記録するために使用できます。ただし、プロパティを時系列の識別子として使用することはできず、時系列を一意に識別するために使用することもできません。時系列のプロパティは、文字列型のキーと値のペアが複数あり、形式はタグに似ています。時系列のプロパティを指定または更新して、プロパティを使用して時系列を取得できます。 |
時系列データ | 時系列のデータポイントは、データが生成された時刻と対応するデータ値で構成されます。時系列の各時点で 1 つの値のみが生成される場合は、単一値モデルが使用されます。時系列の各時点で複数の値が生成される場合は、複数値モデルが使用されます。 Tablestore の TimeSeries モデルでは、複数値モデルを使用します。 1 つの時点で複数のデータ値を指定できます。各値は、時系列テーブルの列(列名と列値を含む)に対応します。列値は、ブール値、整数、浮動小数点数、文字列、バイナリなどのデータ型をサポートします。 |
機能
時系列テーブルの作成と管理
Tablestore コンソール、SDK、または CLI を使用して、インスタンス内のすべての時系列テーブルのクエリ、時系列テーブルの作成、時系列テーブルの構成のクエリ、時系列テーブルの構成の更新、時系列テーブルの削除を行うことができます。
時系列テーブルを作成する場合、または時系列テーブルの構成を更新する場合は、時系列テーブルのデータの Time To Live(TTL)を指定できます。 TTL 値を指定すると、システムは現在の時刻と時系列データが書き込まれたときのタイムスタンプの差を自動的にチェックします。差が TTL 値を超えると、システムは期限切れのデータを自動的に削除します。
時系列データの読み取りと書き込み
Tablestore コンソール、SDK、または CLI を使用して、複数の時系列データ行を同時に時系列テーブルに書き込むことができます。データを時系列テーブルに書き込んだ後、時系列識別子を指定して、指定した時間範囲内の時系列のデータをクエリできます。
時系列の取得
Tablestore コンソール、SDK、または CLI を使用して、時系列テーブルの時系列を取得できます。複数の条件で構成される複合条件を使用して、時系列を取得できます。たとえば、メトリック名が cpu で、タグに名前が region、値が hangzhou のタグが含まれ、プロパティに名前が status、値が online のプロパティが含まれるすべての時系列を取得できます。時系列が取得されたら、API 操作を呼び出して、時系列のデータをさらにクエリできます。
SQL クエリと分析の実装
時系列テーブルは、SQL を使用したクエリをサポートしています。 SQL では、メタデータ条件を指定して時系列をフィルタリングし、異なるディメンションの集約操作に基づいてデータを集約できます。たとえば、一連のデバイスから収集されたサンプルデータの平均値をクエリし、秒レベルのデータ分レベルのデータに集約できます。
また、SQL で時系列のメタデータのみをクエリすることもできます。このようにして、SQL を使用して時系列のメタデータを管理できます。
制限
詳細については、「TimeSeries モデルの制限」をご参照ください。
使用上の注意
TimeSeries モデルは、中国(杭州)、中国(上海)、中国(北京)、中国(張家口)、中国(ウランチャブ)、中国(深セン)、中国(成都)、中国(香港)、日本(東京)、マレーシア(クアラルンプール)、ドイツ(フランクフルト)、インドネシア(ジャカルタ)、英国(ロンドン)、米国(シリコンバレー)、米国(バージニア)、SAU (リヤド - パートナーリージョン)、シンガポールの各リージョンでサポートされています。
API 操作
カテゴリ | 操作 | 説明 |
時系列テーブルに対する API 操作 | 時系列テーブルを作成します。 | |
インスタンス内の時系列テーブルの名前をクエリします。 | ||
時系列テーブルに関する情報をクエリします。 | ||
時系列テーブルの構成を更新します。 | ||
時系列テーブルを削除します。 | ||
時系列に対する API 操作 | 時系列データを時系列テーブルに書き込みます。 | |
時系列のデータをクエリします。 | ||
時系列メタデータを取得します。 | ||
時系列メタデータを更新します。 | ||
時系列のメタデータを削除します。 | ||
時系列分析ストアに対する API 操作 | 時系列分析ストアを作成します。 | |
時系列分析ストアの構成情報を更新します。 | ||
時系列分析ストアの情報をクエリします。 | ||
時系列分析ストアを削除します。 | ||
Lastpoint インデックスに対する API 操作 | Lastpoint インデックスを作成します。 | |
Lastpoint インデックスを削除します。 |
手順
ステップ | 操作 | 説明 |
