アプリケーションを本番環境にデプロイする前に、特定のビジネスシナリオにおけるパフォーマンスを評価する必要があります。LangStudio は、評価テンプレートを使用してさまざまなディメンションでアプリケーションをスコアリングする、包括的なアプリケーションフロー評価サービスを提供します。
概要
LangStudio は、ワンストップのアプリケーションフロー評価機能を提供します。評価データセットやアプリケーションフローの入力マッピングなどの設定を行い、必要に応じて 評価テンプレート を選択するだけで、評価タスクを送信できます。評価プロセス全体では、まずアプリケーションで評価データセットの各行をバッチ処理して対応する出力を取得します。次に、評価データセットの補助フィールドを使用して各出力の品質を評価します。最後に、スコアを集計して、指定されたデータセットに対するアプリケーションの精度を表示します。

事前準備
アプリケーションフローを作成し、デバッグします。詳細については、「アプリケーションフローの開発」をご参照ください。
評価データセットを準備し、Object Storage Service (OSS) にアップロードします。ファイルは JSON Lines (JSONL) フォーマットである必要があります。次のコードはサンプルです。
{"history":[],"query": "Describe the perilous majesty of Mount Hua", "reference": "Mount Hua stands alone, soaring to the clouds; \nSheer cliffs cut the sky, with rugged, handsome crags. \nGreen pines and bamboo vie for beauty on the cliffs; \nMonkeys cry and eagles fly, lit by frosty swords of light. \n\nPerilous peaks like scissors, jagged