このトピックでは、OpenSearch LLM-Based Conversational Search Edition インスタンスを使用して、OpenSearch Vector Search Edition インスタンスに Retrieval-Augmented Generation (RAG) 機能を提供する方法について説明します。
OpenSearch Vector Search Edition インスタンスが既にある場合は、OpenSearch LLM-Based Conversational Search Edition インスタンスを購入するだけで済みます。2 つのインスタンスは、次の機能を提供します。
OpenSearch Vector Search Edition インスタンス:
元のドキュメントデータとベクトルデータを保存します。
元のドキュメントデータとベクトルデータを取得します。
OpenSearch LLM-Based Conversational Search Edition インスタンス:
オプション。元のドキュメントに対してテキストセグメンテーションと単語埋め込みを実行します。
オプション。元のクエリに対して単語埋め込みを実行します。
取得した結果に対して推論と要約を実行します。
次の図は、実装プロセスを示しています。
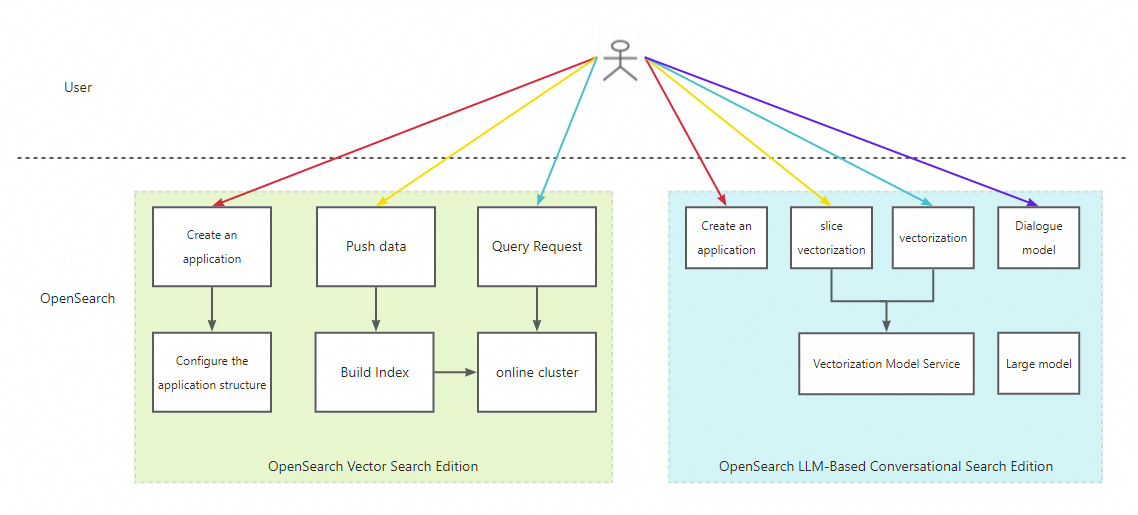
1. インスタンスを作成して構成する
1.1. OpenSearch Vector Search Edition インスタンスを作成して構成する
1.1.1. OpenSearch Vector Search Edition インスタンスを購入する
OpenSearch Vector Search Edition インスタンスが既にある場合は、新しいインスタンスを購入する必要はありません。
OpenSearch Vector Search Edition インスタンスの購入方法の詳細については、OpenSearch Vector Search Edition インスタンスを購入するを参照してください。
1.1.2. OpenSearch Vector Search Edition インスタンスを構成する
既存の OpenSearch Vector Search Edition インスタンスのクエリと取得ロジックを変更したくない場合は、LLM-Based Conversational Search Edition の knowledge-llm オペレーションを呼び出して、取得した結果に対して推論と要約を実行するだけで済みます。詳細については、このトピックの「knowledge-llm オペレーションを呼び出して推論と要約を実行する」セクションを参照してください。
新しく購入したインスタンスは「構成保留中」状態であり、インスタンスのテーブルを構成する必要があります。これを行うには、次の図に示すように、インスタンスの [アクション] 列にある [構成] をクリックします。

1.1.2.1. テーブルの基本情報を構成する
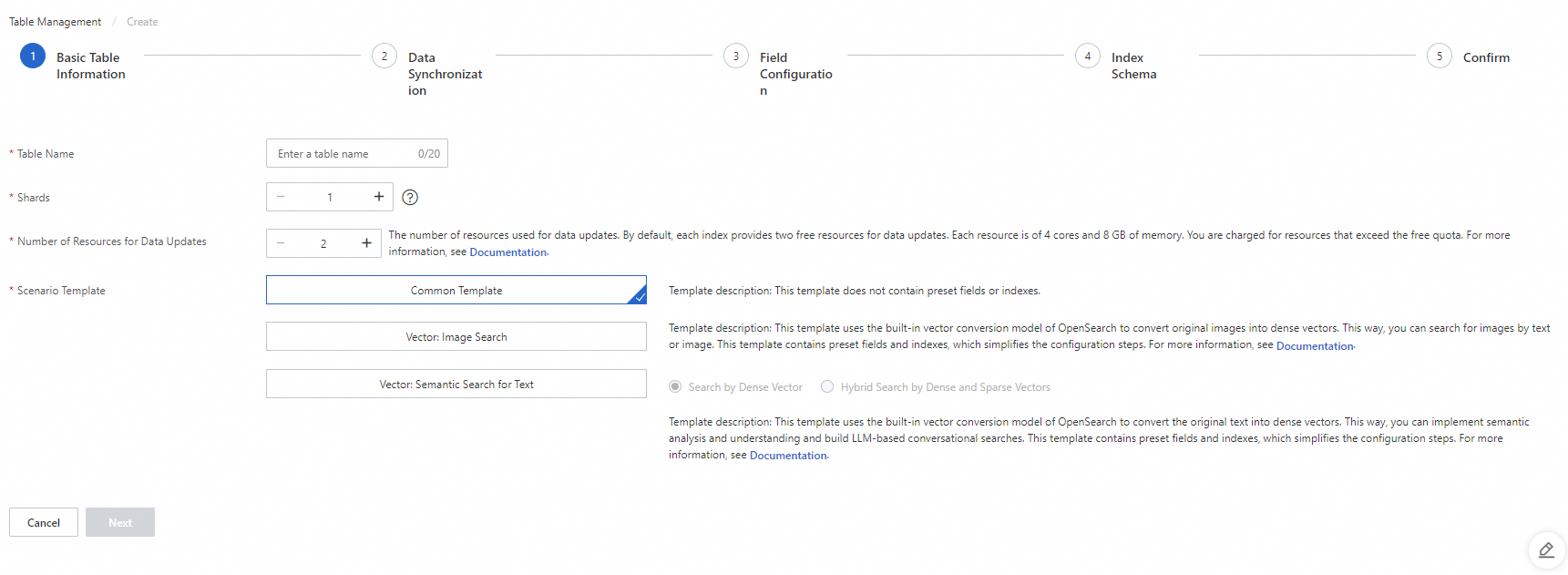
パラメータ:
テーブル名: テーブルの名前。テーブル名をカスタマイズできます。
データシャード: テーブル内のデータシャードの数。インスタンスに複数のインデックステーブルを作成する場合は、インデックステーブルに同じ数のシャードが含まれていることを確認してください。または、少なくとも 1 つのインデックステーブルに 1 つのシャードが含まれており、他のインデックステーブルに同じ数のシャードが含まれていることを確認してください。
