特徴量エンジニアリングは、推薦アルゴリズムにおいて、ユーザー、アイテム、動作などの生データセットを処理し、新たな特徴量テーブルを生成するプロセスです。これらのテーブルは、その後の取得およびソートに使用されます。
前提条件
-
Platform for AI (PAI) ビジュアルモデリングが有効化され、デフォルトのワークスペースが作成済みである必要があります。詳細については、「PAI の有効化とデフォルトワークスペースの作成」をご参照ください。
-
ワークスペースに MaxCompute リソースがアタッチ済みである必要があります。詳細については、「ワークスペース向け計算リソースの管理」をご参照ください。
-
MaxCompute データソースが作成され、ワークスペースのエンジンとしてアタッチ済みである必要があります。詳細については、「MaxCompute データソースの作成」をご参照ください。
データセット
特徴量エンジニアリングの手順を説明するため、本トピックではスクリプトを用いてユーザー、アイテム、動作の各テーブルをシミュレート・生成します。これらのテーブルはサンプルであり、実際のデータは含みません。
ユーザー テーブル:pai_online_project.rec_sln_demo_user_table
|
フィールド |
型 |
説明 |
|
user_id |
bigint |
ユーザー タグ。 |
|
gender |
string |
性別。 |
|
age |
bigint |
年齢。 |
|
city |
string |
市。 |
|
item_cnt |
bigint |
フォローしているユーザー数。 |
|
follow_cnt |
bigint |
フォロー中のユーザー数。 |
|
follower_cnt |
bigint |
フォロワー数。 |
|
register_time |
bigint |
登録時刻。 |
|
tags |
string |
ユーザーのタグ。 |
|
ds |
string |
公開時間。 |
アイテム テーブル:pai_online_project.rec_sln_demo_item_table
|
フィールド |
型 |
説明 |
|
item_id |
bigint |
アイテム ID。 |
|
duration |
double |
動画の持続時間。 |
|
title |
string |
総クリック数。 |
|
category |
string |
レベル 1 カテゴリ。 |
|
author |
bigint |
作成者。 |
|
click_count |
bigint |
クリック総数。 |
|
praise_count |
bigint |
いいね総数。 |
|
pub_time |
bigint |
公開時刻。 |
|
ds |
string |
テーブルのパーティションキー列。 |
動作 テーブル:pai_online_project.rec_sln_demo_behavior_table
|
フィールド |
型 |
説明 |
|
request_id |
bigint |
イベントトラッキング ID またはリクエスト ID。 |
|
user_id |
bigint |
ユーザーの一意な ID。 |
|
exp_id |
string |
動作のイベントタイプ。 |
|
page |
string |
ページ名。 |
|
net_type |
string |
ネットワークタイプ。 |
|
event_time |
bigint |
動作イベントが発生した時刻。 |
|
item_id |
bigint |
アイテム ID。 |
|
event |
string |
動作のイベントタイプ。 |
|
playtime |
double |
再生または読み取りの持続時間。 |
|
ds |
string |
テーブルのパーティションキー列。 |
特徴量エンジニアリング
手順 1: [Designer] ページへ移動
-
PAI コンソール にログインします。
-
左側のナビゲーションウィンドウで、ワークスペース管理 をクリックします。ワークスペース管理ページで、管理対象のワークスペース名をクリックします。
-
ワークスペース ページの左側にあるナビゲーションウィンドウで、[モデル開発とトレーニング > ビジュアルモデリング] を選択して、ビジュアルモデリング ページを開きます。
ステップ 2: ワークフローの構築
-
[デザイナー] ページで、[プリセットテンプレート] タブをクリックします。
-
推薦ソリューション - 特徴量エンジニアリング セクションで、作成 をクリックします。
-
ワークフローの作成 ダイアログボックスでパラメーターを設定します。デフォルト値を使用します。
ワークフローのデータ保存先 を OSS バケットのパスに設定します。このパスは、ワークフロー実行中に生成される一時データおよびモデルの保存先として使用されます。
-
OK をクリックします。
ワークフローの作成完了まで、約 10 秒待ちます。
-
ワークフローリストで、推薦ソリューション - 特徴量エンジニアリング ワークフローをダブルクリックして開きます。
-
システムがプリセットテンプレートに基づいてワークフローを自動構築します(下図参照)。
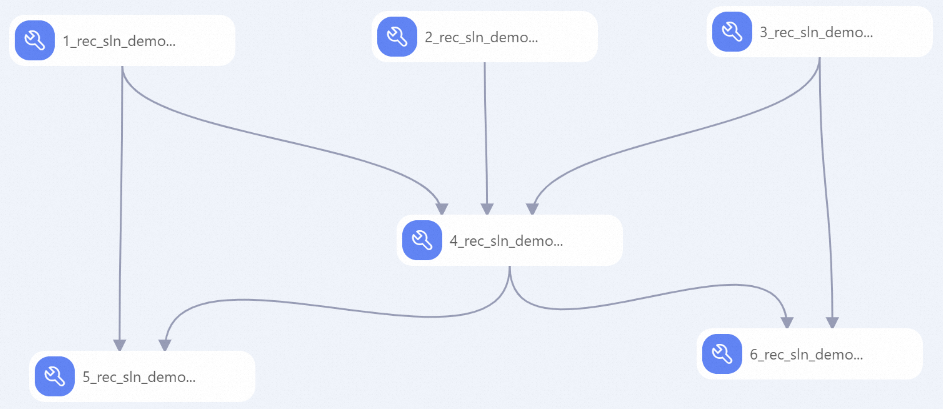
ノード
説明
1
アイテムテーブルの前処理:
-
後続の特徴量生成 (FG) ステップで使用するために、タグ特徴の区切り文字を
chr(29)に置換します。 -
出力が新規登録アイテムの特徴量であるかどうかを示します。
2
動作テーブルの前処理:day_h や week_day など、時間ベースの派生特徴量を生成します。
3
ユーザー テーブルの前処理:
-
output は、ユーザーが新規登録されたかどうかを示す特徴量です。
-
