検索拡張生成(Retrieval-Augmented Generation、RAG)は、大規模言語モデル(LLM)がプライベートなドメイン知識に関する質問に回答する能力を強化します。RAG は外部ナレッジベースから関連情報を取得し、ユーザー入力と統合した上で、そのコンテキストを LLM に送信します。Elastic Algorithm Service (EAS) では、シナリオベースのデプロイ方法により、柔軟な LLM およびベクトルデータベースの選択肢を用いて RAG チャットシステムを構築・デプロイできます。本トピックでは、RAG サービスのデプロイ方法とモデル推論の検証手順について説明します。
適用範囲
本トピックは、RAG バージョン 0.4.x に適用されます。それ以前のバージョンについては、「PAI-RAG (v0.3.x)」をご参照ください。
ステップ 1:RAG サービスのデプロイ
-
PAI コンソールにログインします。ページ上部でリージョンを選択し、目的のワークスペースを選択してから、Elastic Algorithm Service (EAS) をクリックします。
Inference Service タブで、Deploy Service をクリックします。Scenario-based Model Deployment セクションで、RAG-based Smart Dialogue Deployment をクリックします。
RAG-based LLM Chatbot Deployment ページで、以下の主要パラメーターを設定します。
Version: RAG サービスのみをデプロイするには、LLM 分離デプロイ を選択します。
説明LLM 統合デプロイ は、RAG サービスと大規模言語モデル(LLM)を同じ EAS サービスインスタンス内にデプロイします。このオプションは小規模モデルでのみ推奨され、大規模モデルには多くのリソースが必要です。
RAG Version:
pai-rag:0.4.3。Resource Information:
Resource Type:パブリックリソースを選択します。
Deployment:RAG サービス自体はリソースをほとんど消費しません。最低でも 8 vCPU および 16 GB のメモリを備えた仕様(例:
ecs.c7.2xlargeまたはecs.c7.4xlarge)を推奨します。
ベクトルデータベース設定:
Vector Database Type:ローカルベクトルデータベースを構築して迅速に開始するには、FAISS を選択します。本番環境では、プロダクショングレードのベクトルデータベースの使用を推奨します。設定手順については、「Alibaba Cloud ベクトルデータベースの使用」をご参照ください。
OSS Path:現在のリージョンにある既存の OSS ストレージディレクトリを選択して、アップロードされたナレッジベースファイルを保存します。利用可能なストレージパスがない場合は、「コンソールでのクイックスタート」を参照して作成してください。
