Hologresインスタンスの応答速度が低下し、メトリックがHologresインスタンス内の1つ以上のワーカーのCPU使用率が他のワーカーよりも低いことを示している場合、コンピューティングリソースが偏っている可能性があります。Hologresは新しいシステムビュー hologres.hg_worker_info を提供します。このビューを使用して、データベース内のワーカー、テーブルグループ、およびシャード間の関係をクエリできます。これにより、リソースの偏りの問題を特定して解決し、リソース使用率を向上させることができます。このトピックでは、hologres.hg_worker_info を使用してワーカー間のシャード割り当てをクエリする方法について説明します。
背景
Hologresにおけるワーカー、テーブルグループ、およびシャードの概念と関係の詳細については、「アーキテクチャ」および「基本概念」をご参照ください。シャードはワーカーに均等に割り当てられる必要があります。シャードがワーカーに均等に割り当てられていない場合、リソースの偏りが発生し、リソースが非効率的に使用される可能性があります。さらに、ワーカーメトリックはHologresコンソールに表示されます。 Hologres V1.3以降で提供される hologres.hg_worker_info システムビューは、データベース内のワーカー、テーブルグループ、およびシャード間の関係をクエリするのに役立ちます。クエリ結果に基づいて、リソースが不均一に割り当てられているかどうかを判断できます。
制限事項
hologres.hg_worker_info システムビューは、Hologres V1.3.23以降でのみサポートされています。 Hologresインスタンスのバージョンは、Hologresコンソールのインスタンス詳細ページで確認できます。 Hologresインスタンスのバージョンが V1.3.23 より前の場合、HologresコンソールでHologresインスタンスを手動でアップグレードするか、Hologres DingTalkグループに参加してインスタンスのアップグレードを申請してください。 Hologresインスタンスを手動でアップグレードする方法の詳細については、「インスタンスのアップグレード」をご参照ください。 Hologres DingTalkグループへの参加方法の詳細については、「Hologresのオンラインサポートを受ける」をご参照ください。
hologres.hg_worker_info システムビューには、ワーカー間のシャードのリアルタイム割り当てが表示されます。ワーカー間のシャードの履歴割り当てをクエリすることはできません。
テーブルグループを作成すると、
worker_idは 10〜20 秒の遅延で取得されます。テーブルグループを作成した直後にシステムビューをクエリすると、worker_idフィールドの値が空になる場合があります。テーブルグループにテーブルが存在しない場合、リソースはワーカーに割り当てられません。この場合、クエリ結果では
worker_idフィールドの値がid/0として表示されます。Hologres V2.1 以降では、ワーカーにシャードが割り当てられていない場合でもworker_idフィールドが表示されます。このフィールドの値は空で、ワーカーにシャードが割り当てられていないことを示します。現在のデータベース内のワーカー、テーブルグループ、およびシャードに関する情報のみをクエリできます。他のデータベースに関する情報をクエリすることはできません。
使用方法
次の表に、hologres.hg_worker_info システムビューに含まれるフィールドを示します。
フィールド | データ型 | 説明 |
worker_id | TEXT | 現在のデータベースに対応するワーカーのID。 |
table_group_name | TEXT | 現在のデータベース内のテーブルグループの名前。 |
shard_id | BIGINT | テーブルグループ内のシャードのID。 |
