Hologres は、コンピューティングとストレージの分離アーキテクチャを採用した、パフォーマンス専有型の分散リアルタイムデータウェアハウスエンジンです。データは、基盤となるストレージシステム上のデータパーティション (シャードとも呼ばれます) に保存されます。このトピックでは、Hologres におけるテーブルグループと Shard Count の概念について説明します。
テーブルグループとシャード
Hologres では、データは Pangu ストレージに保存されます。シャードはデータパーティションです。テーブルグループは、これらのシャードを管理するための論理ストレージの概念です。テーブルのデータは、固定されたシャードのグループに保存されます。このグループは、テーブルの作成時に割り当てられ、テーブルグループによって管理されます。データが書き込まれる際、分散キーに基づいて特定のシャードに分散されます。
テーブルグループは Hologres 固有の論理ストレージの概念であり、PostgreSQL には存在しません。テーブルグループは、PostgreSQL の表領域とは異なります。表領域はディレクトリのようにデータベースオブジェクトのストレージの場所を識別しますが、テーブルグループは基盤となる論理シャードのグループを表します。
次の図は、テーブルグループのレイアウトを示しています。 この図は、次の関係を示しています。
この図は、次の関係を示しています。
テーブルグループとスキーマの違い
スキーマは標準的なデータベースの概念ですが、テーブルグループは Hologres 固有の論理ストレージの概念です。異なるスキーマ内のテーブルが同じテーブルグループに属することができ、これは、それらがデータストレージに同じ基盤となるシャードのグループを使用することを意味します。
テーブルグループとデータベース (DB) の関係
データベース (DB) は 1 つ以上のテーブルグループを含むことができますが、デフォルトのテーブルグループにできるのは 1 つだけです。DB を作成すると、システムはデフォルトのテーブルグループも作成します。必要に応じて、テーブルグループを追加したり、デフォルトのテーブルグループを変更したりできます。
テーブルグループ間の違い
DB は複数のテーブルグループを持つことができます。ただし、異なるテーブルグループ内のシャードは重複しません。各シャードは、インスタンスレベルで一意の ID を持ちます。
Shard Count
テーブルグループ内のシャードの数がその Shard Count です。テーブルグループを作成する際には、Shard Count を指定する必要があります。テーブルグループが作成された後、その Shard Count を変更することはできません。Shard Count を調整するには、目的のシャード数で新しいテーブルグループを作成する必要があります。
シャードとテーブルの関係
シャードはテーブルデータを保存し、クエリを実行します。システムは分散キーに基づいてシャード間にデータを分散します。分散キーを設定しない場合、データはシャード間にランダムに分散されます。
テーブルグループは複数のテーブルを含むことができ、それらのテーブルは同じシャードのグループに分散されます。ただし、1 つのテーブルは 1 つのテーブルグループにしか属せません。テーブルグループにテーブルが含まれていない場合、システムはそれを自動的に削除します。
テーブルを別のテーブルグループに移動するには、新しいテーブルグループでテーブルを再作成するか、移行関数を使用してデータを移行する必要があります。
シャードとワーカーノードの関係
Hologres では、ストレージエンジン (SE) がデータの管理と処理を担当します。データ操作言語 (DML) の操作に対して、SE は単一またはバッチでの作成・読取・更新・削除 (CRUD) アクセスのためのインターフェイスを提供します。クエリエンジン (QE) はこれらのインターフェイスを使用してシャード上のデータにアクセスし、パフォーマンス専有型のデータ書き込みと読み取りを可能にします。
次の図は、ワーカーノード、SE、およびシャードのレイアウトを示しています。 この図は、テーブルグループとシャードがデータ分散に加えてワーカーノードにも関連していることを示しています。
この図は、テーブルグループとシャードがデータ分散に加えてワーカーノードにも関連していることを示しています。
テーブルグループを作成してその Shard Count を設定すると、各ワーカーノードは複数の内部 SE を作成します。各 SE は、単一のシャードの読み取りおよび書き込み操作を担当します。テーブルグループと Shard Count を明示的に設定しない場合、Hologres はデータベースの作成時にデフォルトのテーブルグループを作成し、デフォルトの Shard Count を設定します。詳細については、「インスタンス管理」をご参照ください。
システムは、計算リソースが均等に割り当てられるように、すべてのワーカー間で SE を均等に分散しようとします。
