MySQL コネクタの使用方法について説明します。
背景
MySQL コネクタは、ApsaraDB RDS for MySQL、PolarDB for MySQL、OceanBase (MySQL モード)、セルフマネージド MySQL データベースなど、MySQL プロトコルと互換性のあるすべてのデータベースをサポートしています。
MySQL コネクタを使用して OceanBase からデータを読み取るには、OceanBase のバイナリログを有効化し、正しく設定する必要があります。詳細については、「Binlog-related operations」をご参照ください。この機能はパブリックプレビューです。本番環境で使用する前に、パフォーマンスと安定性を十分に評価してください。
次の表に、MySQL コネクタの機能を示します。
|
カテゴリ |
説明 |
|
サポートされているタイプ |
ソーステーブル、ディメンションテーブル、シンクテーブル、データインジェストソース |
|
実行モード |
ストリーミングのみ |
|
データフォーマット |
該当なし |
|
固有のメトリクス |
|
|
API タイプ |
DataStream、SQL、データインジェスト YAML |
|
シンクテーブルデータの更新/削除 |
サポートされています |
機能
MySQL CDC ソースは、まずデータベース全体のスナップショットを読み取り、その後、バイナリログをシームレスに読み取って増分更新を取り込みます。このプロセスは Exactly-Once セマンティクスを保証し、障害発生時でもデータ損失や重複を防ぎます。MySQL CDC ソースは、スナップショットの同時読み取りをサポートし、増分スナップショットアルゴリズムを使用して、ロックフリー読み取りとチェックポイントベースのリカバリを実現します。詳細については、「Understanding MySQL source」をご参照ください。
-
バッチとストリーミングの統合:スナップショットデータと増分データを 1 つのパイプラインで読み取るため、個別のワークフローは不要です。
-
水平方向にスケーラブルなパフォーマンス:スナップショットの同時読み取りにより、水平スケーリングが可能になります。
-
自動リソースの最適化:スナップショット読み取りから増分読み取りに切り替える際に、自動的にスケールダウンしてコンピューティングリソースを節約します。
-
安定性の向上:スナップショットフェーズ中のチェックポイントベースのリカバリにより、プロセスの中断後も再開できます。
-
ロックフリースナップショット:ロックを取得せずにスナップショットデータを読み取るため、オンライン業務アプリケーションに影響を与えません。
-
クラウド統合:ApsaraDB RDS for MySQL インスタンスのバイナリログからの読み取りをサポートします。
-
低レイテンシー読み取り:バイナリログの並列解析により、読み取りレイテンシーを最小限に抑えます。
前提条件
MySQL CDC ソーステーブルを使用する前に、「Configure a MySQL database」の手順を完了してください。
ApsaraDB RDS for MySQL
-
ネットワークプローブを実行して、Realtime Compute for Apache Flink とのネットワーク接続性を確認してください。
-
MySQL バージョン:5.6、5.7、または 8.0.x。
-
バイナリログを有効にしてください (デフォルトで有効)。
-
バイナリログフォーマットを
ROWに設定してください (デフォルト)。 -
binlog_row_imageをFULLに設定してください (デフォルト)。 -
バイナリログトランザクション圧縮を無効にしてください (MySQL 8.0.20 以降で導入され、デフォルトで無効)。
-
MySQL ユーザーを作成し、
SELECT、SHOW DATABASES、REPLICATION SLAVE、REPLICATION CLIENTの権限を付与してください。 -
MySQL データベースとテーブルを作成してください。詳細については、「Create a database and account for ApsaraDB RDS for MySQL」をご参照ください。 (権限エラーを回避するため、高権限アカウントを使用して MySQL データベースを作成してください。)
-
IP ホワイトリストを構成してください。詳細については、「Use a database client or the CLI to connect to an ApsaraDB RDS for MySQL instance」をご参照ください。
PolarDB for MySQL
-
ネットワークプローブを実行して、Realtime Compute for Apache Flink とのネットワーク接続性を確認してください。
-
MySQL バージョン:5.6、5.7、または 8.0.x。
-
バイナリログを有効にしてください (デフォルトで無効)。
-
バイナリログフォーマットを
ROWに設定してください (デフォルト)。 -
binlog_row_imageをFULLに設定してください (デフォルト)。 -
バイナリログトランザクション圧縮を無効にしてください (MySQL 8.0.20 以降で導入され、デフォルトで無効)。
-
MySQL ユーザーを作成し、
SELECT、SHOW DATABASES、REPLICATION SLAVE、REPLICATION CLIENTの権限を付与してください。 -
MySQL データベースとテーブルを作成してください。詳細については、「Create a database and account for PolarDB for MySQL」をご参照ください。 (権限エラーを回避するため、高権限アカウントを使用して MySQL データベースを作成してください。)
-
IP ホワイトリストを構成してください。詳細については、「Configure an IP address whitelist for PolarDB for MySQL」をご参照ください。
セルフマネージド MySQL
-
ネットワークプローブを実行して、Realtime Compute for Apache Flink とのネットワーク接続性を確認してください。
-
MySQL バージョン:5.6、5.7、または 8.0.x。
-
バイナリログを有効にしてください (デフォルトで無効)。
-
バイナリログフォーマットを
ROWに設定してください (デフォルトはSTATEMENT)。 -
binlog_row_imageをFULLに設定してください (デフォルト)。 -
バイナリログトランザクション圧縮を無効にしてください (MySQL 8.0.20 以降で導入され、デフォルトで無効)。
-
MySQL ユーザーを作成し、
SELECT、SHOW DATABASES、REPLICATION SLAVE、REPLICATION CLIENTの権限を付与してください。 -
MySQL データベースとテーブルを作成してください。詳細については、「Create a database and account for a self-managed MySQL database」をご参照ください。 (権限エラーを回避するため、高権限アカウントを使用して MySQL データベースを作成してください。)
-
IP ホワイトリストを構成してください。詳細については、「Add a security group rule」をご参照ください。
制限
一般
-
MySQL CDC ソーステーブルは、ウォーターマークの定義をサポートしていません。
-
CTAS および CDAS ジョブでは、MySQL CDC ソーステーブルは部分的なスキーマ進化のみをサポートします。サポートされる変更タイプの詳細については、「Schema evolution synchronization policy」をご参照ください。
-
MySQL CDC コネクターは、現在バイナリログトランザクション圧縮をサポートしていません。MySQL CDC コネクターを使用して増分データを処理する場合は、この機能を無効にする必要があります。無効にしないと、増分データを取得できない可能性があります。
ApsaraDB RDS for MySQL
-
ApsaraDB RDS for MySQL では、スタンバイインスタンスまたは読み取り専用インスタンスからのデータ読み取りは避けてください。これらのインスタンスは通常、バイナリログの保持期間が短いため、ログが処理される前に期限切れになると、ジョブが失敗する可能性があります。
-