1 | RAM ユーザーを作成したら、システム ポリシーまたはカスタム ポリシーを RAM ユーザーにアタッチすることで、Tablestore リソースにアクセスするための最小限の権限を RAM ユーザーに付与します。 Alibaba Cloud アカウントまたは Tablestore リソースにアクセスするために必要な権限が付与されている RAM ユーザーを使用する場合は、このステップをスキップしてください。 重要 デフォルトでは、Alibaba Cloud アカウントには、アカウント内のすべてのクラウド リソースに対して操作を実行する権限があります。セキュリティ上の理由から、RAM ユーザーを作成し、RAM ユーザーに権限を付与することをお勧めします。このようにして、異なる RAM ユーザーが異なるリソースにアクセスする権限を持つことになります。 | |
2 | Tablestore を使用する前に、Tablestore をアクティブ化する必要があります。 Tablestore のアクティブ化は 1 回だけ行う必要があります。 Tablestore のアクティブ化は無料です。 Tablestore がアクティブ化されている場合は、このステップをスキップしてください。 | |
3 | 重要
インスタンス内に作成するテーブルのモデルとインスタンス タイプに基づいて、選択したリージョンに Tablestore インスタンスを作成します。 既存の Tablestore インスタンスがビジネス要件を満たしている場合は、このステップをスキップしてください。 | |
4 | 時系列データを保存する時系列テーブルを作成します。時系列テーブルを作成するときに、既存のデータをクリアするかどうか基づいて、時系列テーブルの TTL を構成できます。 | |
5 | 時系列データをバッチで時系列に書き込みます。時系列データは、メタデータとデータで構成されます。時系列データを書き込む前にメタデータを作成しない場合、システムは書き込まれたデータからメタデータを自動的に抽出します。 説明 kafka-connect-tablestore パッケージを使用して、Apache Kafka から時系列テーブルにデータを同期することもできます。詳細については、「時系列テーブルへのデータ同期」をご参照ください。 | |
6 | 重要 データをクエリする時系列の情報(メトリック名、データソースなど)が不明な場合は、複数の条件を指定して時系列を取得できます。詳細については、「時系列操作」をご参照ください。 データをクエリする時系列が取得されたら、時系列内で指定された条件(時間範囲など)を満たす時系列データをクエリできます。 | |
7 | SQL で時系列テーブル用に 3 つのタイプのマッピング テーブルを作成して、データをクエリできます。
|
TimeSeries モデルを使用する
Tablestore コンソール、SDK、または CLI を使用して、TimeSeries モデルを簡単に試すことができます。
請求ルール
TimeSeries モデルの課金項目には、時系列データと時系列メタデータの読み取りスループット、書き込みスループット、ストレージ使用量、およびインターネット経由のアウトバウンド トラフィックが含まれます。詳細については、「TimeSeries モデルの課金項目」をご参照ください。
FAQ
参考資料
時系列テーブルの既存の時系列データを削除するには、時系列テーブルの TTL を構成します。詳細については、「時系列データの TTL」をご参照ください。
Tablestore の時系列データを費用対効果の高い方法でバックアップしたり、時系列データをファイルとしてローカル デバイスにエクスポートしたりするには、DataWorks の Data Integration 機能を使用して、Tablestore から Object Storage Service (OSS) に時系列データを同期して保存またはダウンロードできます。詳細については、「Tablestore から OSS にデータを同期する」をご参照ください。
時系列データを視覚化するには、Tablestore を Grafana に接続します。詳細については、「Tablestore を Grafana に接続する」をご参照ください。
Realtime Compute for Apache Flink を使用してデータの計算と分析を行う場合は、Tablestore 時系列テーブルを使用して結果を保存できます。詳細については、「チュートリアル(TimeSeries モデル)」をご参照ください。
時系列データを低コストで保存し、時系列データを迅速にクエリおよび分析する場合は、時系列分析ストアを使用できます。詳細については、「時系列分析ストア」をご参照ください。
時系列テーブルの時系列の最新時点のデータをクエリする場合は、時系列テーブルの Lastpoint インデックスを作成できます。詳細については、「Lastpoint インデックス」をご参照ください。