OpenSearch LLM ベースの対話型検索エディションは、非構造化データ処理、ベクトルモデル、テキストとベクトルの取得、および大規模言語モデル(LLM)を統合し、すぐに使える Retrieval-Augmented Generation(RAG)ソリューションを提供します。多様なデータ形式の迅速なインポートをサポートし、対話、リンク、画像を含むマルチモーダル検索サービスを構築することで、開発者が RAG システムを迅速にセットアップできるようにします。
概要
LLM ベースの対話型検索エディションは、業界の検索シナリオ向けに設計されており、企業固有の Q&A 検索サービスを提供します。組み込みの LLM に基づいて、Q&A 検索システムを迅速にセットアップできます。 LLM ベースの対話型検索エディションは、顧客自身のビジネスデータに基づいて、Q&A の結果、参照画像、参照リンク、その他のコンテンツを自動的に生成し、よりインテリジェントで高品質な Q&A 検索サービスを提供します。
サービスアーキテクチャ
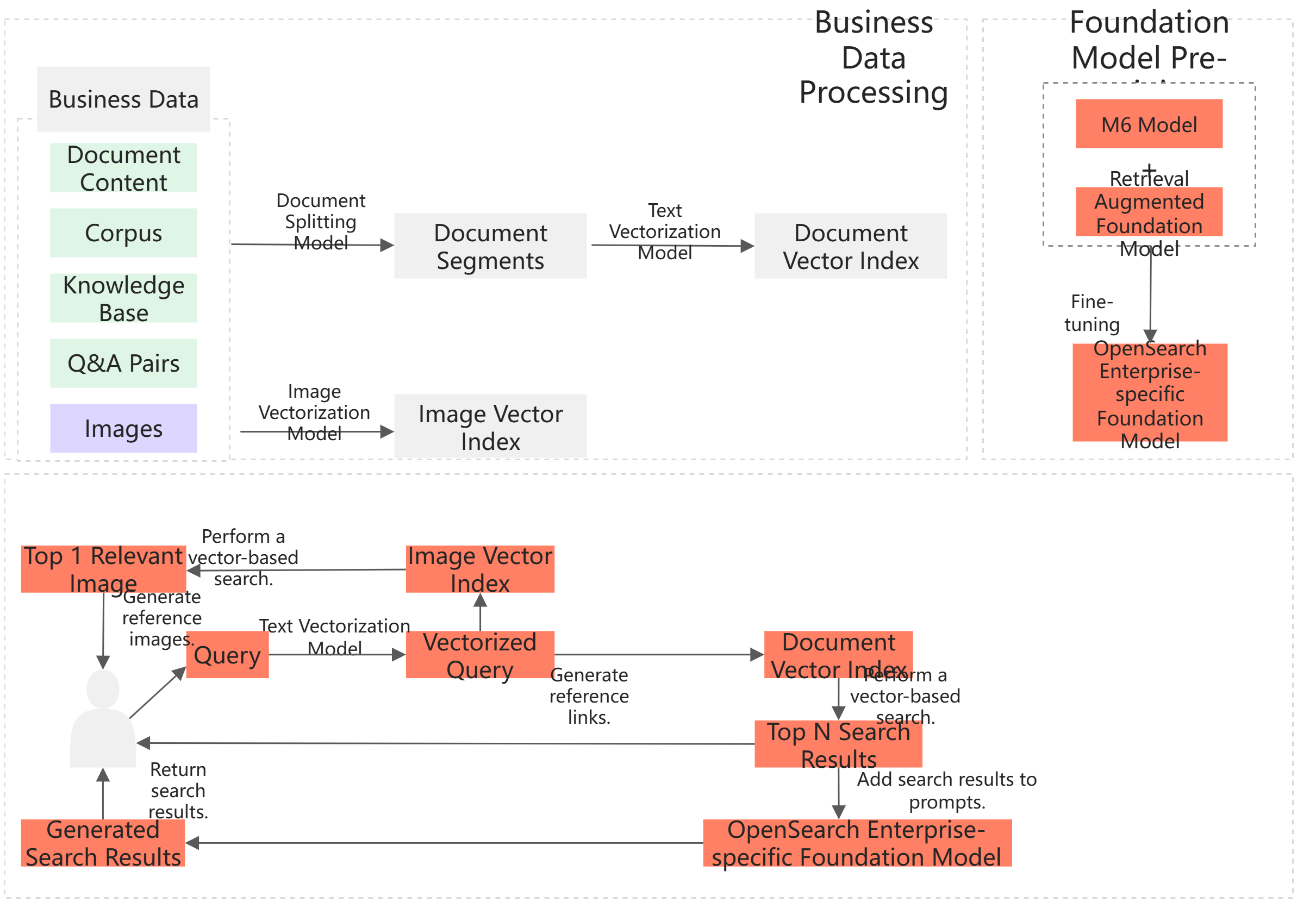
特徴
マルチモーダル RAG:画像コンテンツの理解をサポートし、OCR と LLM を介してマルチモーダルナレッジベースを構築し、多様な出力結果を提供します。
RAG パフォーマンス評価:フルリンクのパフォーマンス評価をサポートし、さまざまなモデルやパラメーター構成における RAG 効果を比較し、効果の比較と選択を容易にします。
豊富なモデル機能とカスタマイズされたモデルトレーニング:組み込みのベクトル、再ランク付け、および LLM を使用して、ビジネスデータに基づいて専用のモデルをトレーニングできます。
リアルタイムデータ更新:増分ベクトルインデックスのリアルタイム構築とリアルタイムデータ同期の更新をサポートします。
テーブル Q&A:NL2SQL に基づくテーブル Q&A をサポートし、企業の構造化データベースを介した対話型検索 Q&A を実現します。
ゼロデプロイメントとメンテナンス不要の完全管理:デプロイメントやメンテナンスが不要な、完全に管理されたクラウドベースの MaaS サービス。
メリット
ワンストップクイックアクセス:フルリンクの RAG プロセスが組み込まれており、コンソールからビジネスデータをアップロードすることで、数分以内に RAG システムを構築できます。
優れた RAG 効果:組み込みのベクトル、再ランク付け、および LLM を備え、モデル機能は業界ランキングで何度もトップにランクインしており、95% を超える RAG 精度を保証します。
柔軟な微調整方法:カスタムプロンプト、パラメーター変更、検索ソート、カスタマイズされたモデルトレーニングなど、さまざまな微調整方法をサポートし、組み込みのフルリンク RAG 効果評価モデルを備えています。
包括的な関連機能:マルチモーダルコンテンツの理解、構造化データと非構造化データの解析、複数ラウンドの会話、ストリーミング出力、意図認識、エージェント、その他の包括的な RAG 関連機能をサポートします。
便利なアクセス方法:DingTalk ロボットや Lark など、さまざまなエコシステムへのゼロコードクイックアクセスをサポートし、API/SDK などの多様で柔軟なアクセス方法をサポートし、API キーをさまざまなオープンソースの大規模モデルアプリケーション開発フレームワークに埋め込むことができます。
エンタープライズレベルの機能向上:エンタープライズレベルのドキュメント権限の隔離とリアルタイムの増分データ更新をサポートします。
バージョン選択
OpenSearch-LLM ベースの対話型検索エディションには、Standard Edition と Professional Edition の 2 つのバージョンがあります。次の表に、これら 2 つのバージョンの機能とその違いを示します。
