CREATE TABLE AS (CTAS) ステートメントは、ソーステーブルからシンクテーブルにデータとスキーマの変更をリアルタイムで同期します。これにより、ソーススキーマの進化に合わせてシンクテーブルの作成とメンテナンスが簡素化されます。このトピックでは、CTAS ステートメントの使用方法を説明し、具体的な使用例を紹介します。
ソースからシンクへデータを同期するには、YAML ベースのデータインジェストジョブの使用を推奨します。既存の CTAS/CDAS SQL ジョブは、CTAS/CDAS ジョブ生成機能を使用してワンクリックで YAML ジョブに変換できます。
-
YAML 機能の利点:YAML ジョブは、データベース全体の同期、単一テーブルの同期、シャーディングされたテーブルとデータベースの同期、新規テーブルの同期、スキーマ変更、計算列の同期など、CTAS/CDAS のすべての機能を網羅しています。さらに、スキーマ変更の即時同期、raw バイナリログの同期、WHERE 句フィルタリング、カラムプルーニング、ユーザー定義関数 (UDF) などの追加機能も提供します。
-
YAML パフォーマンスの利点:SQL ジョブと比較して、YAML ジョブはデフォルトで単一のソースオペレーターを使用して複数のテーブルから読み取り、単一のシンクオペレーターを使用して複数のテーブルに書き込みます。このアプローチにより、リソースオーバーヘッドが削減されます。
その他の例については、「Flink CDC データインジェストのベストプラクティス」をご参照ください。
主な機能
データ同期
|
機能 |
説明 |
|
単一テーブルの同期 |
ソーステーブルからシンクテーブルにフルデータと増分データをリアルタイムで同期します。 (「例:単一テーブルの同期」をご参照ください。) |
|
シャード化されたテーブルとデータベースのマージと同期 |
名前を定義するために 正規表現 を使用して、複数のシャード化されたテーブルとデータベースを照合します。照合されたデータはマージされ、単一のシンクテーブルに同期されます。 (「例:シャード化されたテーブルとデータベースのマージと同期」をご参照ください。) 説明
正規表現でテーブル名の先頭に一致させるためのキャレット文字 ( |
|
計算列の同期 |
計算列を定義して、ソーステーブルのデータを変換します。計算列では、組み込み関数またはカスタム関数を使用でき、その位置も指定できます。これらの新しい列は、シンクテーブルに物理列として作成され、その結果はリアルタイムで同期されます。 (「例:計算列の同期」をご参照ください。) |
|
複数の CTAS 文 |
|
スキーマ変更の同期
CTAS 文は、リアルタイムでデータを同期する際に、ソーステーブルからシンクテーブルにスキーマ変更もレプリケートします。スキーマ変更には、最初のテーブル作成とその後のテーブル変更が含まれます。
-
サポートされるスキーマ変更
スキーマ変更
説明
NULL 可能列の追加
対応する列がシンクテーブルのスキーマの末尾に自動的に追加され、そのデータが同期されます。新しい列はデフォルトで NULL 可能になり、既存の行では、その値は NULL に設定されます。
NOT NULL 列の追加
対応する列がシンクテーブルのスキーマの末尾に自動的に追加され、そのデータが同期されます。
NULL 可能列の削除
列はシンクテーブルから削除されません。代わりに、そのデータは自動的に NULL に設定されます。
列名の変更
これは、新しい列の追加として扱われます。名前が変更された列はシンクテーブルのスキーマの末尾に追加され、元の列のデータは自動的に NULL に設定されます。
説明たとえば、
col_aの名前がcol_bに変更された場合、col_bはシンクテーブルの末尾に追加され、col_aのデータは NULL に設定されます。列のデータ型の変更
-
シンクシステムがデータ型の変更をサポートしている場合:現在、Paimon はデータ型変更の処理をサポートしています。CTAS は、INT から BIGINT への変更など、標準列の型の変更をサポートしています。
サポートされる型の変更は、シンクのルールによって異なります。詳細については、特定のシンクコネクタのドキュメントをご参照ください。
-