warehouse_id | BIGINT | ワーカーが属する仮想ウェアハウスの ID。 |
次のステートメントを実行して、hologres.hg_worker_info システムビューからワーカー間のシャード割り当てをクエリします。
select * from hologres.hg_worker_info;次のサンプルコードは、クエリ結果を示しています。
クエリ結果では、xx_tg_internal は Hologres インスタンスの組み込みテーブルグループです。このテーブルグループは、メタデータなどの情報を管理するために使用されます。このテーブルグループは無視してかまいません。
worker_id | table_group_name | shard_id
------------+------------------+----------
bca90a00ef | tg1 | 0
ea405b4a9c | tg1 | 1
bca90a00ef | tg1 | 2
ea405b4a9c | tg1 | 3
bca90a00ef | db2_tg_default | 0
ea405b4a9c | db2_tg_default | 1
bca90a00ef | db2_tg_default | 2
ea405b4a9c | db2_tg_default | 3
ea405b4a9c | db2_tg_internal | 3
ベストプラクティス:コンピューティングリソースの不均一な割り当て(ワーカー間の負荷の不均衡な分散)の問題のトラブルシューティング
Hologresでは、データはシャード間で分散されます。ワーカーは、計算中に1つ以上のシャードのデータにアクセスする場合があります。 Hologresインスタンスでは、シャードには一度に1つのワーカーしかアクセスできません。各ワーカーがアクセスするシャードの総数が異なる場合、ワーカーの負荷は不均衡になります。この場合、1つ以上のワーカーの CPU使用率 が低くなります。次の図は、ワーカー間の負荷の不均衡な分散の例を示しています。 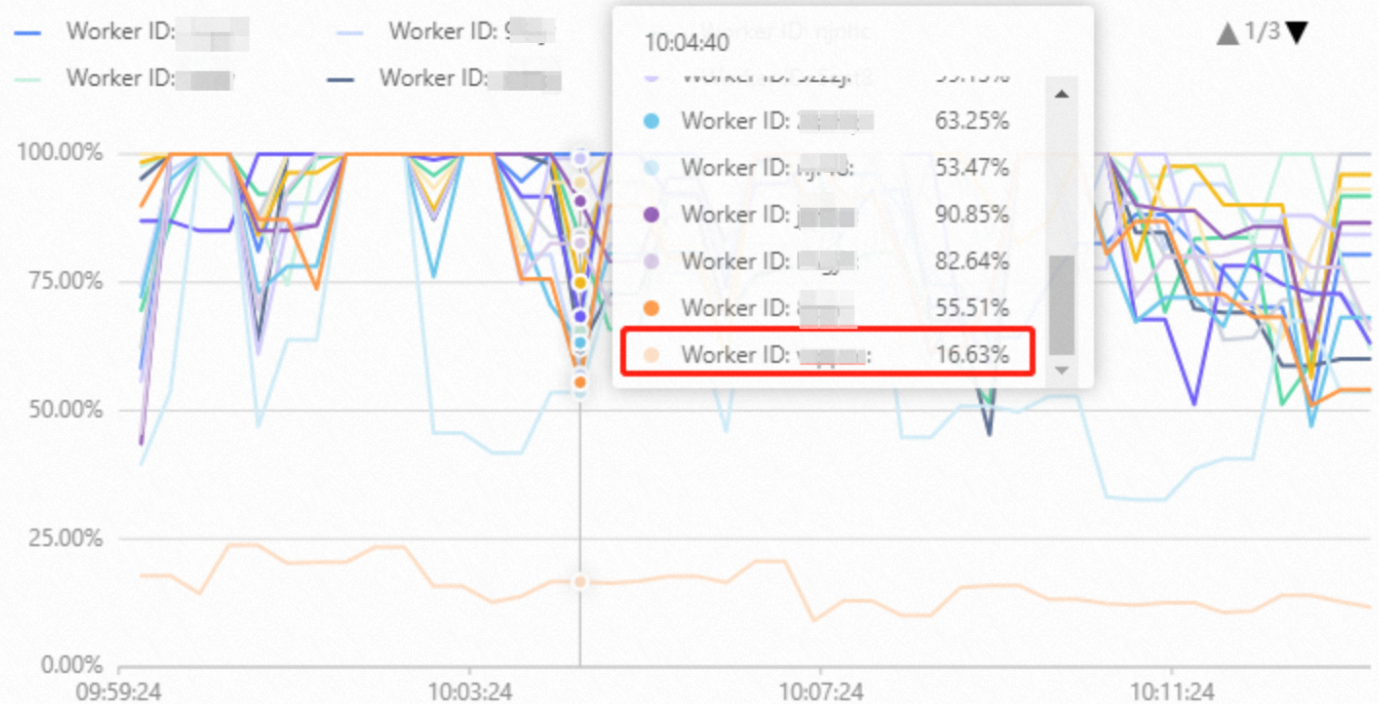 ワーカー間の負荷の不均衡な分散は、さまざまな原因で発生する可能性があります。 hologres.hg_worker_info システムビューを使用して、さらに分析できます。以下の情報は、問題の考えられる原因と解決策について説明しています。
ワーカー間の負荷の不均衡な分散は、さまざまな原因で発生する可能性があります。 hologres.hg_worker_info システムビューを使用して、さらに分析できます。以下の情報は、問題の考えられる原因と解決策について説明しています。
原因1:ワーカーのフェイルオーバー後、シャードがワーカーに不均一に割り当てられる。
「基本概念」で説明されているように、ワーカーがメモリ不足(OOM)エラーなどの原因でフェイルオーバーした場合、システムは障害が発生したワーカーのシャードを他のワーカーに割り当ててクエリを復旧します。ワーカーが復旧した後、システムはこのワーカーにいくつかのシャードを再割り当てします。これにより、ワーカー間のシャードの割り当てが不均一になります。 hologres.hg_worker_info システムビューでは、現在のデータベース内の各ワーカーに割り当てられているシャードの数をクエリできます。このようにして、コンピューティングリソースが不均一に割り当てられているかどうかを確認できます。 hologres.hg_worker_info システムビューには現在のデータベースに関する情報が表示されますが、ワーカーはインスタンス内のすべてのデータベースで共有されます。したがって、ワーカー間のシャード割り当てを確認する場合は、各データベース内の各ワーカーに割り当てられているシャードの数をクエリして、インスタンス内の各ワーカーに割り当てられているシャードの総数を取得し、コンピューティングリソースが不均一に割り当てられているかどうかを判断する必要があります。
