OpenSearch の LLM-based AI Chat Edition は、非構造化データ処理、ベクトルモデル、テキスト検索とベクトル検索、大規模言語モデル (LLM) を統合した、ワンストップですぐに利用できる検索拡張生成 (RAG) ソリューションです。さまざまな形式のデータをインポートして、対話、リンク、画像をサポートするマルチモーダルな対話型検索サービスを構築できます。
製品紹介
LLM-based AI Chat Edition は、業界固有の検索シナリオを対象として、企業に専用の Q&A 検索サービスを提供します。組み込みの LLM により、ビジネスデータを使用して回答、参照画像、参照リンクを自動生成する Q&A 検索システムを迅速にデプロイできます。
サービスアーキテクチャ
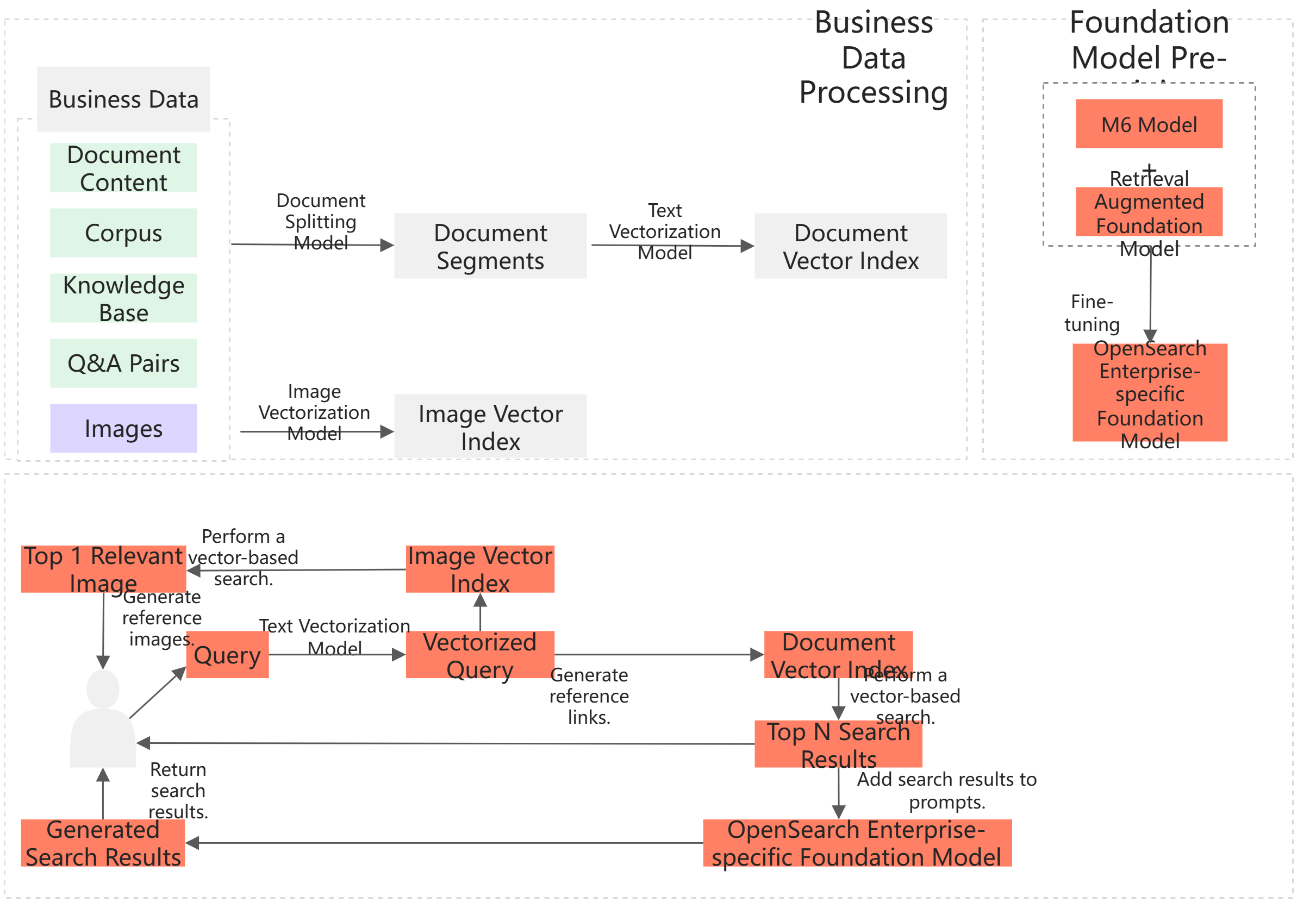
製品の機能
-
マルチモーダル RAG:画像コンテンツを理解します。OCR や LLM などのツールを使用してマルチモーダルナレッジベースを構築し、多様な出力を提供します。
-
RAG パフォーマンス評価:エンドツーエンドのパフォーマンスを評価します。異なるモデルやパラメータ設定での RAG 結果を比較し、パフォーマンス比較とモデル選択を簡素化します。
-
豊富なモデル機能とカスタムモデルトレーニング:豊富な組み込みベクトルモデル、リランキングモデル、大規模言語モデルが含まれています。ビジネスデータを使用してカスタム大規模モデルをトレーニングできます。
-
リアルタイムデータ更新:増分ベクトルインデックスをリアルタイムで構築します。データは即座に同期され、更新されます。
-
テーブル Q&A:NL2SQL を使用したテーブルベースの Q&A に対応しています。これにより、企業の構造化データベースに対する対話型検索と Q&A が可能になります。
-
デプロイ不要、フルマネージド、運用保守不要:デプロイや運用保守が不要な、クラウド上のフルマネージド MaaS (Model-as-a-Service) です。
利点
-
ワンストップでの迅速な統合:内蔵のエンドツーエンド RAG フローにより、コンソールでビジネスデータをアップロードするだけで、数分で RAG システムを構築できます。
-
優れた RAG パフォーマンス:豊富な組み込みベクトルモデル、リランキングモデル、大規模言語モデルが含まれています。当社のモデル機能は業界のリーダーボードで繰り返し首位を獲得しており、95% を超える RAG 精度を保証します。
-
柔軟なチューニング方法:カスタムプロンプト、パラメータ変更、検索結果のソート、カスタムモデルトレーニングなど、さまざまなパフォーマンスチューニング方法に対応しています。エンドツーエンドの RAG パフォーマンス評価用の組み込みモデルが含まれています。
-
包括的な関連機能:マルチモーダルコンテンツ理解、構造化データと非構造化データの解析、マルチターン対話、ストリーミング出力、インテント認識、エージェントなど、RAG 関連のあらゆる機能に対応しています。
-
便利な接続方法:DingTalk ロボットや Lark など、さまざまなエコシステムとのノーコードでの迅速な統合に対応しています。また、API やソフトウェア開発キット (SDK) といった柔軟な接続方法にも対応しています。API キーを使用して、さまざまなオープンソース大規模モデルアプリケーション開発フレームワークにサービスを組み込むことができます。
-
完全なエンタープライズ級機能:エンタープライズ級のドキュメントの権限分離と、増分データのリアルタイム更新に対応しています。
バージョンの選択
OpenSearch の LLM-based AI Chat Edition には、Standard Edition と Professional Edition の 2 つのバージョンがあります。以下の表で機能を比較します。