シンクシステムがデータ型の変更をサポートしていない場合:現在、Hologres のみが型正規化モードをサポートしており、データ型の変更を処理します。このモードでは、CTAS ジョブはより広いデータ型を持つダウンストリームテーブルを作成します。このアプローチは、データ型の変更に対するシンクの互換性を活用します。詳細については、「例:型正規化モードでのデータ同期」をご参照ください。
重要CTAS ジョブの初回起動時に型正規化モードを有効にする必要があります。そうしなかった場合、このモードを有効にするには、シンクテーブルを削除してステートレス再起動を実行する必要があります。
重要CTAS は、特定の DDL 操作を識別するのではなく、連続するレコードのスキーマを比較することによってスキーマ変更を検出します。
-
データ変更がないまま列が削除されてから再追加された場合、CTAS はスキーマ変更を検出しません。
-
CTAS は、新しい列が追加され、データ変更が発生した後にのみスキーマ変更を検出します。その後、スキーマ変更をシンクテーブルに同期します。
-
-
サポートされないスキーマ変更
-
プライマリキーやインデックスなどの制約の変更。
-
NOT NULL 列の削除。
-
列の NOT NULL から NULL 可能への変更。
重要サポートされないスキーマ変更が発生した場合は、手動でシンクテーブルを削除し、CTAS ジョブを再起動する必要があります。これにより、シンクテーブルが再作成され、履歴データが再同期されます。
-
起動プロセス
次の例では、CTAS を使用して MySQL から Hologres にデータを同期するプロセスを説明します。
|
フローチャート |
起動プロセス |
 |
CTAS 文を実行すると、次のプロセスが開始されます:
|
前提条件
CTAS ステートメントを実行する前に、ワークスペースに宛先カタログが登録されていることを確認してください。詳細については、「データ管理」をご参照ください。
制限事項
構文の制限
-
デバッグ機能はサポートされていません。
-
同じジョブで
INSERT INTOステートメントを使用することはできません。 -
StarRocks パーティションテーブルへの同期はサポートされていません。
-
MiniBatch 設定はサポートされていません。
重要-
SQL ジョブを作成する前に:[Configuration Management] ページで、[Job Default Configurations] タブの [Other Configurations] セクションから MiniBatch 設定が削除されていることを確認してください。
-
SQL ジョブを作成した後:解決策については、「Error: Currently does not support merge StreamExecMiniBatchAssigner type ExecNode in CTAS/CDAS syntax」をご参照ください。
-
ソースとシンクの互換性
次の表に、CTAS でサポートされているソースおよびシンクコネクタを示します。
|
コネクタ |
ソーステーブル |
シンクテーブル |
注意事項 |
|
√ |
× |
|
|
|
√ |
× |
なし。 |
|
|
√ |
× |
|
|
|
× |
√ |
なし。 |
|
|
× |
√ |
EMR 上の StarRocks のみがサポートされています。 |
|
|
× |
√ |
シンクが Hologres の場合、CTAS は 説明
Hologres にデータを同期する際、ソーステーブルに Fixed Plan でサポートされていないデータ型が含まれている場合は、データを同期する前に Flink 内で型変換を実行するために INSERT INTO ステートメントを使用することを推奨します。CTAS を使用すると Fixed Plan を使用できず、書き込みパフォーマンスが低下するため、シンクテーブルの作成には使用しないでください。 |
|
|
× |
√ |
Paimon DLF 2.5 シンクテーブルへのデータ同期は、Realtime Compute for Apache Flink エンジンの VVR 11.1 以降でのみサポートされています。 |
構文
CREATE TABLE IF NOT EXISTS <sink_table>
(
[ <table_constraint> ]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (
key1=val1,
key2=val2,
...
