Elastic Algorithm Service (EAS) には、組み込みの EasyRec プロセッサが含まれており、EasyRec または TensorFlow でトレーニングされたレコメンデーションモデルを、特徴量エンジニアリングと統合されたスコアリングサービスとしてデプロイできます。特徴量エンジニアリングと TensorFlow モデルを共同で最適化することにより、EasyRec プロセッサは高性能なスコアリングサービスを提供します。このトピックでは、EasyRec モデルサービスのデプロイおよび呼び出し方法について説明します。
背景情報
EasyRec プロセッサは、PAI-EAS プロセッサ仕様に基づく推論サービスです (C または C++ を使用したカスタムプロセッサの開発)。次の 2 つのシナリオで使用されます。
特徴量生成 (FG) および EasyRec でトレーニングされたディープラーニングモデルの場合、EasyRec プロセッサはアイテム特徴量をメモリ内にキャッシュし、特徴量変換および推論パフォーマンスを最適化することで、スコアリングパフォーマンスを大幅に向上させます。また、FeatureStore を使用してオンラインおよびリアルタイム特徴量を管理することもできます。PAI-Rec レコメンデーションシステム開発プラットフォーム 上で構築されたカスタムレコメンデーションソリューションは、トレーニング、特徴量変換、推論最適化を合理化するコードを生成します。PAI-Rec DPI エンジン と組み合わせることで、迅速なモデルデプロイおよびサービス統合が可能になり、コストを削減し、開発効率を向上させます。
EasyRec プロセッサは、Feature Generator を使用せずに EasyRec または TensorFlow でトレーニングされたモデルにも対応しています。このプロセスは、EasyRec プロセッサをバイパスモードで実行すると呼ばれます。
次の図は、EasyRec プロセッサに基づくレコメンデーションエンジンのアーキテクチャを示しています。
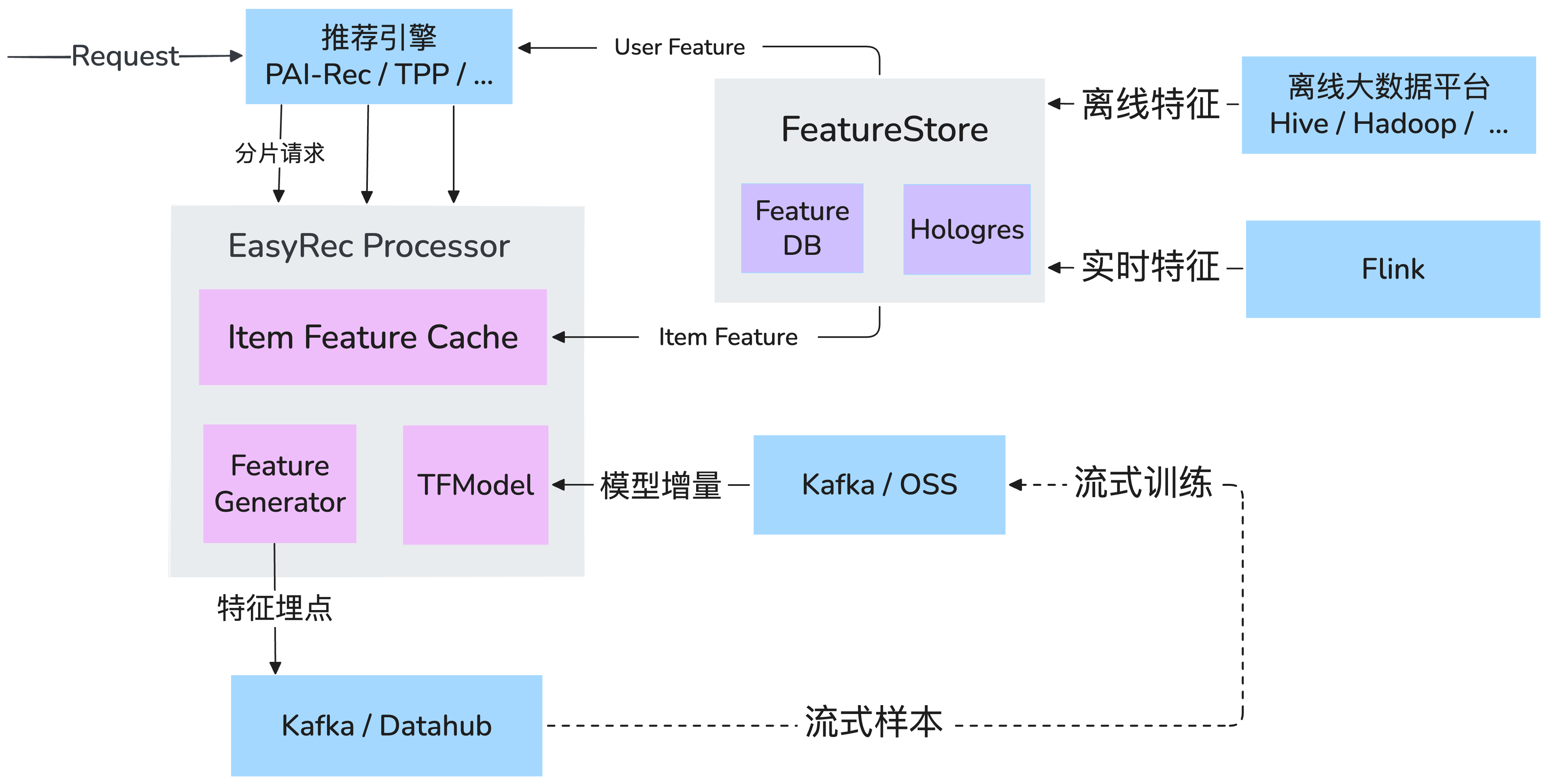
注:プロセッサは MaxCompute からのオフラインデータもサポートしています。
EasyRec プロセッサには、次のモジュールが含まれています。
アイテム特徴量キャッシュ:FeatureStore からの特徴量をメモリ内にキャッシュし、ネットワークオーバーヘッドおよび FeatureStore への負荷を軽減します。リアルタイム特徴量更新などの増分更新もサポートしています。
特徴量ジェネレーター:特徴量エンジニアリングモジュール (特徴量生成の概要と構成) で、オフラインおよびオンラインの特徴量処理に同一の実装を使用して一貫性を確保します。特徴量エンジニアリングの実装は、淘宝 (タオバオ) の実績あるソリューションを活用しています。FG 関連の概念の詳細については、「EasyRec におけるデータフィールド、データ特徴量、FG 特徴量の概念」をご参照ください。カスタム特徴量オペレーターによる FG の拡張方法については、「特徴量オペレーターのカスタマイズ」をご参照ください。
TFModel:EasyRec からエクスポートされた SavedModel ファイルをロードし、Blade を使用して CPU および GPU 上でのモデル推論を最適化します。
機能インスツルメンテーションおよびインクリメンタルモデル更新モジュール: これらのモジュールは主にリアルタイムトレーニングシナリオをサポートします。詳細については、「リアルタイムトレーニング」をご参照ください。
制限事項
CPU 推論は、汎用インスタンスファミリー g6、g7、および g8(Intel CPU のみ)でのみサポートされています。
GPU 推論は、T4、A10、GU30、L20、3090、および 4090 GPU でサポートされていますが、P100 はサポートされていません。
詳細については、「汎用 (g シリーズ)」をご参照ください。
バージョン
EasyRec プロセッサは積極的に開発されています。推論サービスをデプロイする際は、最新バージョンを使用することを推奨します。新しいバージョンでは、より多くの機能と改善されたパフォーマンスが提供されます。
ステップ 1:サービスのデプロイ
eascmd クライアントを使用して EasyRec モデルサービスをデプロイする場合、プロセッサタイプ を easyrec-{version} に設定します。クライアントを使用したサービスのデプロイ方法の詳細については、「サービスデプロイ:EASCMD」をご参照ください。以下のセクションでは、サービス設定ファイルの例を示します。
新しい FeatureGenerator ライブラリ (fg_mode=normal)
この例では、PyOdps3 ノードタイプを使用しています。このモードでは、新しいバージョンの FeatureGenerator ライブラリを使用できます。このライブラリは、豊富な組み込み変換オペレーターを提供し、カスタムオペレーター、配列やマップなどの複雑な入力タイプ、DAG ベースの特徴量依存関係をサポートしています。
次の例では、PAI-FeatureStore を使用して特徴量データを管理しています。スクリプト内の ${fs_project},${fs_model} 変数を実際の値に置き換えてください。詳細については、「ステップ 2:EAS モデルサービスの作成およびデプロイ」をご参照ください。
import json
import os
service_name = 'ali_rec_rnk_with_fg'
config = {
'name': service_name,
'metadata': {
"cpu": 8,
#"cuda": "11.2",
"gateway": "default",
"gpu": 0,
"memory": 32000,
"rolling_strategy": {
"max_unavailable": 1
},
"rpc": {
"enable_jemalloc": 1,
"max_queue_size": 256
}
},
"processor_envs": [
{
"name": "ADAPTE_FG_CONFIG",
"value": "true"
}
],
"model_path": "",
"processor": "easyrec-3.5",
"storage": [
{