比較項目 | Standard Edition | Professional Edition |
カスタマイズされたモデルトレーニング | サポートされていません。 | 独自のビジネスデータに基づく SFT をサポートします。 |
LLM 選択 | Qwen シリーズ、オープンソースモデル、外部モデルをサポートします。 | Qwen シリーズ、オープンソースモデル、外部モデル、およびカスタマイズされたモデルをサポートします。 |
制限 | 最大 10 QPS。 | 速度制限はありません。購入した GPU リソースが推論リクエストをサポートしている限り。 |
計算リソースの課金 | 呼び出し中に消費された計算リソースに基づいて従量課金されます。 | 購入した GPU の仕様に従って課金され、追加の計算リソース料金は必要ありません。 |
シナリオ | 一般的なインテリジェントカスタマーサービス、企業ナレッジベース、E コマースショッピングガイドなどに適しています。 | ビジネスデータが比較的特殊で、インテリジェントカスタマーサービス、企業ナレッジベース、E コマースショッピングガイドなどに専用の LLM を使用するためにトレーニングが必要なシナリオに適しています。 |
シナリオ
インテリジェントカスタマーサービス:
アプリ、ミニアプリ、Web サイトでインテリジェントなプリセールスおよびアフターセールスカスタマーサービスを提供します。さまざまな入力に基づいてユーザーの意図を分類および判断し、対応するサポートと回答を提供します。
手動介入に基づく固定の Q&A ペアをサポートします。
画像や動画などのマルチモーダルコンテンツの返却をサポートします。
ユーザーの注文、物流情報などに関する NL2SQL ベースのデータベースクエリをサポートします。
企業ナレッジベース:
社内ポータル Web サイトおよびチャットソフトウェアに企業ナレッジベースを構築して、従業員およびユーザーにナレッジサポートとクイックナビゲーションエントリを提供します。
エンタープライズレベルのドキュメント権限の隔離をサポートします。
リアルタイムのデータ更新とインデックス構築をサポートします。
さまざまな非構造化データの解析と理解をサポートします。
E コマースショッピングガイド:
E コマースおよび小売アプリと Web サイトの既存の検索ボックスまたはショッピングガイドカスタマーサービスに、インテリジェントショッピングガイド機能を追加します。ユーザーの対話情報を組み合わせて、関連商品をインテリジェントに推奨します。
商品画像などの情報を含めることができる、画像などのマルチモーダルコンテンツの理解をサポートします。
ターゲット商品にすばやくアクセスするための商品検索へのリンクの返却をサポートします。
運用ニーズに基づいて商品検索のソートを調整することをサポートします。
コンテンツとコミュニティの概要:
コンテンツおよびコミュニティアプリと Web サイトでは、内部コンテンツデータに基づいて、既存の検索ボックスにインテリジェントな要約機能を追加します。 Web サイトのコンテンツ概要を使用して、ユーザーの対話情報に基づいて戦略と参考文献を生成します。
Web ページと Web サイトのコンテンツの迅速なインポートをサポートします。
OCR と大規模モデルに基づく、画像などのマルチモーダルコンテンツの理解をサポートします。
元のドキュメントへの参照リンクの返却をサポートします。
テーブル Q&A:
ビジネスや金融など、さまざまな業界シナリオの構造化データ情報について、NL2SQL 機能に基づいて関連コンテンツをすばやく検索し、LLM を介して関連情報をすばやく要約して返します。
カスタムテーブル構造をサポートします。
MaxCompute データソースデータの自動同期をサポートします。
NL2SQL に基づく情報の抽出、要約、および集約をサポートします。