)
AS TABLE <source_table> [/*+ OPTIONS(key1=val1, key2=val2, ... ) */]
[ADD COLUMN { <column_component> | (<column_component> [, ...])}];
<sink_table>:
[catalog_name.][db_name.]table_name
<table_constraint>:
[CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED
<source_table>:
[catalog_name.][db_name.]table_name
<column_component>:
column_name AS computed_column_expression [COMMENT column_comment] [FIRST | AFTER column_name]CTAS 構文は、CREATE TABLE ステートメントに基づいています。次の表では、そのパラメーターについて説明します。
|
パラメーター |
説明 |
|
|
データ同期に使用するシンクテーブルの名前です。カタログ名とデータベース名を指定できます。 |
|
|
シンクテーブルの説明です。デフォルトでは、 |
|
|
1 つ以上の列に基づいてパーティションテーブルを作成します。 重要
StarRocks のパーティションテーブルへの同期はサポートしていません。 |
|
|
テーブルのプライマリキー制約を定義します。この制約はデータの一意性を示しますが、強制はされません。 |
|
|
シンクテーブルのオプション。シンクテーブルでサポートされている任意の 説明
キーと値はどちらも文字列である必要があります。たとえば、 |
|
|
データ同期に使用するソーステーブルの名前です。カタログ名とデータベース名を指定できます。 |
|
|
ソーステーブルのオプション。ソーステーブルでサポートされている 説明
キーと値はいずれも文字列型である必要があります。例: 'server-id' = '65500'。 |
|
|
シンクテーブルで、ソーステーブルから新規追加または名前変更する列を定義します。列エイリアスと計算列をサポートします。 重要
|
|
|
新しい列の定義です。 |
|
|
列を計算するための式です。 |
|
|
新しい列を、テーブルの論理スキーマの先頭フィールドとして配置します。このパラメーターを指定しない場合、新しい列はデフォルトで論理スキーマの末尾に追加されます。 |
|
|
新しい列を、指定した既存列の後ろに配置します。 |
-
この
IF NOT EXISTSキーワードは必須です。宛先ストレージにシンクテーブルが存在しない場合、まず作成されます。それ以外の場合、作成ステップはスキップされます。 -
シンクテーブルのスキーマは、プライマリキーおよび物理列の名前と型を含め、ソーステーブルのスキーマを継承します。計算列、メタデータ列、またはウォーターマークは含まれません。
-
列の データ型 は、ソーステーブルからシンクテーブルへの 型マッピング によって変換されます。詳細については、該当するコネクタのドキュメントの型マッピングのセクションをご参照ください。
コード例
単一テーブルの同期
シナリオ:MySQL から Hologres へ web_sales テーブルを同期します。
前提条件:ワークスペースに次のカタログが登録済みであること。
-
holo という名前の Hologres カタログ
-
mysql という名前の MySQL カタログ
コード例:
CTAS は通常、ソースと送信先の両方でカタログと共に使用されます。ソースカタログはソーステーブルのスキーマとオプションを自動的に解析するため、手動での DDL が不要になり、ソーステーブルからシンクテーブルへの完全データと増分データの同期が可能になります。