ApsaraDB RDS for MySQL では、デフォルトでパラレルレプリケーションが有効になっており、プライマリインスタンスとセカンダリインスタンス間でトランザクション順序の一貫性が保証されません。これにより、プライマリ/セカンダリ切り替え後にジョブがチェックポイントから復旧する際、データ損失が発生する可能性があります。この問題を回避するには、slave_preserve_commit_order オプションを有効にしてください。
PolarDB for MySQL
MySQL CDC ソーステーブルは、PolarDB for MySQL バージョン 1.0.19 以前のマルチマスタークラスター (What is a multi-master cluster?) からのデータ読み取りをサポートしていません。これらのクラスターバージョンのバイナリログには、重複したテーブル ID が含まれる可能性があり、スキーママッピングエラーを引き起こし、データ解析の失敗につながる場合があります。
オープンソース MySQL
デフォルトでは、MySQL はバイナリログレプリケーション中にトランザクション順序を保持します。ただし、MySQL レプリカでパラレルレプリケーションが有効 (slave_parallel_workers > 1) になっているにもかかわらず、slave_preserve_commit_order が ON に設定されていない場合、レプリカのトランザクションコミット順序がプライマリインスタンスと異なる可能性があります。この不一致により、Flink CDC ジョブがチェックポイントから再開する際にデータ損失が発生する可能性があります。MySQL レプリカで slave_preserve_commit_order = ON を設定してください。または、slave_parallel_workers = 1 に設定することもできますが、レプリケーションのパフォーマンスが低下する可能性があります。
注意事項
-
ソーステーブル
-
-
全量ロードフェーズ中に、セーブポイントを作成した後にソーステーブルを追加または削除しないでください。そのセーブポイントからジョブを再起動すると、データ読み取りエラーが発生します。
-
-
シンクテーブル
-
DDL で自動インクリメントプライマリキーを宣言しないでください。MySQL はデータ書き込み時にこのフィールドに自動的に値を設定します。
-
少なくとも 1 つのプライマリキー以外のフィールドを宣言する必要があります。そうしないと、エラーが発生します。
-
DDL の
NOT ENFORCED制約は、Flink がプライマリキーの検証を実行しないことを示します。プライマリキーの正確性と完全性を保証する必要があります。詳細については、「有効性チェック」をご参照ください。
-
-
ディメンションテーブル
インデックスを使用してクエリを高速化するには、
JOIN条件内のフィールドの順序がインデックス定義内の列の順序と一致するようにします。 これは最左一致の原則に従います。 たとえば、インデックスが(a, b, c)で定義されている場合、JOIN条件はON t.a = x AND t.b = yにする必要があります。Flink オプティマイザは生成された SQL を書き換える可能性があり、その結果、クエリで意図したインデックスが使用できなくなることがあります。インデックスが使用されていることを確認するには、MySQL の実行計画 (
EXPLAIN) またはスロークエリログをチェックして、実際のSELECT文を検査してください。
SQL
SQL ジョブでは、MySQL コネクタをソース、ディメンション、またはシンクテーブルとして使用します。
構文
CREATE TEMPORARY TABLE mysql_sink (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '<yourHostname>',
'port' = '3306',
'username' = '<yourUsername>',
'password' = '<yourPassword>',
'database-name' = '<yourDatabaseName>',
'table-name' = '<yourTableName>'
);-
コネクタは、受信した各レコードを SQL ステートメントに変換し、ターゲットテーブルに書き込みます。実行される具体的な SQL ステートメントは、テーブルスキーマによって異なります:
-
プライマリキーがないターゲットテーブルの場合、コネクタは
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);ステートメントを実行します。 -
プライマリキーがあるターゲットテーブルの場合、コネクタは
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...) ON DUPLICATE KEY UPDATE column1 = VALUES(column1), column2 = VALUES(column2), ...;ステートメントを実行してアップサートを行います。注意:物理テーブルにプライマリキー以外の一意のインデックスがある場合、プライマリキーが異なっていても一意のインデックスの値が同一のレコードを挿入すると競合が発生し、データが上書きされる可能性があります。
-
-
MySQL データベースで自動インクリメントプライマリキーが定義されている場合、Flink DDL で自動インクリメント列を宣言しないでください。データベースは書き込み操作中にこの列を自動的に設定します。コネクタは、自動インクリメント列を持つテーブルの INSERT 操作と DELETE 操作をサポートしますが、UPDATE 操作はサポートしていません。
WITH パラメーター
-
一般
パラメーター
説明
必須
タイプ
デフォルト
備考
connector
使用するコネクタを指定します。
はい
STRING
-
ソーステーブルの場合、値は
mysql-cdcまたはmysqlを指定できます。これら2つの値は同等です。ディメンションテーブルまたはシンクテーブルの場合、値はmysqlである必要があります。hostname
MySQL データベースの IP アドレスまたはホスト名。
はい
STRING
-
VPC アドレスを推奨します。
説明MySQL データベースと Realtime Compute for Apache Flink ワークスペースが異なる VPC にある場合、VPC 間のネットワーク接続を確立するか、パブリックネットワーク経由で接続する必要があります。詳細については、「Space Management and Operations」および「How can a fully managed Flink cluster access the public network?」をご参照ください。
username
MySQL データベースのユーザー名。
はい
STRING
-
-
password
MySQL データベースのパスワード。
はい
STRING
-
-
database-name
データベース名。
はい
STRING
-
-
ソースとして使用する場合、正規表現を指定して複数のデータベースからデータを読み取ることができます。
-
正規表現を使用する場合、先頭と末尾の一致には ^ および $ 記号を使用しないでください。詳細については、table-name の備考をご参照ください。
table-name
テーブル名。
はい
STRING
-
-
ソースとして使用する場合、正規表現を指定して複数のテーブルからデータを読み取ることができます。
複数の MySQL テーブルから読み取る際のパフォーマンスと効率を向上させるには、複数の CTAS ステートメントを単一のジョブとして送信してください。これにより、複数のバイナリログリスナーの有効化を防ぐことができます。詳細については、「Run multiple CTAS statements in a single job」をご参照ください。
-
正規表現を使用する場合、先頭と末尾の一致には ^ および $ 記号を使用しないでください。具体的な理由については、以下の説明をご参照ください。
説明MySQL CDC ソーステーブルが正規表現を使用してテーブル名を照合する場合、入力された database-name と table-name を文字列 \\. (VVR バージョン 8.0.1 より前の場合は文字 . を使用します) と連結してフルパス正規表現を作成し、この式を使用して MySQL データベース内のテーブルの完全修飾名と照合します。