"mount_path": "/home/admin/docker_ml/workspace/model/",
"oss": {
"path": "oss://easyrec/ali_rec_sln_acc_rnk/20250722/export/final_with_fg"
}
}
],
# fg_mode を変更する場合、呼び出し方法も変更する必要があります。
# fg_mode が 'normal' または 'tf' の場合、EasyRecRequest SDK を使用します。
# fg_mode が 'bypass' の場合、TFRequest SDK を使用します。
'model_config': {
'outputs': 'probs_ctr,probs_cvr',
'fg_mode': 'normal',
'steady_mode': True,
'period': 2880,
'access_key_id': f'{o.account.access_id}',
'access_key_secret': f'{o.account.secret_access_key}',
"load_feature_from_offlinestore": True,
'region': 'cn-shanghai',
'fs_project': '${fs_project}',
'fs_model': '${fs_model}',
'fs_entity': 'item',
'featuredb_username': 'guest',
'featuredb_password': '123456',
'log_iterate_time_threshold': 100,
'iterate_featuredb_interval': 5,
'mc_thread_pool_num': 1,
}
}
with open('echo.json', 'w') as output_file:
json.dump(config, output_file)
os.system(f'/home/admin/usertools/tools/eascmd -i {o.account.access_id} -k {o.account.secret_access_key} -e pai-eas.cn-shanghai.aliyuncs.com create echo.json')
# os.system(f'/home/admin/usertools/tools/eascmd -i {o.account.access_id} -k {o.account.secret_access_key} -e pai-eas.cn-shanghai.aliyuncs.com modify {service_name} -s echo.json')注:featuredb_username および featuredb_password パラメーターの値を有効なユーザー名およびパスワードに変更してください。
TF オペレーターバージョンの FeatureGenerator (fg_mode=tf)
重要:TF オペレーターバージョンの FeatureGenerator は、限定された組み込み特徴量のみをサポートしています:id_feature, raw_feature, combo_feature, lookup_feature, match_feature, sequence_feature。カスタム FeatureGenerator オペレーターはサポートされていません。
次のシェルスクリプトはデプロイに使用されます。スクリプトには AccessKey ID および AccessKey Secret がプレーンテキストで含まれています。この方法は簡単ですが、PAI-FeatureStore の使用方法や Hologres への負荷を軽減するために MaxCompute からデータをロードする方法は示していません。
PAI-FeatureStore を使用し、MaxCompute からデータをロードすることを推奨します。詳細については、「ステップ 2:EAS モデルサービスの作成およびデプロイ」をご参照ください。参照先のトピックでは、Python スクリプト、DataWorks 組み込みの o オブジェクト、および一時的な Security Token Service (STS) トークンを使用した、より安全なデプロイ方法について説明しています。その例では、load_feature_from_offlinestore が True に設定されています。
bizdate=$1
# fg_mode を変更する場合、呼び出し方法も変更する必要があります。fg_mode が 'normal' または 'tf' の場合、EasyRecRequest SDK を使用します。fg_mode が 'bypass' の場合、TFRequest SDK を使用します。
cat << EOF > echo.json
{
"name":"ali_rec_rnk_with_fg",
"metadata": {
"instance": 2,
"rpc": {
"enable_jemalloc": 1,
"max_queue_size": 100
}
},
"cloud": {
"computing": {
"instance_type": "ecs.g7.large",
"instances": null
}
},
"model_config": {
"remote_type": "hologres",
"url": "postgresql://<AccessKeyID>:<AccessKeySecret>@<endpoint>:<port>/<database>",
"tables": [{"name":"<schema>.<table_name>","key":"<index_column_name>","value": "<column_name>"}],
"period": 2880,
"fg_mode": "tf",
"outputs":"probs_ctr,probs_cvr",
},
"model_path": "",
"processor": "easyrec-3.5",
"storage": [
{
"mount_path": "/home/admin/docker_ml/workspace/model/",
"oss": {
"path": "oss://easyrec/ali_rec_sln_acc_rnk/20221122/export/final_with_fg"