USE CATALOG holo;
CREATE TABLE IF NOT EXISTS web_sales -- データベースが指定されていない場合、テーブルはデフォルトデータベースの web_sales テーブルに同期されます。
WITH ('jdbcWriteBatchSize' = '1024') -- オプション: シンクテーブルのパラメーターを指定します。
AS TABLE mysql.tpcds.web_sales
/*+ OPTIONS('server-id'='8001-8004') */; -- mysql-cdc ソーステーブルの追加パラメーターを指定します。シャードテーブルとデータベースのマージ
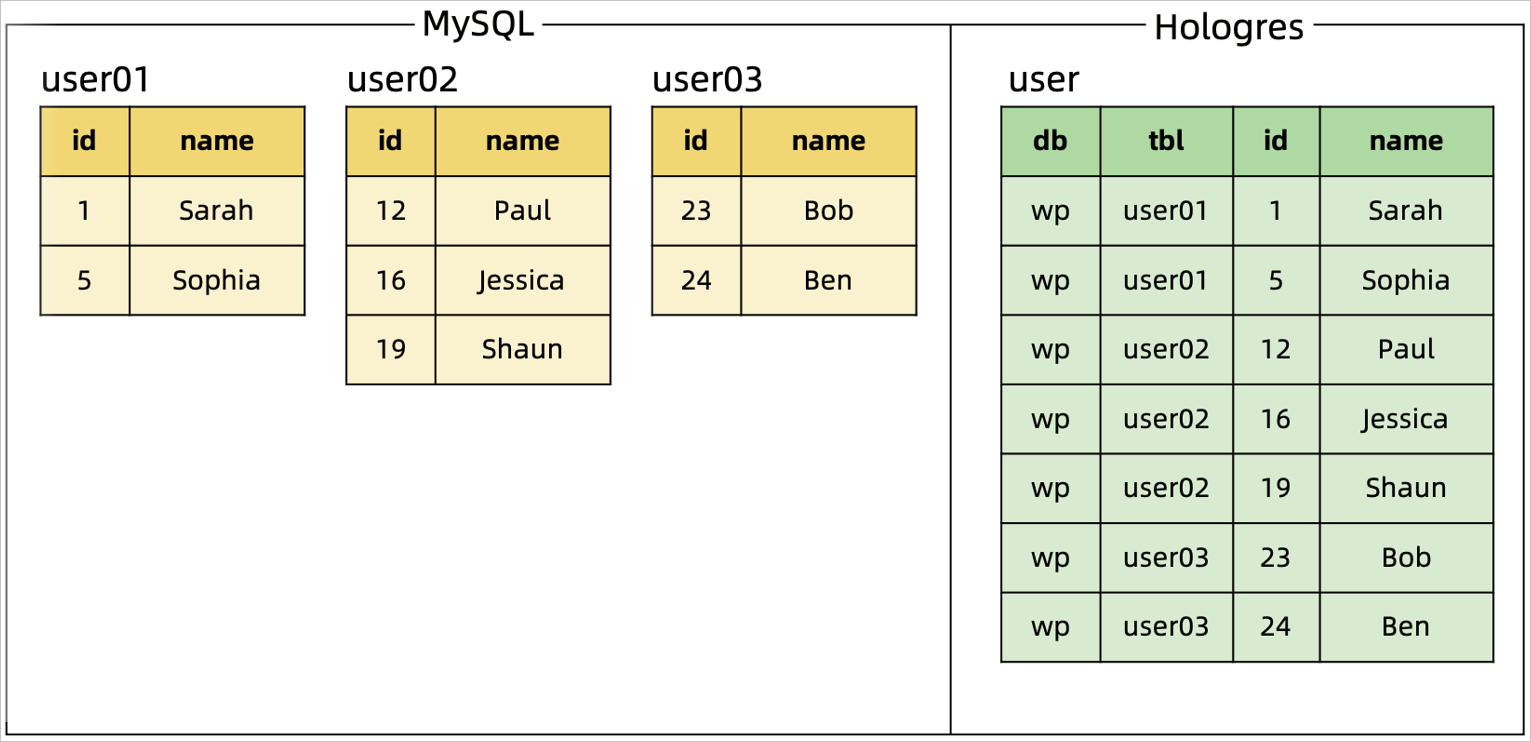
シナリオ:CTAS を使用して、複数のシャード化された MySQL テーブルを単一の Hologres テーブルにマージします。
ソリューション:MySQL カタログと組み合わせて、正規表現を使用して同期するテーブルのデータベース名とテーブル名を照合します。データベース名とテーブル名は、シンクテーブルに追加の 2 列として書き込まれます。プライマリキーの一意性を保証するために、データベース名、テーブル名、および元のプライマリキーを組み合わせて、Hologres テーブルの新しい複合プライマリキーを構成します。
コード例とマージ結果:
|
コード例 |
マージ結果 |
|
シャードテーブルのマージと同期のシナリオ: |
|
|
ソーステーブルのスキーマ変更シナリオ:user02 テーブルに age 列が追加され、レコードが挿入されます。シャードテーブルのスキーマは一貫していませんが、user02 テーブルのその後のデータとスキーマの変更は、リアルタイムでダウンストリームテーブルに自動的に同期されます。 |
|

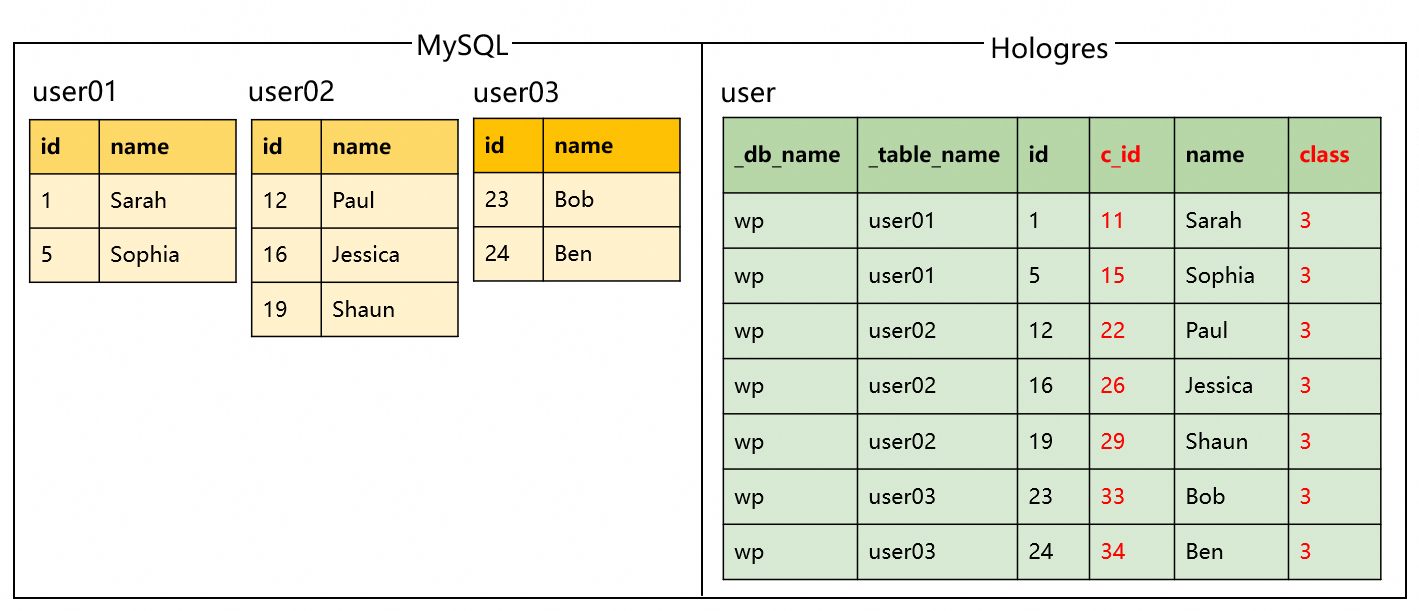
計算列の同期
シナリオ:シャード化された MySQL テーブルをマージ・同期する際に、Hologres テーブルにカスタム計算列を追加します。
コード例とマージ結果:
|
コード例 |
マージ結果 |
|
|
複数の CTAS ステートメントを単一ジョブとして実行
シナリオ:MySQL の web_sales テーブルとシャード化された user テーブルを、単一ジョブとして Hologres に同期します。
ソリューション:STATEMENT SET 構文を使用して、複数の CTAS ステートメントを単一ジョブとしてコミットします。このアプローチにより、単一のソースノードを複数の業務テーブルからのデータ読み取りに再利用でき、MySQL CDC ソースのサーバー ID 数、データベース接続数、および読み取り負荷を削減できます。
-
ソーステーブルの
OPTIONSが同一である場合にのみ、ソースを再利用できます。 -
MySQL コネクタでのサーバー ID の設定については、「binlog 消費の競合を回避するためのサーバー ID の設定」をご参照ください。
コード例:
USE CATALOG holo;
BEGIN STATEMENT SET;
-- web_sales テーブルを同期します。
CREATE TABLE IF NOT EXISTS web_sales
AS TABLE mysql.tpcds.web_sales
/*+ OPTIONS('server-id'='8001-8004') */;
-- シャード化された user テーブルを同期します。
CREATE TABLE IF NOT EXISTS user
AS TABLE mysql.`wp.*`.`user[0-9]+`