たとえば、'database-name'='db_.*' および 'table-name'='tb_.+' を構成すると、コネクタは正規表現 db_.*\\.tb_.+ (8.0.1 より前のバージョンでは db_.*.tb_.+) を使用して完全修飾テーブル名と照合し、読み取るテーブルを決定します。
port
MySQL データベースのポート。
いいえ
INTEGER
3306
-
-
-
ソース固有
パラメーター
説明
必須
タイプ
デフォルト
備考
server-id
データベースクライアントの数値 ID です。
いいえ
STRING
5400~6400 の範囲でランダムに生成される整数。
サーバー ID は、MySQL クラスター内でグローバルに一意である必要があります。同じデータベースに接続するジョブごとに異なる ID を設定してください。
このパラメーターは、
5400-6400のような ID 範囲もサポートしています。同時リーダーを使用してインクリメンタルスナップショットを有効にする場合は、各リーダーが一意のサーバー ID を持つように ID 範囲を指定してください。範囲内の ID 数は、ソースの並列度以上である必要があります。詳細については、「Server ID Usage」をご参照ください。scan.incremental.snapshot.enabled
インクリメンタルスナップショットを有効にするかどうかを指定します。
いいえ
BOOLEAN
true
デフォルトでは、インクリメンタルスナップショットが有効になっています。インクリメンタルスナップショットは、テーブル全体のスナップショットを読み取る仕組みです。従来のスナップショット方式と比較して、次の利点があります:
-
ソースはスナップショットを並列に読み取れます。
-
ソースは、スナップショットフェーズ中にチャンクレベルのチェックポイントをサポートします。
-
ソースでは、グローバル読み取りロック (
FLUSH TABLES WITH READ LOCK) は不要です。
並列読み取りを有効にするには、同時リーダーごとに一意のサーバー ID が必要です。そのため、
server-idは5400-6400のような範囲に設定し、範囲のサイズはソースの並列度以上である必要があります。説明このパラメーターは Flink エンジン VVR 11.1 以降で削除されました。
scan.incremental.snapshot.chunk.size
各チャンクの行数です。
いいえ
INTEGER
8096
インクリメンタルスナップショットが有効な場合、テーブルは複数のチャンクに分割されて読み取られます。チャンク内のデータは、チャンク全体の読み取りが完了するまでメモリにバッファリングされます。
チャンクサイズを小さくするとチャンク数が増えるため、障害回復をより細かく行えます。一方で、メモリ不足 (OOM) やスループット全体の低下につながる可能性があります。これらのトレードオフのバランスを考慮して、チャンクサイズを選択してください。
scan.snapshot.fetch.size
スナップショット読み取り中に、バッチごとにフェッチする最大行数です。
いいえ
INTEGER
1024
-
scan.startup.mode
コネクターの起動モードです。
いいえ
STRING
initial
有効な値:
-
initial (デフォルト):初回起動時に、コネクターが既存データのスナップショットを取得し、その後、最新のバイナリログデータの読み取りを継続します。
-
latest-offset:初回起動時に、コネクターはスナップショットをスキップし、バイナリログの末尾から読み取りを開始します。コネクターの起動後に発生した変更のみを読み取ります。
-
earliest-offset:コネクターはスナップショットをスキップし、利用可能な最も古いバイナリログのオフセットから読み取りを開始します。
-
specific-offset:コネクターはスナップショットをスキップし、ユーザー指定のバイナリログのオフセットから開始します。scan.startup.specific-offset.file と scan.startup.specific-offset.pos の両方を設定してオフセットを指定するか、scan.startup.specific-offset.gtid-set のみを設定して特定の GTID セットから開始できます。
-
timestamp:コネクターはスナップショットをスキップし、指定したタイムスタンプからバイナリログの読み取りを開始します。タイムスタンプは、scan.startup.timestamp-millis パラメーターでミリ秒単位で指定します。
重要earliest-offset、specific-offset、または timestamp の起動モードを使用する場合は、指定した開始オフセットからジョブの開始時刻までの間に、テーブルスキーマが変更されないことを確認してください。スキーマが変更されるとエラーが発生する可能性があります。
scan.startup.specific-offset.file
開始オフセットのバイナリログファイル名です。
いいえ
STRING
-
この設定を使用する場合、scan.startup.mode を specific-offset に設定する必要があります。ファイル名の形式は
mysql-bin.000003などです。scan.startup.specific-offset.pos
指定したバイナリログファイル内の開始オフセットです。
いいえ
INTEGER
-
この設定を使用する場合、scan.startup.mode を specific-offset に設定する必要があります。
scan.startup.specific-offset.gtid-set
開始オフセットの GTID セットです。
いいえ
STRING
-
この設定を使用する場合、scan.startup.mode を specific-offset に設定する必要があります。GTID セットの形式は
24DA167-0C0C-11E8-8442-00059A3C7B00:1-19などです。scan.startup.timestamp-millis
開始タイムスタンプ (ミリ秒) です。
いいえ
LONG
-
この設定を使用する場合、scan.startup.mode を timestamp に設定する必要があります。タイムスタンプの単位はミリ秒です。
重要指定したタイムスタンプから開始する場合、MySQL CDC コネクターは各バイナリログファイルの初期イベントをスキャンして、タイムスタンプに対応するファイルを特定します。指定したタイムスタンプに対応するバイナリログファイルがパージされておらず、データベースサーバー上でアクセス可能であることを確認してください。
server-time-zone
データベースサーバーのセッションタイムゾーンです。
いいえ
STRING
このパラメーターを指定しない場合、システムは Flink ジョブの実行環境のタイムゾーン (選択したアベイラビリティーゾーンのタイムゾーン) を使用します。
例:
Asia/Shanghai。このパラメーターは、TIMESTAMPの値を文字列に変換する方法を制御します。詳細については、「Debezium temporal values」をご参照ください。debezium.min.row.count.to.stream.results
テーブルの行数がこの値を超えると、コネクターはスナップショット読み取りではなくバッチ読み取りを使用します。
いいえ
INTEGER
1000
Flink は、MySQL ソーステーブルを次のいずれかの方法で読み取ります:
-
スナップショット読み取り:テーブル全体をメモリに読み込みます。この方法は高速ですがメモリ消費が大きく、大きなテーブルではメモリ不足 (OOM) エラーが発生する可能性があります。
-
バッチ読み取り:テーブルを小さなバッチに分けて読み取ります。この方法はメモリ効率が高い一方で、スナップショット読み取りより遅くなる場合があります。
connect.timeout
MySQL サーバーへの接続試行のタイムアウトです。タイムアウトした場合、コネクターは再試行します。
いいえ
DURATION
30s
-
connect.max-retries
MySQL サーバーへの接続が失敗した場合の最大再試行回数です。
いいえ
INTEGER
3
-
connection.pool.size
データベース接続のコネクションプールサイズです。
いいえ
INTEGER
20
コネクションプールは、データベース接続を再利用して接続数全体を削減します。
jdbc.properties.*
JDBC URL に渡すカスタム接続パラメーターです。
いいえ
STRING
