Chatbox は、AI クライアントアプリケーションであり、スマートアシスタントです。コンピューティング環境を構成することなく、大規模言語モデル (LLM) とチャットできます。
前提条件
1. Chatbox の起動
Chatbox にアクセスします。ご利用のデバイス用のバージョンをダウンロードしてインストールするか、[ウェブ版を直接起動] することもできます。
2. モデルと API キーの設定
2.1. カスタムプロバイダーの選択
Chatbox ページ左下の [設定] をクリックします。[モデルプロバイダー] をクリックし、下部にある [追加] をクリックします。
表示されるダイアログボックスで、[名前] を「DashScope」に、[API モード] を [OpenAI API 互換] に設定します。その後、[追加] をクリックします。
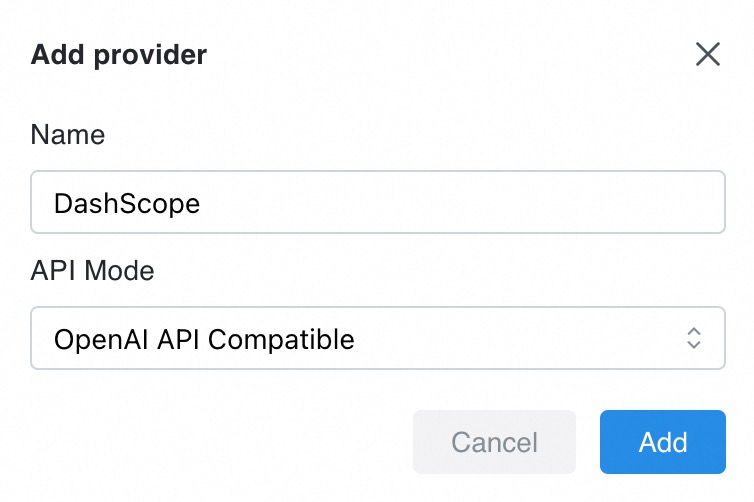
2.2. モデルと API キーの設定
|
|
2.3. 会話設定
モデルと API キーを設定した後、設定ページの左側にある [会話設定] をクリックします。ダイアログボックスで、[コンテキストメッセージの最大数] と [温度] パラメーターを設定します:
[コンテキストメッセージの最大数]
このパラメーターは、新しい質問ごとに LLM が考慮する過去の対話のターン数を指定します。カジュアルなチャットの場合、5 から 10 の設定が推奨されます。コンテキストメッセージの数が多いと、次のエラーが発生する可能性があります:
Range of input length should be [1, xxx]。温度
このパラメーターは、LLM によって生成されるテキストの多様性をコントロールします。
[温度] を高くすると、より多様なテキストが生成され、コンテンツ作成やブレインストーミングなどのシナリオに適しています。
[温度] を低くすると、より決定論的なテキストが生成されます。これは、コード作成や数学的推論などのシナリオに適しています。
このパラメーターは 2 未満の値に設定してください。そうしないと、エラー「
'temperature' must be Float」が報告されます。Top P
温度パラメーターと同様に、このパラメーターは生成されるテキストの多様性をコントロールします。
このパラメーターは 1 以下の値に設定してください。そうしないと、「xx is greater than the maximum of 1 - 'top_p'」というエラーが報告されます。
3. 会話の開始
ダイアログボックスに質問を入力して、会話を開始します。
現在、会話でビデオまたはオーディオファイルを使用することはできません。
通常の会話
入力ボックスに「あなたは誰ですか?」と入力して、設定をテストします:
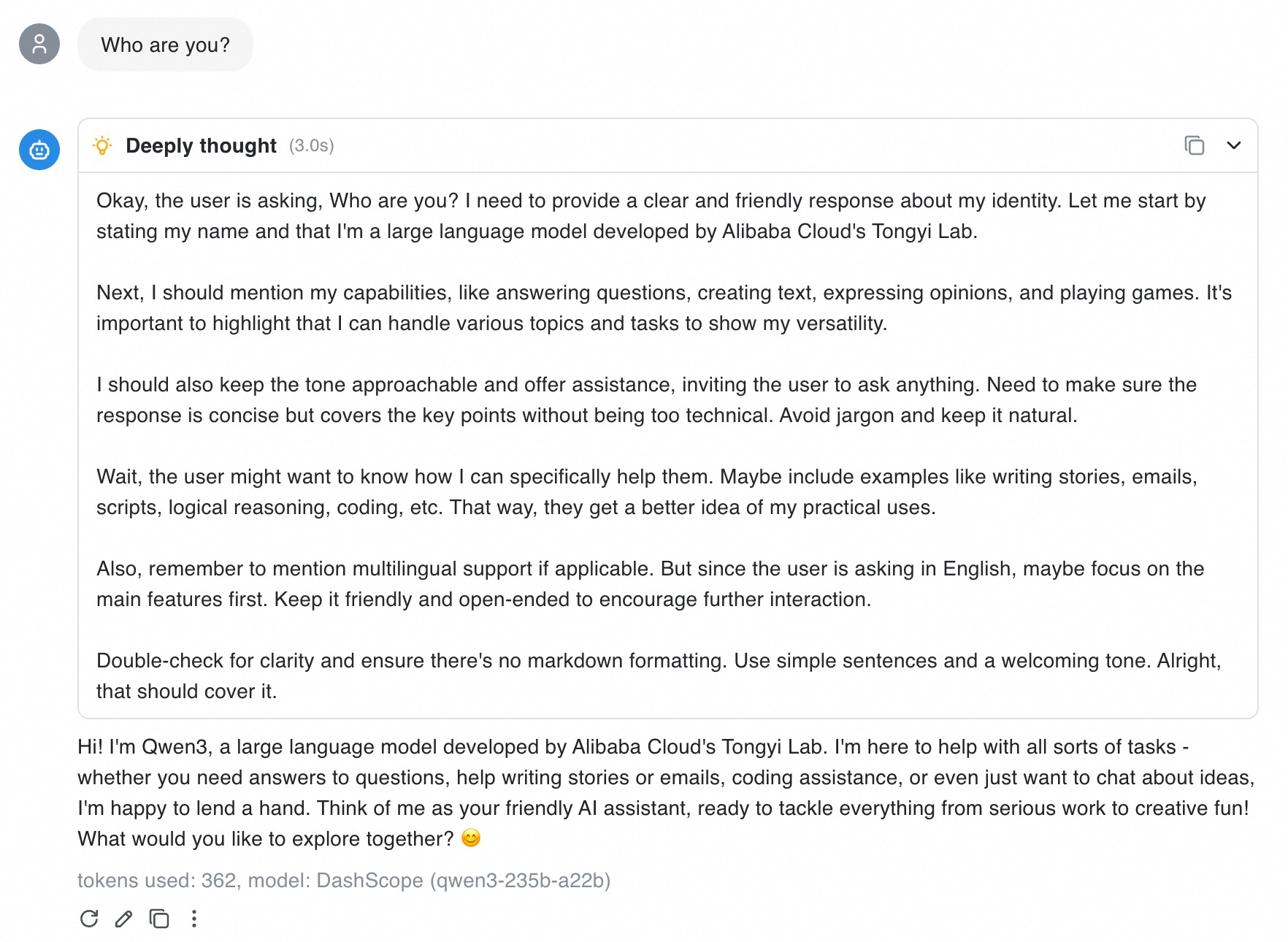