後続の FG ステップで使用するために、タグ特徴の区切り文字を
chr(29)に置換します。
4
動作、ユーザー、アイテムの各テーブルを関連付けて、統計的特性を備えたワイド動作ログテーブルを作成します。
5
一定期間におけるアイテムの統計的特徴量を含むアイテム特徴量テーブルを生成します。
-
item__{event}_cnt_{N}d:N 日間における特定イベントのアイテムへの発生回数(アイテムの人気度を示す)。 -
item__{event}_{itemid}_dcnt_{N}d:N 日間における特定イベントを該当アイテムに対して実行したユニークユーザー数(アイテムの人気度を示す)。 -
item__{min|max|avg|sum}_{field}_{N}d:N 日間における、該当アイテムに対するポジティブイベントにおけるユーザーの数値プロパティの統計的ディストリビューション(特定の数値プロパティを持つユーザーのプリファレンスを示す)。 -
item__kv_{cate}_{event}_{N}d:N 日間における、該当アイテムに対する特定イベントにおけるユーザーのカテゴリプロパティの統計情報(特定のカテゴリプロパティを持つユーザーのプリファレンスを示す)。
6
一定期間におけるユーザーの統計的特徴量を含むユーザー特徴量テーブルを生成します。
-
ステップ 3: 関数の追加
-
ビジネスフローを作成します。詳細については、「ビジネスフローの作成」をご参照ください。
-
新しいビジネスフロー内の MaxCompute を右クリックし、 を選択して、count_cates_kvs.py という名前の Python スクリプトリソースを作成します。詳細については、「MaxCompute リソースの作成および使用」をご参照ください。
-
新しいビジネスフロー内の MaxCompute を右クリックし、新規関数 を選択します。MaxCompute 関数 COUNT_CATES_KVS を作成します。クラス名 には
count_cates_kvs.CountCatesKVSを、リソースリスト にはcount_cates_kvs.pyを指定します。詳細については、「ユーザー定義関数の作成および使用」をご参照ください。
ステップ 4: ワークフローの実行と出力の確認
デフォルトでは、このデータセットは過去 45 日分のデータを使用するため、実行に長時間を要する場合があります。実行を高速化するには、以下の操作を行ってください。
-
実行タイムウィンドウのパラメーターを更新し、より短い期間のデータを使用します。
-
以下の各ノードをクリックします。右側の パラメーター設定 タブで、実行タイムウィンドウ パラメーターをデフォルトの
(-45,0]から(-9,0]に変更します。-
1_rec_sln_demo_item_table_preprocess_v2 -
2_rec_sln_demo_behavior_table_preprocess_ v2 -
3_rec_sln_demo_user_table_preprocess_v2 -
4_rec_sln_demo_behavior_table_preprocess_wide_v2
-
-
以下の各ノードをクリックします。右側の パラメーター設定 タブで、実行タイムウィンドウ パラメーターをデフォルトの
(-31,0]から(-8,0]に変更します。-
5_rec_sln_demo_item_table_preprocess_all_feature_v2 -
6_rec_sln_demo_user_table_preprocess_all_feature_v2
-
-
-
SQL スクリプトを変更して、ユーザーのサブセットを選択します。
-
2_rec_sln_demo_behavior_table_preprocess_ v2ノードをクリックします。右側の パラメーター設定 タブで、SQL スクリプト パラメーターの 32 行目をWHERE ds = '${pai.system.cycledate}'からWHERE ds = '${pai.system.cycledate}' and user_id %10=1に変更します。 -
3_rec_sln_demo_user_table_preprocess_v2ノードをクリックします。右側の パラメーター設定 タブで、SQL スクリプト パラメーターの 38 行目をWHERE ds = '${pai.system.cycledate}'からWHERE ds = '${pai.system.cycledate}' and user_id %10=1に変更します。
-
-
ビジュアルモデリングキャンバス上部のツールバーにある実行ボタン
 をクリックします。
をクリックします。 -
ワークフローの実行が完了したら、以下の MaxCompute テーブルに過去 30 日分のデータが格納されていることを確認します。
-
アイテム特徴量テーブル:
rec_sln_demo_item_table_preprocess_all_feature_v2 -
ワイド動作ログテーブル:
rec_sln_demo_behavior_table_preprocess_v2 -
ユーザー特徴量テーブル:
rec_sln_demo_user_table_preprocess_all_feature_v2
前述のテーブルのデータは、SQL クエリページで照会できます。詳細については、「DataWorks を使用した接続」をご参照ください。
説明プロジェクトでは、パーティションテーブルに対する全表スキャンが禁止されています。クエリには必ずパーティション条件を指定してください。やむを得ず全表スキャンが必要な場合は、SQL ステートメントの前に
set odps.sql.allow.fullscan=true;を追加し、両方を同時に実行してください。全表スキャンでは多くのデータが読み込まれるため、コストが高くなる可能性があります。 -