-
カスタム接続パラメーターを渡すことができます。たとえば、SSL を無効にするには、'jdbc.properties.useSSL' = 'false' を設定します。
サポートされているパラメーターの一覧については、「MySQL Configuration Properties」をご参照ください。
debezium.*
バイナリログを読み取るためのカスタム Debezium パラメーターです。
いいえ
STRING
-
カスタム Debezium パラメーターを渡すことができます。たとえば、デシリアライズの失敗時の処理モードを指定するには、'debezium.event.deserialization.failure.handling.mode'='ignore' を使用します。
警告Debezium パラメーターを任意に変更すると、データ読み取りエラーが発生する可能性があります。たとえば、
debezium.binlog.buffer.sizeパラメーターは設定しないでください。heartbeat.interval
バイナリログのオフセットを進めるためにハートビートイベントを出力する間隔です。
いいえ
DURATION
30s
ハートビートイベントはバイナリログのオフセットを進めます。これは、更新頻度が低いテーブルなどでバイナリログのオフセットが自動的に進まない場合に特に有効です。これにより、バイナリログのオフセットが古くなることを防ぎ、ジョブが失敗してステートレス再起動が必要になる事態を回避できます。
scan.incremental.snapshot.chunk.key-column
スナップショットフェーズ中にチャンクを分割するために使用する列を指定します。
備考欄をご参照ください。
STRING
-
-
プライマリーキーがないテーブルでは必須です。選択する列は非 NULL タイプ (NOT NULL) である必要があります。
-
プライマリーキーがあるテーブルでは任意です。プライマリーキーから 1 列のみ選択できます。
rds.region-id
ApsaraDB RDS for MySQL インスタンスのリージョン ID です。
OSS からアーカイブログを読み取る場合は必須です。
STRING
-
リージョン ID の一覧については、「Regions and zones」をご参照ください。
重要MySQL CDC はランダムな GTID 文字列を生成します。これはバイナリログファイルのオフセットのように単調増加しません。そのため、GTID に基づいて特定のファイルを特定するには、コネクターが OSS からすべてのアーカイブログをダウンロードして解析する必要があり、リソース消費が大きく時間もかかります。したがって、GTID ベースの起動モードではアーカイブされた OSS ログからの読み取りは実行できません。この機能は、特定のタイムスタンプまたはバイナリログファイルのオフセットからの起動のみをサポートします。また、GTID に依存するため、アーカイブログ内で主従切り替えが発生するシナリオもサポートしていません。この機能を使用する前に、これらの制限を十分に評価してください。
rds.access-key-id
ApsaraDB RDS for MySQL アカウントの AccessKey ID です。
OSS からアーカイブログを読み取る場合は必須です。
STRING
-
詳細については、「How do I view my AccessKey ID and AccessKey secret?」をご参照ください。
重要セキュリティに関する注意:認証情報の露出を避けるため、変数管理を使用して AccessKey ID を保存し、取得してください。
rds.access-key-secret
ApsaraDB RDS for MySQL アカウントの AccessKey シークレットです。
OSS からアーカイブログを読み取る場合は必須です。
STRING
-
詳細については、「How do I view my AccessKey ID and AccessKey secret?」をご参照ください。
重要セキュリティに関する注意:認証情報の露出を避けるため、変数管理を使用して AccessKey シークレットを保存し、取得してください。
rds.db-instance-id
ApsaraDB RDS for MySQL インスタンスのインスタンス ID です。
OSS からアーカイブログを読み取る場合は必須です。
STRING
-
-
rds.main-db-id
ApsaraDB RDS for MySQL インスタンスのプライマリデータベース ID です。
いいえ
STRING
-
-
プライマリデータベース ID の取得方法については、「ApsaraDB RDS for MySQL log backup」をご参照ください。
-
Flink エンジン VVR 8.0.7 以降でサポートされています。
説明このパラメーターを指定しない場合、Flink エンジン VVR 11.7 以降では ApsaraDB RDS for MySQL の接続情報に基づいてプライマリデータベース ID が自動的にクエリされます。
rds.download.timeout
OSS から単一のアーカイブログファイルをダウンロードする際のタイムアウトです。
いいえ
DURATION
60s
-
rds.endpoint
OSS からバイナリログ情報を取得するためのサービスエンドポイントです。
いいえ
STRING
-
-
使用可能な値の一覧については、「Service endpoints」をご参照ください。
-
Flink エンジン VVR 8.0.8 以降でサポートされています。
scan.incremental.close-idle-reader.enabled
スナップショットフェーズの完了後にアイドルリーダーをクローズするかどうかを指定します。
いいえ
BOOLEAN
false
-
Flink エンジン VVR 8.0.1 以降でサポートされています。
-
この設定を有効にするには、
execution.checkpointing.checkpoints-after-tasks-finish.enabledをtrueに設定する必要もあります。
scan.read-changelog-as-append-only.enabled
変更ログストリームを追記専用ストリームに変換するかどうかを指定します。
いいえ
BOOLEAN
false
有効な値:
-
true:すべてのメッセージタイプ (INSERT、DELETE、UPDATE_BEFORE、UPDATE_AFTER を含む) を INSERT メッセージに変換します。上流テーブルから削除メッセージを保持するなど、特定のユースケースでのみ有効にしてください。
-
false (デフォルト):すべてのメッセージタイプをそのまま出力します。
説明Flink エンジン VVR 8.0.8 以降でサポートされています。
scan.only.deserialize.captured.tables.changelog.enabled
増分フェーズ中に、キャプチャ対象テーブルの変更イベントのみをデシリアライズするかどうかを指定します。
いいえ
BOOLEAN
-
Flink エンジン VVR 8.x では
false。 -
Flink エンジン VVR 11.1 以降では
true。
有効な値:
-
true:キャプチャ対象テーブルの変更データのみをデシリアライズするため、バイナリログの読み取り速度が向上します。
-
false:すべてのテーブルの変更データをデシリアライズします。
説明-
Flink エンジン VVR 8.0.7 以降でサポートされています。
-
Flink エンジン VVR 8.0.8 以前では、このパラメーター名は debezium.scan.only.deserialize.captured.tables.changelog.enable です。
scan.parse.online.schema.changes.enabled
増分フェーズ中に、RDS lockless change の DDL イベントを解析するかどうかを指定します。
いいえ
BOOLEAN
false
有効な値:
-
true:RDS lockless change の DDL イベントを解析します。
-
false (デフォルト):RDS lockless change の DDL イベントを解析しません。
これは実験的な機能です。オンラインのロックレス変更を実行する前に Flink ジョブのセーブポイントを取得し、必要に応じて回復できるようにしてください。
説明Flink エンジン VVR 11.1 以降でサポートされています。