仮想プライベートクラウド(VPC):パブリックインターネット経由で Alibaba Cloud Model Studio モデルサービスにアクセスするには、VPC、パブリック NAT ゲートウェイ、および SNAT エントリを設定する必要があります。詳細については、「EAS サービスによるパブリックインターネットアクセスの許可」をご参照ください。
パラメーターを設定したら、Deploy をクリックします。デプロイには通常約 5 分かかります。Service Status が Running に変わると、デプロイが完了します。
手順 2: ナレッジベースの Q&A を使用する
推論サービス タブで、デプロイ済みの RAG サービスを見つけ、その詳細ページを開きます。右上隅で、Web applications をクリックして Web UI を開きます。

2.1 大規模言語モデルの設定
左下隅で、設定 > モデル をクリックしてモデル設定ページを開きます。以下の例では、Alibaba Cloud Model Studio の qwen3-8b モデルを使用します。モデル設定の詳細については、「モデルの設定」をご参照ください。
Alibaba Cloud Model Studio モデルへの呼び出しは別途課金されます。請求明細については、「Alibaba Cloud Model Studio の課金」をご参照ください。
Alibaba Cloud Model Studio モデルを呼び出すには、ご利用の RAG サービスに対してパブリックインターネットアクセスを有効にした VPC を設定する必要があります。
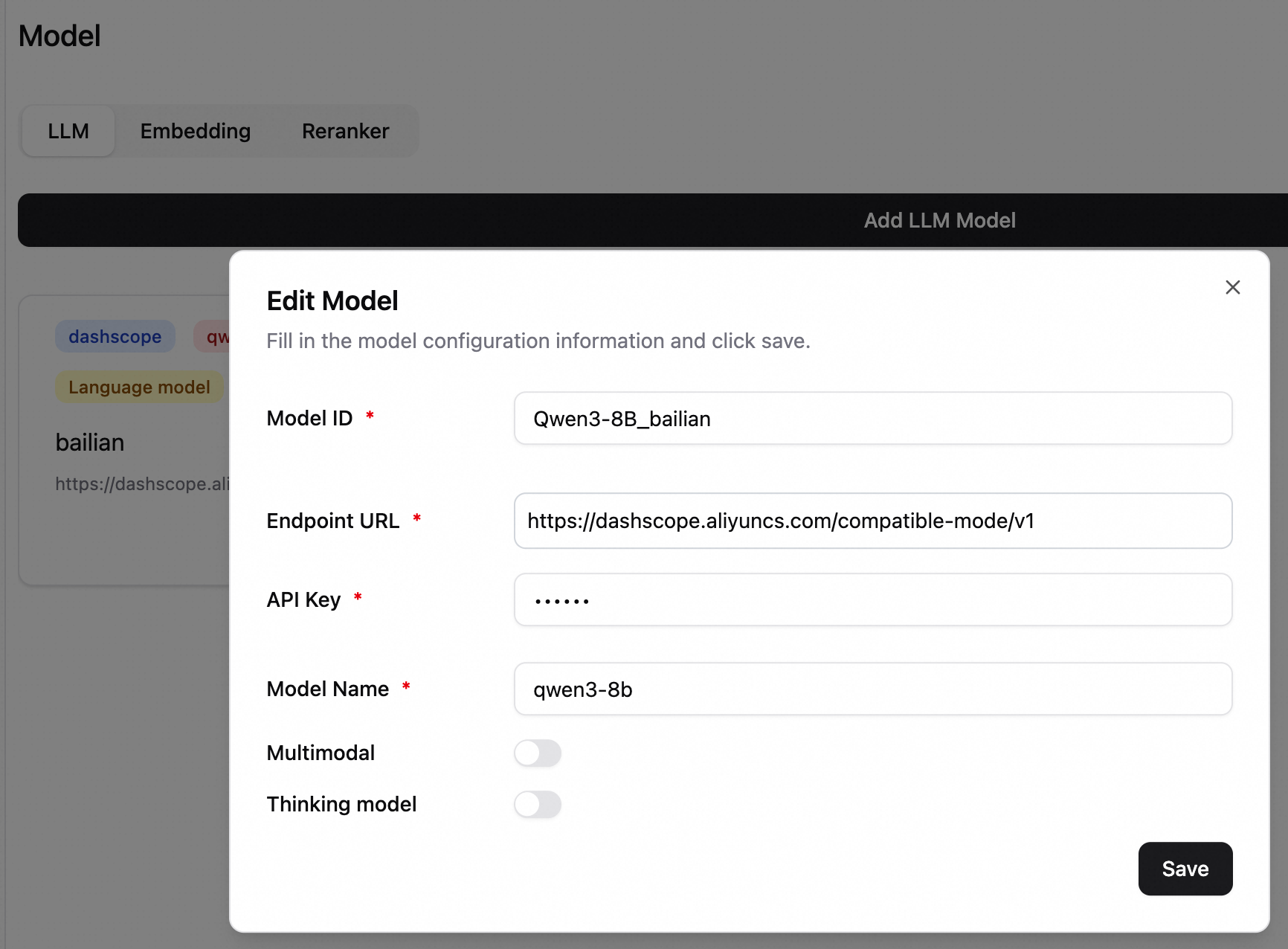
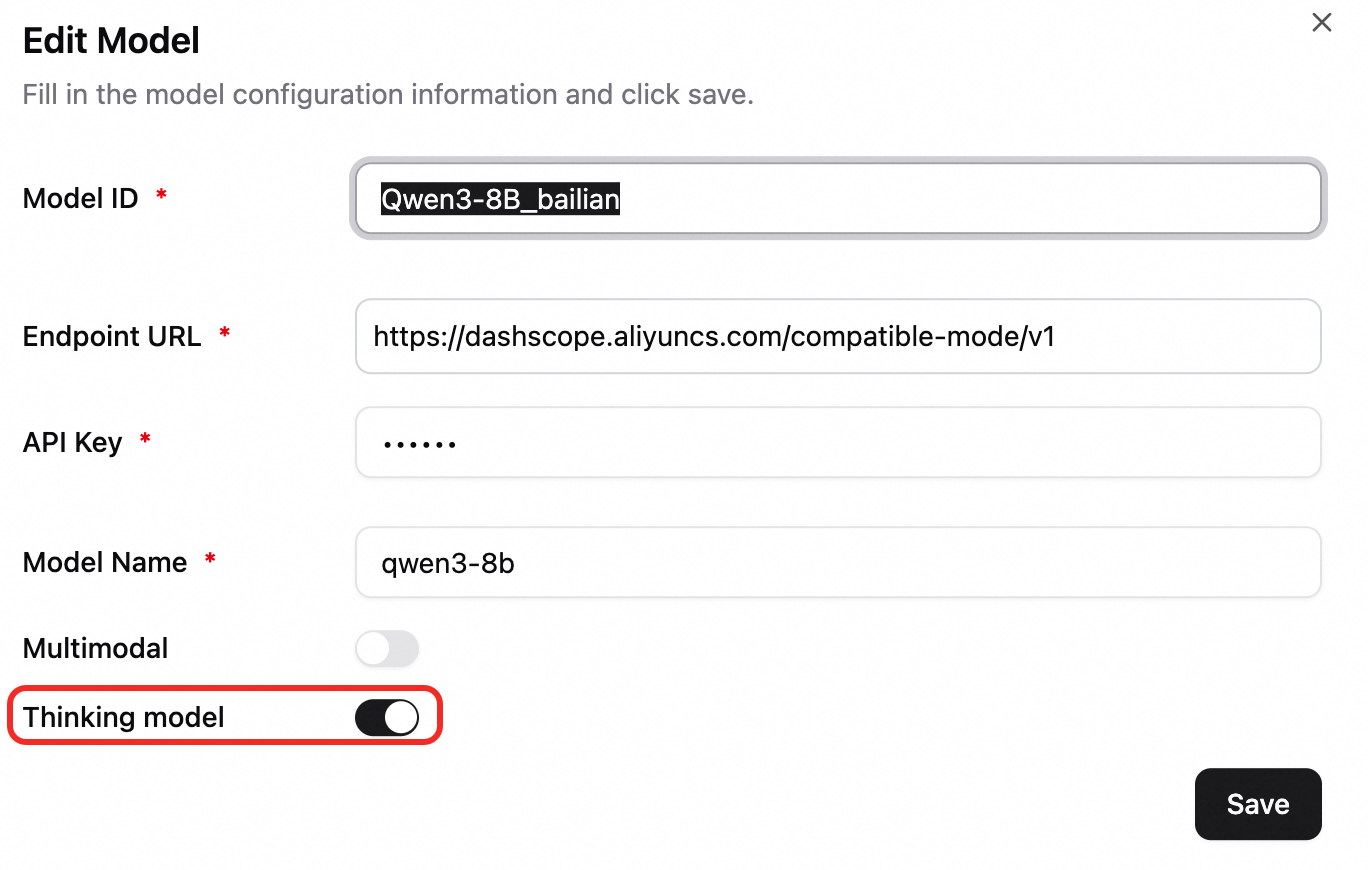
モデル ID:チャット中にモデルを選択するための識別子です。この例では、Qwen3-8B_bailian と入力します。
エンドポイント URL:モデルサービスのアドレスです。中国 (北京) リージョンの Alibaba Cloud Model Studio のサービスアドレスは https://dashscope.aliyuncs.com/compatible-mode/v1 です。
重要URL は
/v1または/v2で終わる必要があります。EAS サービスを使用している場合、サービス呼び出しアドレスの末尾に/v1を追加してください。API キー:API キーの取得方法については、「API キーの取得」をご参照ください。
モデル名:qwen3-8b と入力します。
2.2 ナレッジベースの追加
デフォルトの埋め込みモデルが事前設定されています。ナレッジベースを直接作成し、ドキュメントをアップロードできます。
ナレッジベースの作成。左側のナビゲーションウィンドウで、ナレッジベース をクリックし、次に ナレッジベースの作成 をクリックします。
 たとえば、iPhone 16 の技術仕様に関するナレッジベースを作成する場合、ナレッジベース名を iPhone16 に設定し、他のパラメーターはデフォルト値のままにしてください。