}
}
]
}
EOF
# デプロイコマンドを実行します。
eascmd create echo.json
# eascmd -i <AccessKeyID> -k <AccessKeySecret> -e <endpoint> create echo.json
# 更新コマンドを実行します。
eascmd update ali_rec_rnk_with_fg -s echo.jsonFeatureGenerator のバイパス (fg_mode=bypass)
FeatureGenerator を使用しない場合は、EasyRec プロセッサを呼び出す前にクライアント側でリクエストをアセンブルする必要があります。詳細については、「EasyRec でトレーニングせずに EAS を使用した推論の方法」をご参照ください。
bizdate=$1
# fg_mode を変更する場合、呼び出し方法も変更する必要があります。fg_mode が 'normal' または 'tf' の場合、EasyRecRequest SDK を使用します。fg_mode が 'bypass' の場合、TFRequest SDK を使用します。
cat << EOF > echo.json
{
"name":"ali_rec_rnk_no_fg",
"metadata": {
"instance": 2,
"rpc": {
"enable_jemalloc": 1,
"max_queue_size": 100
}
},
"cloud": {
"computing": {
"instance_type": "ecs.g7.large",
"instances": null
}
},
"model_config": {
"fg_mode": "bypass"
},
"processor": "easyrec-3.5",
"processor_envs": [
{
"name": "INPUT_TILE",
"value": "2"
}
],
"storage": [
{
"mount_path": "/home/admin/docker_ml/workspace/model/",
"oss": {
"path": "oss://easyrec/ali_rec_sln_acc_rnk/20221122/export/final/"
}
}
],
"warm_up_data_path": "oss://easyrec/ali_rec_sln_acc_rnk/rnk_warm_up.bin"
}
EOF
# デプロイコマンドを実行します。
eascmd create echo.json
# eascmd -i <AccessKeyID> -k <AccessKeySecret> -e <endpoint> create echo.json
# 更新コマンドを実行します。
eascmd update ali_rec_rnk_no_fg -s echo.json次の表は、主要なパラメーターについて説明しています。その他のパラメーターについては、「JSON デプロイ」をご参照ください。
パラメーター | 必須 | 説明 | 例 |
processor | はい | EasyRec プロセッサの名前。 |
|
fg_mode | はい | 特徴量エンジニアリングモード。選択したモードに基づいて、サービスを呼び出す際に対応する SDK およびリクエスト構築方法を使用する必要があります。
|
|
outputs | はい | TensorFlow モデルの出力変数名 (例:probs_ctr)。複数の名前はカンマ (,) で区切ります。出力変数名を確認するには、TensorFlow コマンド saved_model_cli を実行します。 | "outputs":"probs_ctr,probs_cvr" |
save_req | いいえ | リクエストから取得したデータファイルをモデルディレクトリに保存するかどうかを指定します。保存されたファイルは、ウォームアップおよび性能テストに使用できます。有効値:
| "save_req": "false" |
アイテム特徴量キャッシュパラメーター | |||
period | はい | アイテム特徴量キャッシュの更新間隔 (分単位)。アイテム特徴量が毎日更新される場合、このパラメーターを 1 日の分数 (1,440) より大きい値 (例:2 日間隔の場合は 2,880) に設定できます。これにより、同じ日の間に不要な特徴量更新が行われるのを防ぎます。これは、特徴量が日常的なサービスデプロイ時にも更新されるためです。 |
|
remote_type | はい | アイテム特徴量のデータソース。有効値:
|
|
tables | いいえ | アイテム特徴量テーブル。remote_type が hologres に設定されている場合に必要です。次のサブパラメーターが含まれます。
複数のテーブルから入力アイテムデータを読み取ることができます。構成は次の形式である必要があります。
テーブル間で列名が重複する場合、リストの後ろに記述されたテーブルの列が、前に記述されたテーブルの列を上書きします。 |
|
url | いいえ | Hologres エンドポイント。 |
|
プロセッサによる PAI-FeatureStore アクセスのためのパラメーター | |||
fs_project | いいえ | PAI-FeatureStore プロジェクトの名前。PAI-FeatureStore を使用する場合に必要です。詳細については、「FeatureStore プロジェクトの構成」をご参照ください。 | "fs_project": "fs_demo" |
fs_model | いいえ | PAI-FeatureStore 内のモデル特徴量の名前。 | "fs_model": "fs_rank_v1" |
fs_entity | いいえ | PAI-FeatureStore 内のエンティティ名。 | "fs_entity": "item" |
region | いいえ | PAI-FeatureStore プロジェクトが存在するリージョン。 | "region": "cn-beijing" |
access_key_id | いいえ | PAI-FeatureStore にアクセスするために使用する AccessKey ID。 | "access_key_id": "xxxxx" |