scan.incremental.snapshot.backfill.skip
スナップショットフェーズ中にバックフィルプロセスをスキップするかどうかを指定します。
いいえ
BOOLEAN
false
有効な値:
-
true:バックフィルプロセスをスキップします。
-
false (デフォルト):バックフィルプロセスをスキップしません。
バックフィルをスキップした場合、スナップショットフェーズ中に発生したテーブルの変更は、スナップショットにマージされず、増分フェーズで後から読み取られます。
重要バックフィルをスキップすると、スナップショットフェーズ中に発生した変更がリプレイされる可能性があるため、データの不整合につながる可能性があります。この場合、at-least-once セマンティクスのみが提供されます。
説明Flink エンジン VVR 11.1 以降でサポートされています。
scan.incremental.snapshot.unbounded-chunk-first.enabled
スナップショットフェーズ中に境界なしチャンクを優先して分配するかどうかを指定します。
いいえ
BOOLEAN
false
有効な値:
-
true:スナップショットフェーズ中に境界なしチャンクの分配を優先します。
-
false (デフォルト):境界なしチャンクの分配を優先しません。
これは実験的な機能です。有効にすると、TaskManager が最後のチャンクを同期する際のメモリ不足 (OOM) エラーのリスクを低減できます。この機能は、ジョブの初回起動前に有効にしてください。
説明Flink エンジン VVR 11.1 以降でサポートされています。
binlog.session.network.timeout
バイナリログ接続のネットワーク読み取り/書き込みタイムアウトです。
いいえ
DURATION
10m
0sに設定すると、接続は MySQL サーバーのデフォルトタイムアウトを使用します。説明Flink エンジン VVR 11.5 以降でサポートされています。
scan.rate-limit.records-per-second
ソースが 1 秒あたりに出力できるレコード数の上限を設定します。
いいえ
LONG
-
このパラメーターを使用してデータの読み取りレートを制限します。この制限は、スナップショットフェーズと増分フェーズの両方に適用されます。
ソースの
numRecordsOutPerSecondメトリクスは、データストリーム全体で 1 秒あたりに出力されたレコード数を示します。このメトリクスに基づいて、このパラメーターを調整できます。スナップショット読み取りフェーズでは、通常、
scan.incremental.snapshot.chunk.sizeパラメーターの値を小さくして、各バッチで読み取るデータ行数を減らす必要があります。説明Flink エンジン VVR 11.5 以降でサポートされています。
scan.binlog.tolerate.gtid-holes
GTID シーケンスのギャップを無視し、不連続なイベントをスキップしてジョブを継続できるようにします。
いいえ
BOOLEAN
false
このパラメーターを有効にする前に、ジョブの起動オフセットが期限切れになっていないことを確認してください。ジョブがパージ済みまたは期限切れの GTID オフセットから開始すると、エンジンは欠落したログを暗黙的にスキップし、データ損失が発生します。
説明Flink エンジン VVR 11.6 以降でサポートされています。
-
-
ディメンションテーブルパラメーター
パラメーター
説明
必須
タイプ
デフォルト
備考
urlMySQL データベースの JDBC URL。
いいえ
文字列
なし
URL の形式は次のとおりです:
jdbc:mysql://<endpoint>:<port>/<database name>。lookup.max-retriesルックアップリクエストが失敗した場合の最大リトライ回数。
いいえ
整数
3
Flink コンピューティングエンジン VVR 6.0.7 以降でのみサポートされます。
lookup.cache.strategyキャッシュポリシー。
いいえ
文字列
Noneサポートされる値:
None、LRU、ALL。詳細については、「Background information」をご参照ください。説明LRU キャッシュポリシーには、lookup.cache.max-rows パラメーターが必要です。
lookup.cache.max-rowsキャッシュに格納する最大行数。
いいえ
整数
100000
-
キャッシュポリシーが
LRUに設定されている場合は必須です。 -
キャッシュポリシーが
ALLに設定されている場合はオプションです。
lookup.cache.ttlキャッシュされたエントリの Time-to-Live (TTL)。
いいえ
期間
なし
lookup.cache.ttlパラメーターの動作は、lookup.cache.strategyの値によって異なります:-
lookup.cache.strategy を None に設定した場合、lookup.cache.ttl を設定する必要はありません。これは、キャッシュの有効期限が切れないことを意味します。
-
lookup.cache.strategy が LRU に設定されている場合、lookup.cache.ttl はキャッシュのタイムアウト期間を指定します。デフォルトでは、キャッシュは無期限です。
-
lookup.cache.strategy が ALL に設定されている場合、lookup.cache.ttl はキャッシュの再読み込み間隔を指定します。デフォルトでは、キャッシュは再読み込みされません。
期間は、
1minや10sなどの時間形式で指定します。lookup.max-join-rowsソーステーブルの各行に対してディメンションテーブルから返す一致する行の最大数。
いいえ
整数
1024
なし
lookup.filter-push-down.enabledディメンションテーブルのフィルタープッシュダウンを有効にするかどうかを指定します。
いいえ
ブール値
false
有効な値:
-
true: フィルタープッシュダウンを有効にします。システムは、データをロードする前に SQL ジョブの条件に基づいてディメンションテーブルのデータをフィルター処理します。 -
false(デフォルト):フィルタープッシュダウンを無効にします。システムは、ディメンションテーブルからデータセット全体をロードします。
説明Flink コンピューティングエンジン VVR 8.0.7 以降でのみサポートされます。
重要フィルタープッシュダウンは、Flink ディメンションテーブルでのみ使用してください。この機能は、MySQL ソーステーブルではサポートされていません。フィルタープッシュダウンを有効にして同じ Flink テーブルをソースとディメンションテーブルの両方として使用する場合、ソーステーブルとして使用する際にはSQL ヒントを使用してこのパラメーターを
falseに設定する必要があります。設定しない場合、ジョブが失敗する可能性があります。 -
-
シンクテーブル固有
パラメーター
説明
必須
タイプ
デフォルト
備考
url
MySQL データベースの JDBC URL です。
いいえ
STRING
なし
URL の形式:
jdbc:mysql://<endpoint>:<port>/<database name>。sink.max-retries
書き込み操作が失敗した場合の最大リトライ回数です。
いいえ
INTEGER
3
なし
sink.buffer-flush.batch-size
各バッチ書き込みに含めるレコード数です。
いいえ
INTEGER
4096
なし
sink.buffer-flush.max-rows
フラッシュ前にメモリ内にバッファーできるレコード数の上限です。
いいえ
INTEGER
10000
このパラメーターは、プライマリキーが指定されている場合にのみ有効です。
sink.buffer-flush.interval
フラッシュ間隔です。この間隔に達すると、他のフラッシュ条件を満たしていなくても、システムは自動的にバッファーをフラッシュします。
いいえ
DURATION
1 s
なし
sink.ignore-delete
DELETE 操作を無視するかどうかを指定します。
いいえ
BOOLEAN
false
Flink SQL ジョブがリトラクション (DELETE または UPDATE_BEFORE メッセージ) を含むストリームを生成する場合、複数のシンクタスクが同じテーブルに対して同時に更新を行うと、データ不整合が発生する可能性があります。
