DLC は、クラウドネイティブでワンストップのディープ ラーニング学習プラットフォームです。開発者および企業向けに、柔軟性・安定性・使いやすさ・パフォーマンス専有型を兼ね備えた機械学習学習環境を提供します。本トピックでは、DLC を使用して MPIJob 型の分散学習タスクを mpirun または DeepSpeed のいずれかの方法で送信する手順について説明します。
前提条件
DLC の従量課金を有効化し、デフォルトのワークスペースを作成済みである必要があります。詳細については、「PAI の有効化とデフォルトワークスペースの作成」をご参照ください。
Lingjun Intelligent Computing リソースを購入し、リソースクォータを作成済みである必要があります。詳細については、「リソースクォータの作成」をご参照ください。
制限事項
本タスクは、中国 (ウランチャブ) リージョンでのみ、Lingjun Intelligent Computing リソースを使用して送信できます。
MPIJob トレーニング タスクの送信
分散学習タスクを送信するには、以下の手順に従ってください。
ステップ 1:コードソースの準備
公式 DeepSpeed のサンプルリポジトリを使用して、コードビルドを作成します。以下に示す主要なパラメーターを設定してください。その他のパラメーターはすべてデフォルト構成のままとします。詳細については、「コード構成」をご参照ください。
名前:コードビルドのカスタム名を入力します。本例では deepspeed-examples を使用します。
Git URL:
https://github.com/microsoft/DeepSpeedExamples.git。
ステップ 2:分散学習タスクの送信
分散学習タスクは、以下のいずれかの方法で送信できます。
mpirun を使用する方法
Create Jobページへ移動します。
PAI コンソールにログインします。ページ上部でターゲットリージョンと対象ワークスペースを選択し、「Enter DLC」をクリックします。
Deep Learning Containers (DLC) ページで、Create Jobをクリックします。
Create Jobページで、下表に示す主要なパラメーターを設定します。その他のパラメーターの詳細については、「学習タスクの作成」をご参照ください。
パラメーター
説明
Environment Information
Image Configuration
本ソリューションではテスト用ランタイムイメージが提供されます。「Image URL」をクリックし、テキストボックスに
dsw-registry-vpc.<RegionID>.cr.aliyuncs.com/pai-common/deepspeed-training:23.08-gpu-py310-cu122-ubuntu22.04を入力して MPIJob 分散学習タスクを送信します。このアドレス内の<RegionID>はリージョン ID に置き換える必要があります(例:中国 (ウランチャブ) の場合、cn-wulanchabu)。リージョン ID の一覧については、「リージョンとゾーン」をご参照ください。Startup Command
分散タスクの各 Pod で実行されるスクリプトコマンドです。本ソリューションではデフォルトのシステム環境変数設定を使用します。また、起動コマンド内で環境変数を設定することで、デフォルト値をオーバーライドすることも可能です。詳細については、「システム環境変数」をご参照ください。
cd /root/code/DeepSpeedExamples/training/cifar/ # -np 2 -npernode 1 は、ノード数 2、ノードあたり GPU 数 1(合計 GPU 数 2)を意味します。 mpirun -np 2 -npernode 1 --allow-run-as-root -bind-to none -map-by slot -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib python /root/code/DeepSpeedExamples/training/cifar/cifar10_tutorial.pyCode Builds
Online configurationを選択し、既存のコード構成を選択します。Mount pathはデフォルト値のままとします。
Resource Information
Resource Type