データ更新用リソース数: データ更新に使用されるリソースの数。デフォルトでは、OpenSearch は OpenSearch Vector Search Edition インスタンスの各データソースに対して 2 つのリソースの無料クォータを提供します。各リソースは 4 つの CPU コアと 8 GB のメモリで構成されています。無料クォータを超えるリソースについては課金されます。詳細については、OpenSearchベクトル検索版の課金概要を参照してください。
シナリオテンプレート: テーブルの作成に使用されるテンプレート。この例では、「共通テンプレート」が選択されています。
[次へ] をクリックして、データソースを追加する「データ同期」ステップに進みます。
1.1.2.2. データソースを追加する

パラメータ:
フルデータソース: データソースのタイプ。この例では、「API」が選択されています。これは、ユーザーデータが API を使用して OpenSearch Vector Search Edition インスタンスにプッシュされることを示します。
[次へ] をクリックして、フィールドを構成する「フィールド構成」ステップに進みます。
1.1.2.3. フィールドを構成する
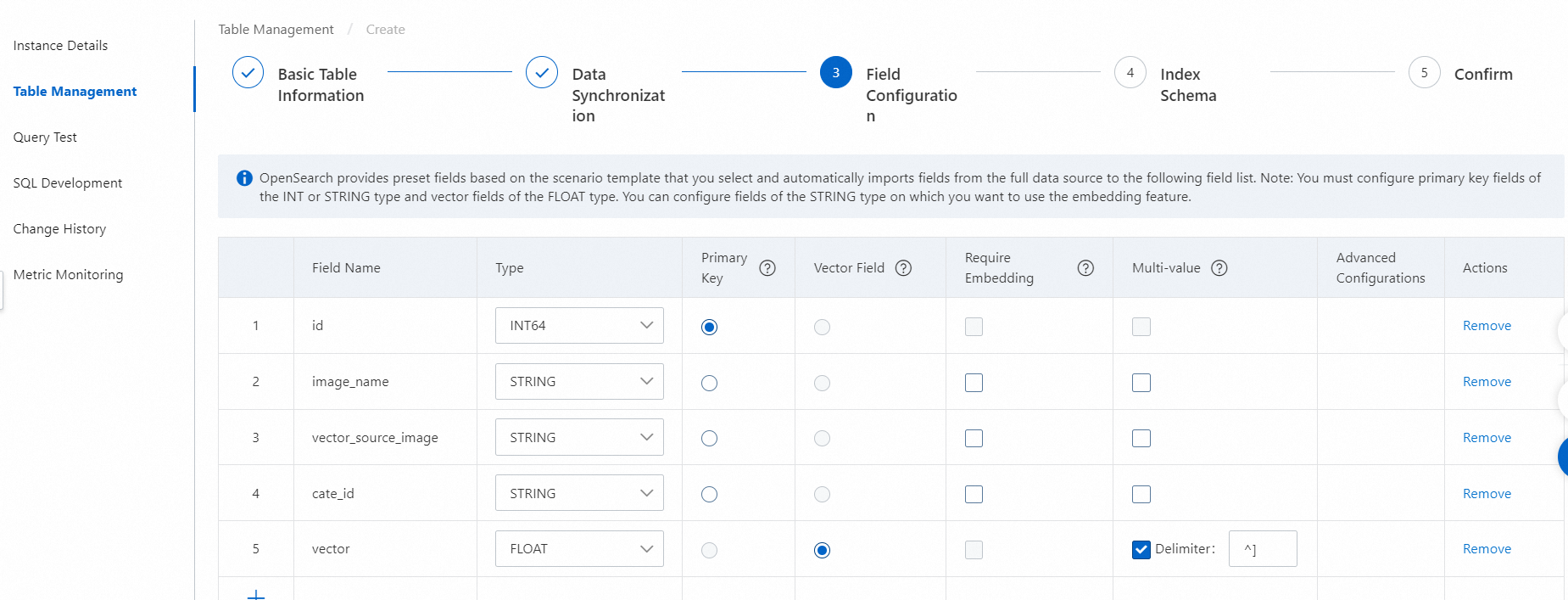
テーブルスキーマには、次のフィールドが含まれている必要があります。
ドキュメントの主キーフィールド (前の図の doc_id フィールドなど)。
テキストセグメンテーション後に取得されたコンテンツを保存するフィールド (前の図の split_content フィールドなど)。
単語埋め込み後に取得されたコンテンツのベクトルを保存するフィールド (前の図の split_content_embedding フィールドなど)。このフィールドはベクトルフィールドとして定義し、ベクトルフィールドの複数の値をコンマ (,) で区切る必要があります。
上記の必須フィールドに加えて、カスタムフィールドを追加し、ビジネス要件に基づいてこれらのフィールドをソートやフィルタリングに使用できます。
1.1.2.4. インデックススキーマを構成する
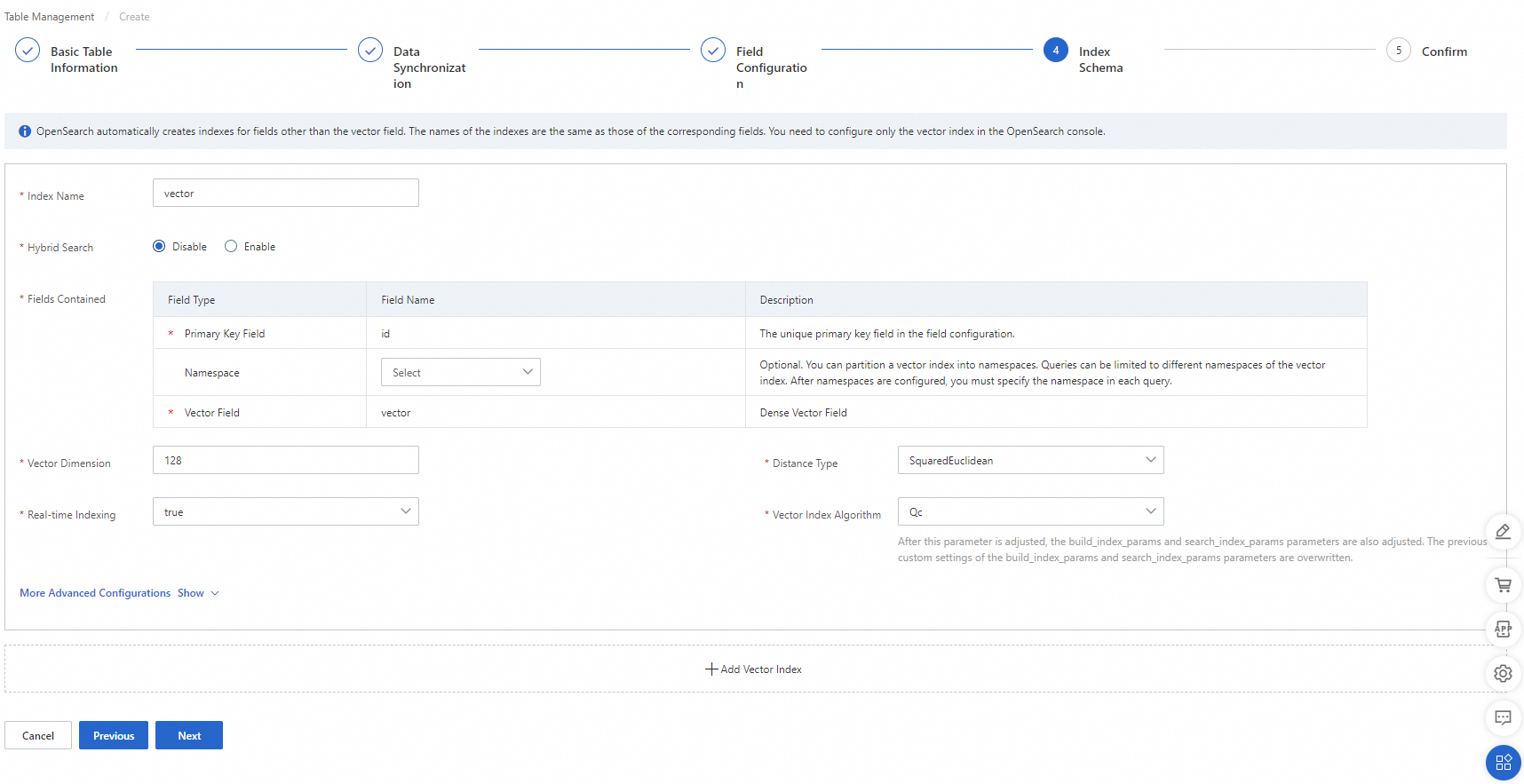
パラメータ:
ベクトル次元: ベクトルの次元数。この例では、パラメータを 1536 に設定します。
その他のパラメータにはデフォルト設定を使用します。
1.1.2.5. 作成を確認する
[確認] ステップで、[確認] をクリックします。
左側のナビゲーションペインで [変更履歴] をクリックして、テーブルの作成の進行状況を表示できます。進行状況が完了すると、テーブルが作成され、後続の操作を実行できます。

1.2. OpenSearch LLM-Based Conversational Search Edition インスタンスを作成して構成する
1.2.1. OpenSearch LLM-Based Conversational Search Edition インスタンスを購入して構成する
OpenSearch LLM-Based Conversational Search Edition インスタンスの購入方法の詳細については、コンソールでエンタープライズナレッジベースに基づいて会話型検索を実装するトピックの「インスタンスを購入する」セクションを参照してください。
OpenSearch LLM-Based Conversational Search Edition インスタンスを購入した後、インスタンスを構成することなく使用できます。
2. OpenSearch Vector Search Edition インスタンスにデータをプッシュする
2.1. 元のドキュメントに対してテキストセグメンテーションと単語埋め込みを実行する
単語埋め込みモデルは最大 300 トークンをサポートします。ただし、元のドキュメントは通常サイズが大きいです。したがって、元のドキュメントに対してテキストセグメンテーションを実行する必要があります。さらに、テキストセグメンテーションの実行後、ドキュメントに対して単語埋め込みを実行する必要があります。
