このトピックでは、Lindorm コンピュートエンジンのオンライン分析処理 (OLAP) または抽出・変換・書き出し (ETL) リソースグループを使用して、SQL でデータを迅速に読み書きする方法について説明します。
前提条件
LindormTable がアクティブ化されていること。詳細については、「インスタンスの作成」をご参照ください。
Lindorm コンピュートエンジンがアクティブ化されていること。詳細については、「サービスのアクティブ化」をご参照ください。
クライアント IP アドレスが Lindorm のホワイトリストに追加されていること。詳細については、「ホワイトリストの設定」をご参照ください。
OLAP リソースグループの使用
コンピュートエンジンの OLAP リソースグループは、MySQL 互換のアクセスインターフェイスを提供します。クエリ分析シナリオ向けに設計されており、高同時実行性かつ低レイテンシーのクエリ応答を実現します。OLAP リソースグループを作成すると、専用の計算リソースが割り当てられ、高速なクエリ応答が保証されます。
ステップ 1: OLAP リソースグループの作成
Lindorm コンソールにログインします。ページの左上隅で、インスタンスのリージョンを選択します。Instances ページで、対象インスタンスの ID をクリックするか、インスタンスの Actions 列にある View Instance Details をクリックします。
Instance Details ページの Configurations セクションに移動し、Compute Engine 列の リソースグループの管理 をクリックします。
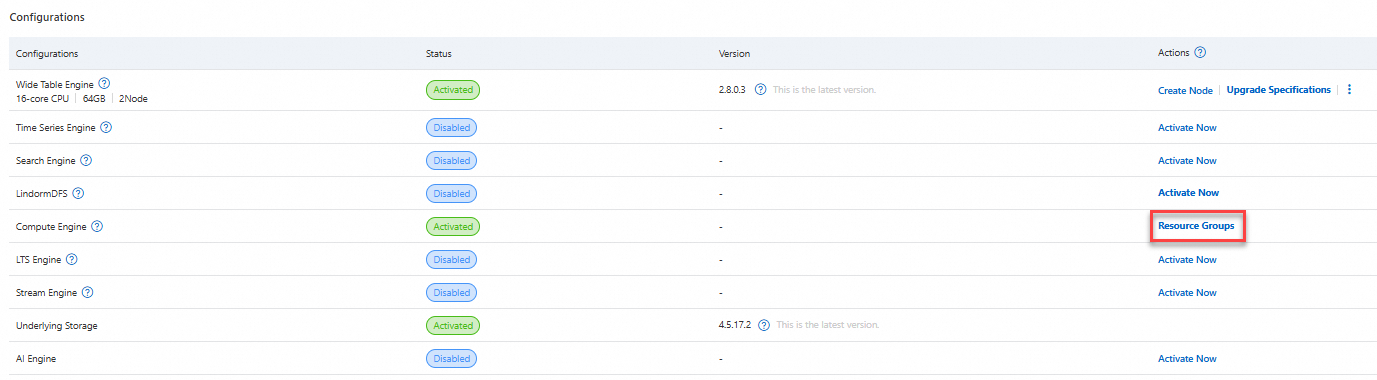
リソースグループの詳細 ページで、リソースグループの作成 をクリックし、以下を設定します:
パラメーター
説明
リソースグループタイプ
[OLAP] を選択します。
リソースグループ名
リソースグループの名前。名前には小文字と数字のみ使用できます。名前の長さは最大 63 文字です。例:
cg0。Node Specifications
ノード仕様を選択します。
ジョブワーカーノードの数
値は [4, 1024] の範囲内である必要があります。デフォルト値は
4です。OK をクリックしてリソースグループを作成します。
説明作成プロセスには約 20 分かかります。
リソースグループの詳細 ページで、新しく作成されたリソースグループのステータスが ステータスと説明情報 の下で 実行中 になったら、OLAP リソースグループ名にカーソルを合わせると、その VPC 内部エンドポイント (例:
jdbc:mysql://ld-bp1dv48fk0yg0****-olap-proxy-ldps.lindorm.aliyuncs.com:9030) を取得できます。MySQL クライアントを設定した後、JDBC を使用して OLAP リソースグループの VPC エンドポイントに接続します。LindormTable のユーザー名とパスワードを使用してログインします。その後、SQL クエリを実行できます。
mysql -hld-bp1dv48fk0yg0****-olap-proxy-ldps.lindorm.aliyuncs.com -P9030 -uroot -p
ステップ 2: データへのアクセス
列ストアデータへのアクセス
列ストアは、列指向ストレージを使用し、Iceberg エコシステムと互換性のあるデータレイクです。データは Lindorm インスタンスのファイルエンジンに保存されます。OLAP リソースグループを使用して、データの書き込みとクエリができます。
列ストアデータは lindorm_columnar カタログに保存されます。カタログは、異なるデータソースを識別するために使用されます。MySQL プロトコルを使用して接続すると、このカタログにデフォルトでアクセスします。SET CATALOG lindorm_columnar; コマンドを実行して、明示的に列ストアデータカタログに切り替えることもできます。
データベースを作成して使用します。
-- データベースを作成します。 CREATE DATABASE olapdemo; -- データベースを使用します。 USE olapdemo;テーブルを作成し、データを書き込みます。
-- テーブルを作成します。 CREATE TABLE test (id INT, name STRING) ENGINE = iceberg; -- データを挿入します。 INSERT INTO test VALUES (0, 'Jay'), (1, 'Edison');データをクエリします。
例 1:
SELECT id, name FROM test WHERE id != 0;次の結果が返されます:
+------+--------+ | id | name | +------+--------+ | 1 | Edison | +------+--------+例 2:
SELECT count(distinct name) FROM test;次の結果が返されます:
+----------------------+ | count(DISTINCT name) | +----------------------+ | 2 | +----------------------+例 3:
SELECT * FROM (SELECT id, name FROM test WHERE id != 0) t0 JOIN (SELECT id, name FROM test WHERE id != 2) t1 ON t0.id=t1.id;+------+--------+------+--------+ | id | name | id | name | +------+--------+------+--------+ | 1 | Edison | 1 | Edison | +------+--------+------+--------+
テーブルを削除します。
DROP TABLE test;データベースを削除します。
DROP DATABASE olapdemo;
ワイドテーブルデータへのアクセス
OLAP リソースグループは、LindormTable のデータを直接クエリすることをサポートしています。その計算能力を使用して、複雑なクエリを効率的に実行できます。OLAP リソースグループはクエリ操作のみをサポートし、LindormTable へのテーブル作成やデータ書き込みはサポートしていません。
LindormTable データは lindorm_table カタログに保存されます。このデータにアクセスするには、SET CATALOG lindorm_table; コマンドを実行してカタログを切り替える必要があります。
ワイドテーブルが既にある場合は、次のステップに進みます。そうでない場合は、LindormTable に接続し、次の文を実行して tb という名前のワイドテーブルを作成します。
-- データベースを作成します。
CREATE DATABASE test;
-- データベースを使用します。
USE test;
-- データテーブルを作成し、2行のデータを挿入します。
CREATE TABLE tb (id varchar, name varchar, address varchar, primary key(id, name)) ;
UPSERT INTO tb (id, name, address) values ('001', 'Jack', 'hz');
UPSERT INTO tb (id, name, address) values ('002', 'Edison', 'bj'); OLAP リソースグループに接続されている MySQL コマンドラインインターフェイス (CLI) で、次のクエリ文を実行してワイドテーブルデータにアクセスします。
データソースを明示的に切り替え、データベースを使用します。
-- データソースを明示的に切り替えます。 SET CATALOG lindorm_table; -- test データベースを使用します。 USE test;ワイドテーブルデータをクエリします。
例 1:
SELECT * FROM tb LIMIT 5;次の結果が返されます:
+------+--------+---------+ | id | name | address | +------+--------+---------+ | 001 | Jack | hz | | 002 | Edison | bj | +------+--------+---------+例 2:
SELECT count(*) FROM tb;次の結果が返されます:
+----------+ | count(*) | +----------+ | 2 | +----------+
ETL リソースグループの使用
コンピュートエンジン内の ETL リソースグループは、クエリの実行とデータの書き込みを行うためのサーバーレス Spark SQL を提供します。リソースはオンデマンドでリクエストされ、自動的にリリースされます。これにより、頻度の低いクエリやオフラインレポートに最適です。
ステップ 1:リソースグループのアクティブ化
Lindorm コンソールにログインします。 ページの左上隅で、インスタンスのリージョンを選択します。 Instances ページで、目的のインスタンスの ID をクリックするか、Actions 列の View Instance Details をクリックします。
Instance Details ページで、Configurations セクションに移動し、Compute Engine 列の リソースグループの管理 をクリックします。
リソースグループの詳細 ページで、リソースグループの作成 をクリックし、次のパラメーターを設定します:
パラメーター
説明
リソースグループタイプ
[ETL] を選択します。
リソースグループ名
リソースグループの名前です。名前には小文字と数字のみを使用でき、長さは 63 文字以内にする必要があります。例:
cg0。1 日あたりのリソース消費クォータ
リソースグループが 1 日あたりに消費できるキャパシティユニット (CU) の最大数です。単位は
CU*Hourです。デフォルト値は100000です。重要上限を超えると、ジョブは直ちに削除されます。高い安定性が求められるリソースグループの場合は、このパラメーターを
0に設定してください。値 0 は制限がないことを示します。CPU 上限 (コア)
リソースグループの CPU コアの最大数です。有効な値:[100, 100000]。
メモリ上限 (GB)
リソースグループの最大メモリサイズです。有効な値:[400 GB, 1000000 GB]。デフォルト値はありません。
許可されるユーザー
デフォルト値は
*です。これは、すべてのユーザーがリソースグループにアクセスできることを示します。リソースグループを作成するには、OK をクリックします。
ステップ 2:環境の準備
以下の環境は、Lindorm インスタンスと同じ Virtual Private Cloud (VPC) 内の Elastic Compute Service (ECS) インスタンスにデプロイされます。
Java 開発キット (JDK) 1.8 以降をインストールします。
またはSpark をダウンロードします。
Spark インストールパッケージを解凍します。
SPARK_HOME 環境変数を、パッケージを解凍したパスに設定します。
export SPARK_HOME=/path/to/spark/;$SPARK_HOME/conf/beeline.conf設定ファイルを編集します。endpoint:Lindorm コンピュートエンジンの JDBC URL です。URL の取得方法の詳細については、「エンドポイントの表示」をご参照ください。
user:LindormTable にアクセスするためのユーザー名です。
password:ユーザー名に対応するパスワードです。
shareResource:同じユーザーの複数のセッション間で計算リソースを共有するかどうかを指定します。デフォルト値は
trueです。compute-group:コンピュートエンジンが使用する ETL リソースグループの名前です。このパラメーターを設定しない場合、デフォルト値は
defaultです。
$SPARK_HOME/binディレクトリに移動し、./beelineコマンドを実行します。コマンドは次の出力を表示します。Welcome to Lindorm Distributed Processing System (LDPS) !!! Initializing environment. It might take minutes ... Environemnt prepared. You may visit your jdbc cluster by below url: http://alb-boqak6zfns5gzx****.cn-hangzhou.alb.aliyuncsslb.com/proxy/75ce76086b61470da7046bd4c2b7**** Please note -- you are sharing this JDBC cluster between SQL sessions from the same user. The cluster will be released by auto if idle for 4 hours. You may also kill it manually by visiting above web url and clicking 'kill' in tab of 'Query Engine' lindorm-beeline>対話型セッションで、SQL 文を入力して書き込みまたはクエリ操作を実行します。
説明返されたリンク
http://alb-boqak6zfns5gzx****.cn-hangzhou.alb.aliyuncsslb.com/proxy/75ce76086b61470da7046bd4c2b7****を使用して、コンピュートエンジンの Spark UI にアクセスします。
ステップ 3:データへのアクセス
列のストアデータへのアクセス
列のストアは、カラムナストレージを使用し、Iceberg エコシステムと互換性のあるデータレイクです。データは Lindorm インスタンスのファイルエンジンに保存されます。Spark SQL を使用して、データの書き込みとクエリを実行できます。
列のストアデータは lindorm_columnar カタログに保存されます。カタログは、さまざまなデータソースを識別するために使用されます。このカタログは、MySQL プロトコルを使用して接続する際にデフォルトでアクセスされます。SET CATALOG lindorm_columnar; コマンドを実行して、明示的に列のストアデータカタログに切り替えることもできます。