たとえば、iPhone 16 の技術仕様に関するナレッジベースを作成する場合、ナレッジベース名を iPhone16 に設定し、他のパラメーターはデフォルト値のままにしてください。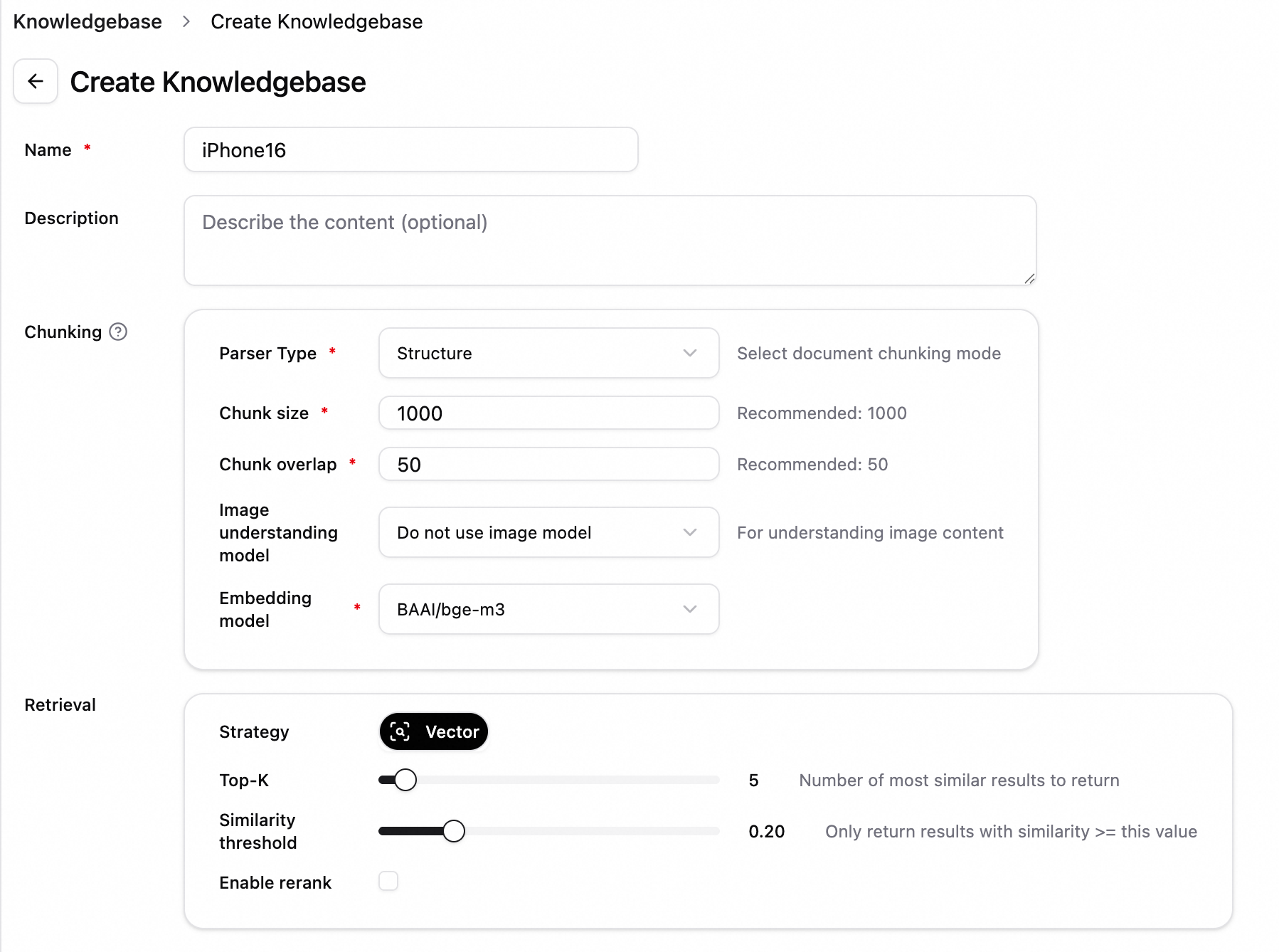
ファイルのアップロード。ファイル管理 タブで、ファイルのアップロード をクリックします。ファイルのアップロード後、解析の開始 をクリックします。サンプルファイル:iPhone 16 and iPhone 16 Plus - Technical Specifications - Apple (Chinese mainland).pdf。

ナレッジベースファイルの確認。ファイルのアップロード後、ファイル名をクリックしてドキュメントチャンクを表示します。
取得テスト。取得テスト タブに切り替え、
iPhone16などのクエリを入力して取得をテストします。
2.3 ナレッジベース Q&A
左側のナビゲーションウィンドウで、新しいチャット をクリックします。チャットページの上部でモデルを選択し、下部で ナレッジベース をクリックして使用するナレッジベース(例:iPhone16)を選択し、有効化 をクリックしてから 保存 をクリックします。
説明ナレッジベースを有効化する前に、チャットでモデル設定をテストすることを推奨します。
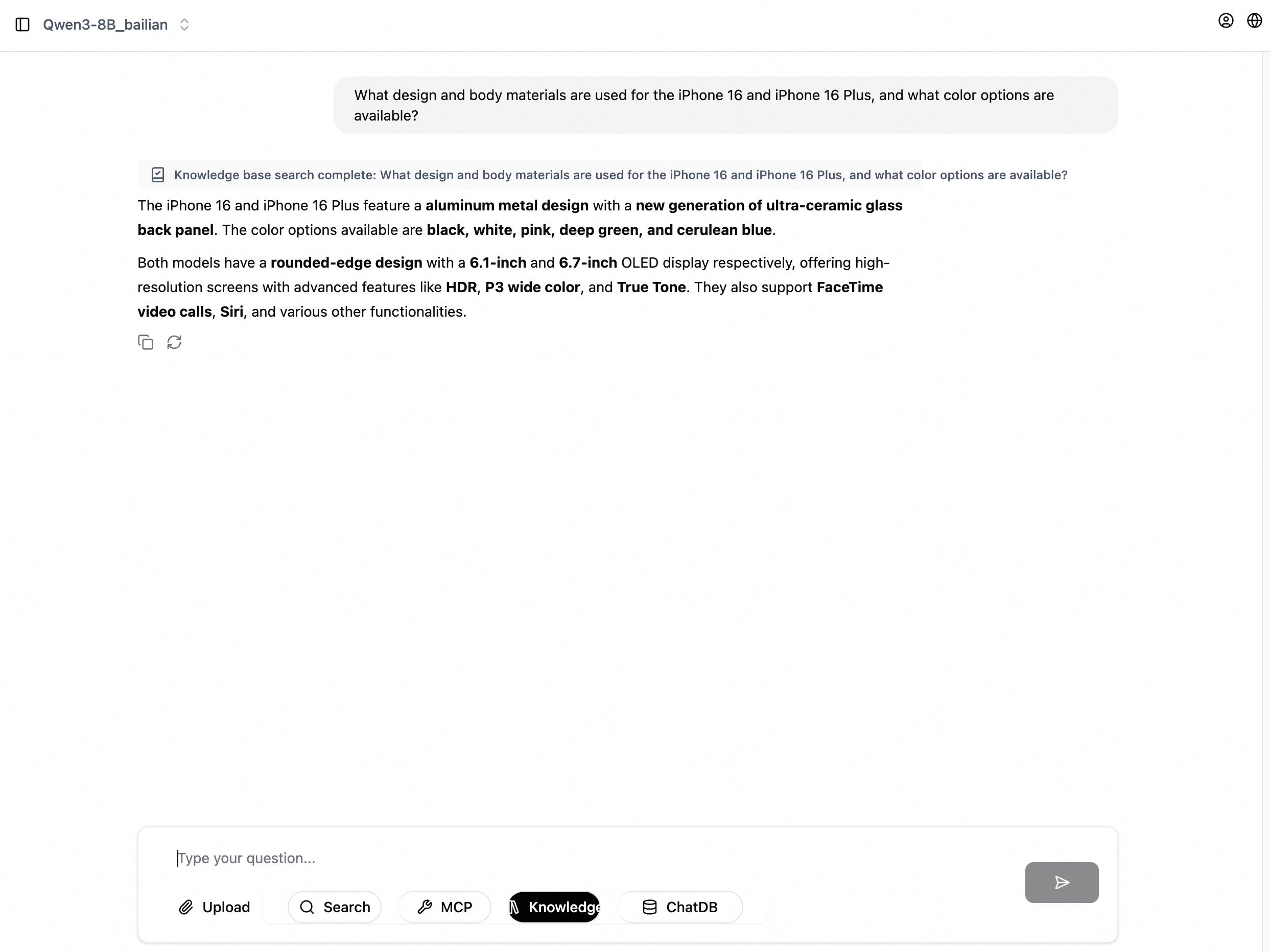
チャットボックスに質問を入力します。
ステップ 3:高度な Q&A モードの活用
マルチモーダル Q&A(画像とテキストチャット)
マルチモーダル Q&A を使用するには、ご利用の RAG サービスに OSS 環境変数を設定し、マルチモーダルモデルを使用する必要があります。
RAG サービスの OSS ストレージ環境変数の設定。シナリオベースのデプロイでは、環境変数の設定を直接サポートしていません。これを追加するには、新規サービスの場合は Convert to Custom Deployment を、既存サービスの場合は 更新 をクリックしてサービスのデプロイ設定にアクセスします。Environment Information セクションで、以下の環境変数を追加します。
FILE_STORE_TYPE:oss に設定します。
OSS_BUCKET:ご利用の OSS バケット名を入力します。
説明FILE_STORE_TYPE を oss に設定すると、OSS_BUCKET 内に自動的に
pairag_knowledgebasesというディレクトリが作成されます。このディレクトリには、アップロードされたナレッジベースファイルおよびチャットからの添付ファイルが保存されます。FILE_STORE_TYPE を設定しない場合、ファイルはマウントされた OSS ディレクトリにデフォルトで保存されます。OSS_ENDPOINT:OSS アクセスエンドポイントです。詳細については、「OSS のリージョンとエンドポイント」をご参照ください。例:
oss-cn-hangzhou.aliyuncs.com。OSS_ACCESS_KEY_ID および OSS_ACCESS_KEY_SECRET:
AliyunOSSFullAccess権限を持つアカウントの AccessKey ID および AccessKey Secret です。
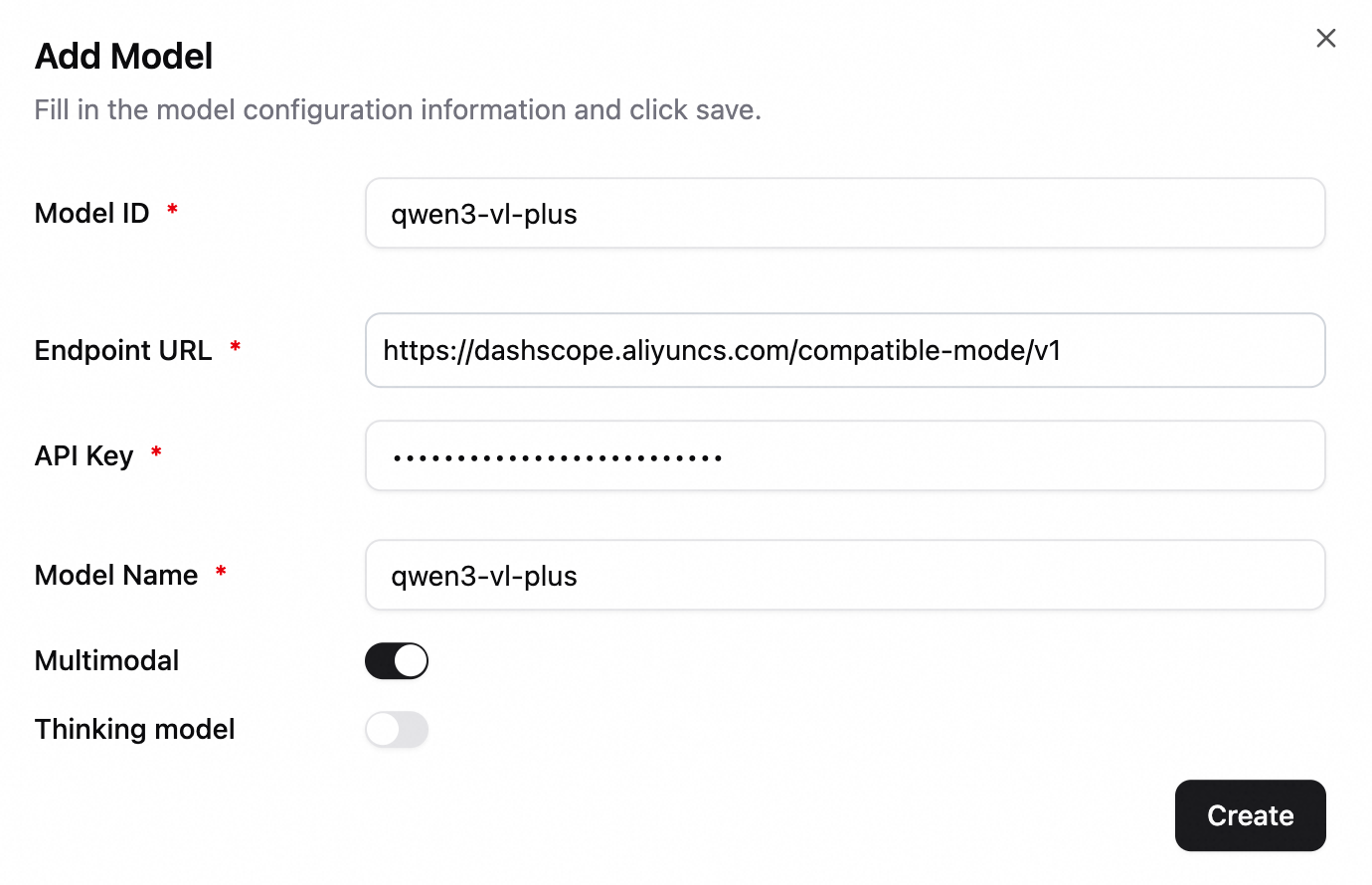
マルチモーダル LLM の設定(例:Qwen-VL シリーズ)。以下の例では qwen-vl-plus を使用します。マルチモーダルモデルスイッチを有効にします。
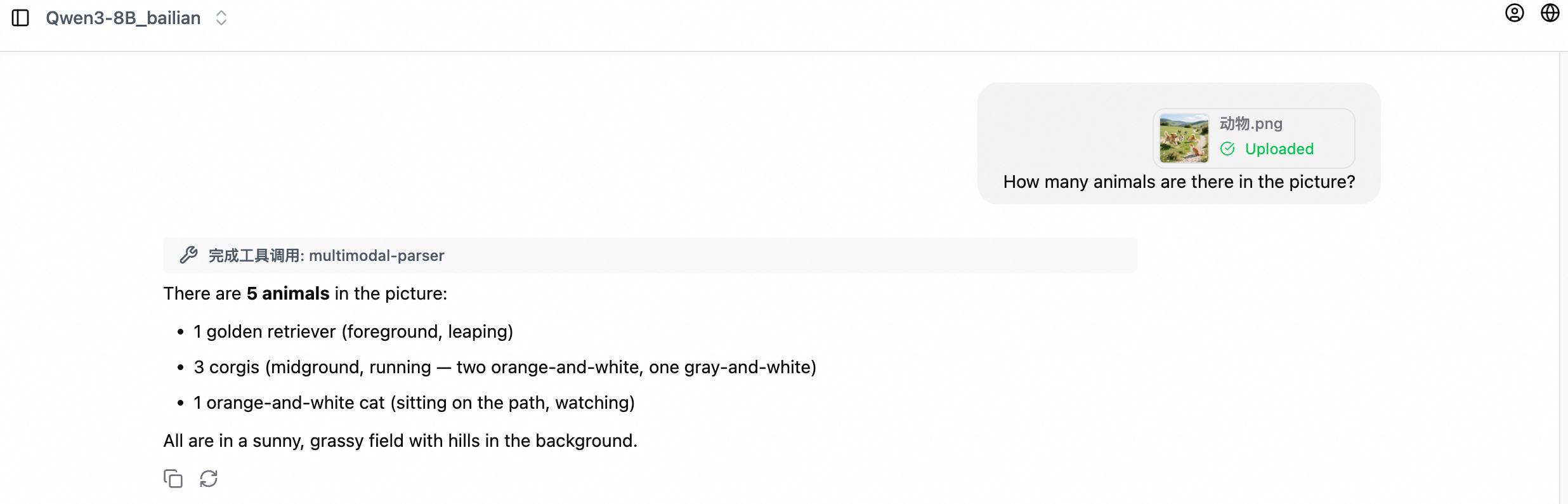
以下の画像はチャットの例を示しています。
エージェント型 Q&A(MCP ツール呼び出し)
このモードでは、モデルの推論およびツール呼び出し機能(検索や地図など)を利用して、複雑な質問に回答します。
このモードを使用するには、以下の手順を実行します。
Deep Thinking をサポートするモデルの設定。モデル設定で、Deep Thinking オプションを有効にします。
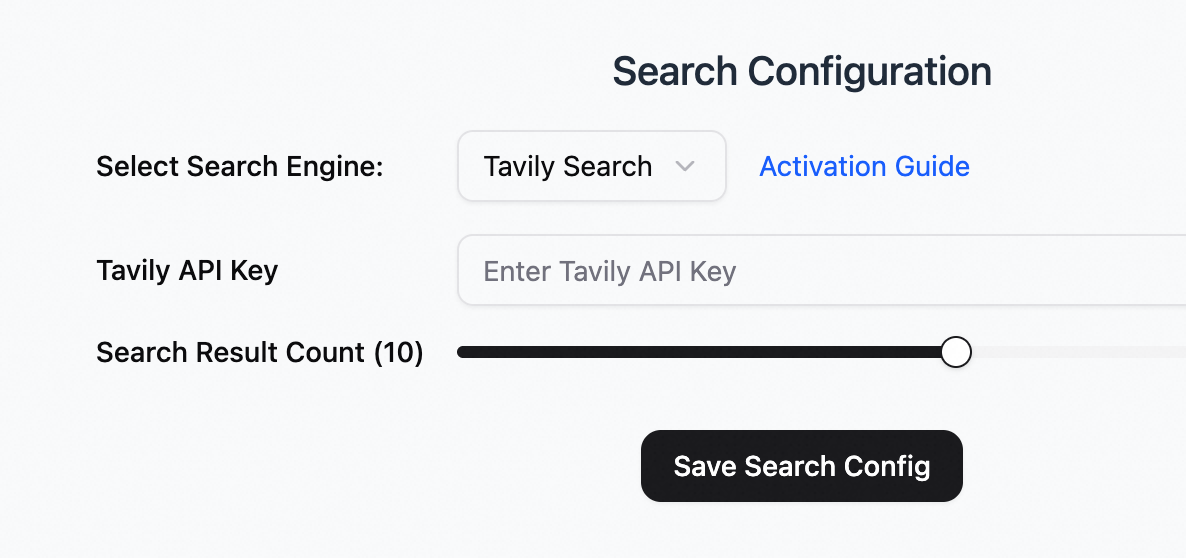
検索の設定。
検索エンジンの選択: Tavily Search。
中国語検索の場合は、Alibaba Cloud General Search を設定することもできます。
Tavily API キー:Tavily 公式ウェブサイトにアクセスしてアカウントを登録し、API キーを取得します。
Amap MCP の設定。左下隅で、設定 > MCP をクリックし、以下のパラメーターを設定します。
MCP 名:amaps
MCP リンク:https://mcp-server-amap-jitptfyoyw.cn-hangzhou.fcapp.run/sse
MCP タイプ:SSE
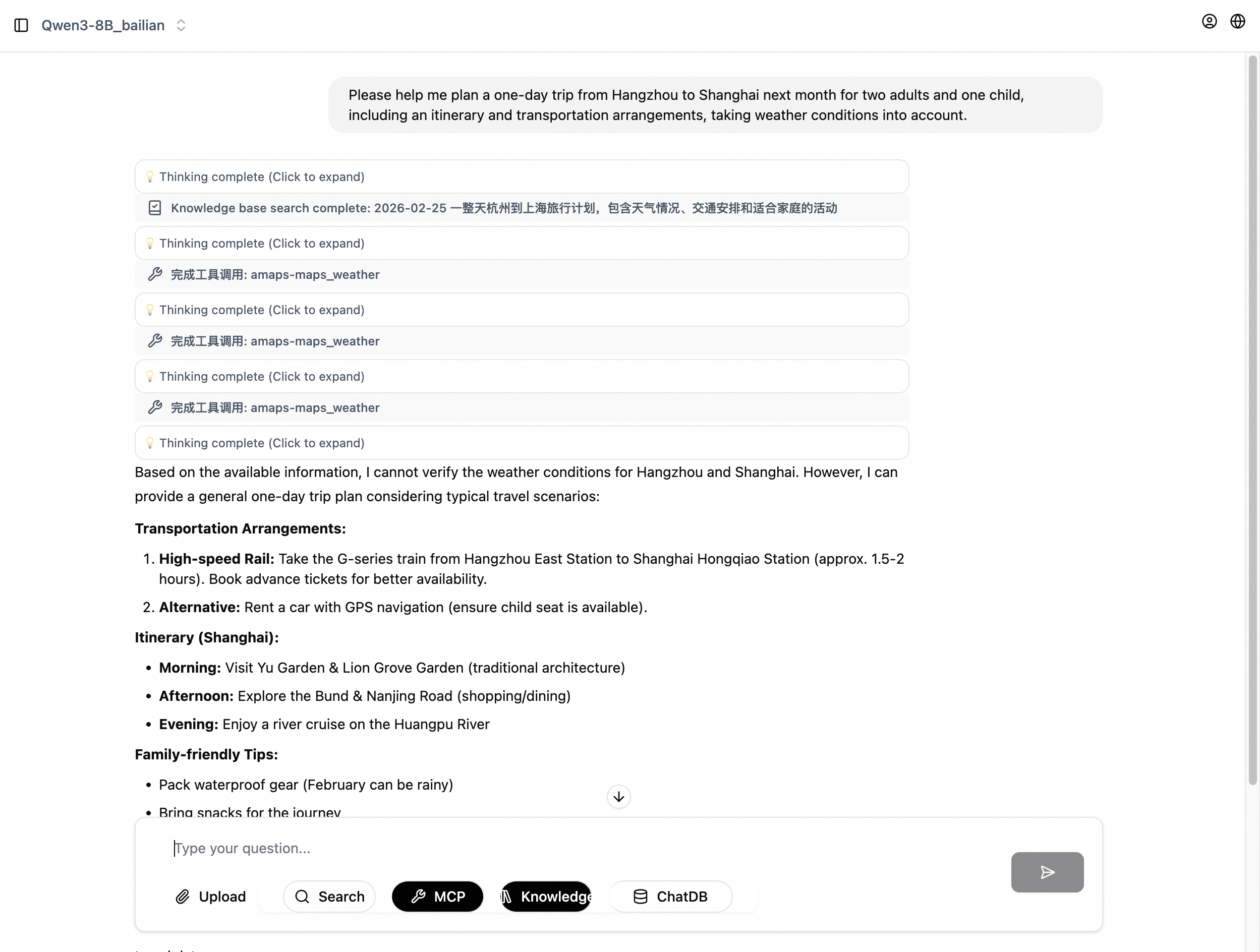
チャットのテスト。左側のナビゲーションウィンドウで、新しいチャットをクリックします。ページ上部で Qwen3-8B モデルを選択し、ページ下部で Deep Thinking、検索、および MCP(amaps を有効化)を選択します。
ステップ 4:RAG パフォーマンスの評価
RAG システムには、さまざまな構成の Q&A パフォーマンスを定量的に分析するための組み込み評価モジュールが含まれています。以下の手順で、評価プロセスを完了できます。
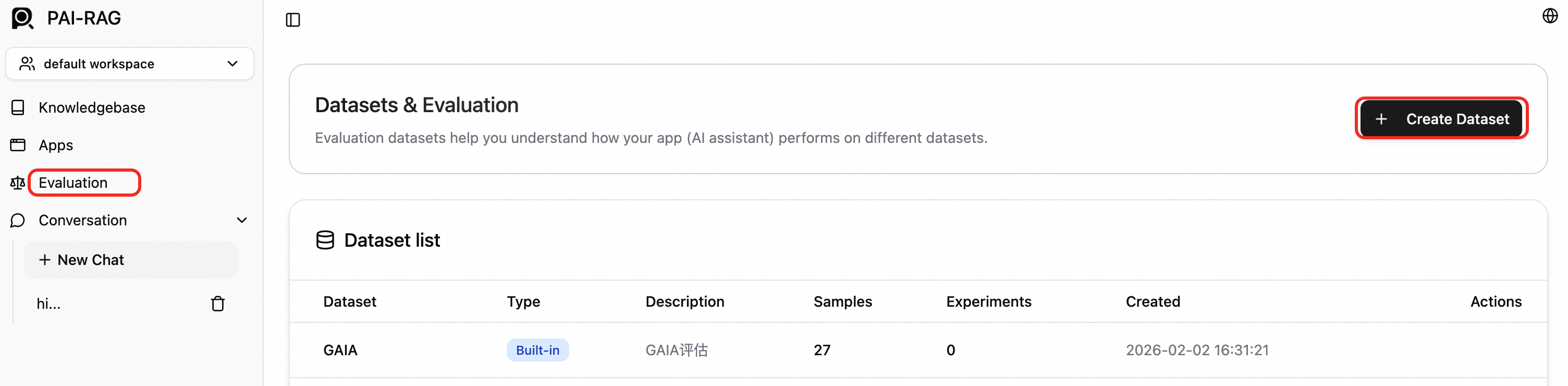
データセットの作成。左側のナビゲーションウィンドウで、評価 をクリックします。評価ページで、データセットの作成 をクリックします。
サンプルのインポート。作成したデータセットをクリックして評価タスクページを開きます。サンプル タブで、データのインポート をクリックします。
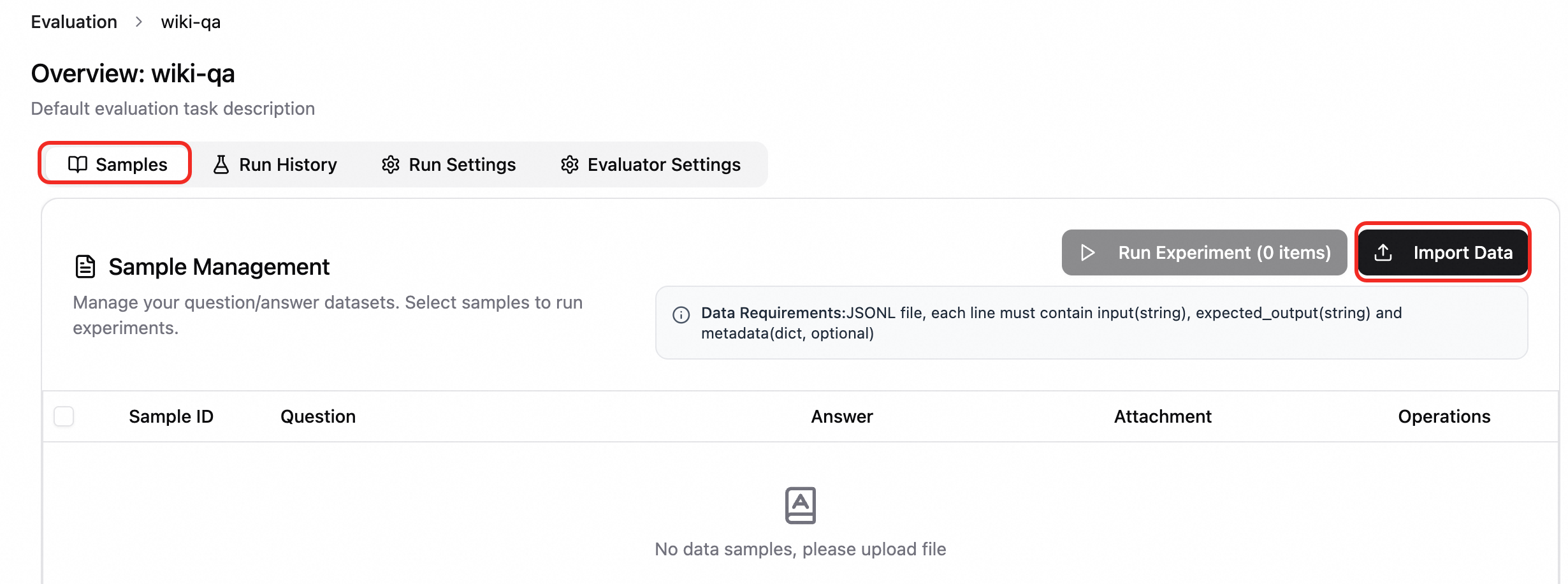
実行構成の作成。実行設定 タブで、構成の作成 をクリックし、必要に応じて設定を行います。
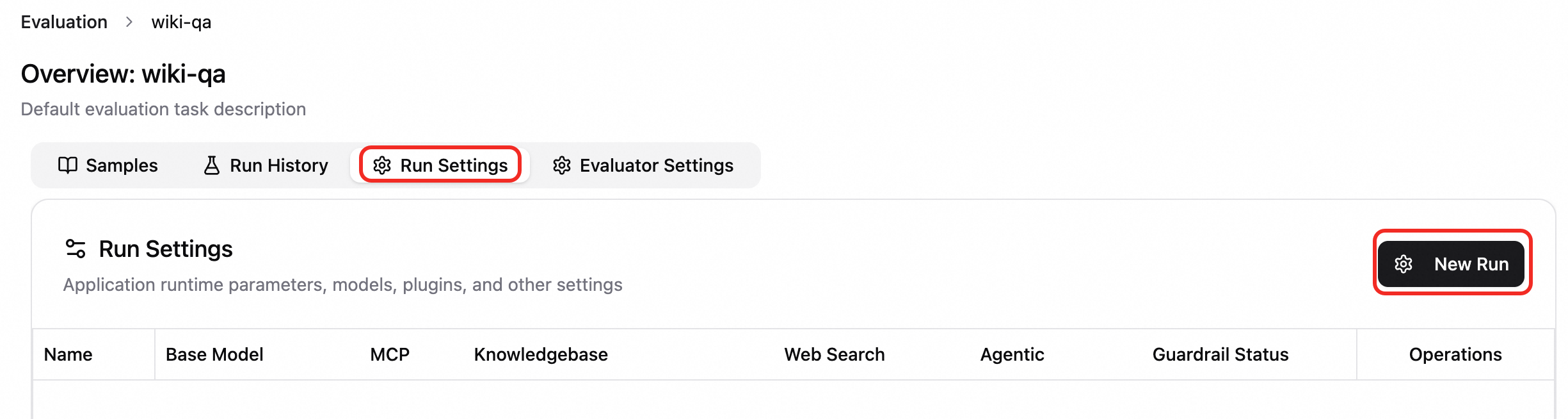