OpenSearch LLM-Based Conversational Search Edition インスタンスのエンドポイントと API の詳細については、このトピックの「Java 用 SDK のサンプルコード」セクション、または次のトピックを参照してください。
2.2. テキストセグメンテーションと単語埋め込み後に取得した結果を OpenSearch Vector Search Edition インスタンスにプッシュする
ステップ 2.1 の返された結果では、
chunk_id フィールドには、テキストセグメンテーション後に取得されたチャンクの ID が保存されます。チャンク ID と元のドキュメントの ID を連結して、チャンクの主キーフィールドの値を生成します。この主キーフィールドは doc_id です。
chunk フィールドには、テキストセグメンテーション後に取得されたチャンクコンテンツが保存されます。これは split_content フィールドにプッシュする必要があります。
embedding フィールドには、単語埋め込み後のチャンクコンテンツのベクトルが保存されます。これは split_content_embedding フィールドにプッシュする必要があります。
上記の結果を OpenSearch Vector Search Edition インスタンスにプッシュします。
OpenSearch Vector Search Edition インスタンスのエンドポイントと API の詳細については、このトピックの「Java 用 SDK のサンプルコード」セクション、または次のトピックを参照してください。
3. 会話型検索を実行する
3.1. 元のクエリに対して単語埋め込みを実行する
元のクエリに対して単語埋め込みを実行する必要があります。
OpenSearch LLM-Based Conversational Search Edition インスタンスのエンドポイントと API の詳細については、このトピックの「Java 用 SDK のサンプルコード」セクション、または次のトピックを参照してください。
3.2. ベクトル結果を取得する
元のクエリの埋め込みを使用して、OpenSearch Vector Search Edition インスタンスで検索します。一般的に、上位 5 つの結果のみを取得する必要があります。
OpenSearch Vector Search Edition インスタンスのエンドポイントと API の詳細については、このトピックの「Java 用 SDK のサンプルコード」セクション、または次のトピックを参照してください。
3.3. knowledge-llm オペレーションを呼び出して推論と要約を実行する
OpenSearch LLM-Based Conversational Search Edition が提供する knowledge-llm オペレーションを呼び出して、OpenSearch Vector Search Edition インスタンスから取得した結果に対して推論と要約を実行します。
詳細については、このトピックの「Java 用 SDK のサンプルコード」セクション、または次のトピックを参照してください。
4. Java 用 SDK のサンプルコード
次のサンプルコードは、Java 用 SDK を使用してデータをプッシュし、会話型検索を実行する方法の例を示しています。
Maven 依存関係:
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-sdk-ha3engine-vector</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>com.aliyun.opensearch</groupId>
<artifactId>aliyun-sdk-opensearch</artifactId>
<version>4.0.0</version>