Chatbox に Qwen3 モデルの思考プロセスと応答が表示されます。
画像の入力
1. モデルの選択
画像を使用した Q&A には、視覚機能を持つモデルが必要です。設定時に、Qwen-VL、QVQ、または Qwen-Omni モデルを選択します。
詳細については、「2.2. モデルと API キーの設定」をご参照ください。[モデル] で、使用したい視覚モデルを追加し、[ビジョン] 機能を選択します。
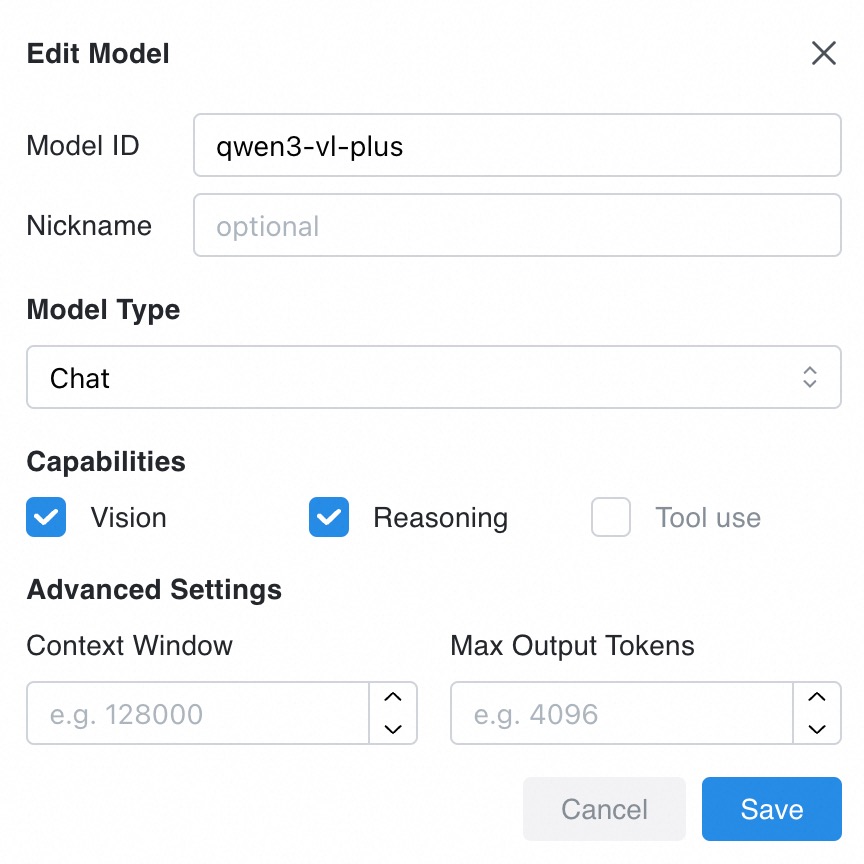
2. 対話
送信ボタン ![]() の横にある視覚モデルを選択します。入力ボックスに質問を入力し、
の横にある視覚モデルを選択します。入力ボックスに質問を入力し、![]() アイコンをクリックして、[画像を追加] を選択し、画像をアップロードします。
アイコンをクリックして、[画像を追加] を選択し、画像をアップロードします。
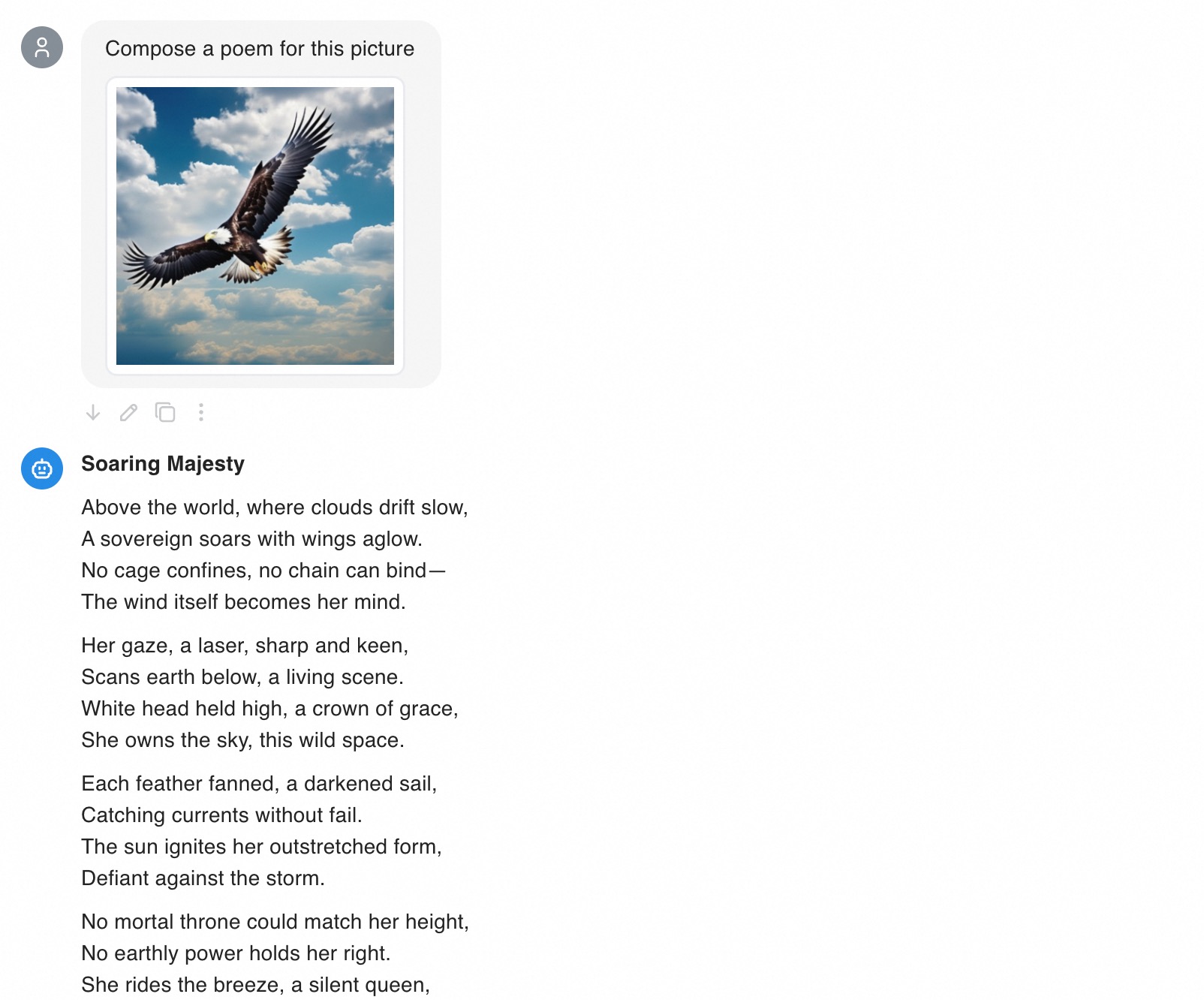
ドキュメントの入力
Chatbox は PDF、DOCX、TXT などのファイルをサポートしており、モデルがドキュメントの内容に基づいて質問に回答できます。
現在、Chatbox はドキュメント内の画像情報を解析できません。
1. モデルの選択
