インスタンスを購入する
詳細については、OpenSearch ベクトル検索版インスタンスの購入を参照してください。
インスタンスを構成する
購入したインスタンスの詳細ページで、インスタンスは構成保留中状態です。システムは、データを含まないインスタンスを自動的にデプロイします。クエリ結果サーチャー (QRS) ワーカーとサーチャーワーカーの数と仕様は、購入した QRS ワーカーとサーチャーワーカーの数と仕様と同じです。検索にインスタンスを使用する前に、次の手順を実行します。再インデックスが完了すると、インスタンスを使用してクエリを実行できます。
1. テーブルの基本情報を構成する
インスタンスの詳細ページの左側のペインで、[テーブル管理] をクリックします。[テーブル管理] ページで、テーブルを追加をクリックします。作成ウィザードの [テーブルの基本情報] ステップで、テーブル名、データシャード、データ更新のリソース数、およびシナリオテンプレートパラメータを構成します。このトピックでは、シナリオテンプレートパラメータはベクトル: テキストのセマンティック検索に設定され、データ処理パラメータは未加工データをベクトルデータに変換に設定されています。次に、[次へ] をクリックします。
パラメータ:
テーブル名: テーブルの名前。テーブル名はカスタマイズできます。
データシャード: テーブルに含まれるデータシャードの数。1 から 256 の範囲の正の整数を入力します。シャーディングを実行してフルインデックスを高速化し、単一クエリの パフォーマンスを向上させることができます。既存の OpenSearch インスタンスに複数のインデックステーブルを作成する場合は、インデックステーブルに同じ数のシャードが含まれていることを確認してください。または、少なくとも 1 つのインデックステーブルに 1 つのシャードが含まれており、他のインデックステーブルに同じ数のシャードが含まれていることを確認してください。
データ更新のリソース数: データ更新に使用されるリソースの数。デフォルトでは、OpenSearch は OpenSearch ベクトル検索版インスタンスの各データソースに対してデータ更新用の 2 つのリソースの無料クォータを提供します。各リソースは、4 つの CPU コアと 8 GB のメモリで構成されています。無料クォータを超えるリソースに対しては課金されます。詳細については、国際サイト (alibabacloud.com) 向けの OpenSearch ベクトル検索版の課金概要を参照してください。
シナリオテンプレート: テーブルの作成に使用されるテンプレート。有効な値: 共通テンプレート、ベクトル: 画像検索、ベクトル: テキストのセマンティック検索。
2. データソースを追加する
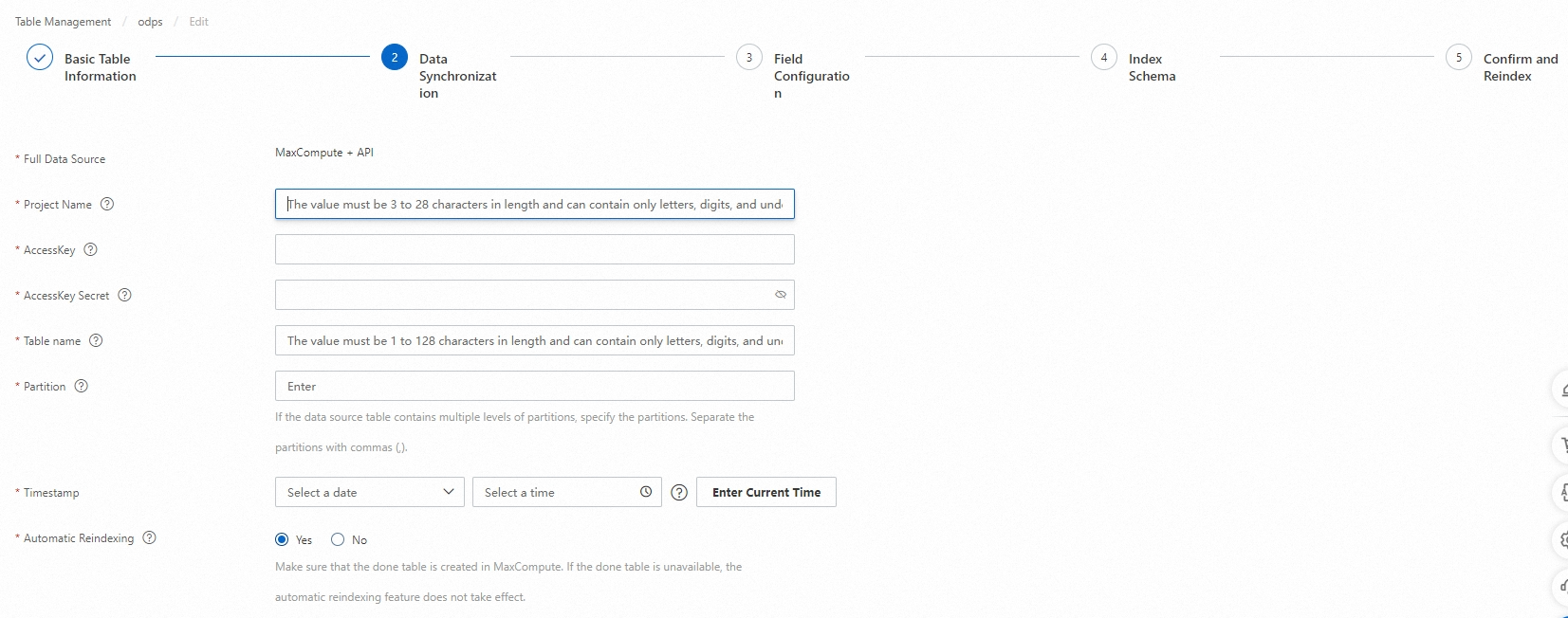
[データ同期] ステップで、データソースを追加します。MaxCompute データソースまたは API データソースを追加できます。この例では、MaxCompute + API がフルデータソースとして選択されています。プロジェクト、アクセスキー、アクセスキーのシークレット、テーブル、およびパーティションキーのパラメータを構成し、自動再インデックスパラメータを [はい] または [いいえ] に設定して、確認をクリックします。データソース情報がチェックに合格したら、[次へ] をクリックします。