/*+ OPTIONS('server-id'='8001-8004') */;
END;1 つのソースから複数のシンクテーブルへの同期
-
シンクテーブルに計算列が不要な場合
USE CATALOG `holo`; BEGIN STATEMENT SET; -- CTAS ステートメントを使用して、MySQL の user テーブルを Hologres データウェアハウスの database1 内の user テーブルに同期します。 CREATE TABLE IF NOT EXISTS `database1`.`user` AS TABLE `mysql`.`tpcds`.`user` /*+ OPTIONS('server-id'='8001-8004') */; -- CTAS ステートメントを使用して、MySQL の user テーブルを Hologres データウェアハウスの database2 内の user テーブルに同期します。 CREATE TABLE IF NOT EXISTS `database2`.`user` AS TABLE `mysql`.`tpcds`.`user` /*+ OPTIONS('server-id'='8001-8004') */; END; -
シンクテーブルに計算列が必要な場合
-- ソーステーブル user に基づいて一時テーブル user_with_changed_id を作成します。ソーステーブルの id に基づいて計算される computed_id などの計算列を定義できます。 CREATE TEMPORARY TABLE `user_with_changed_id` ( `computed_id` AS `id` + 1000 ) LIKE `mysql`.`tpcds`.`user`; -- ソーステーブル user に基づいて一時テーブル user_with_changed_age を作成します。ソーステーブルの age に基づいて計算される computed_age などの計算列を定義できます。 CREATE TEMPORARY TABLE `user_with_changed_age` ( `computed_age` AS `age` + 1 ) LIKE `mysql`.`tpcds`.`user`; BEGIN STATEMENT SET; -- CTAS ステートメントを使用して、MySQL の user テーブルを Hologres データウェアハウスの user_with_changed_id テーブルに同期します。テーブルには computed_id 列に計算された ID が含まれます。 CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`user_with_changed_id` AS TABLE `user_with_changed_id` /*+ OPTIONS('server-id'='8001-8004') */; -- CTAS ステートメントを使用して、MySQL の user テーブルを Hologres データウェアハウスの user_with_changed_age テーブルに同期します。テーブルには computed_age 列に計算された年齢が含まれます。 CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`user_with_changed_age` AS TABLE `user_with_changed_age` /*+ OPTIONS('server-id'='8001-8004') */; END;
新しいテーブルの同期
シナリオ:複数の CTAS ステートメントを含むジョブが開始された後、新しく追加されたテーブルからデータを同期するために新しい CTAS ステートメントを追加する必要があります。