長文コンテキスト処理機能を持つモデルは、ドキュメント Q&A に適しています。Qwen-Flash、Qwen-Long、qwen2.5-14b-instruct-1m、または qwen2.5-7b-instruct-1m を選択します。これらのモデルは数百万のトークンを処理でき、より低価格で提供されています。
詳細については、「2.2. モデルと API キーの設定」をご参照ください。[モデル] で、使用したいモデルを追加します。この例では qwen-flash を使用します。
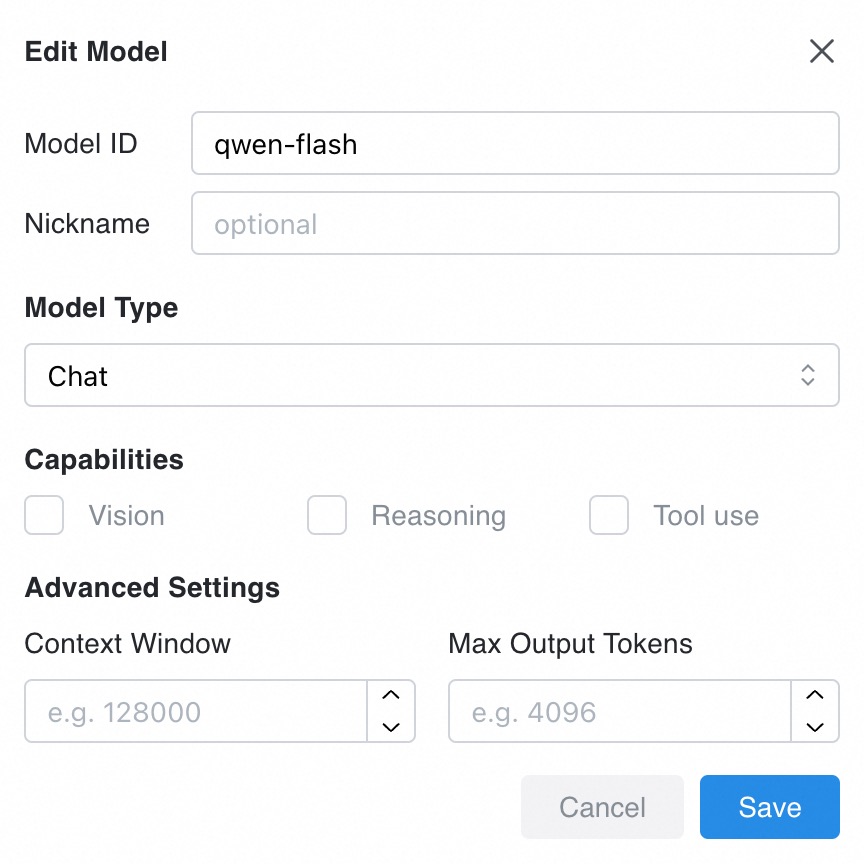
2. 会話の開始
送信ボタン ![]() の横で追加したモデルを選択します。入力ボックスに質問を入力し、
の横で追加したモデルを選択します。入力ボックスに質問を入力し、![]() アイコンをクリックしてから、[ファイルを選択] をクリックします。
アイコンをクリックしてから、[ファイルを選択] をクリックします。
ドキュメントに基づいて複数の質問をすると、多くのトークンを消費する可能性があります。コストを節約するために、[コンテキストメッセージの最大数] を低く設定して入力トークン数を減らすことができます。また、qwen-flash モデルを使用することもできます。このモデルは コンテキストキャッシュ をサポートしており、マルチターン対話での入力トークンコストを削減できます。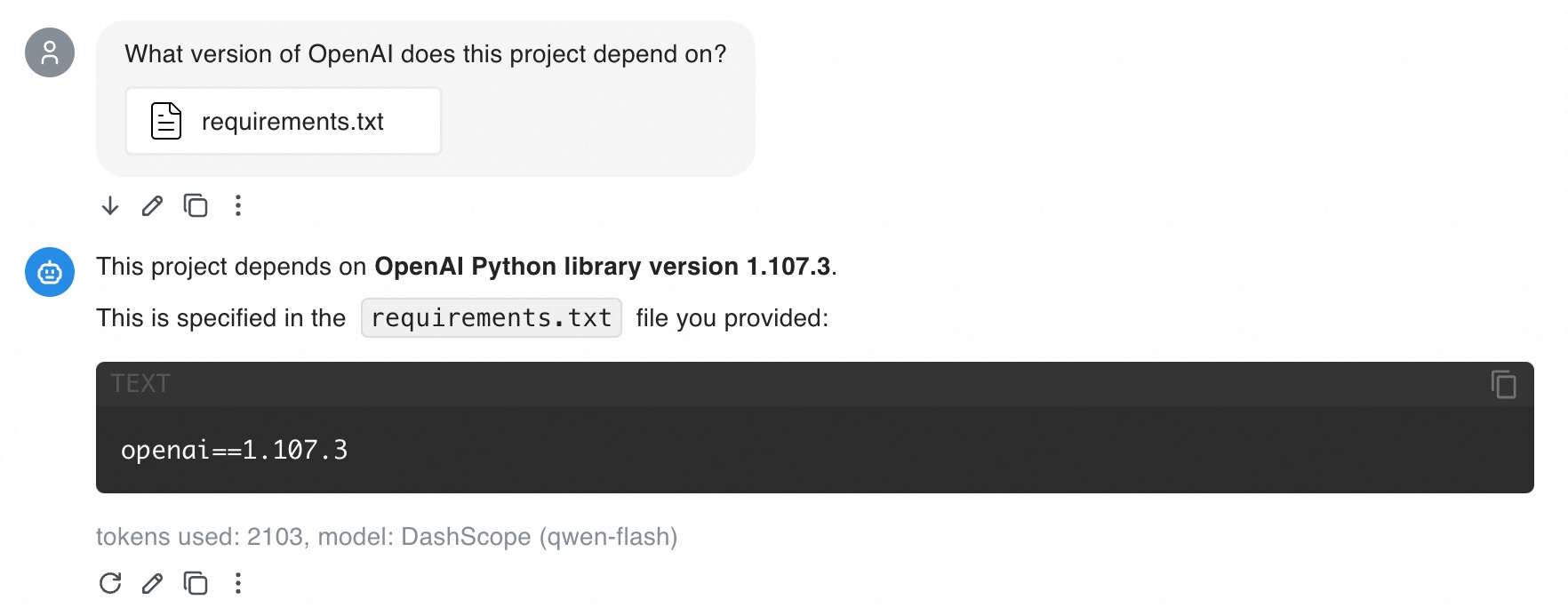
よくある質問