</dependency>
Java 用 SDK のサンプルコード:
import com.aliyun.ha3engine.vector.Client;
import com.aliyun.ha3engine.vector.models.*;
import com.aliyun.opensearch.OpenSearchClient;
import com.aliyun.opensearch.sdk.dependencies.org.json.JSONObject;
import com.aliyun.opensearch.sdk.generated.OpenSearch;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchClientException;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchException;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchResult;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.util.*;
public class LLMDemo {
/**
* OpenSearch LLM-Based Conversational Search Edition インスタンスの名前。
*/
private static String llmAppName = "test_llm";
/**
* OpenSearch LLM-Based Conversational Search Edition インスタンスのエンドポイント。
*/
private static String llmHost = "http://opensearch-cn-shanghai.aliyuncs.com";
/**
* OpenSearch LLM-Based Conversational Search Edition インスタンスにアクセスするために使用される AccessKey ID。
*/
private static String llmAccessKey = "xxxxx";
/**
* OpenSearch LLM-Based Conversational Search Edition インスタンスにアクセスするために使用される AccessKey シークレット。
*/
private static String llmAccessSecret = "xxxx";
/**
* OpenSearch Vector Search Edition インスタンスの API エンドポイント。
*/
private static String embeddingEndpoint = "ha-cn-xxxx.public.ha.aliyuncs.com";
/**
* OpenSearch Vector Search Edition インスタンスの名前。
*/
private static String embeddingInstanceId = "ha-cn-xxx";
/**
* OpenSearch Vector Search Edition インスタンスのドキュメントデータテーブルの名前。
*/
private static String embeddingTableName = "ha-cn-xxx_xxx";
/**
* OpenSearch Vector Search Edition インスタンスのドキュメントインデックステーブルの名前。
*/
private static String embeddingIndexName = "xxx";
/**
* OpenSearch Vector Search Edition インスタンスにプッシュされるドキュメントの主キーフィールド。
*/