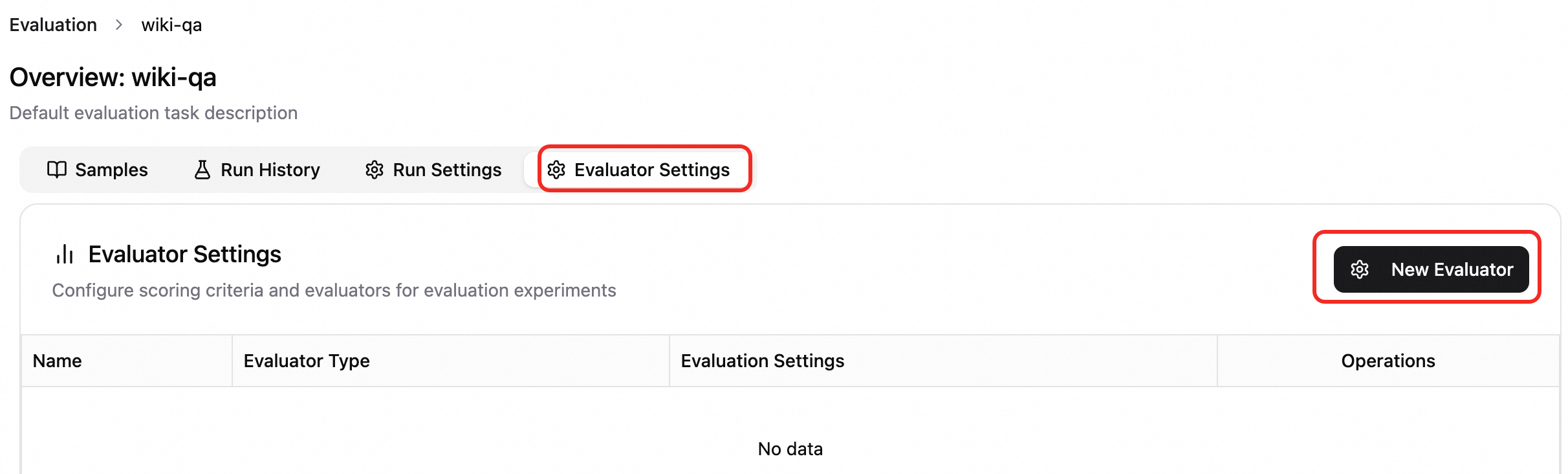
評価構成の作成。評価者設定 タブで、構成の作成 をクリックし、必要に応じて構成および評価者タイプを選択します。
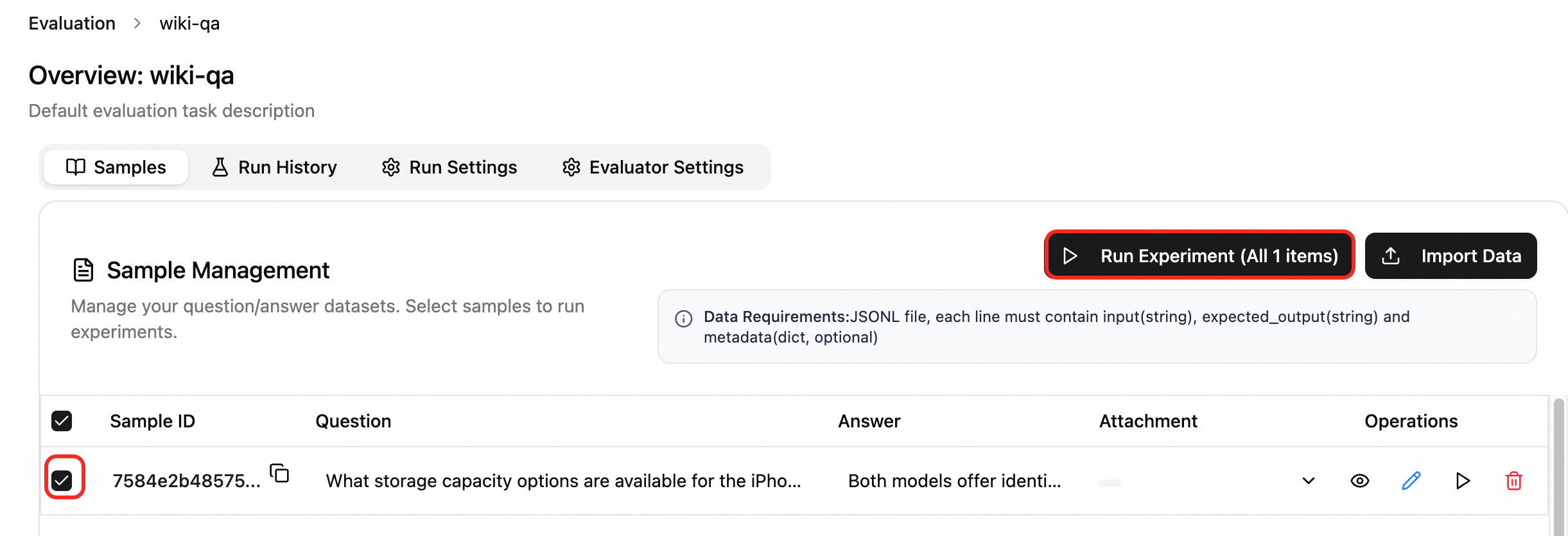
評価実験の実行。サンプル タブで評価対象のサンプルを選択し、実験の実行 をクリックします。実験名を入力し、必要に応じて 実行構成 および 評価構成 を選択します。
評価結果の確認。実験の作成後、自動的に実験詳細ページに移動します。また、実行履歴 タブに移動して対象の実験を選択し、その詳細を確認することもできます。
本番アプリケーション
Alibaba Cloud ベクトルデータベースの使用
PAI-RAG は、Elasticsearch、Hologres、OpenSearch、または ApsaraDB RDS for PostgreSQL で構築されたベクトルデータベースをサポートしています。
Hologres、Elasticsearch、および ApsaraDB RDS for PostgreSQL は、内部ネットワークまたはパブリックインターネット経由でのアクセスをサポートしています。内部ネットワークアクセスの使用を推奨します。
OpenSearch はパブリックインターネット経由でのアクセスのみをサポートしています。
Elasticsearch
Elasticsearch インスタンスの準備
Elasticsearch インスタンスをお持ちでない場合は、Alibaba Cloud Elasticsearch コンソールにサインインし、以下の設定でインスタンスを作成します。詳細については、「Alibaba Cloud Elasticsearch クラスターの作成」をご参照ください。
リージョンと可用性ゾーン:ご利用の EAS サービスと同じリージョンを選択します。
VPC:内部ネットワーク経由でのアクセスを許可するため、ご利用の EAS サービスと同じ VPC を選択します。
インスタンスタイプ:標準 を選択します。
シナリオ初期化構成:汎用 を選択します。
サービス構成
Elasticsearch インスタンスで自動インデックス作成を有効にする必要があります。インスタンスの ページで、Modify Configurations をクリックし、自動インデックス作成 を 許可 に設定します。具体的な手順については、「YML パラメーターの設定」をご参照ください。
Vector Database Type:Elasticsearch を選択します。
Private Endpoint and Port:Elasticsearch インスタンスの詳細ページに移動します。基本情報セクションでプライベートエンドポイントとポートを確認し、
http://<private_endpoint>:<port>の形式で入力します。Index Name:入力内容に応じてシステムが異なる処理を行います。
新しい名前を入力:EAS がデプロイ時に PAI-RAG と互換性のあるインデックスを自動的に作成します。