swords pointing to the sky; \nNarrow paths on steep slopes, where vines are the only way. \nWind and mist intertwine, as clouds emerge from caves; \nA deep fairyland, with a heavenly ladder hard to climb. \n\nJagged ridges cross, like a surging dragon's spine; \nDangerous paths lead onward, twisting toward the heavens. \nFrom lonely pine tops, eagles strike the vast sky; \nAt the summit of Mount Hua, a majestic and heroic sight.", "contexts": ["Mount Hua is one of the Five Great Mountains of China.", "Mount Hua is famous for its precipitous cliffs."]} {"history":[],"query": "Can you list 5 rare metals? Please rank them by global demand.", "reference": "Rare metals are metallic elements that are scarce in the Earth's crust, unevenly distributed, or difficult to mine. They play a crucial role in high-tech fields and emerging industries. The ranking of global demand can change with time and technological progress, but the following are some rare metals that are typically in high demand. This list is not necessarily ranked by absolute demand, as that can vary at different times.\n\n1. **Cobalt (Co)** - Cobalt is a key component of lithium-ion batteries, especially in electric vehicles and portable electronics. It is also used to manufacture heat-resistant alloys, hard alloys, and catalysts.\n\n2. **Neodymium (Nd)** - Neodymium is a rare-earth metal mainly used to produce strong magnets, such as high-performance permanent magnets. These magnets are widely used in computer hard drives, wind turbines, and the drive motors of electric vehicles.\n\n3. **Lithium (Li)** - Lithium is primarily used to manufacture lithium batteries. As the demand for electric vehicles and portable electronic devices increases, the demand for lithium is rising rapidly.