システムは、テーブルグループ内のシャードが複数のワーカーに分散されるようにします。これにより、テーブルグループのすべてのシャードが単一のワーカーに割り当てられ、他のワーカーがアイドル状態になるシナリオを防ぎます。ただし、テーブルグループの Shard Count が小さく、インスタンスに多くのワーカーがある場合、一部のワーカーにはシャードが割り当てられず、アイドル状態のままになることがあります。したがって、Shard Count を決定する際には、ビジネスニーズを考慮して、ワーカー数とインスタンス内の総シャード数のバランスを確保する必要があります。
前の図は、潜在的な問題を示しています。テーブルグループの Shard Count がワーカー数の倍数でない場合 (たとえば、
Table Group 1には 3 つのシャードがあるがワーカーは 2 つしかない場合)、1 つのワーカーには必然的に他のワーカーよりも多くの SE が割り当てられます。これは、計算中にリソースの偏りやロングテールレイテンシーを容易に引き起こす可能性があります。したがって、Shard Count はワーカー数の倍数に設定する必要があります。次の図に示すように、Table Group 1とTable Group 2の Shard Count はワーカー数の倍数であるため、計算リソースを均等に分散できます。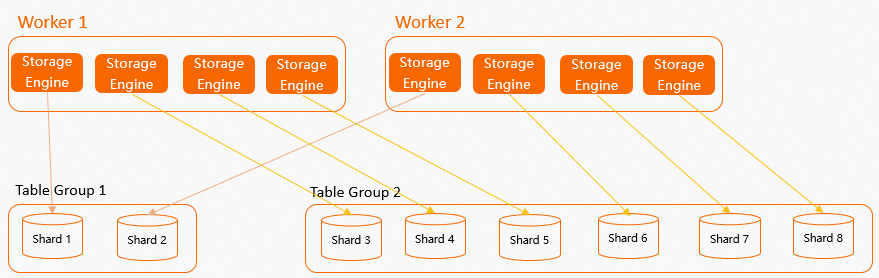
実際には、メモリ不足 (OOM) エラーなどの理由でワーカーがフェールオーバーすることがあります。これが発生すると、障害が発生したワーカー上のシャードは自動的に他のワーカーに再割り当てされます。システムは、残りのワーカー間でシャードができるだけ均等に分散されるようにします。たとえば、4 つのワーカーと 2 つのテーブルグループからの 8 つのシャードを持つインスタンスを考えます。各ワーカーには 2 つの SE があり、シャードは均等に分散されています。
Worker 4がフェールオーバーし、それがShard 7とShard 8を担当していたと仮定すると、Shard 7とShard 8はすぐに他の 3 つのワーカーに再割り当てされます。再割り当てが必要なシャードは 2 つだけなので、システムは残りのワーカーからランダムに 2 つを選択して割り当て、各ワーカーの SE 数をできるだけバランスの取れた状態に保ちます。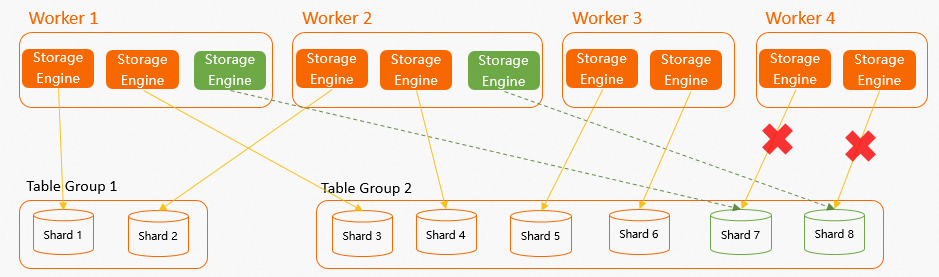
まとめ
ワーカー数は Shard Count と密接に関連しています。テーブルグループと Shard Count を適切に構成することで、データの書き込み、クエリ、分析においてより高い並列処理の次数を実現できます。この構成により、計算リソースの使用が最大化され、データストレージと計算の効率が向上します。逆に、テーブルグループと Shard Count が適切に設定されていない場合、パフォーマンスが期待どおりにならず、最適化が困難になる可能性があります。
特定の範囲内では、シャード数が多いテーブルグループほど、データの書き込み、クエリ、分析において高い並列処理の次数を達成できます。ただし、シャード数を増やすことが常に有益であるとは限りません。シャード数が増えると、より多くのノード間通信、計算リソース、およびメモリが必要になります。リソースが不足している場合やクエリが小さい場合、Shard Count が多いと逆効果になることがあります。
最小の Shard Count は 1 です。データ量が非常に少ない場合、たとえば数百行または数千行の場合は、Shard Count を 1 に設定する必要があります。テーブルグループの推奨される最大の Shard Count は、インスタンス内のコンピューティングコアの総数です。この構成により、各シャードが計算のために少なくとも 1 つのコアを持つことが保証されます。Shard Count がコンピューティングコアの数を超えると、クエリ中に一部のシャードに CPU リソースが一貫して割り当てられなくなります。これにより、ロングテールレイテンシーやコンテキストスイッチのオーバーヘッドが発生する可能性があります。
テーブルグループの数を増やすことが常に有益であるとは限りません。各シャードは、利用中であるかどうかにかかわらず、メタデータ、スキーマ情報、その他のデータを保存するためにメモリを占有します。シャードに含まれるテーブルにデータが書き込まれると、さらに多くのメモリを消費します。したがって、テーブルグループが多いほどインスタンス内の総シャード数が増え、メモリ消費量が増加します。さらに、ローカル JOIN が必要など、テーブル間に特別な関係がある場合は、同じテーブルグループに属している必要があります。
ディスク上では、同じテーブルに対してより多くのシャードを使用すると、データがより散在することになります。これにより、小さなファイルの数が増加する可能性があります。多くのテーブルと多くのシャードがある場合、ファイルの総数が非常に大きくなる可能性があります。これにより、クエリやフェールオーバー中のオーバーヘッドが増加し、クエリ I/O が増加し、回復時間が長くなります。