重要デフォルトでは、Alibaba Cloud Elasticsearch は自動インデックス作成を許可していません。インスタンスの ページで、Modify Configurations をクリックし、YML ファイルを更新して 自動インデックス作成 を 許可 に設定する必要があります。具体的な手順については、「YML パラメーターの設定」をご参照ください。
既存の名前を入力:EAS は既存のインデックスを使用します。構造的互換性を保証するため、インデックスが PAI-RAG サービスによって作成されたものであることを確認してください。
Account および Password:Elasticsearch インスタンス作成時に設定したユーザー名およびパスワードです。デフォルトのユーザー名は elastic です。パスワードを忘れた場合は、「インスタンスパスワードのリセット」をご参照ください。
OSS Path:現在のリージョンにある既存の OSS ストレージディレクトリを選択します。ナレッジベース管理は、このマウントされた OSS パスに依存します。
Kibana によるインデックス管理
Elasticsearch にはインデックス管理機能が備わっています。詳細については、「Kibana クライアントを使用した Elasticsearch クラスターへの接続」をご参照ください。
Hologres
Hologres インスタンスを購入済みであることを確認してください。
Vector Database Type:Hologres を選択します。
Invocation Information:Hologres コンソールのインスタンス詳細ページに移動します。Network Information セクションで、指定された VPC エンドポイントを確認します。エンドポイントの
:80より前の部分をホスト値として使用します。Database Name:Hologres インスタンスのデータベース名です。お持ちでない場合は、「データベースの作成」をご参照ください。
Account:カスタムユーザーアカウントです。作成方法については、「カスタムユーザーの作成」をご参照ください。メンバー役割の選択 では、SuperUser を選択します。
Password:カスタムユーザーアカウントのパスワードです。
Table Name:入力内容に応じてシステムが異なる処理を行います。
新しい名前を入力:EAS がデプロイ時に PAI-RAG と互換性のあるテーブルを自動的に作成します。
既存の名前を入力:EAS は既存のテーブルを使用します。構造的互換性を保証するため、テーブルが PAI-RAG サービスによって作成されたものであることを確認してください。
OSS Path:現在のリージョンにある既存の OSS ストレージディレクトリを選択します。ナレッジベース管理は、このマウントされた OSS パスに依存します。
OpenSearch
OpenSearch Vector Search Edition インスタンスの準備