private static String embeddingPkField = "doc_id";
/**
* OpenSearch Vector Search Edition インスタンスにアクセスするために使用されるユーザー名。
*/
private static String embeddingUserName = "xxxx";
/**
* OpenSearch Vector Search Edition インスタンスにアクセスするために使用されるパスワード。
*/
private static String embeddingPassword = "xxxx";
public static void main(String[] args) throws Exception {
// OpenSearch LLM-Based Conversational Search Edition インスタンスにアクセスするためのオブジェクトを作成します。
// OpenSearch オブジェクトを作成します。
OpenSearch openSearch = new OpenSearch(llmAccessKey, llmAccessSecret, llmHost);
// OpenSearch オブジェクトをパラメータとして使用して、OpenSearchClient オブジェクトを作成します。
OpenSearchClient llmClient = new OpenSearchClient(openSearch);
// OpenSearch Vector Search Edition インスタンスにアクセスするためのオブジェクトを作成します。
Config config = new Config();
config.setEndpoint(embeddingEndpoint);
config.setInstanceId(embeddingInstanceId);
config.setAccessUserName(embeddingUserName);
config.setAccessPassWord(embeddingPassword);
Client embeddingClient = new Client(config);
// コンテンツに対してテキストセグメンテーションと単語埋め込みを実行します。
Map<String, String> splitParams = new HashMap<String, String>() {{
put("format", "full_json");
// 日本語のコンテンツに置き換える
put("_POST_BODY", "{\"content\":\"OpenSearch は、商用インテリジェント検索サービスを開発するために使用されるオールインワンプラットフォームとして機能します。これは、Alibaba によって開発された大規模分散検索エンジンに基づいて構築されています。OpenSearch は、Taobao、Tmall、Cainiao など、Alibaba グループのコア検索ビジネスにミッドエンドサービスを提供しています。\"+ \"さまざまな業界での長年の検索経験と、大規模なオンラインプロモーション中のトラフィックピークを処理する機能のおかげで、OpenSearch チームは、高性能、効率性、可用性、安定性を提供する一連のサービスエディションをリリースしています。リリースされたサービスエディションは、LLM ベースの会話型検索エディション、業界アルゴリズムエディション、高性能検索エディション、ベクトル検索エディション、検索エンジンエディションです。これは、さまざまな業界の検索要件を満たすのに役立ちます。\"+ \"OpenSearch は、検索テクノロジーの使用を簡素化し、技術的なしきい値とコストを削減する PaaS です。OpenSearch を使用すると、低コストでサービスの検索機能と高速な反復を実装できます。これにより、検索テクノロジーがビジネスのボトルネックになるのを防ぎます。\",\"use_embedding\":true}");