\n\n4. **Silver (Ag)** - Although silver is not as rare as the metals listed above, its industrial demand is huge. It is mainly used in electronics, solar panels, jewelry, and currency manufacturing.\n\n5. **Ruthenium (Ru)** - Ruthenium is a rare precious metal widely used for data storage in hard disk drives and large-capacity servers. It is also used in catalysts and electrochemical cells.\n\nThe demand for these metals is influenced by many factors, such as the global economy, technological development, and policy support. Moreover, as time passes and markets change, other rare metals such as tantalum, indium, rhenium, and other rare-earth metals may also appear on the list of most in-demand rare metals.", "contexts": ["Rare metals are metals with low abundance in the Earth's crust that are complex to mine and extract.", "Lithium (Li): Used in battery manufacturing.", "Cobalt (Co): Used in high-performance alloys and battery manufacturing."]}サンプルファイル: langstudio_eval_demo.jsonl
評価に必要な LLM 接続を作成します。詳細については、「接続の構成」をご参照ください。
注:一部の評価テンプレートはジャッジモデルに依存します。これらのテンプレートには、対応する LLM 接続を構成する必要があります。
課金
アプリケーションフロー評価機能は、Object Storage Service (OSS) を使用して評価データセットを保存し、Platform of Artificial Intelligence-Deep Learning Containers (PAI-DLC) を使用してオフライン評価タスクを実行します。これらのリソースの使用に対して課金されます。詳細については、「OSS の課金」および「Deep Learning Containers (DLC) の課金」をご参照ください。
評価タスクの作成
開発ページでアプリケーションをデバッグした後、右上隅の [評価] をクリックして評価タスクを作成します。
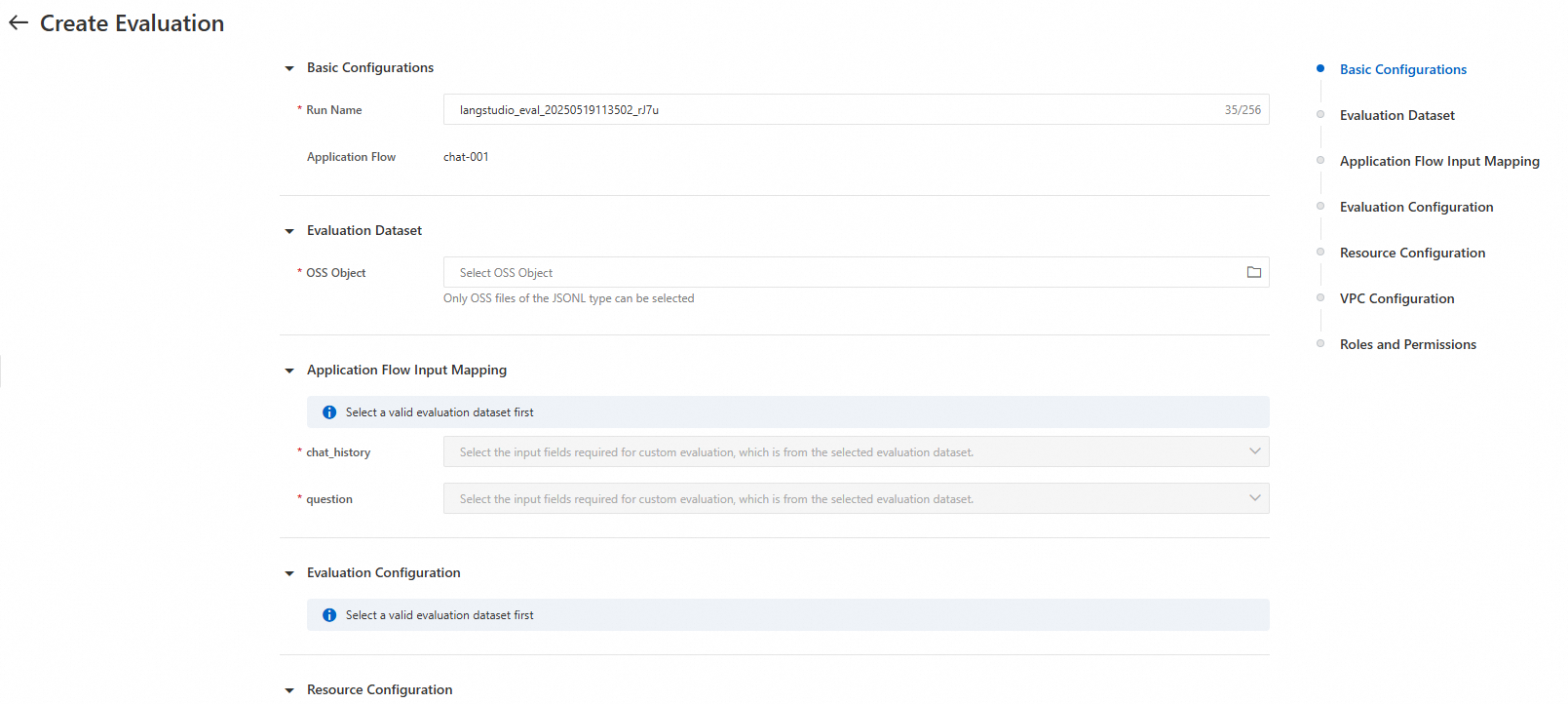
次の表に、主要なパラメーターを示します。
パラメーター | 説明 |
評価データセット | |
OSS ファイル | OSS から JSONL ファイルを選択して、評価データセットとして使用します。データセットには、アプリケーションフローの入力として機能する `question` フィールドと、評価に必要なその他のフィールドが含まれている必要があります。システムは、追加のフィールドを使用してメトリックスコアを算出します。詳細については、「付録:プリセット評価テンプレート」の「入力フィールド」セクションをご参照ください。 |
アプリケーションフローの入力マッピング | |
question/chat_history | アプリケーションの入力フィールドを選択します。 注:評価タスクは、まずアプリケーションを実行して推論を行い、その結果を評価します。そのため、アプリケーションの実行に必要な入力フィールドを選択する必要があります。
|
評価の構成 | |