Resource Quotaを選択します。
説明ワークスペースが Lingjun Intelligent Computing リソースおよび汎用コンピューティングリソースの両方をサポートしている場合にのみ、リソースタイプを選択できます。
Source
Resource Quotaを選択します。
Resource Quota
既存の Lingjun Intelligent Computing リソースクォータを選択します。
Framework
MPI を選択します。
Job Resource
Number of Nodesを 2 に設定します。
vCPUsを 4 に設定します。
GPUsを 1 に設定します。
Memory (GiB)を 8 に設定します。
Shared Memory (GiB)を 8 に設定します。
Driver Settings
上記のテストイメージを使用する場合、ドライバーのバージョンとして 535.54.03 を選択することを推奨します。
説明ドライバー設定は、現在 Lingjun Intelligent Computing リソースタイプでのみサポートされています。
OK をクリックします。
DeepSpeed (pdsh) を使用する方法
本方法を使用する場合、Startup Command を以下のように設定します。その他のパラメーターは、mpirun 方法と同様に設定します。
cd /root/code/DeepSpeedExamples/training/pipeline_parallelism
deepspeed --hostfile /etc/mpi/hostfile train.py --deepspeed_config=ds_config.json -p 2 --steps=200DeepSpeed タスクを実行するためにカスタムイメージを使用する場合は、イメージ内に必要な MPIJob および DeepSpeed ライブラリを事前にインストールしてください。あるいは、DockerHub から公式 DeepSpeed イメージをプルすることも可能です。このイメージには、必要な MPIJob および DeepSpeed ライブラリがすべて事前にインストールされています。
本ソリューションではデフォルトのシステム環境変数設定を使用します。また、起動コマンド内で環境変数を設定することで、デフォルト値をオーバーライドすることも可能です。詳細については、「システム環境変数」をご参照ください。
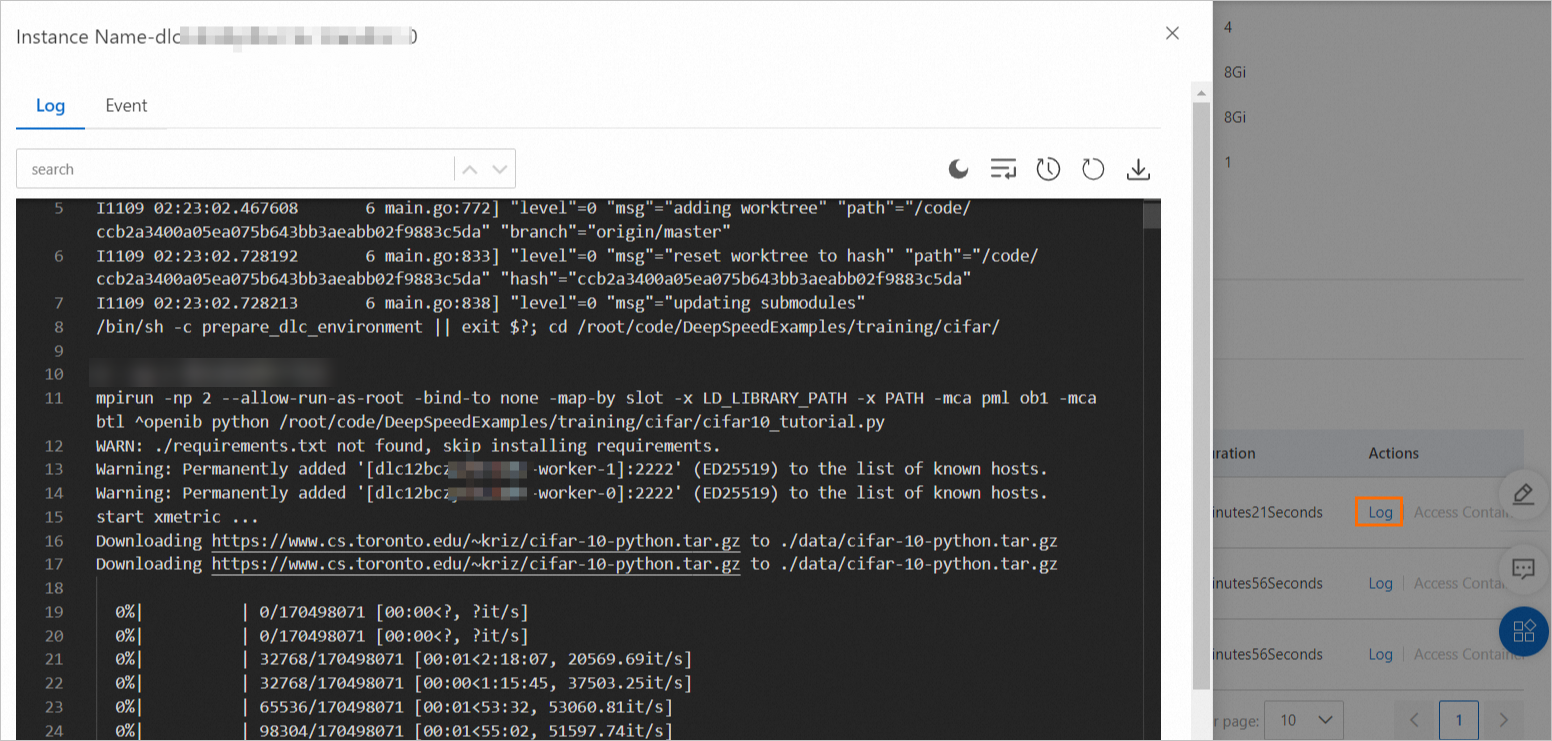
ステップ 3:タスクの詳細とログの確認
タスクの送信が正常に完了した後、Deep Learning Containers (DLC) ページへ移動し、タスク名をクリックします。
タスク詳細ページで、タスクの基本情報および実行ステータスを確認します。
タスク詳細ページの下部にある Instance セクションで、Launcher インスタンスの Log を Actions 列からクリックし、タスクの実行ステータスを確認します。
システム環境変数
MPI 分散タスクでは、Launcher と Worker の 2 つのロールがあります。これらのロールは学習中に通信を行う必要があります。DLC では、Launcher ロールに対してデフォルトの環境変数がすでに設定されています。また、特定のシナリオに応じて、起動コマンド内で環境変数を設定してデフォルト値をオーバーライドすることも可能です。
環境変数 | 説明 | デフォルト値 | 適用シナリオ |
OMPI_MCA_btl_tcp_if_include | Launcher と Worker 間の通信に使用するネットワークインターフェースコントローラー (NIC) を指定します。複数の NIC を指定する場合は、カンマで区切ります。 | eth0 | mpirun を使用してタスクを起動する場合に適用されます。 |
OMPI_MCA_orte_default_hostfile | mpirun コマンドで使用する hostfile を指定します。PAI-DLC では hostfile が自動生成されるため、手動での編集は不要です。 |
| |
OMPI_MCA_plm_rsh_agent | Launcher がリモートで Worker タスクを起動する方法を指定します。 |
| |
PDSH_RCMD_TYPE | PDSH のリモートコマンドタイプを指定します。 | ssh | DeepSpeed を使用してタスクを起動する場合に適用されます。 |