サンプルステートメント
select worker_id, count(1) as shard_count from hologres.hg_worker_info group by worker_id;サンプル結果
-- この例では、インスタンスにはデータベースが 1 つしかなく、次の結果が返されます: worker_id | shard_count ------------+------------- bca90a | 4 ea405b | 4 tkn4vc | 4 bqw5cq | 3 mbbrf6 | 3 hsx66f | 1 (6 rows)結果の説明
インスタンスには6つのワーカーがあり、6つのワーカーに割り当てられているシャードの数は異なります。 Hologresコンソールのメトリックは、シャードが少ないワーカーのCPU使用率が他のワーカーよりも低いことを示しています。インスタンスのコンピューティングリソースは不均一に割り当てられています。
解決策
インスタンスを再起動します。このようにして、シャードはワーカー間で再割り当てされます。これにより、ワーカー間でシャードが均等に割り当てられます。インスタンスを再起動しない場合、別のワーカーに障害が発生したときに、アイドル状態のワーカーにより多くのリソースが割り当てられます。
原因2:データの偏りにより、コンピューティングリソースが不均一に割り当てられる。
ビジネスデータが著しくスキューしている場合、ほとんどのデータは一部のシャードに分散されます。データをクエリすると、ワーカーはこれらのシャードに頻繁にアクセスします。これにより、ワーカー間の CPU 負荷が不均衡になります。hologres.hg_worker_info および hologres.hg_table_properties システムビューを使用して、テーブル内のスキューしたデータに対応する
worker_idをクエリできます。次に、データスキューによって計算リソースが不均等に割り当てられているかどうかを判断できます。次の手順を実行します:データの偏りが存在するかどうかを確認します。
次のSQLステートメントを実行して、テーブルデータが偏っているかどうかを確認します。シャード内のデータ量が他のシャード内のデータ量と大幅に異なる場合、テーブルデータは偏っています。
select hg_shard_id,count(1) from <table_name> group by hg_shard_id order by 2; -- サンプル結果: シャード 39 のデータ量は他のシャードよりも著しく大きいです。これはデータスキューが存在することを示します。 hg_shard_id | count -------------+-------- 53 | 29130 65 | 28628 66 | 26970 70 | 28767 77 | 28753 24 | 30310 15 | 29550 39 | 164983worker_idをhg_shard_idフィールドで指定されたシャードの ID に基づいてクエリします。前のステップで、スキューしたシャードを見つけることができます。hologres.hg_worker_info および hologres.hg_table_properties システムビューを使用して、
hg_shard_idフィールドで指定されたシャードに対応するworker_idをクエリできます。サンプル文:SELECT distinct b.table_name, a.worker_id, a.table_group_name,a.shard_id from hologres.hg_worker_info a join (SELECT property_value, table_name FROM hologres.hg_table_properties WHERE property_key = 'table_group') b on a.table_group_name = b.property_value and b.table_name = '<tablename>' and shard_id=<shard_id>; -- サンプル結果 table_name | worker_id | table_group_name | shard_id ------------+------------+-------------------+------------------ table03 | bca90a00ef | db2_tg_default | 39クエリ結果の