MaxCompute データソースの詳細については、MaxCompute データソースのテーブルを作成するを参照してください。
API データソースの詳細については、API データソースのテーブルを作成するを参照してください。
オブジェクトストレージサービス (OSS) データソースの詳細については、OSS データソースのテーブルを作成するを参照してください。
3. フィールドを構成する
OpenSearch は、選択したシナリオテンプレートに基づいて関連するプリセットフィールドを提供し、データソースからフィールドリストにすべてのフィールドを自動的にインポートします。
[フィールドの構成] ステップで、フィールドを構成します。前のステップでシナリオテンプレートパラメータを [ベクトル: テキストのセマンティック検索] に設定した場合、OpenSearch は id を主キーフィールド、vector をベクトルフィールド、cate_id をカテゴリフィールド、vector_source_text を単語埋め込みを実行するフィールドとしてプリセットします。
注:
主キーフィールドとベクトルフィールドは必須です。主キーフィールドの場合は、[タイプ] パラメータを INT または STRING に設定し、[主キー] 列を選択する必要があります。ベクトルフィールドの場合は、[タイプ] パラメータを FLOAT に設定し、[ベクトルフィールド] 列を選択する必要があります。
デフォルトでは、ベクトルフィールドは FLOAT タイプの複数値フィールドであり、ベクトルフィールドの複数の値は HA3 デリミタ (^]) で区切られます。このデリミタは、UTF 形式で \x1D としてエンコードされます。カスタムの複数値デリミタを入力することもできます。
単語埋め込みを実行する vector_source_text フィールドに対して [埋め込みが必要] を選択します。
vector_source_text フィールドの値の長さは最大 128 バイトです。値の長さが 128 バイトを超える場合は、最初の 128 バイトのみがベクトル予測のために保持されます。
ベクトルインデックスを構成する場合は、主キーフィールド、名前空間フィールド、ベクトルフィールドの順にフィールドを指定する必要があります。名前空間フィールドはオプションです。前の図は例を示しています。
ソースデータにフィールドが存在しないか空の場合、システムは自動的にフィールドをデフォルト値に設定します。デフォルトでは、数値タイプのフィールドは 0 に設定され、STRING タイプのフィールドは空の文字列に設定されます。カスタムのデフォルト値を指定することもできます。
vector_source_text フィールドの高度な構成
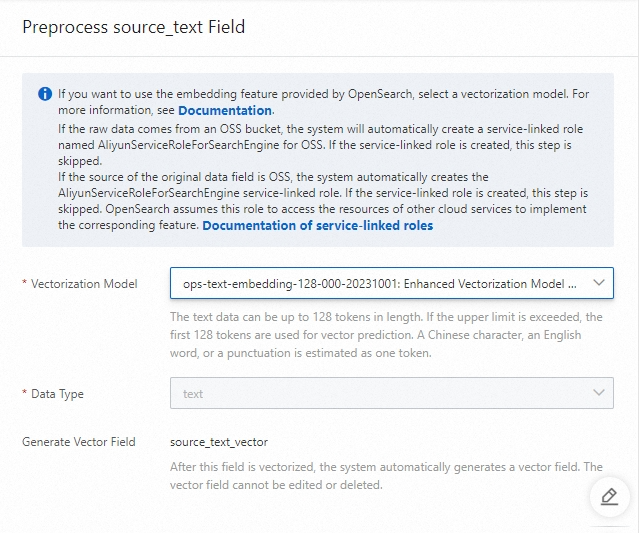
ベクトル化モデル: 中国語または英語の短いテキストを変換するモデル。有効な値:
ops-text-embedding-000: 短い中国語テキストをベクトルに変換するモデル。このモデルは 768 次元を使用します。
ops-text-embedding-en-000: 短い英語テキストをベクトルに変換するモデル。このモデルは 768 次元を使用します。
ops-text-embedding-1024-000-20231001: 中国語テキストをベクトルに変換する拡張モデル。このモデルは 1,024 次元を使用します。