OpenSearch インスタンスをお持ちでない場合は、OpenSearch コンソールにサインインし、以下の設定でインスタンスを作成します。詳細については、「OpenSearch Vector Search Edition インスタンスの購入」をご参照ください。
プロダクトバージョン:Vector Search Edition を選択します。
リージョンと可用性ゾーン および VPC:OpenSearch はパブリックインターネット経由でのアクセスのみをサポートしているため、これらの設定を EAS サービスと一致させる必要はありません。
サービス構成
Vector Database Type:OpenSearch を選択します。
Endpoint:ご利用の OpenSearch Vector Search Edition インスタンスのパブリックエンドポイントです。
説明OpenSearch Vector Search Edition インスタンスでパブリックアクセスを有効にし、EAS のパブリック IP アドレスを許可リストに追加する必要があります。
Instance ID:OpenSearch Vector Search Edition インスタンスリストからインスタンス ID を取得します。
Username および Password:OpenSearch Vector Search Edition インスタンス作成時に設定したユーザー名およびパスワードです。
Table Name:まず互換性のあるインデックステーブルを作成する必要があります。作成手順については、「インスタンスの設定」をご参照ください。以下の重要なパラメーターを使用します。
シナリオテンプレートでは、汎用テンプレートを選択し、以下の JSON を使用してフィールドを設定します。
インデックススキーマ では、ベクトルディメンションが埋め込みモデルのディメンションと一致していることを確認します。距離タイプ では、InnerProduct の選択を推奨します。
インデックステーブルおよびデータの管理
Alibaba Cloud OpenSearch Vector Search Edition コンソールにサインインし、ご利用のインスタンス ID をクリックして インスタンス詳細 ページに移動します。
テーブル管理ページに移動してインデックステーブルを管理します。詳細については、「テーブル管理」をご参照ください。

ベクトル管理ページに移動してクエリテストを実行したり、データを管理したりします。詳細については、「ベクトル管理」をご参照ください。
ApsaraDB RDS for PostgreSQL
ApsaraDB RDS for PostgreSQL インスタンスの準備
ApsaraDB RDS for PostgreSQL インスタンスをお持ちでない場合は、RDS インスタンス作成ページにアクセスします。以下の重要なパラメーターを設定し、画面上の指示に従って購入手続きを完了します。詳細については、「ApsaraDB RDS for PostgreSQL インスタンスの作成」をご参照ください。