データベースを作成して使用します。
-- データベースの作成 CREATE DATABASE etldemo; -- データベースの使用 USE etldemo;データテーブルを作成し、データを書き込みます。
-- テーブルの作成 CREATE TABLE test (id INT, name STRING); -- データの挿入 INSERT INTO test VALUES (0, 'Jay'), (1, 'Edison');データをクエリします。
例 1:
SELECT id, name FROM test WHERE id != 0;次の結果が返されます。
+------+--------+ | id | name | +------+--------+ | 1 | Edison | +------+--------+例 2:
SELECT count(distinct name) FROM test;次の結果が返されます。
+----------------------+ | count(DISTINCT name) | +----------------------+ | 2 | +----------------------+例 3:
SELECT * FROM (SELECT id, name FROM test WHERE id != 0) t0 JOIN (SELECT id, name FROM test WHERE id != 2) t1 ON t0.id=t1.id;+------+--------+------+--------+ | id | name | id | name | +------+--------+------+--------+ | 1 | Edison | 1 | Edison | +------+--------+------+--------+
テーブルを削除します。
DROP TABLE test;データベースを削除します。
DROP DATABASE etldemo;
ワイドテーブルデータへのアクセス
ETL リソースグループの Spark SQL 接続を使用して、LindormTable のデータをクエリできます。弾力性のある計算リソースを使用して、ワイドテーブルデータに対して複雑なクエリや計算を実行できます。Spark SQL 接続は、LindormTable でのテーブルの作成や削除などのデータ定義言語 (DDL) 文をサポートしていません。ただし、データのクエリには使用できます。
LindormTable データは lindorm_table カタログに保存されます。このデータにアクセスするには、SET CATALOG lindorm_table; コマンドを実行してカタログを切り替える必要があります。
ワイドテーブルが既にある場合は、次のステップに進みます。そうでない場合は、「LindormTable への接続」を参照して、以下の文を実行し、tb という名前のワイドテーブルを作成します。
-- データベースの作成
CREATE DATABASE test;
-- データベースの使用
USE test;
-- データテーブルを作成し、2行のデータを挿入
CREATE TABLE tb (id varchar, name varchar, address varchar, primary key(id, name)) ;
UPSERT INTO tb (id, name, address) values ('001', 'Jack', 'hz');
UPSERT INTO tb (id, name, address) values ('002', 'Edison', 'bj'); lindorm-beeline 対話型セッションで、次のクエリ文を実行してワイドテーブルデータにアクセスします。
データソースを明示的に切り替え、データベースを使用します。
-- データソースを明示的に切り替え SET CATALOG lindorm_table; -- test データベースの使用 USE test;ワイドテーブルデータをクエリします。
例 1:
SELECT * FROM tb LIMIT 5;次の結果が返されます。
+------+--------+---------+ | id | name | address | +------+--------+---------+ | 001 | Jack | hz | | 002 | Edison | bj | +------+--------+---------+例 2:
SELECT count(*) FROM tb;次の結果が返されます。
+-----------+ | count(1) | +-----------+ | 2 | +-----------+