ソリューション:SQL ジョブで新しいテーブルの検出機能を有効にし、新しい CTAS ステートメントを追加してから、セーブポイントからジョブを再起動します。新しいテーブルがキャプチャされると、そのデータが同期されます。
制限事項:
-
新しいテーブルの検出機能は、Realtime Compute for Apache Flink (VVR) 8.0.1 以降でサポートされています。
-
CDC ソーステーブルから同期する場合、新規テーブル検出機能は、ソーステーブルの起動モードが 初期 に設定されているジョブでのみサポートされます。
-
ソースを再利用するためには、追加された CTAS ステートメント内の新しいソーステーブルの設定が、既存のソーステーブルの設定と同一である必要があります。
-
新しい CTAS ステートメントを追加する前後で、起動モードなどのジョブ設定パラメーターは変更できません。
手順:
-
新しい CTAS ステートメントを追加する必要がある場合は、[運用保守] ページに移動し、ジョブを停止して [Stop With Savepoint] を選択します。
-
SQL ジョブで、新しいテーブルの検出を有効にし、新しい CTAS ステートメントを追加してから、ジョブを再度 [Deploy] します。
-
次のステートメントを SQL ジョブに追加して、新しいテーブルの検出を有効にします。
SET 'table.ctas.scan.newly-added-table.enabled' = 'true'; -
新しい CTAS ステートメントを SQL ジョブに追加します。最終的なコード全体は次のとおりです。
-- 新しいテーブルの検出を有効にします。 SET 'table.ctas.scan.newly-added-table.enabled' = 'true'; USE CATALOG holo; BEGIN STATEMENT SET; -- web_sales テーブルを同期します。 CREATE TABLE IF NOT EXISTS web_sales AS TABLE mysql.tpcds.web_sales /*+ OPTIONS('server-id'='8001-8004') */; -- シャード化された user テーブルを同期します。 CREATE TABLE IF NOT EXISTS user AS TABLE mysql.`wp.*`.`user[0-9]+` /*+ OPTIONS('server-id'='8001-8004') */; -- product テーブルを同期します。(新しいテーブル) CREATE TABLE IF NOT EXISTS product AS TABLE mysql.tpcds.product /*+ OPTIONS('server-id'='8001-8004') */; END; -
[Deploy] をクリックします。
-
-
セーブポイントからジョブを復元します。
-
[運用保守] ページで、対象のジョブの名前をクリックし、[State Management] タブに移動して [History] をクリックします。
-
[Savepoints] リストで、ジョブが停止したときに作成されたセーブポイントを見つけます。
-
対象のセーブポイントの [Actions] 列で、 を選択してジョブを開始します。詳細については、「ジョブの開始」をご参照ください。
-
Hologres パーティションテーブルへの同期
シナリオ:CTAS ステートメントを使用して、MySQL ソーステーブルを Hologres パーティションテーブルに同期します。
Hologres のパーティションルール:Hologres では、シンクテーブルにプライマリキーが定義されている場合、パーティション列はプライマリキーに含まれている必要があります。