}};
String splitPath = String.format("/apps/%s/actions/knowledge-split", llmAppName);
OpenSearchResult openSearchResult = llmClient.callAndDecodeResult(splitPath, splitParams, "POST");
System.out.println("split result:" + openSearchResult.getResult());
JsonArray array = JsonParser.parseString(openSearchResult.getResult()).getAsJsonArray();
// ドキュメント操作を指定する外部構造。構造には 1 つ以上のドキュメント操作を指定できます。
ArrayList<Map<String, ?>> documents = new ArrayList<>();
// たとえば、元のドキュメントの主キー値は 001 です。
String doc_raw_id="001";
for(JsonElement element:array){
JsonObject object = element.getAsJsonObject();
// ドキュメントをアップロードします。
Map<String, Object> add2Document = new HashMap<>();
Map<String, Object> add2DocumentFields = new HashMap<>();
// ドキュメントのコンテンツを挿入します。キーは値とペアにする必要があります。
// field_pk フィールドの値は、pkField フィールドの値と同じである必要があります。
add2DocumentFields.put("doc_id", doc_raw_id+"_"+object.get("chunk_id").getAsString());
add2DocumentFields.put("doc_raw_id", doc_raw_id);
List<Float> vectors = new ArrayList();
for(String str: object.get("embedding").getAsString().split(",")){
vectors.add(Float.parseFloat(str));
}
add2DocumentFields.put("split_content_embedding", vectors);
add2DocumentFields.put("split_content", object.get("chunk"));
add2DocumentFields.put("time", System.currentTimeMillis());
// ドキュメントコンテンツを add2Document 構造に追加します。
add2Document.put("fields", add2DocumentFields);
// add コマンドを実行してドキュメントをアップロードします。
add2Document.put("cmd", "add");
documents.add(add2Document);
}
System.out.println("push docs:"+documents.toString());
// OpenSearch Vector Search Edition インスタンスにデータをプッシュします。
PushDocumentsRequest request = new PushDocumentsRequest();
request.setBody(documents);