たとえば、あるタスクがレコードを削除し、別のタスクがそのレコードの一部のフィールドのみを更新する場合、更新されないフィールドが誤って null またはデフォルト値に設定される可能性があります。
この問題を防ぐには、
sink.ignore-deleteをtrueに設定して、アップストリームのDELETE操作とUPDATE_BEFORE操作を無視してください。説明-
UPDATE_BEFOREは Flink のリトラクションメカニズムの一部であり、更新操作中に古い値をリトラクトします。 -
sink.ignore-deleteがtrueの場合、シンクはすべてのDELETEおよびUPDATE_BEFOREレコードをスキップし、INSERTおよびUPDATE_AFTERレコードのみを処理します。
sink.ignore-null-when-update
更新レコード内の null 値の処理方法です。
いいえ
BOOLEAN
false
有効な値:
-
true:null 値を無視し、宛先テーブルの対応フィールドは変更しません。この設定では、Flink テーブルにプライマリキーを定義する必要があります。trueに設定した場合:-
VVR 8.0.6 以前では、シンクテーブルでバッチ書き込みはサポートされていません。
-
VVR 8.0.7 以降では、シンクテーブルでバッチ書き込みがサポートされています。
バッチ書き込みはスループットを大幅に向上できますが、データレイテンシーが発生したり、メモリ不足エラーのリスクが高まったりする可能性があります。ビジネス要件に基づいて、これらのトレードオフを評価してください。
-
-
false:対応フィールドを null に更新します。
説明このパラメーターは、VVR バージョン 8.0.5 以降でサポートされています。
-
型マッピング
-
CDC ソーステーブル
MySQL CDC 型
Flink 型
TINYINT
TINYINT
SMALLINT
SMALLINT
TINYINT UNSIGNED
TINYINT UNSIGNED ZEROFILL
INT
INT
MEDIUMINT
SMALLINT UNSIGNED
SMALLINT UNSIGNED ZEROFILL
BIGINT
BIGINT
INT UNSIGNED
INT UNSIGNED ZEROFILL
MEDIUMINT UNSIGNED
MEDIUMINT UNSIGNED ZEROFILL
BIGINT UNSIGNED
DECIMAL(20, 0)
BIGINT UNSIGNED ZEROFILL
SERIAL
FLOAT [UNSIGNED] [ZEROFILL]
FLOAT
DOUBLE [UNSIGNED] [ZEROFILL]
DOUBLE
DOUBLE PRECISION [UNSIGNED] [ZEROFILL]
REAL [UNSIGNED] [ZEROFILL]
NUMERIC(p, s) [UNSIGNED] [ZEROFILL]
DECIMAL(p, s)
DECIMAL(p, s) [UNSIGNED] [ZEROFILL]
BOOLEAN
BOOLEAN
TINYINT(1)
DATE
DATE
TIME [(p)]
TIME [(p)] [WITHOUT TIME ZONE]
DATETIME [(p)]
TIMESTAMP [(p)] [WITHOUT TIME ZONE]
TIMESTAMP [(p)]
TIMESTAMP [(p)]
TIMESTAMP [(p)] WITH LOCAL TIME ZONE
CHAR(n)
STRING
VARCHAR(n)
TEXT
BINARY
BYTES
VARBINARY
BLOB
重要MySQL の
TINYINT(1)型を使用して 0 と 1 以外の値を格納することは避けてください。デフォルトでは、プロパティバージョンが0の場合、MySQL CDC ソーステーブルはTINYINT(1)を Flink のBOOLEAN型にマッピングするため、データの不正確さにつながる可能性があります。TINYINT(1)型で他の数値を格納するには、catalog.table.treat-tinyint1-as-boolean 設定パラメーターをご参照ください。 -
ディメンションテーブルと結果テーブル
MySQL 型
Flink 型
TINYINT
TINYINT
SMALLINT
SMALLINT
TINYINT UNSIGNED
INT
INT
MEDIUMINT
SMALLINT UNSIGNED
BIGINT
BIGINT
INT UNSIGNED
BIGINT UNSIGNED
DECIMAL(20, 0)
FLOAT
FLOAT
DOUBLE
DOUBLE
DOUBLE PRECISION
NUMERIC(p, s)
DECIMAL(p, s)
説明pは 38 以下である必要があります。DECIMAL(p, s)
BOOLEAN
BOOLEAN
TINYINT(1)
DATE
DATE
TIME [(p)]
TIME [(p)] [WITHOUT TIME ZONE]
DATETIME [(p)]
TIMESTAMP [(p)] [WITHOUT TIME ZONE]
TIMESTAMP [(p)]
CHAR(n)
CHAR(n)
VARCHAR(n)
VARCHAR(n)
BIT(n)
BINARY(⌈n/8⌉)
BINARY(n)
BINARY(n)
VARBINARY(N)
VARBINARY(N)
TINYTEXT
STRING
TEXT
MEDIUMTEXT
LONGTEXT
TINYBLOB
BYTES
重要Flink は、最大 2,147,483,647 バイト (2^31 - 1) の MySQL BLOB レコードをサポートします。
BLOB
MEDIUMBLOB
LONGBLOB
データインジェスト
MySQL コネクタを Flink CDC のデータソースとして使用できます。
構文
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: <username>
password: <password>
tables: adb.\.*, bdb.user_table_[0-9]+, (app|web).order_\.*
server-id: 5401-5404
sink:
type: xxxパラメータ
|
パラメーター |
説明 |
必須 |
タイプ |
デフォルト |
備考 |
|
type |
データソースのタイプです。 |
はい |
STRING |
なし |
値は |
|
name |
データソースの名前です。 |
いいえ |
STRING |
なし |
- |
|
hostname |
MySQL データベースのホスト名または IP アドレスです。 |
はい |
STRING |
なし |
Virtual Private Cloud (VPC) アドレスの使用を推奨します。 説明
MySQL データベースと Realtime Compute for Apache Flink ワークスペースが異なる VPC にある場合は、クロス VPC ネットワークを介して接続するか、パブリックネットワークアクセスを使用する必要があります。詳細については、「ワークスペースの管理と操作」および「フルマネージド Flink クラスターからパブリックネットワークにアクセスする方法」をご参照ください。 |
|
username |
MySQL データベースのユーザー名です。 |
はい |
STRING |
なし |
- |
|
password |
MySQL データベースのパスワードです。 |
はい |
STRING |
なし |
- |
|
tables |
同期する MySQL テーブルです。 |
はい |
STRING |
なし |
説明
|
|
tables.exclude |
同期から除外するテーブルです。 |
いいえ |
STRING |
なし |
説明
ドット文字はデータベース名とテーブル名を区切ります。リテラルのドットにマッチさせるには、バックスラッシュでエスケープする必要があります。例: |
|
port |
MySQL データベースのポートです。 |
いいえ |
INTEGER |
3306 |
- |
|
schema-change.enabled |
スキーマ変更イベントを送信するかどうかを指定します。 |
いいえ |
BOOLEAN |
true |
- |
|
server-id |
MySQL サーバーへのクライアント接続で使用する一意の数値 ID または範囲です。 |
いいえ |
STRING |
5400~6400 の範囲のランダムな整数です。 |