access_key_secret | いいえ | PAI-FeatureStore にアクセスするために使用する AccessKey Secret。 | "access_key_secret": "xxxxx" |
featuredb_username | いいえ | FeatureDB のユーザー名。 | "featuredb_username": "xxxxx" |
featuredb_password | いいえ | FeatureDB のパスワード。 | "featuredb_password": "xxxxx" |
load_feature_from_offlinestore | いいえ | PAI-FeatureStore OfflineStore から直接オフライン特徴量を取得するかどうかを指定します。有効値:
| "load_feature_from_offlinestore": True |
iterate_featuredb_interval | いいえ | リアルタイム統計特徴量を更新する間隔 (秒単位)。 間隔を短くすると特徴量の新鮮さが向上しますが、特徴量が頻繁に変更される場合、読み取りコストが増加します。精度とコストのバランスを考慮してください。 | "iterate_featuredb_interval": 5 |
input_tile:自動特徴量ブロードキャストのためのパラメーター | |||
INPUT_TILE | いいえ | INPUT_TILE 環境変数を 1 に設定すると、アイテム特徴量の自動ブロードキャストが有効になります。これにより、user_id など、リクエスト内で一定のままとなる特徴量に対して単一の値を渡すことができます。INPUT_TILE 環境変数を 2 に設定すると、
説明
| "processor_envs": [ { "name": "INPUT_TILE", "value": "2" } ] |
ADAPTE_FG_CONFIG | いいえ | 古いバージョンの FeatureGenerator でトレーニングされたモデルとの互換性を有効にします。 | "processor_envs": [ { "name": "ADAPTE_FG_CONFIG", "value": "true" } ] |
DISABLE_FG_PRECISION | いいえ | 古いバージョンの FeatureGenerator でトレーニングされたモデルとの互換性のため。旧バージョンでは、デフォルトで float 型特徴量を 6 桁の有効数字に制限していましたが、新バージョンではこの制限が解除されています。旧バージョンの動作 (6 桁制限) を適用するには、この変数を | "processor_envs": [ { "name": "DISABLE_FG_PRECISION", "value": "false" } ] |
EasyRec プロセッサ推論最適化
パラメーター | 必須 | 説明 | 例 |
TF_XLA_FLAGS | いいえ | GPU 推論の場合、このパラメーターにより XLA がモデルのコンパイルおよび最適化を行い、オペレーター融合を自動的に実行します。 | "processor_envs": [ { "name": "TF_XLA_FLAGS", "value": "--tf_xla_auto_jit=2" }, { "name": "XLA_FLAGS", "value": "--xla_gpu_cuda_data_dir=/usr/local/cuda/" }, { "name": "XLA_ALIGN_SIZE", "value": "64" } ] |
TF スケジューリングパラメーター | いいえ | inter_op_parallelism_threads:異なるオペレーションを並列で実行するためのスレッド数を制御します。 intra_op_parallelism_threads:単一のオペレーション内で使用されるスレッド数を制御します。 32 コア CPU の場合、これらのパラメーターを 16 に設定すると通常パフォーマンスが向上します。ただし、2 つのスレッド数の合計が CPU コア総数を超えてはいけません。 | "model_config": { "inter_op_parallelism_threads": 16, "intra_op_parallelism_threads": 16, } |
rpc.worker_threads | いいえ | EAS 構成の | "metadata": { "rpc": { "worker_threads": 15 } |
ステップ 2:サービスの呼び出し
2.1 ネットワーク構成
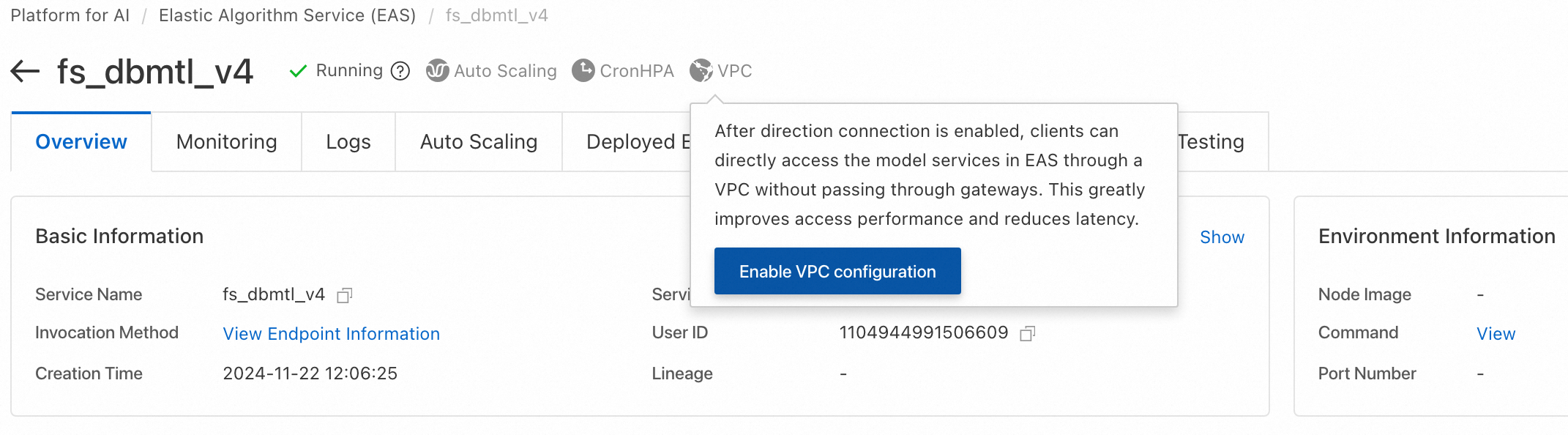
PAI-Rec エンジンおよびモデルスコアリングサービスは PAI-EAS 上にデプロイされ、ダイレクトネットワーク接続が必要です。PAI-EAS インスタンスページで、右上隅の「VPC」をクリックして、同じ VPC、vSwitch、およびセキュリティグループを構成します。詳細については、「EAS からのパブリックまたはオンプレミスリソースへのアクセス」をご参照ください。Hologres を使用する場合も、同じ VPC 情報を構成する必要があります。次の図はその例を示しています。
2.2 サービス情報の取得
EasyRec モデルサービスをデプロイした後、Elastic Algorithm Service (EAS) ページに移動します。呼び出したいサービスを見つけ、サービス方法 列で 呼び出し情報 をクリックして、サービスエンドポイントおよびトークンを表示します。
2.3 SDK コード例
EasyRec モデルサービスは、入力および出力の両方に Protocol Buffers (Protobuf) 形式を使用します。そのため、PAI-EAS コンソールからサービスをテストすることはできません。
サービスを呼び出す前に、ステップ 1 のデプロイ時に model_config で構成された fg_mode を確認してください。モードによってクライアントの呼び出し方法が異なります。
モード (fg_mode) | リクエストクラス |
normal または tf (組み込み特徴量エンジニアリングあり) | EasyRecRequest |
bypass (組み込み特徴量エンジニアリングなし) | TFRequest |
FG あり fg_mode=normal または tf
Java