PushDocumentsResponse response = embeddingClient.pushDocuments(embeddingTableName, embeddingPkField, request);
String responseBody = response.getBody();
System.out.println("push result:" + responseBody);
// 元のクエリに対して単語埋め込みを実行します。
Map<String, String> embeddingParams = new HashMap<String, String>() {
{
put("format", "full_json");
// 日本語のクエリに置き換える
put("_POST_BODY", "{\"content\":\"OpenSearch とは\",\"query\":true}");
}};
String embeddingPath = String.format("/apps/%s/actions/knowledge-embedding", llmAppName);
openSearchResult = llmClient.callAndDecodeResult(embeddingPath, embeddingParams, "POST");
System.out.println("query embedding:"+openSearchResult.getResult());
String embedding = openSearchResult.getResult();
List<Float> vectors = new ArrayList();
for(String str: embedding.split(",")){
vectors.add(Float.parseFloat(str));
}
System.out.println("query vectors size:"+vectors.size()+" vectors:"+vectors);
QueryRequest queryRequest = new QueryRequest();
queryRequest.setTableName(embeddingIndexName);
queryRequest.setVector(vectors);
queryRequest.setTopK(5);
queryRequest.setIncludeVector(true);
queryRequest.setOutputFields(Arrays.asList("split_content"));
FetchRequest fetchRequest = new FetchRequest();
fetchRequest.setTableName(embeddingIndexName);
fetchRequest.setIds(Arrays.asList("001_1"));
SearchResponse searchResponse = embeddingClient.query(queryRequest);
System.out.println("Search results:" + searchResponse.getBody());
JsonObject recallResult = JsonParser.parseString(searchResponse.getBody()).getAsJsonObject();
long hits = recallResult.get("totalCount").getAsLong();
List<String> list = new ArrayList<>();
if(hits <=0){
System.out.println("結果が見つかりません。");
return ;
}else{