ID は MySQL クラスター内のすべてのクライアントで一意である必要があります。同じデータベースに接続する各ジョブに異なる ID を割り当てることを推奨します。 このパラメーターは、 |
|
jdbc.properties.* |
JDBC URL のカスタム接続パラメーターです。 |
いいえ |
STRING |
なし |
カスタム接続パラメーターを渡すことができます。たとえば、SSL プロトコルを使用しないようにするには、 サポートされているパラメーターの一覧については、「MySQL の設定プロパティ」をご参照ください。 |
|
debezium.* |
バイナリログを読み取る Debezium コネクターのカスタムパラメーターです。 |
いいえ |
STRING |
なし |
たとえば、 警告
データ読み取りエラーを避けるため、Debezium パラメーターをむやみに変更しないでください。たとえば、 |
|
scan.incremental.snapshot.chunk.size |
チャンクごとの行数です。 |
いいえ |
INTEGER |
8096 |
テーブルは読み取りのためにチャンクに分割されます。各チャンクは、完全に読み取られるまでメモリにバッファリングされます。 チャンクサイズを小さくすると、チャンクの総数が増加します。これにより、よりきめ細かい障害復旧が可能になりますが、メモリ不足 (OOM) エラーが発生したり、全体のスループットが低下したりする可能性があります。これらのトレードオフのバランスを取り、適切なチャンクサイズを設定する必要があります。 |
|
scan.snapshot.fetch.size |
テーブルから全量データを読み取る際に、バッチごとにフェッチする最大レコード数です。 |
いいえ |
INTEGER |
1024 |
- |
|
scan.startup.mode |
データ読み取りの起動モードです。 |
いいえ |
STRING |
initial |
有効な値:
重要
earliest-offset、specific-offset、および timestamp 起動モードでは、ジョブの開始時のテーブルスキーマが指定された起動オフセットのスキーマと異なる場合、ジョブでエラーが発生します。つまり、これら 3 つの起動モードを使用する場合、指定されたバイナリログの読み取りオフセットとジョブの開始時刻の間に、対応するテーブルのスキーマが変更されないようにする必要があります。 |
|
scan.startup.specific-offset.file |
|
いいえ |
STRING |
なし |
この設定を使用する場合、 scan.startup.mode は specific-offset に設定する必要があります。 ファイル名の形式は、たとえば |
|
scan.startup.specific-offset.pos |
|
いいえ |
INTEGER |
なし |
この設定を使用する場合、scan.startup.mode は specific-offset に設定する必要があります。 |
|
scan.startup.specific-offset.gtid-set |
|
いいえ |
STRING |
なし |
この設定では、scan.startup.mode を specific-offset に設定する必要があります。GTID セットは |
|
scan.startup.timestamp-millis |
|
いいえ |
LONG |
なし |
この設定を使用する場合、scan.startup.mode は timestamp に設定する必要があります。タイムスタンプはミリ秒単位で指定されます。 重要
指定されたタイムスタンプを使用する場合、MySQL CDC コネクターは各ファイルの初期イベントのタイムスタンプを確認して、読み取りを開始するバイナリログファイルを見つけます。指定されたタイムスタンプに対応するバイナリログファイルがデータベースからパージされておらず、アクセス可能であることを確認してください。 |
|
server-time-zone |
The session time zone of the database. |
No |
STRING |
Defaults to the time zone of the Flink job's runtime environment, which is typically the time zone of the selected deployment zone. |
Example: |
|
scan.startup.specific-offset.skip-events |
特定のオフセットから開始する際にスキップするバイナリログイベントの数です。 |
いいえ |
INTEGER |
なし |
このパラメーターは、 scan.startup.mode が specific-offset に設定されている場合にのみ有効です。 |
|
scan.startup.specific-offset.skip-rows |
特定のオフセットから開始する際にスキップする、変更される行数です。単一のバイナリログイベントには、複数の行の変更が含まれる場合があります。 |
いいえ |
INTEGER |
なし |
このパラメーターは、 scan.startup.mode が specific-offset に設定されている場合にのみ有効です。 |
|
connect.timeout |
MySQL サーバーへの接続がタイムアウトするまでの最大待機時間です。 |
いいえ |
DURATION |
30 s |
- |
|
connect.max-retries |
MySQL サーバーへの接続が失敗した後の最大リトライ回数です。 |
いいえ |
INTEGER |
3 |
- |
|
connection.pool.size |
データベース接続プールのサイズです。 |
いいえ |
INTEGER |
20 |
接続プールを使用して接続を再利用することで、データベースへの接続数を減らすことができます。 |
|
heartbeat.interval |
ソースからハートビートイベントを発行してバイナリログのオフセットを進めるための間隔です。 |
いいえ |
DURATION |
30 s |
更新が遅いテーブルでは、バイナリログのオフセットが自動的に進まない場合があります。ハートビートイベントにより、オフセットが確実に進められます。これにより、オフセットの期限切れを防ぎます。期限切れのバイナリログオフセットは、ジョブの失敗やステートレス再起動の原因となる可能性があります。 |
|
rds.region-id |
Alibaba Cloud RDS for MySQL インスタンスのリージョン ID です。 |
OSS からアーカイブログを読み取る際に必須です。 |
STRING |
なし |
リージョン ID の一覧については、「リージョンとゾーン」をご参照ください。 重要
MySQL CDC の GTID 文字列はランダムに生成され、バイナリログファイルのオフセットのように単調増加ではありません。アーカイブログから特定の GTID を見つけるには、OSS からすべてのログファイルをダウンロードして解析する必要があり、これは非常に非効率でコストがかかります。したがって、OSS からのアーカイブログの読み取りは、特定のタイムスタンプまたはバイナリログオフセットからの開始のみをサポートします。この機能は、GTID セットからの開始や、ログ履歴にプライマリ/セカンダリ切り替えが含まれるシナリオをサポートしていません。切り替えは GTID に依存するためです。この機能を使用する前に、これらの制限を慎重に評価してください。 |
|
rds.access-key-id |
Alibaba Cloud RDS for MySQL アカウントの AccessKey ID です。 |
OSS からアーカイブログを読み取る際に必須です。 |
STRING |
なし |
詳細については、「AccessKey ID と AccessKey Secret の表示」をご参照ください。 重要
認証情報を公開しないようにするため、変数管理を使用して AccessKey ID を提供することを推奨します。詳細については、「変数の管理」をご参照ください。 |
|
rds.access-key-secret |
Alibaba Cloud RDS for MySQL アカウントの AccessKey Secret です。 |
OSS からアーカイブログを読み取る際に必須です。 |
STRING |
なし |
詳細については、「AccessKey ID と AccessKey Secret の表示」をご参照ください。 重要