|
比較項目 |
Standard Edition |
Professional Edition |
|
カスタムモデルトレーニング |
サポートされていません。 |
独自のビジネスデータに基づく教師ありファインチューニング (SFT) に対応しています。 |
|
LLM の選択 |
Qwen シリーズ、オープンソースモデル、外部モデルに対応しています。 |
Qwen シリーズ、オープンソースモデル、外部モデル、カスタムモデルに対応しています。 |
|
制限 |
最大 10 QPS (秒間クエリ数) でスロットリングされます。 |
スロットリングはありません。購入した GPU リソースが十分な数の推論リクエストを処理できる限り、制限は適用されません。 |
|
コンピューティングリソースの課金 |
呼び出しごとに消費されるコンピューティングリソースに基づく従量課金です。 |
購入した GPU 仕様に応じて課金されます。コンピューティングリソースの追加料金はかかりません。 |
|
シナリオ |
一般的な AI カスタマーサービス、企業ナレッジベース、e コマースショッピングガイドなどのシナリオに適しています。 |
AI カスタマーサービス、企業ナレッジベース、e コマースショッピングガイドなど、専門的なビジネスデータを活用し、カスタム LLM のトレーニングや使用が必要となるシナリオに適しています。 |
シナリオ
AI カスタマーサービス:
アプリ、ミニプログラム、Web サイトでインテリジェントなプリセールスおよびアフターセールスサポートを提供します。サービスはユーザーのインテントを分類し、関連する回答を提供します。
-
手動介入に基づく固定の Q&A ペアに対応しています。
-
画像や動画などのマルチモーダルコンテンツの出力に対応しています。
-
NL2SQL を使用して、データベースからユーザーの注文、物流情報などを照会することに対応しています。
企業ナレッジベース:
社内ポータルやチャットソフトウェア内に企業ナレッジベースを構築し、従業員にナレッジサポートとクイックナビゲーションを提供します。
-
エンタープライズ級のドキュメントの権限分離に対応しています。
-
リアルタイムデータ更新とインデックス構築に対応しています。
-
さまざまな種類の非構造化データの解析と理解に対応しています。
e コマースショッピングガイド:
e コマースおよび小売アプリの検索ボックスまたはカスタマーサービスチャットにインテリジェントなショッピングガイド機能を追加します。サービスは会話履歴を使用して関連製品を推奨します。
-
製品画像を含む、画像などのマルチモーダルコンテンツの理解に対応しています。
-
ターゲット製品への迅速なアクセスのために、元の製品検索リンクの返却に対応しています。
-
運用ニーズに基づいて製品検索結果のソートを調整することに対応しています。
コンテンツおよびコミュニティの要約:
コンテンツおよびコミュニティアプリの検索ボックスにインテリジェントな要約を追加します。サービスは、サイトのコンテンツに基づくガイドや参照情報を利用して、ユーザーのクエリに応答します。
-
Web ページおよび Web サイトコンテンツの迅速なインポートに対応しています。
-
OCR、大規模モデル、その他のツールを使用した画像などのマルチモーダルコンテンツの理解に対応しています。
-
元の参照ドキュメントへのリンクの返却に対応しています。
テーブル Q&A:
ビジネスや金融などの業界における構造化データを対象に、NL2SQL を使用して関連コンテンツを照会します。その後、LLM が結果を要約して返します。
-
カスタムテーブルスキーマに対応しています。
-
MaxCompute データソースからの自動データ同期に対応しています。
-
NL2SQL を使用した情報抽出、要約、集約に対応しています。