Q:課金方法は?
A:Alibaba Cloud Model Studio は、モデルの入力および出力トークンに基づいて課金します。モデルトークンのコストについては、「モデルリスト」をご参照ください。
マルチターン対話には過去の会話履歴が含まれるため、より多くのトークンを消費します。不要なトークン消費を減らすには、新しい会話を開始するか、[コンテキストメッセージの最大数] を低く設定します。カジュアルなチャットの場合、[コンテキストメッセージの最大数] は 5 から 10 に設定することを推奨します。
Q:Chatbox で「Failed to connect to Custom Provider」というエラーが報告された場合はどうすればよいですか?
A:エラーメッセージに基づいてトラブルシューティングを行います:
Range of input length should be [1, xxx]
このエラーは、入力が長すぎる場合や、マルチターン対話で蓄積されたコンテキストがモデルの最大コンテキスト長を超えた場合に発生する可能性があります。シナリオに基づいてトラブルシューティングできます:
最初のターンでのエラー
入力したテキストが長すぎるか、アップロードしたファイルのトークン数が多すぎる可能性があります。qwen-flash や qwen-long のような 1,000,000 のコンテキスト長を持つモデルを使用して、リクエストを処理できます。
マルチターン対話後のエラー
マルチターン対話で蓄積されたトークンが、モデルの最大コンテキスト長を超えた可能性があります。次のいずれかの方法を試すことができます:
新しい会話を開始する
LLM は返信する際に、過去の会話を参照しなくなります。
[コンテキストメッセージの最大数] を減らす
これにより、LLM は返信する際に限られた範囲の会話履歴のみを参照するようになり、すべての過去の会話を入力として使用することを回避します。
モデルを変更する
qwen-flash や qwen-long のような 1,000,000 のコンテキスト長を持つモデルに切り替えることで、より長いコンテキストを処理し、より多くの対話ターンを可能にすることができます。
'temperature' must be Float
モデルの
温度パラメーターは2未満である必要があります。[温度]パラメーターを2未満の値に設定してください。
上記に問題が記載されていない場合は、「エラーメッセージ」をご参照のうえ、トラブルシューティングを行ってください。
Q:アップロードされた画像とドキュメントの制限は?
A:
画像:アップロードされた画像の制限については、「画像と動画の理解」をご参照ください。
ドキュメント:Chatbox はアップロードされたドキュメントを解析します。解析されたテキストと会話コンテキストの合計トークン長は、モデルの最大コンテキスト長を超えてはなりません。