Maven 環境構成については、「Java SDK ガイド」をご参照ください。次のコードは、ali_rec_rnk_with_fg サービスへのリクエスト送信方法を示しています。
import com.aliyun.openservices.eas.predict.http.*;
import com.aliyun.openservices.eas.predict.request.EasyRecRequest;
PredictClient client = new PredictClient(new HttpConfig());
// パブリックゲートウェイ経由でサービスにアクセスする場合、ユーザー ID (UID) で始まるエンドポイントを使用します。このエンドポイントは、EAS コンソールのサービスの呼び出し情報から取得できます。
client.setEndpoint("xxxxxxx.vpc.cn-hangzhou.pai-eas.aliyuncs.com");
client.setModelName("ali_rec_rnk_with_fg");
// ご利用のサービストークンに置き換えてください。
client.setToken("******");
EasyRecRequest easyrecRequest = new EasyRecRequest(separator);
// userFeatures: ユーザー特徴量。特徴量は \u0002 (CTRL_B) で区切られます。特徴量名と値はコロン (:) で区切られます。
// user_fea0:user_fea0_val\u0002user_fea1:user_fea1_val
// 特徴量値のフォーマットの詳細については、https://easyrec.readthedocs.io/latest/feature/rtp_fg.html をご参照ください。
easyrecRequest.appendUserFeatureString(userFeatures);
// 1 つのユーザー特徴量を個別に追加することもできます:
// easyrecRequest.addUserFeature(String userFeaName, T userFeaValue)。
// 特徴量値のデータ型 T は、String、float、long、int のいずれかです。
// contextFeatures: コンテキスト特徴量。特徴量は \u0002 (CTRL_B) で区切られます。特徴量名とその値はコロン (:) で区切られます。同じ特徴量の複数の値もコロンで区切られます。
// ctxt_fea0:ctxt_fea0_ival0:ctxt_fea0_ival1:ctxt_fea0_ival2\u0002ctxt_fea1:ctxt_fea1_ival0:ctxt_fea1_ival1:ctxt_fea1_ival2
easyrecRequest.appendContextFeatureString(contextFeatures);
// 1 つのコンテキスト特徴量を個別に追加することもできます:
// easyrecRequest.addContextFeature(String ctxtFeaName, List<Object> ctxtFeaValue)。
// ctxtFeaValue のデータ型は、String、Float、Long、Integer のいずれかです。
// itemIdStr: 予測対象のアイテム ID リスト。カンマ (,) で区切られます。
easyrecRequest.appendItemStr(itemIdStr, ",");
// 1 つのアイテム ID を個別に追加することもできます:
// easyrecRequest.appendItemId(String itemId)
easyrecPredictProtos.PBResponse response = client.predict(easyrecRequest);
for (Map.Entry<String, easyrecPredictProtos.Results> entry : response.getResultsMap().entrySet()) {
String key = entry.getKey();
easyrecPredictProtos.Results value = entry.getValue();
System.out.print("key: " + key);
for (int i = 0; i < value.getScoresCount(); i++) {
System.out.format("value: %.6g\n", value.getScores(i));
}
}
// FG 処理後の特徴量を取得して、オフライン特徴量との一貫性を確認します。
// DebugLevel を 1 に設定すると、生成された特徴量が返されます。
easyrecRequest.setDebugLevel(1);
easyrecPredictProtos.PBResponse response = client.predict(easyrecRequest);
Map<String, String> genFeas = response.getGenerateFeaturesMap();
for(String itemId: genFeas.keySet()) {
System.out.println(itemId);
System.out.println(genFeas.get(itemId));
}Python
環境構成方法については、「Python SDK ガイド」をご参照ください。本番環境では、より高いパフォーマンスを得るために Java クライアントを使用することを推奨します。次のコードはその例です。
from eas_prediction import PredictClient
from eas_prediction.easyrec_request import EasyRecRequest
from eas_prediction.easyrec_predict_pb2 import PBFeature
from eas_prediction.easyrec_predict_pb2 import PBRequest
if __name__ == '__main__':
endpoint = 'http://xxxxxxx.vpc.cn-hangzhou.pai-eas.aliyuncs.com'
