EasyRec アルゴリズムフレームワークには、データフィールド、特徴フィールド、Feature Generator(FG)特徴という 3 つの主要な概念があります。このトピックでは、これらの概念とその違いについて説明します。
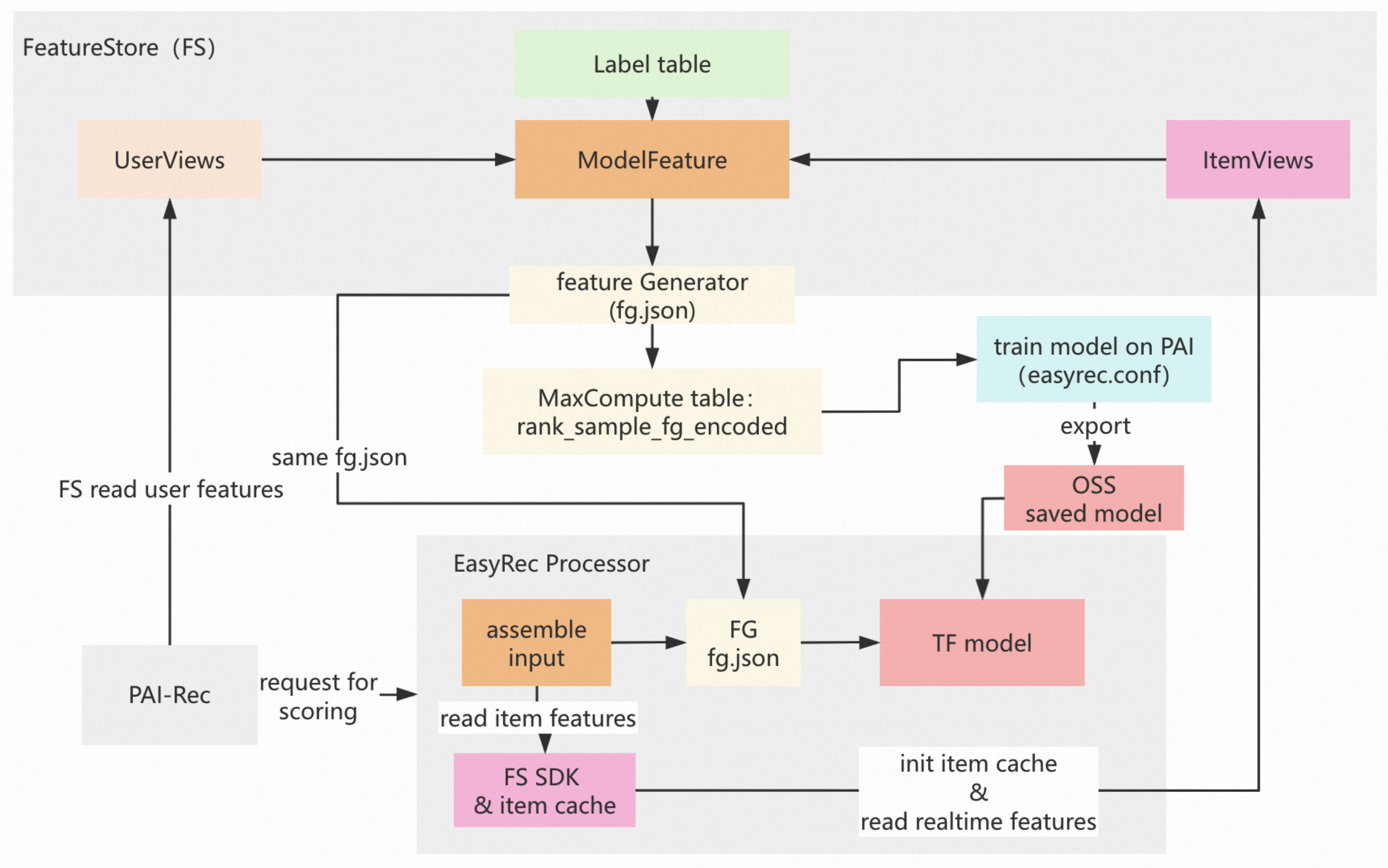
EasyRec のオフライン トレーニングとオンライン推論における FG の役割
用語
FeatureStore:FeatureStore は、Platform for AI(PAI)が提供する特徴管理ツールです。このツールを使用すると、オフラインシステムとオンラインシステムの特徴を保存および管理できます。詳細については、「概要」(FeatureStore)をご参照ください。
FG:FG は、オフラインとオンラインの特徴処理間の一貫性を確保するために設計されています。FG は、ID 特徴、未加工特徴、組み合わせ特徴、ルックアップ特徴、一致特徴、シーケンス特徴、および重複特徴を生成できます。ルックアップ特徴とシーケンス特徴は一般的に使用されます。詳細については、「RTP FG」をご参照ください。
ユーザー特徴:前の図に示されているユーザー特徴には、オフラインシステムとオンラインシステムの両方から取得されたものが含まれます。前の図の左下隅にある PAI-Rec エンジンは、FeatureStore SDK を使用してユーザー特徴を読み取ります。
アイテム特徴:スコアリングサービス EasyRec プロセッサ は、FeatureStore SDK を使用してアイテム特徴を読み取ります。
入力のアセンブル:リクエスト内のユーザー特徴とキャッシュ内のアイテム特徴が、特徴生成のためにアセンブルされます。特徴生成後、生成された特徴はスコアリングのために TensorFlow モデルにインポートされます。
EasyRec プロセッサ:PAI の Elastic Algorithm Service(EAS)にデプロイされ、レコメンデーション、広告、検索モデルのスコアリングに使用されます。EasyRec プロセッサは、EasyRec ディープラーニングモデルを読み込み、パフォーマンスの最適化を行うことができます。
easyrec.conf:このファイルは、EasyRec ディープラーニングモデルで使用されるデータフィールド、特徴タイプ、およびネットワーク構造を記述します。
パイプライン
オフライン パイプライン:FeatureStore は、UserViews(複数のユーザー側 特徴ビュー)、ItemViews(複数のアイテム側特徴ビュー)、およびラベルテーブル(トレーニングラベルを含む MaxCompute テーブル)を使用して、モデル特徴(トレーニングサンプルテーブル)を構築します。FG(MapReduce JAR パッケージ fg_on_odps-1.3.59-jar-with-dependencies.jar)は fg.json ファイルと連携して、モデル特徴を結果テーブル rank_sample_fg_encoded に変換します。モデルは easyrec.conf ファイルに基づいて PAI でトレーニングされ、Object Storage Service(OSS)にエクスポートおよび保存された後、スコアリングのために TensorFlow モデルにインポートされます。
オンライン パイプライン:PAI-Rec エンジンは、スコアリングされるユーザー特徴とアイテム ID を取得し(このロジック部分は前の図には示されていません)、EasyRec プロセッサに特徴のアセンブルをリクエストします。次に、EasyRec プロセッサは FG を使用してオンライン特徴変換を実行し、アイテム ID をスコアリングしてから、スコアを返します。