JsonArray items = recallResult.get("result").getAsJsonArray();
for(JsonElement element:items) {
JsonObject object = element.getAsJsonObject();
String splitContent = object.get("fields").getAsJsonObject().get("split_content").getAsString();
list.add(splitContent);
}
}
// OpenSearch LLM-Based Conversational Search Edition インスタンスを使用して会話型検索を実行します。
StringBuffer sb =new StringBuffer();
// 日本語の質問に置き換える
sb.append("{ \"question\" : \"OpenSearch とは\" ,");
sb.append(" \"type\" : \"text\",");
sb.append(" \"content\" : [");
for(String str:list){
sb.append("\"");
sb.append(str);
sb.append("\"");
sb.append(",");
}
sb.deleteCharAt(sb.lastIndexOf(","));
sb.append("]}");
Map<String, String> llmParams = new HashMap<String, String>() {{
put("format", "full_json");
put("_POST_BODY", sb.toString());
}};
System.out.println("llm request params:"+llmParams);
String llmPath = String.format("/apps/%s/actions/knowledge-llm", llmAppName);
openSearchResult = llmClient.callAndDecodeResult(llmPath, llmParams, "POST");
System.out.println("llm result:"+openSearchResult.getResult());
}
}
会話型検索のサンプル結果:
split result:[{"chunk":"OpenSearch は、商用インテリジェント検索サービスを開発するために使用されるオールインワンプラットフォームとして機能します。これは、Alibaba によって開発された大規模分散検索エンジンに基づいて構築されています。OpenSearch は、Taobao、Tmall、Cainiao など、Alibaba グループのコア検索ビジネスにミッドエンドサービスを提供しています。さまざまな業界での長年の検索経験と、大規模なオンラインプロモーション中のトラフィックピークを処理する機能のおかげで、OpenSearch チームは、高性能、効率性、可用性、安定性を提供する一連のサービスエディションをリリースしています。リリースされたサービスエディションは、LLM ベースの会話型検索エディション、業界アルゴリズムエディション、高性能検索エディション、ベクトル検索エディション、検索エンジンエディションです。これは、さまざまな業界の検索要件を満たすのに役立ちます。OpenSearch は、検索テクノロジーの使用を簡素化し、技術的なしきい値とコストを削減する PaaS です。OpenSearch を使用すると、低コストでサービスの検索機能と高速な反復を実装できます。これにより、検索テクノロジーがビジネスのボトルネックになるのを防ぎます。","embedding":"(embedding data)", "type":"text","chunk_id":"1"}]