Hologres はストレージ分離アーキテクチャを採用しています。このページでは、アーキテクチャの設計と各コンポーネントの役割について説明します。
ストレージとコンピューティングのアーキテクチャモデル
分散システムでは、一般的に 3 つのストレージ・コンピューティングアーキテクチャが使用されます。
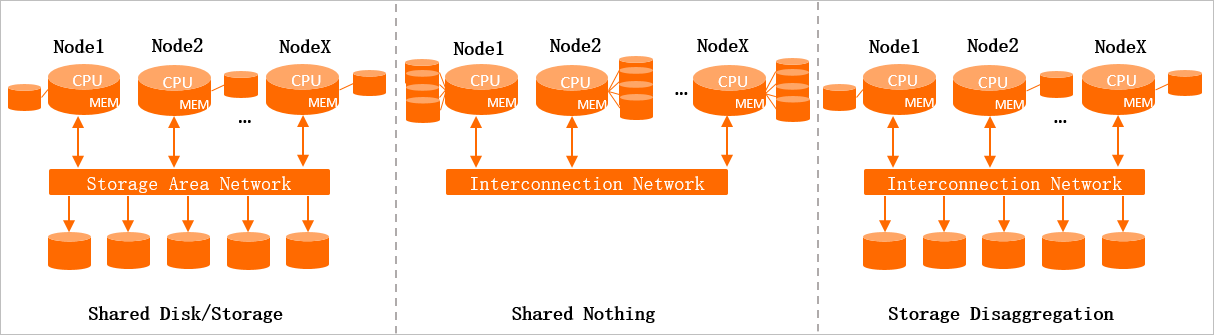
共有ディスク / 共有ストレージ
分散ストレージクラスターは、すべてのワーカーノードで共有されます。各ワーカーノードは、ローカルにあるかのようにデータにアクセスします。ストレージクラスターは容易にスケールしますが、ワーカーノードは整合性を維持するために分散コーディネーションを必要とし、これがワーカーノードの最大数を制限します。
シェアードナッシング
各ワーカーノードは、独自のローカルストレージをマウントし、単一のシャードからのデータを処理します。ワーカーノードは互いに通信し、専用の集約ノードが結果を集約します。このアーキテクチャは水平にスケールしますが、トレードオフがあります。フェイルオーバー後、回復中のノードはリクエストを処理する前にデータを再読み込みする必要があり、スケールアウトを行うとノード間でデータリバランスがトリガーされ、時間のかかるプロセスとなります。
ストレージ分離
分散ストレージクラスターは共有されますが、各コンピューティングノードはシェアードナッシングと同様に専用のシャードからのデータを処理し、ローカルキャッシュを維持します。このアーキテクチャには、以下の利点があります。
容易なデータ整合性:一度に 1 つのワーカーノードのみがシャードに書き込むため、複雑なコーディネーションが不要になります。
柔軟なスケーリング:コンピューティングリソースとストレージリソースは独立してスケールします。トラフィックのピーク時には、データリバランスをトリガーすることなく、コンピューティングレイヤーのみをスケールアウトできます。
迅速なフェイルオーバー復旧:障害発生後、新しいノードは分散ストレージから非同期でデータをプルし、迅速にサービスを再開します。
Hologres は、共有ストレージの管理のシンプルさと、シャードベースのコンピューティングのパフォーマンスおよびスケーラビリティを組み合わせたストレージ分離アーキテクチャを採用しています。基盤となるストレージは、Alibaba の分散ファイルシステムである Pangu であり、Hadoop 分散ファイルシステム (HDFS) と同様の役割を果たします。
Hologres アーキテクチャのコンポーネント
次の図は、Hologres のアーキテクチャを示しています。
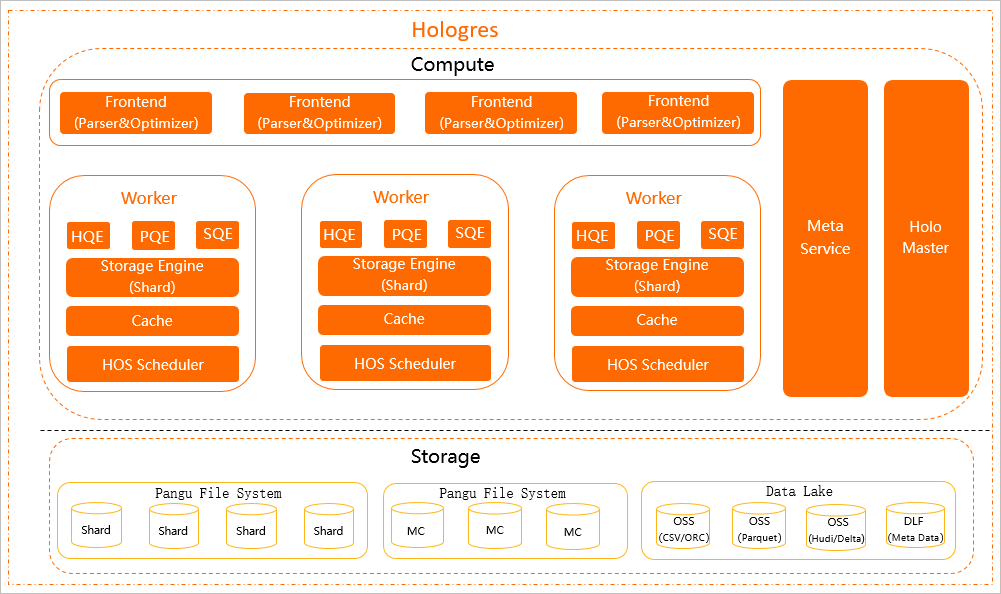
コンピューティングレイヤー
フロントエンド (FE)
FE は SQL ステートメントの認証、解析、最適化を行います。1 つの Hologres インスタンスは複数の FE を実行します。Hologres は PostgreSQL 11 と互換性があるため、標準の PostgreSQL 構文を使用でき、追加の構成なしで PostgreSQL 互換の開発ツールやビジネスインテリジェンス (BI) ツールに接続できます。
HoloWorker