1. EasyRec 構成ファイルのデータフィールドと特徴フィールド
1.1. データフィールド構成:data_config
data_config は、easyrec.conf ファイル内の元のデータフィールドの名前とタイプ、およびこれらのデータフィールドの欠損値を補完する方法を指定します。詳細については、「EasyRec のデータフィールド」をご参照ください。データフィールドの値の型には、int、double、string が含まれます。データは、CSV ファイル、MaxCompute テーブル、Kafka データストリームなど、さまざまな形式で保存できます。
例:キーと値のタイプのデータ
欠損値の補完:欠損値はキーと値のペアで補完されます。この例では、キーと値のペアは -1024:0 です。
オフライン トレーニングとオンライン予測のロジック:欠損値は TensorFlow モデルで補完されます。
input_fields: {
input_name: "prop_kv"
input_type: STRING
default_val:"-1024:0"
}1.2. 特徴フィールド構成:feature_config
data_config は主にデータフィールドとラベルを定義します。feature_config は、これらのデータフィールドがモデルによってどのように解析および使用されるかを指定します。たとえば、フィールド x は STRING タイプの特徴として使用されます。feature_config では、このフィールドは ID 特徴、タグ特徴、またはシーケンス特徴 として解釈できます。
例:ID 特徴
features {
input_names: "user_id"
feature_type: IdFeature
embedding_dim: 32
hash_bucket_size: 100000
}説明:user_id で示される特徴は、100,000 個のバケットにハッシュマッピングされます。各バケット ID は、モデル トレーニングを通じて 32 次元ベクトルにマッピングされます。
オフライン トレーニングとオンライン予測のロジック:user_id で示される特徴は、TensorFlow モデルで 32 次元ベクトルに変換されます。
例:未加工特徴
features {
input_names: "ctr"
feature_type: RawFeature
boundaries: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
embedding_dim: 8
}前処理:PAI のビニングアルゴリズムを使用して、一連の境界を取得します。次に、これらの境界が feature_config の特徴に対して構成されます。
オフライン トレーニングとオンライン予測のロジック:ctr で示される特徴について、境界がバケット化されてバケット ID が生成され、バケット ID がベクトルにマッピングされます。
例:タグ特徴
features : {
input_names: 'tags'
feature_type: TagFeature
separator: '|'
hash_bucket_size: 100000
embedding_dim: 24
}たとえば、記事のタグ特徴は Entertainment|Funny|Popular で、縦棒(|)が区切り文字として使用されます。
オフライン トレーニングとオンライン予測のロジック:TensorFlow モデルでタグ特徴に対してハッシュ埋め込みを実行して、埋め込みベクトルを生成します。次に、ベクトルに対して平均プーリングを実行して、平均埋め込みベクトルを生成します。
2. FG でのルックアップ特徴変換