service_name = 'ali_rec_rnk_with_fg'
token = '******'
client = PredictClient(endpoint, service_name)
client.set_token(token)
client.init()
req = PBRequest()
uid = PBFeature()
uid.string_feature = 'u0001'
req.user_features['user_id'] = uid
age = PBFeature()
age.int_feature = 12
req.user_features['age'] = age
weight = PBFeature()
weight.float_feature = 129.8
req.user_features['weight'] = weight
req.item_ids.extend(['item_0001', 'item_0002', 'item_0003'])
easyrec_req = EasyRecRequest()
easyrec_req.add_feed(req, debug_level=0)
res = client.predict(easyrec_req)
print(res)パラメーターは次のとおりです。
endpoint:サービスエンドポイント。取得するには、Elastic Algorithm Service (EAS) ページに移動し、ご利用のサービスを見つけ、サービス方法 列で 呼び出し情報 をクリックします。
service_name:サービス名。Elastic Algorithm Service (EAS) ページから取得します。
token:サービストークン。Invocation Information ダイアログボックスで確認できます。
FG なし fg_mode=bypass
Java
Maven 環境構成については、「Java SDK ガイド」をご参照ください。次のコードは、ali_rec_rnk_no_fg サービスへのリクエスト送信方法を示しています。
import java.util.List;
import com.aliyun.openservices.eas.predict.http.PredictClient;
import com.aliyun.openservices.eas.predict.http.HttpConfig;
import com.aliyun.openservices.eas.predict.request.TFDataType;
import com.aliyun.openservices.eas.predict.request.TFRequest;
import com.aliyun.openservices.eas.predict.response.TFResponse;
public class TestEasyRec {
public static TFRequest buildPredictRequest() {
TFRequest request = new TFRequest();
request.addFeed("user_id", TFDataType.DT_STRING,
new long[]{3}, new String []{ "u0001", "u0001", "u0001"});
request.addFeed("age", TFDataType.DT_FLOAT,
new long[]{3}, new float []{ 18.0f, 18.0f, 18.0f});
// 注:INPUT_TILE=2 を設定している場合、同じ値を持つ特徴量については、値を 1 回だけ渡す必要があります:
// request.addFeed("user_id", TFDataType.DT_STRING,
// new long[]{1}, new String []{ "u0001" });
// request.addFeed("age", TFDataType.DT_FLOAT,
// new long[]{1}, new float []{ 18.0f});
request.addFeed("item_id", TFDataType.DT_STRING,
new long[]{3}, new String []{ "i0001", "i0002", "i0003"});
request.addFetch("probs");
return request;
}
public static void main(String[] args) throws Exception {
PredictClient client = new PredictClient(new HttpConfig());
// ダイレクトネットワーク接続を使用するには、setDirectEndpoint メソッドを使用します。例:
// client.setDirectEndpoint("pai-eas-vpc.cn-shanghai.aliyuncs.com");
// EAS コンソールでダイレクトネットワーク接続を有効にし、EAS サービスにアクセスするために使用するソース vSwitch を指定する必要があります。
// ダイレクトネットワーク接続は、より安定性とパフォーマンスを提供します。
client.setEndpoint("xxxxxxx.vpc.cn-hangzhou.pai-eas.aliyuncs.com");
client.setModelName("ali_rec_rnk_no_fg");
client.setToken("");
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
try {
TFResponse response = client.predict(buildPredictRequest());
// "probs" はモデルの出力フィールドです。curl コマンドを使用してモデルの入力および出力を確認できます:
// curl xxxxxxx.vpc.cn-hangzhou.pai-eas.aliyuncs.com -H "Authorization:{token}"
List<Float> result = response.getFloatVals("probs");
System.out.print("Predict Result: [");