コード例:
MySQL ソーステーブルの DDL ステートメントは次のとおりです。
CREATE TABLE orders (
order_id INTEGER NOT NULL,
product_id INTEGER NOT NULL,
city VARCHAR(100) NOT NULL,
order_date DATE,
purchaser INTEGER,
PRIMARY KEY(order_id, product_id)
);方法は、ソーステーブルのプライマリキーにパーティションキーが含まれているかどうかによって異なります。
-
ソースのプライマリキーにパーティション列が含まれている場合、CTAS ステートメントで直接同期できます。
Hologres は、パーティション列がプライマリキーの一部であることを自動的に検証します。
CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`orders` PARTITIONED BY (product_id) AS TABLE `mysql`.`tpcds`.`orders`; -
ソースのプライマリキーにパーティション列が含まれていない場合は、CTAS ステートメントでシンクテーブルのプライマリキーを再宣言します。
パーティション列 (例:
city) がソーステーブルのプライマリキーの一部ではない場合、ジョブは失敗します。パーティション列がプライマリキーの一部となるように、CTAS 文でシンクテーブルのプライマリキーを再宣言する必要があります。-- 次の SQL を使用して、Hologres パーティションテーブルのプライマリキーを order_id、product_id、および city として指定できます。 CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`orders`( CONSTRAINT `PK_order_id_city` PRIMARY KEY (`order_id`,`product_id`,`city`) NOT ENFORCED ) PARTITIONED BY (city) AS TABLE `mysql`.`tpcds`.`orders`;
型の正規化モードでのデータ同期
シナリオ: CTAS ステートメントを使用して Hologres テーブルにデータを同期する際に、既存のデータ型の精度の調整 (たとえば、VARCHAR(10) から VARCHAR(20) へ) や、データ型の変更 (たとえば、SMALLINT から INT へ) が必要なシナリオをサポートします。
ソリューション:Hologres の型の正規化モードを使用してデータを同期します。このモードは、CTAS ジョブの初回起動時に有効にする必要があります。起動時に有効にしなかった場合、有効にするには、ダウンストリームテーブルを削除した上で、ジョブをステートレスで再起動する必要があります。
型の正規化ルール:
アップストリームのデータ型が変更された後、新しい型と元の型が同じターゲット型に正規化される場合、ジョブは正常に実行されます。そうでない場合、変更は互換性がないと見なされ、CTAS ジョブは例外をスローします。具体的なルールは次のとおりです。
-
TINYINT、SMALLINT、INT、およびBIGINTはBIGINTに正規化されます。 -
CHAR、VARCHAR、およびSTRINGはSTRINGに正規化されます。 -
FLOATとDOUBLEはDOUBLEに正規化されます。 -
その他のデータ型は、元の型マッピングルールに従って作成されます。詳細については、「型マッピング」をご参照ください。
コード例:
CREATE TABLE IF NOT EXISTS `holo`.`tpcds`.`orders`
WITH (