FG は、さまざまな特徴の組み合わせと変換方法をサポートしています。ルックアップ特徴変換の例を次に示します。
{
"map": "user:map_brand_click_kv",
"key":"item:brand",
"feature_name": "map_brand_click_count",
"feature_type":"lookup_feature",
"needDiscrete":false,
}オフライン データ処理:オフラインシステムでは、fg_on_odps-1.3.59-jar-with-dependencies.jar パッケージが必要です。アイテム特徴 brand をキーとして使用して、ユーザー特徴 map_brand_click_kv の値をクエリし、取得した値を新しい特徴 map_brand_click_count に使用します。この例では、map_brand_click_kv はさまざまなブランドでのユーザー クリック数を示し、map_brand_click_count は現在のアイテム ブランドでのユーザー クリック数を示します。
オンライン予測:EasyRec プロセッサ(スコアリングサービス) は FG を使用して map_brand_click_count の値を計算し、その値を予測のために TensorFlow モデルに送信します。
3. FAQ
3.1. 境界はどこから来て、何を意味しますか?
EasyRec 構成ファイルの次の例では、CTR で示される特徴の構成に boundaries パラメータが含まれています。
feature_configs: {
input_names: "CTR"
feature_type: RawFeature
boundaries: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
embedding_dim: 8
}boundaries パラメータの値は、PAI の ビニング コンポーネントを使用して取得されます。
TensorFlow モデルでは、ビニングコンポーネントが CTR で示される特徴に対して離散化を実行する場合、境界は一連の離散間隔と見なされます。(-inf, 0.1)、[0.1, 0.2)、[0.2, 0.3)、[0.3, 0.4)、[0.4, 0.5)、[0.5, 0.6)、[0.6, 0.7)、[0.7, 0.8)、[0.8, 0.9)、[0.9, 1.0)。boundaries パラメータを構成した後、embedding_dim パラメータを構成して、間隔番号をベクトルに変換する必要があります。
3.2. オンラインシステムで FG を使用して特徴変換を実行するにはどうすればよいですか?オフラインシステムとオンラインシステム間の一貫性を確保するにはどうすればよいですか?
fg.json ファイルは、特徴変換プロセスを記述するために使用されます。オンラインシステムとオフラインシステムの両方で同じコードを使用して、特徴変換ロジックの一貫性を確保します。オンラインシステムは FG を使用して特徴変換を実行します。
3.3. 特徴の欠損値の補完はどのように実装されますか?欠損値の補完はどこで構成しますか?
easyrec.config ファイルを構成する場合、data_config の各特徴フィールドに default_value パラメータを構成して、欠損値を補完できます。モデル トレーニング中は、データの読み取り時に欠損値が default_value パラメータの値で補完されます。オンライン モデル推論中は、推論を実行できるように、最初に欠損値を補完する必要があります。
FG を使用する場合は、オンラインシステムとオフラインシステムの両方で fg.json ファイルに欠損値の補完が構成されます。