HoloWorker は、ユーザークエリのスケジュールと実行を行います。各 HoloWorker には、クエリエンジン (QE)、ストレージエンジン (SE)、キャッシュ、および HOS Scheduler が含まれています。
*クエリエンジン (QE)*
HoloWorker は 3 つのクエリエンジンをサポートしており、それぞれが異なるワークロードに対応しています
| エンジン | 目的 | 主な特徴 |
|---|---|---|
| Hologres クエリエンジン (HQE) | 分析クエリ用のプライマリエジン | ベクトル化演算子を備えたスケーラブルな MPP アーキテクチャ。CPU 使用率を最大化し、高いクエリパフォーマンスを実現します。 |
| PostgreSQL クエリエンジン (PQE) | PostgreSQL 互換レイヤー | PostGIS および PL/Java、PL/SQL、PL/Python で記述された UDF をサポートします。HQE でまだサポートされていない操作を処理します。 |
| Seahawks クエリエンジン (SQE) | MaxCompute 統合 | データ移行なしで MaxCompute に接続します。ハッシュテーブル、レンジクラスター化テーブル、PB レベルのバッチデータのインタラクティブ分析をサポートします |
長期的な目標は、すべての PQE 機能を HQE に統合することです。
*ストレージエンジン (SE)*
SE はデータを管理し、すべての作成、読み取り、更新、削除 (CRUD) 操作を処理します
*キャッシュ*
キャッシュコンポーネントはクエリ結果をキャッシュして、クエリパフォーマンスを向上させます。
*HOS Scheduler*
HOS Scheduler は軽量なスケジューリング機能を提供します。
Meta Service
Meta Service は、テーブル構造や SE 全体のデータ分散などのメタデータを管理し、FE に提供します。
Holo Master
Hologres は Kubernetes 上でネイティブに実行されます。ワーカーノードに障害が発生した場合、Kubernetes は短時間で代替ノードをプロビジョニングし、ノードレベルの可用性を維持します。Holo Master は、各ワーカーノード内のコンポーネントのヘルス状態を監視し、異常な状態になったコンポーネントを再起動することで、サービスの中断を低減します
ストレージレイヤー
Hologres のデータは、Alibaba の分散ファイルシステムである Pangu に保存されます。ストレージレイヤーは、外部データソースとも統合されています。
MaxCompute:Hologres は Pangu に保存されている MaxCompute データを読み取ります。Pangu により、Hologres と MaxCompute はデータ移動なしで効率的に相互アクセスできます。
Object Storage Service (OSS) and Data Lake Formation (DLF):Hologres は OSS と DLF のデータをクエリして、データレイクでの分析を高速化します。サポートされているフォーマットには、CSV、ORC、Parquet、Hudi、Delta、Meta Data があります。Hologres は、ストレージコストを削減するために OSS にデータを書き込むこともできます。