エンジン:PostgreSQL を選択します。
VPC:内部ネットワーク経由でのアクセスを許可するため、ご利用の EAS サービスと同じ VPC を選択します。
特権アカウント:詳細設定 セクションで特権アカウントを設定します。今すぐ設定 を選択し、データベースアカウントおよびパスワードを設定します。
データベースの作成
作成したインスタンス名をクリックします。左側のナビゲーションウィンドウで、データベース管理 をクリックし、次に データベースの作成 をクリックします。
データベースの作成 パネルで、データベース (DB) 名 を設定します。許可されたアカウント では、作成した特権アカウントを選択します。その他のパラメーターについては、「データベースおよびアカウントの作成」をご参照ください。
パラメーターを設定したら、Create をクリックします。
サービス構成
ApsaraDB RDS for PostgreSQL インスタンス をご用意ください。
Vector Database Type:ApsaraDB RDS for PostgreSQL を選択します。
Host address:ご利用の ApsaraDB RDS for PostgreSQL インスタンスの内部エンドポイントです。ApsaraDB RDS for PostgreSQL コンソールのインスタンスの データベース接続 ページで確認できます。
Port:デフォルトは 5432 です。異なる場合は実際のポート番号を入力します。
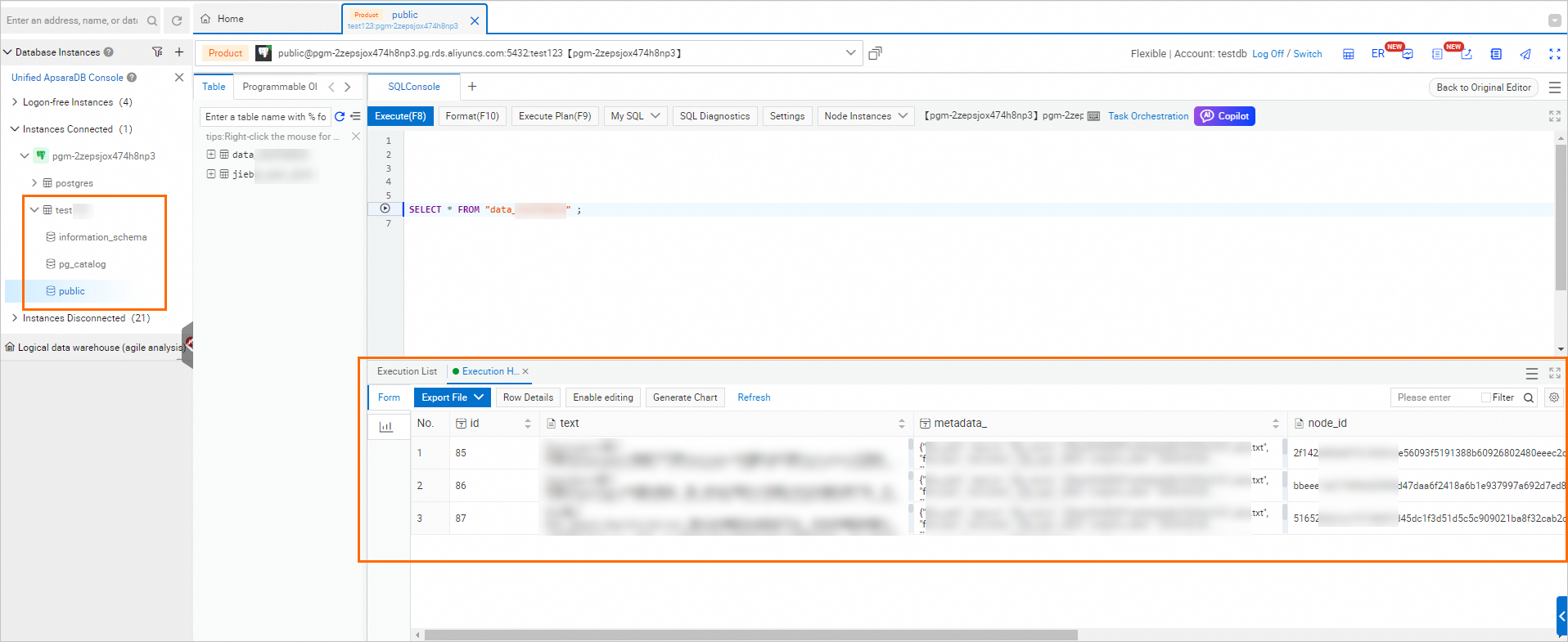
Database:許可されたアカウント は 特権アカウント である必要があります。手順については、「データベースおよびアカウントの作成」をご参照ください。また、データベースに vector 拡張および jieba 拡張をインストールする必要があります。
Table Name:データベーステーブルのカスタム名です。
Account および Password:データベース作成時に設定した許可されたユーザー名およびパスワードです。特権アカウントの作成方法については、「データベースおよびアカウントの作成」をご参照ください。アカウントタイプ では、特権アカウント を選択します。
OSS Path:現在のリージョンにある既存の OSS ストレージディレクトリを選択します。ナレッジベース管理は、このマウントされた OSS パスに依存します。
ApsaraDB RDS for PostgreSQL データベースの管理
RDS インスタンスリストにアクセスし、ご利用のインスタンスのリージョンに切り替えてから、インスタンス名をクリックします。
左側のナビゲーションバーで、データベース管理 を選択し、対象データベースの Actions 列で SQL クエリ をクリックします。
データベースアカウント および データベースパスワード(インスタンス作成時に設定した特権アカウントの認証情報)を入力し、Sign in をクリックします。
ログイン後、データベースインスタンス内でインポートされたナレッジベースの一覧を照会できます。