worker_idで指定された ワーカーの CPU 使用率 が他のワーカーよりもはるかに高い場合、データスキューによって計算リソースが不均等に割り当てられています。
解決策
適切な分散キーを設定します。このようにして、データはシャード間で均等に分散できます。詳細については、「Hologres内部テーブルに対するクエリの パフォーマンス を最適化する」をご参照ください。
ビジネスデータが著しく偏っている場合は、テーブルを複数のテーブルに分割できます。たとえば、ライブストリーミングで行われた注文のテーブルの商品取扱高(GMV)は、ストリーマーによって明らかに異なる場合があります。
原因3:シャード数が正しく設定されていない。
ワーカー間の負荷を分散させるために、シャード数をワーカー数の倍数に設定することをお勧めします。シャード数が正しく設定されていない場合、ワーカー間の負荷が不均衡になる可能性があります。 hologres.hg_worker_info システムビューを使用して、現在のデータベースでテーブルグループのシャード数が正しく設定されているかどうかを確認できます。
サンプルステートメント
select table_group_name, worker_id, count(1) as shard_count, warehouse_id from hologres.hg_worker_info group by table_group_name, worker_id, warehouse_id order by table_group_name desc;サンプル結果
table_group_name | worker_id | shard_count | warehouse_id ------------------+------------+--------------+------------- tg2 | ea405b4a9c | 1 | 1 tg2 | bca90a00ef | 2 | 2 tg1 | ea405b4a9c | 5 | 1 tg1 | bca90a00ef | 6 | 2 db2_tg_default | bca90a00ef | 4 | 2 db2_tg_default | ea405b4a9c | 4 | 1 db2_tg_internal | bca90a00ef | 1 | 2 (7 rows)結果の説明(2つのワーカーを持つインスタンスの場合)
tg2テーブルグループには 3 つのシャードがあります。一方のワーカーには、もう一方のワーカーより 1 つ少ないシャードが割り当てられています。パフォーマンスが期待どおりでない場合は、適切な Shard Count を設定するか、インスタンスをスケールアウトすることをお勧めします。tg1テーブルグループには 11 個のシャードがあります。一方のワーカーには、もう一方のワーカーより 1 つ少ないシャードが割り当てられています。パフォーマンスが期待どおりでない場合は、適切な Shard Count を設定するか、インスタンスをスケールアウトすることをお勧めします。デフォルトのテーブルグループ
db2_tg_defaultには 8 つのシャードがあります。これにより、シャードはワーカーに均等に割り当てられます。
解決策
不適切なシャード数のためにリソースがワーカーに均等に割り当てられていない場合は、ビジネス要件に基づいてシャード数の設定を見積もります。シャード数をワーカー数の倍数に設定することをお勧めします。