for (int j = 0; j < result.size(); j++) {
System.out.print(result.get(j).floatValue());
if (j != result.size() - 1) {
System.out.print(", ");
}
}
System.out.print("]\n");
} catch (Exception e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis();
System.out.println("Spend Time: " + (endTime - startTime) + "ms");
client.shutdown();
}
}Python
手順については、「Python SDK ガイド」をご参照ください。パフォーマンスが低いため、Python SDK はデバッグ用途でのみ推奨されます。本番環境では Java SDK を使用してください。次のコードは、ali_rec_rnk_no_fg サービスへのリクエスト送信方法を示しています。
#!/usr/bin/env python
from eas_prediction import PredictClient
from eas_prediction import StringRequest
from eas_prediction import TFRequest
if __name__ == '__main__':
client = PredictClient('http://xxxxxxx.vpc.cn-hangzhou.pai-eas.aliyuncs.com', 'ali_rec_rnk_no_fg')
client.set_token('')
client.init()
# 注:server_default をご利用のモデルの実際の signature_name に置き換えてください。詳細については、上記の SDK ガイドをご参照ください。
req = TFRequest('server_default')
req.add_feed('user_id', [3], TFRequest.DT_STRING, ['u0001'] * 3)
req.add_feed('age', [3], TFRequest.DT_FLOAT, [18.0] * 3)
# 注:INPUT_TILE=2 最適化を有効にした後、上記の特徴量に対して単一の値を渡すことができます。
# req.add_feed('user_id', [1], TFRequest.DT_STRING, ['u0001'])
# req.add_feed('age', [1], TFRequest.DT_FLOAT, [18.0])
req.add_feed('item_id', [3], TFRequest.DT_STRING,
['i0001', 'i0002', 'i0003'])
for x in range(0, 100):
resp = client.predict(req)
print(resp)2.4 カスタムサービスリクエストの構築
Python および Java 以外の言語からサービスを呼び出すには、.proto ファイルから予測リクエストコードを手動で生成する必要があります。サービスリクエストを構築するには、次の Protocol Buffers 定義を使用して関連コードを生成します。
tf_predict.proto:TensorFlow モデルのリクエスト定義。
syntax = "proto3"; option cc_enable_arenas = true; option go_package = ".;tf"; option java_package = "com.aliyun.openservices.eas.predict.proto"; option java_outer_classname = "PredictProtos"; enum ArrayDataType { // DataType の有効な値ではありません。DataType フィールドが // 設定されていないことを示すために使用されます。 DT_INVALID = 0; // すべての計算デバイスがサポートすることが期待される // データ型。 DT_FLOAT = 1; DT_DOUBLE = 2; DT_INT32 = 3; DT_UINT8 = 4; DT_INT16 = 5; DT_INT8 = 6; DT_STRING = 7; DT_COMPLEX64 = 8; // 単精度複素数 DT_INT64 = 9; DT_BOOL = 10; DT_QINT8 = 11; // 量子化 int8 DT_QUINT8 = 12; // 量子化 uint8 DT_QINT32 = 13; // 量子化 int32 DT_BFLOAT16 = 14; // 16 ビットに切り捨てられた Float32。キャスト演算子専用。 DT_QINT16 = 15; // 量子化 int16 DT_QUINT16 = 16; // 量子化 uint16 DT_UINT16 = 17; DT_COMPLEX128 = 18; // 倍精度複素数 DT_HALF = 19; DT_RESOURCE = 20; DT_VARIANT = 21; // 任意の C++ データ型 } // 配列の次元 message ArrayShape { repeated int64 dim = 1 [packed = true]; } // 配列を表すプロトコルバッファー message ArrayProto { // データ型。 ArrayDataType dtype = 1; // 配列の形状。 ArrayShape array_shape = 2; // DT_FLOAT。 repeated float float_val = 3 [packed = true]; // DT_DOUBLE。 repeated double double_val = 4 [packed = true]; // DT_INT32, DT_INT16, DT_INT8, DT_UINT8。 repeated int32 int_val = 5 [packed = true]; // DT_STRING。 repeated bytes string_val = 6; // DT_INT64。 