ops-text-embedding-512-000-20231001: 中国語テキストをベクトルに変換する拡張モデル。このモデルは 512 次元を使用します。
ops-text-embedding-128-000-20231001: 中国語テキストをベクトルに変換する拡張モデル。このモデルは 128 次元を使用します。
ops-text-embedding-512-en-000-20231001: 英語テキストをベクトルに変換する拡張モデル。このモデルは 512 次元を使用します。
ops-text-embedding-128-en-000-20231001: 英語テキストをベクトルに変換する拡張モデル。このモデルは 128 次元を使用します。
データ型: データ型。デフォルト値は text で、変更できません。
注: テキストの長さは、特定のトークン数までにすることができます。テキストの長さが指定されたトークン数を超える場合は、最初の指定されたトークン数がベクトル予測のために保持されます。漢字、英単語、句読点は 1 つのトークンとして認識されます。
4. インデックススキーマを構成する
4.1. ベクトルインデックス
OpenSearch は、主キーフィールドとベクトルフィールドのインデックスを自動的に作成します。インデックス名はフィールド名と同じです。OpenSearch コンソールでベクトルインデックスのみを構成する必要があります。

主キーフィールドとベクトルフィールドは必須です。名前空間フィールドはオプションで、空のままにすることができます。
名前空間フィールド: インスタンスのエンジンバージョンが vector_service_1.0.2 以前の場合、名前空間フィールドは STRING タイプにすることはできません。インスタンスのエンジンバージョンが vector_service_1.0.2 以降の場合、フィールドタイプに制限はありません。
システムは、ベクトルインデックスの高度な構成のパラメータを自動的に構成します。ベクトル次元パラメータを 768 に設定し、その他のパラメータ設定は変更しないことをお勧めします。

5. 作成を確認する
[確認] ステップで、[確認] をクリックします。

6. 変更履歴を表示する
インスタンスの詳細ページの左側のペインで、[変更履歴] をクリックします。表示されるページの [データソースの変更] タブで、テーブルの作成、インデックスの作成、フルデータの再インデックスの実行のプロセスに関連するすべての有限状態マシン (FSM) を表示できます。検索エンジンが構築されたら、インスタンスでクエリテストを実行できます。
7. クエリテストを実行する
サンプルクエリ: 詳細については、「データのクエリ」トピックの予測ベースのクエリセクションを参照してください。
サンプル結果:
{
"totalCount": 5,
"result": [
{
"id": 5,
"score": 1.103209137916565
},
{
"id": 3,
"score": 1.1278988122940064
},
{
"id": 2,
"score": 1.1326735019683838
}
],
"totalTime": 242.615
}result: 返された結果。
構文
予測ベースのクエリの構文の詳細については、予測ベースのクエリを参照してください。
主キーベースのクエリの構文の詳細については、主キーベースのクエリを参照してください。
フィルタ式の構文の詳細については、フィルタ式を参照してください。