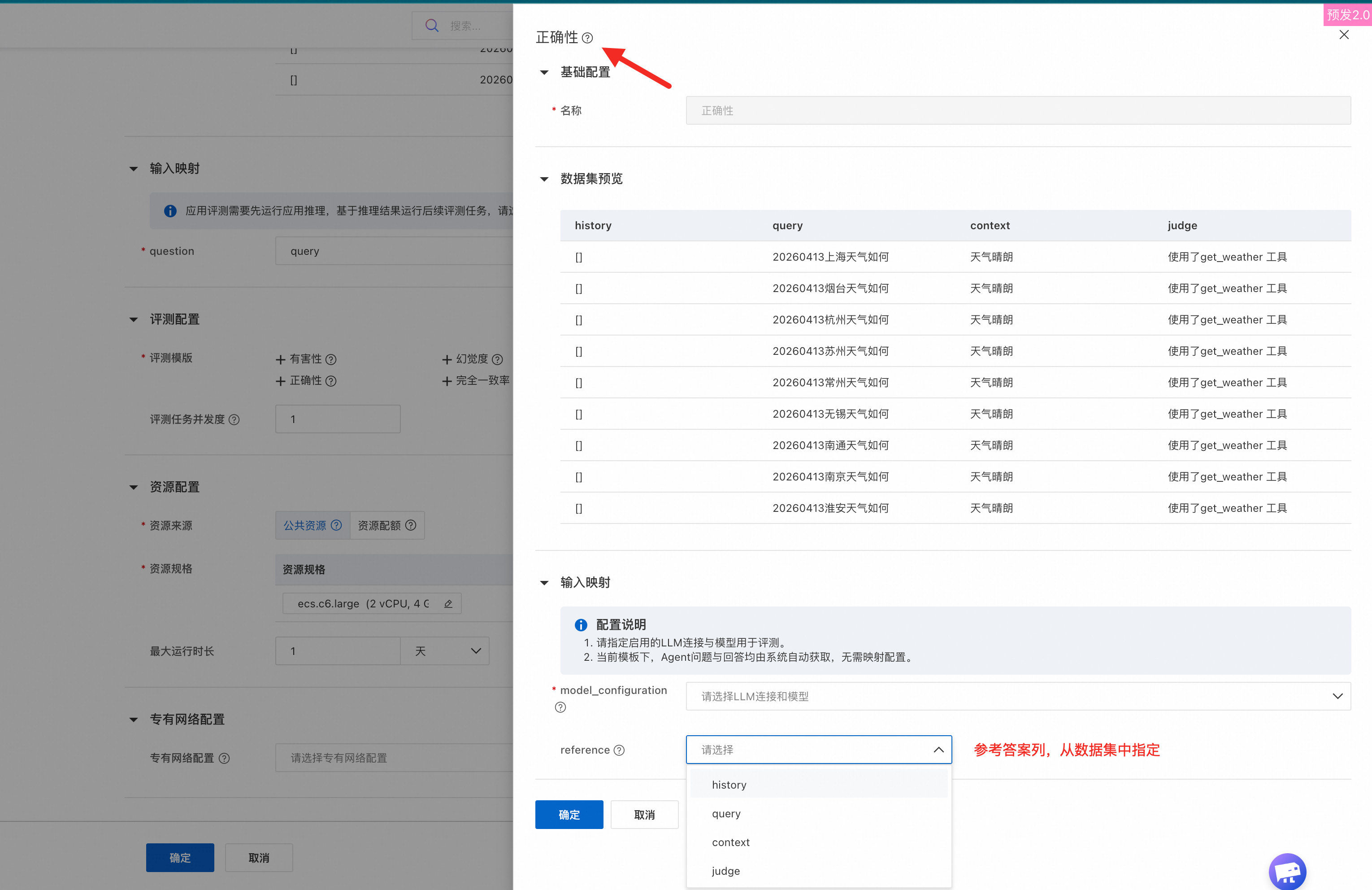
プリセットテンプレート評価 | システムには、複数のプリセット評価テンプレートが用意されています。複数のテンプレートを選択した場合、評価結果はタスク詳細ページで集計されます。このトピックでは、[回答の正しさの評価] テンプレートを例として使用します。このテンプレートを選択する場合、次のパラメーターを構成する必要があります。
次の表に、主要なパラメーターを示します。
テンプレートの詳細については、「付録:プリセット評価テンプレート」をご参照ください。 |
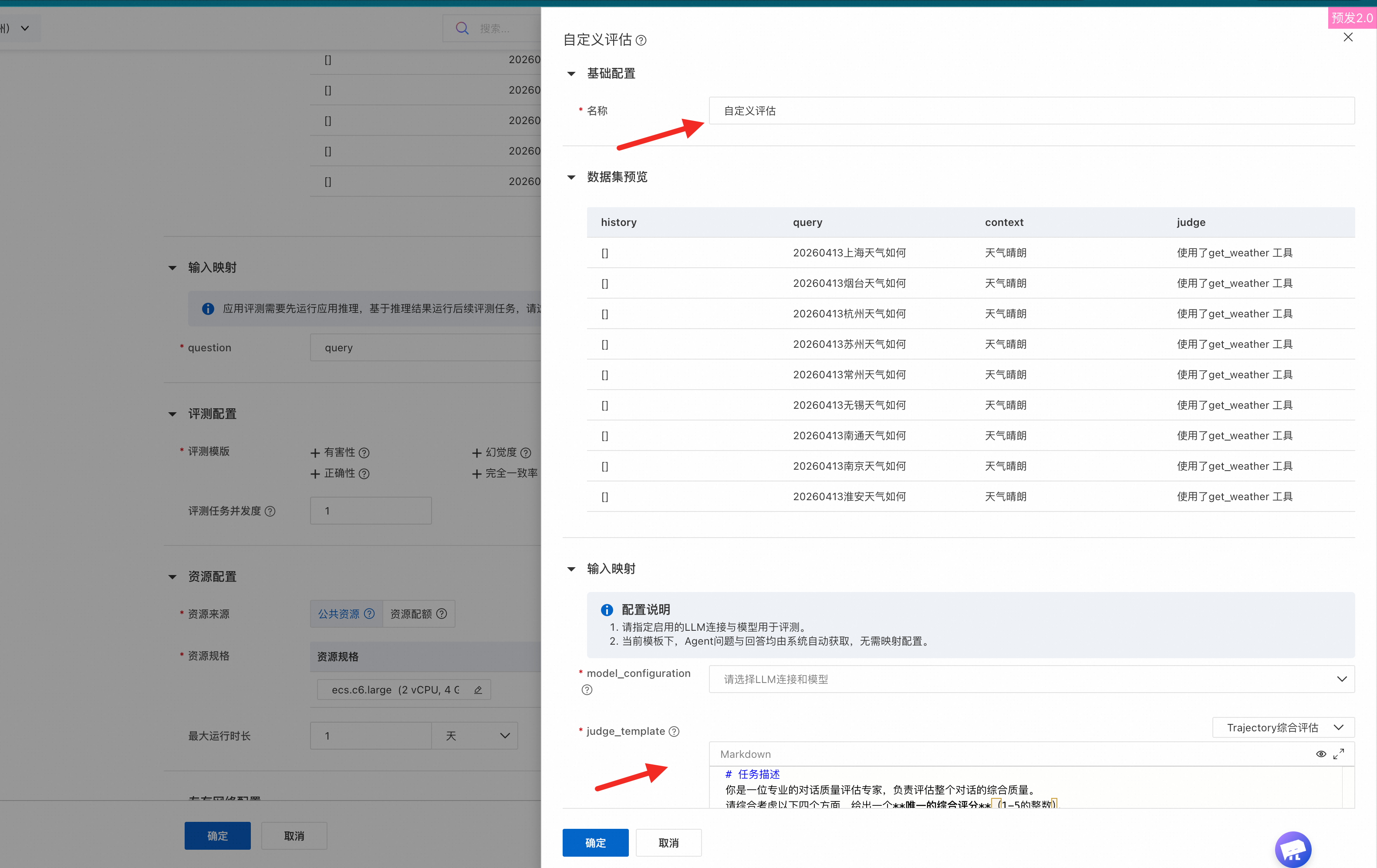
カスタム評価 | システムには、カスタム評価を作成できる特別なテンプレートが用意されています。評価プロンプトをカスタマイズできます。
|
リソース構成:これらのリソースは、評価タスクのスケジューリングにのみ使用されます。タスクの複雑さに応じて、適切な CPU リソース を選択することを推奨します。 | |

評価結果の表示
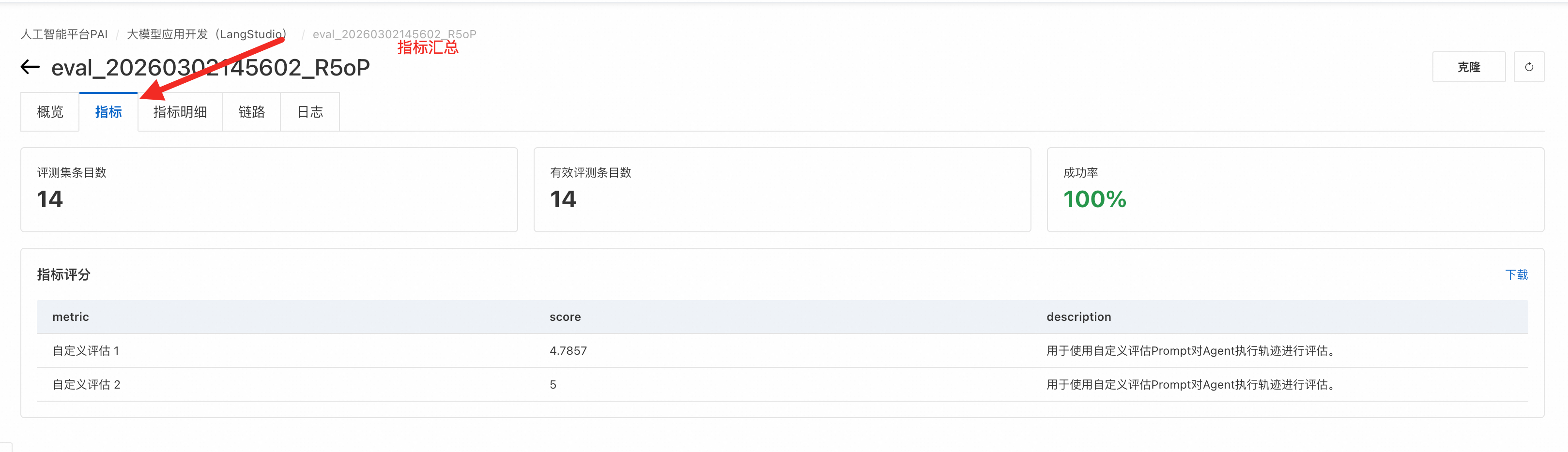
評価タスクを送信すると、LangStudio はタスクの [概要] ページにリダイレクトします。各評価実行は、バッチ実行 と メトリック評価 のステージで構成されます。バッチ実行 ステージでは、データセットの各行を処理して出力を生成します。メトリック評価 ステージでは、システムは評価データセットの補助フィールドを使用して、バッチ実行からの各出力をスコアリングします。実行が完了すると、各サブタスクのトレース、メトリック、および出力の詳細を表示できます。
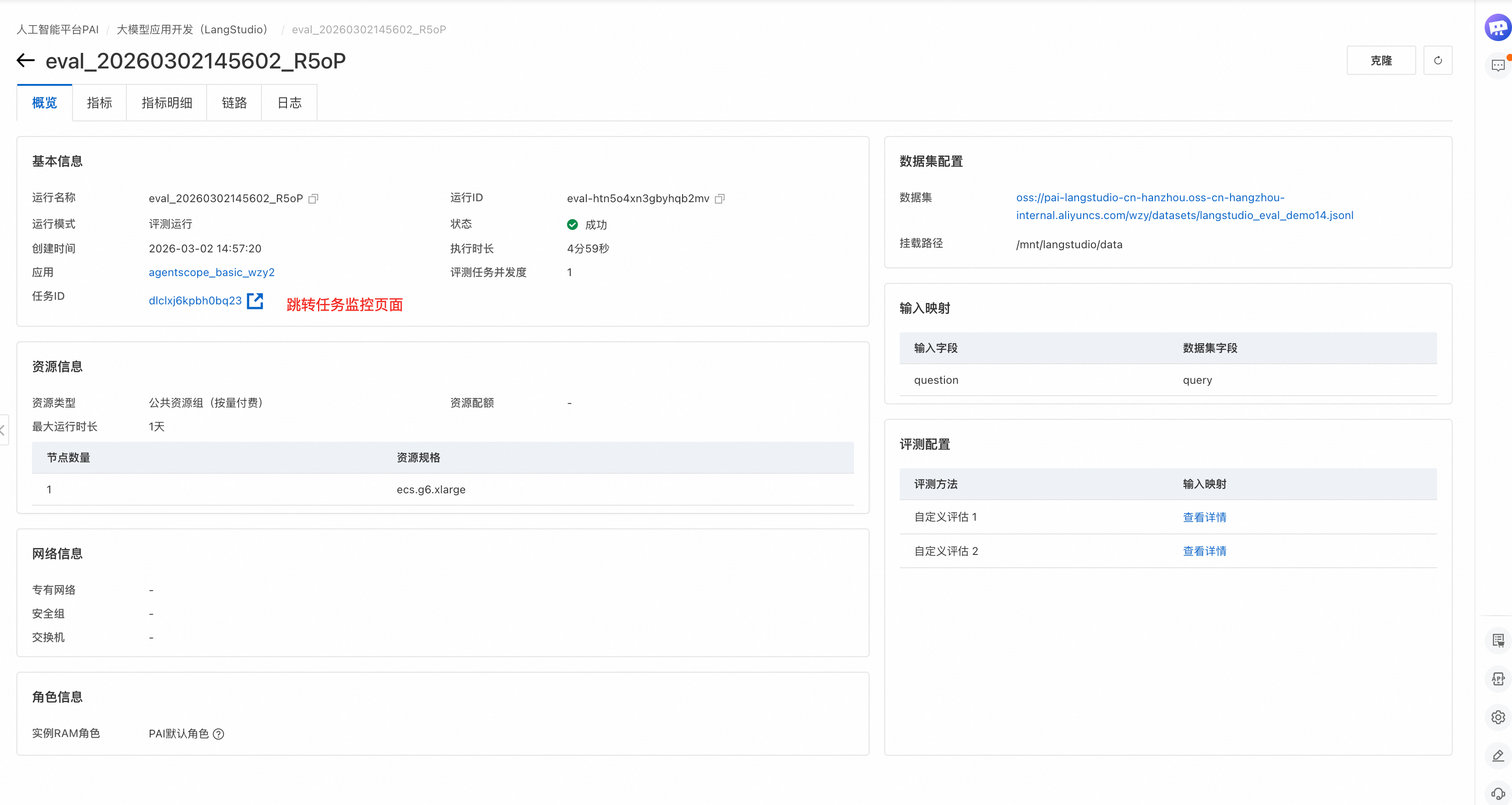
[メトリック] ページでは、すべての評価メトリックの結果を表示できます。メトリック名の詳細については、「付録:プリセット評価テンプレート」をご参照ください。
付録:プリセット評価テンプレート
LangStudio は、メトリックスコアを使用して複数のディメンションでアプリケーションのパフォーマンスを評価するための、いくつかの組み込み評価テンプレートを提供します。