repeated int64 int64_val = 7 [packed = true]; // DT_BOOL。 repeated bool bool_val = 8 [packed = true]; } // PredictRequest は、実行する TensorFlow モデル、 // 入力をテンソルにマッピングする方法、および // ユーザーに返す前に出力をフィルターする方法を指定します。 message PredictRequest { // 評価する名前付き署名。指定しない場合、デフォルトの署名が // 使用されます。 string signature_name = 1; // 入力テンソル。 // 入力テンソルの名前はエイリアス名です。エイリアスから実際の // 入力テンソル名へのマッピングは、モデルエクスポートの // 「inputs」というキーの下にある名前付き汎用署名として // 格納されていると想定されます。 // 「inputs」という名前の汎用署名に記載されている各エイリアスは、 // 予測を実行するために正確に 1 回提供する必要があります。 map<string, ArrayProto> inputs = 2; // 出力フィルター。 // 指定された名前はエイリアス名です。エイリアスから実際の出力 // テンソル名へのマッピングは、モデルエクスポートの // 「outputs」というキーの下にある名前付き汎用署名として // 格納されていると想定されます。 // ここで指定されたテンソルのみが実行/フェッチされ、返されます。 // ただし、何も指定されていない場合は、名前付き署名で指定された // すべてのテンソルが実行/フェッチされ、返されます。 repeated string output_filter = 3; // デバッグフラグ // 0: 予測結果のみを返し、デバッグ情報は返しません。 // 100: 予測結果を返し、リクエストを model_dir に保存します。 // 101: タイムラインを model_dir に保存します。 int32 debug_level = 100; } // 成功した実行時の PredictRequest の応答。 message PredictResponse { // 出力テンソル。 map<string, ArrayProto> outputs = 1; }easyrec_predict.proto:FG を含む TensorFlow モデルのリクエスト定義。
syntax = "proto3"; option cc_enable_arenas = true; option go_package = ".;easyrec"; option java_package = "com.aliyun.openservices.eas.predict.proto"; option java_outer_classname = "EasyRecPredictProtos"; import "tf_predict.proto"; // コンテキスト特徴量 message ContextFeatures { repeated PBFeature features = 1; } message PBFeature { oneof value { int32 int_feature = 1; int64 long_feature = 2; string string_feature = 3; float float_feature = 4; } } // PBRequest はアグリゲーターのリクエストを指定します。 message PBRequest { // デバッグフラグ // 0: 予測結果のみを返し、デバッグ情報は返しません。 // 3: FG モジュールによって生成された特徴量を文字列形式で返します。 // 特徴量の一貫性チェックやオンラインディープラーニングサンプルの生成に使用できます。 // 特徴量値は \u0002 で区切られます。 // 100: 予測結果を返し、リクエストを model_dir に保存します。 // 101: タイムラインを model_dir に保存します。 // 102: DSSM や MIND などのリコールモデルの場合、Faiss で取得された結果だけでなく、 // ユーザー埋め込みベクトルも返します。 int32 debug_level = 1; // ユーザー特徴量 map<string, PBFeature> user_features = 2; // アイテム ID、静的 (毎日更新) アイテム特徴量。 // 各プロセッサノードに存在する特徴量キャッシュから // item_ids によって取得されます。 repeated string item_ids = 3; // 各アイテムのコンテキスト特徴量、リアルタイムアイテム特徴量。 // コンテキスト特徴量として渡すことができます。 map<string, ContextFeatures> context_features = 4; // 埋め込み取得の近傍数。 int32 faiss_neigh_num = 5; } // 返却結果 message Results { repeated double scores = 1 [packed = true]; } enum StatusCode { OK = 0; INPUT_EMPTY = 1; EXCEPTION = 2; } // PBResponse はアグリゲーターの応答を指定します。 message PBResponse { // 結果 map<string, Results> results = 1; // アイテム特徴量 map<string, string> item_features = 2; // FG 生成特徴量 map<string, string> generate_features = 3; // コンテキスト特徴量 map<string, ContextFeatures> context_features = 4; string error_msg = 5; StatusCode status_code = 6; // アイテム ID repeated string item_ids = 7; repeated string outputs = 8; // すべての FG 入力特徴量 map<string, string> raw_features = 9; // 出力テンソル map<string, ArrayProto> tf_outputs = 10; }