'connector' = 'hologres',
'enableTypeNormalization' = 'true' -- 型の正規化モードを有効にします。
) AS TABLE `mysql`.`tpcds`.`orders`;MongoDB から Hologres への同期
制限事項:
-
VVR 8.0.6 以降と MongoDB 6.0 以降が必要です。
-
SQL ヒントで、scan.incremental.snapshot.enabled と scan.full-changelog を true に設定します。
-
MongoDB データベースで pre-image と post-image 機能を有効にする必要があります。有効にする方法については、「Document Preimages」をご参照ください。
-
単一ジョブで複数の MongoDB コレクションを同期するには、次の要件があります。
-
MongoDB の設定は、
hosts、scheme、username、password、およびconnectionOptionsを含め、各テーブルで同一にする必要があります。 -
scan.startup.mode設定は、各テーブルで同一である必要があります。
-
コード例:
BEGIN STATEMENT SET;
CREATE TABLE IF NOT EXISTS `holo`.`database`.`table1`
AS TABLE `mongodb`.`database`.`collection1`
/*+ OPTIONS('scan.incremental.snapshot.enabled'='true','scan.full-changelog'='true') */;
CREATE TABLE IF NOT EXISTS `holo`.`database`.`table2`
AS TABLE `mongodb`.`database`.`collection2`
/*+ OPTIONS('scan.incremental.snapshot.enabled'='true','scan.full-changelog'='true') */;
END;よくある質問
ジョブの操作
-
タイムアウトの問題: エラー: akka.pattern.AskTimeoutException
ジョブのパフォーマンス
データ同期
関連ドキュメント
-
CTAS はカタログを使用して永続的なテーブルメタデータを管理し、スキーマが永続化できない、ジョブをまたいでテーブルにアクセスできないといった制限を克服します。一般的なカタログの使用方法については、以下をご参照ください。
-
CTAS および CDAS のユースケースと実践的なシナリオ:
-
データベース全体の同期、データベースのマージ、またはソースデータベースで新たに追加されたテーブルの同期:「CREATE DATABASE AS (CDAS) ステートメント」をご参照ください。
-
MySQL データベース全体を Kafka に同期して、複数のジョブによるデータベースの負荷を軽減するには:「Flink CDC を使用した MySQL データベースの Kafka への同期」をご参照ください。
-
CTAS および CDAS を使用したデータ同期を実装するためのチュートリアル:「リアルタイムデータベースのデータインジェスト」、「Hologres リアルタイムデータウェアハウスの構築」、または「Paimon および StarRocks ストリーミングレイクハウス」をご参照ください。
-
-
YAML ジョブによるデータ同期の実装:
-
クイックスタート:「Flink CDC データインジェストジョブ」をご参照ください。
-
CTAS ジョブの YAML ジョブへの変換:「Flink CDC データインジェストジョブの作成」をご参照ください。
-