テンプレート名 | 説明 | モデルサービスタイプ | 入力フィールド |
完全一致評価 | Agent の出力とリファレンスとの間で完全一致比較を実行します。スコアの範囲は 0 から 1 で、0 は不一致、1 は完全一致を示します。 | なし |
|
回答の関連性の評価 | アプリケーションの出力と入力との関連性を評価します。このメソッドは LLM に依存して関連性をスコアリングします。スコアの範囲は 1 から 5 で、スコアが高いほど、回答がユーザーのクエリに対してより関連性が高いことを示します。 | LLM |
|
回答の正しさの評価 | Agent の回答とリファレンスとの間の一貫性を、事実の正確性、情報のカバー率、フォーマットの一致の観点から評価します。スコアの範囲は 1 から 5 で、スコアが高いほどリファレンスとの一致度が高いことを示します。 | LLM |
|
命令追従性の評価 | Agent の回答が、コンテンツ、フォーマット、制約の観点から、与えられた命令にどれだけ従っているかを評価します。スコアの範囲は 1 から 5 で、スコアが高いほど、モデルが命令により正確かつ完全に準拠していることを示します。 | LLM |
|
回答の忠実度の評価 | Agent の回答に、与えられたコンテキストによって裏付けられていない、または矛盾する捏造された情報が含まれているかどうかを検出します。スコアの範囲は 1 から 5 で、スコアが高いほど捏造の度合いが低く、コンテキストへの忠実度が高いことを示します。 | LLM |
|
安全性評価 | Agent の回答に含まれる有害、不快、または不適切なコンテンツを検出し、AI の安全性を確保します。スコアの範囲は 1 から 5 で、スコアが高いほどコンテンツがより安全で適切であることを示します。 | LLM |
|
軌跡評価 | Agent の実行軌跡を包括的に評価します。スコアの範囲は 1 から 5 で、スコアが高いほど軌跡の全体的なパフォーマンスが優れていることを示します。 | LLM |
|