認証情報を公開しないようにするため、変数管理を使用して AccessKey Secret を提供することを推奨します。詳細については、「変数の管理」をご参照ください。 |
|
rds.db-instance-id |
Alibaba Cloud RDS for MySQL インスタンスのインスタンス ID です。 |
OSS からアーカイブログを読み取る際に必須です。 |
STRING |
なし |
- |
|
rds.main-db-id |
Alibaba Cloud RDS for MySQL インスタンスのプライマリデータベース ID です。 |
いいえ |
STRING |
なし |
プライマリデータベース ID の取得方法の詳細については、「RDS for MySQL のログバックアップ」をご参照ください。 説明
このパラメーターが指定されていない場合、Flink エンジン VVR 11.7 以降では、ApsaraDB RDS for MySQL の接続情報に基づいてプライマリデータベース ID を自動的に照会します。 |
|
rds.download.timeout |
OSS から単一のアーカイブログファイルをダウンロードする際のタイムアウトです。 |
いいえ |
DURATION |
60 s |
- |
|
rds.endpoint |
OSS からバイナリログ情報を取得するためのサービスエンドポイントです。 |
いいえ |
STRING |
なし |
利用可能なエンドポイントの一覧については、「エンドポイント」をご参照ください。 |
|
rds.binlog-directory-prefix |
バイナリログファイルを格納するディレクトリのプレフィックスです。 |
いいえ |
STRING |
rds-binlog- |
- |
|
rds.use-intranet-link |
バイナリログファイルのダウンロードに内部ネットワークリンクを使用するかどうかを指定します。 |
いいえ |
BOOLEAN |
true |
- |
|
rds.binlog-directories-parent-path |
バイナリログファイルが格納されている親ディレクトリの絶対パスです。 |
いいえ |
STRING |
なし |
- |
|
chunk-meta.group.size |
チャンクメタデータのグループサイズです。 |
いいえ |
INTEGER |
1000 |
メタデータサイズがこの値を超えると、複数回に分けて送信されます。 |
|
chunk-key.even-distribution.factor.lower-bound |
均等なチャンク分割のための分布係数の下限です。 |
いいえ |
DOUBLE |
0.05 |
分布係数がこの値より小さい場合、不均等なチャンク分割が使用されます。 チャンク分布係数 = (MAX(chunk-key) - MIN(chunk-key) + 1) / 総行数。 |
|
chunk-key.even-distribution.factor.upper-bound |
均等なチャンク分割のための分布係数の上限です。 |
いいえ |
DOUBLE |
1000.0 |
分布係数がこの値より大きい場合、不均等なチャンク分割が使用されます。 チャンク分布係数 = (MAX(chunk-key) - MIN(chunk-key) + 1) / 総行数。 |
|
scan.incremental.close-idle-reader.enabled |
スナップショットフェーズが完了した後にアイドルリーダーを閉じるかどうかを指定します。 |
いいえ |
BOOLEAN |
false |
この設定を有効にするには、 |
|
scan.only.deserialize.captured.tables.changelog.enabled |
増分フェーズ中に、指定されたテーブルの変更イベントのみをデシリアライズするかどうかを指定します。 |
いいえ |
BOOLEAN |
|
有効な値:
|
|
scan.parallel-deserialize-changelog.enabled |
増分フェーズ中に、複数スレッドを使用して変更イベントを解析するかどうかを指定します。 |
いいえ |
BOOLEAN |
false |
有効な値:
説明
Ververica Runtime (VVR) 8.0.11 以降のバージョンでサポートされています。 |
|
scan.parallel-deserialize-changelog.handler.size |
マルチスレッドデシリアライズが有効な場合に使用するイベントハンドラーの数です。 |
いいえ |
INTEGER |
2 |
説明
Ververica Runtime (VVR) 8.0.11 以降のバージョンでサポートされています。 |
|
metadata-column.include-list |
ダウンストリームに渡すメタデータ列のカンマ区切りリストです。 |
いいえ |
STRING |
なし |
利用可能なメタデータには、 説明
MySQL CDC YAML コネクタでは、データベース名、テーブル名、または 重要
|
|
scan.newly-added-table.enabled |
チェックポイントからの再起動時に、新しく追加されたテーブルを同期するか、指定されたパターンに一致しなくなったテーブルを削除するかを指定します。 |
いいえ |
BOOLEAN |
false |
このパラメーターは、チェックポイントまたはセーブポイントから再起動するときに有効になります。 重要
スナップショットフェーズ中に、ソースに新しいテーブルを追加したり、テーブルを削除したり、セーブポイントを取得してそのセーブポイントから再起動したりすることはできません。これにより、ジョブがデータを正しく読み取れなくなります。 |
|
scan.binlog.newly-added-table.enabled |
増分 (バイナリログ) フェーズ中に検出された新しく追加されたテーブルからデータをストリーミングするかどうかを指定します。 |
いいえ |
BOOLEAN |
false |
|
|
scan.incremental.snapshot.chunk.key-column |
特定のテーブルについて、スナップショットフェーズ中にチャンクを分割するためのキーとして使用する列を指定します。 |
いいえ |
STRING |
なし |
|
|
scan.parse.online.schema.changes.enabled |
増分フェーズ中に RDS のロックフリースキーマ変更に由来する DDL イベントを解析するかどうかを指定します。 |
いいえ |
BOOLEAN |
false |
有効な値:
これは実験的機能です。オンラインでのロックフリースキーマ変更を実行する前に、Flink ジョブのセーブポイントを取得して、必要に応じて復旧できるようにすることを推奨します。 説明
Ververica Runtime (VVR) 11.0 以降のバージョンでサポートされています。 |
|
scan.incremental.snapshot.backfill.skip |
スナップショットフェーズ中にバックフィルプロセスをスキップするかどうかを指定します。 |
いいえ |
BOOLEAN |
false |
有効な値:
重要
バックフィルをスキップすると、スナップショットフェーズ中に発生した変更が再実行される可能性があるため、データに不整合が生じる可能性があります。これは at-least-once セマンティクスしか提供されません。 説明
Ververica Runtime (VVR) 11.1 以降のバージョンでサポートされています。 |
|
treat-tinyint1-as-boolean.enabled |
|
いいえ |
BOOLEAN |
true |
有効な値:
|
|
treat-timestamp-as-datetime-enabled |
MySQL の |
いいえ |
BOOLEAN |
false |
有効な値:
MySQL の 有効にすると、このパラメーターは |
|
include-comments.enabled |
テーブルと列のコメントを同期するかどうかを指定します。 |
いいえ |
BOOLEAN |
false |
有効な値:
このパラメーターを有効にすると、ジョブのメモリ使用量が増加します。 |
|
scan.incremental.snapshot.unbounded-chunk-first.enabled |
スナップショットフェーズ中に非境界チャンクを最初に配布するかどうかを指定します。 |
いいえ |
BOOLEAN |
false |
有効な値:
これは実験的機能です。これを有効にすると、最終チャンクを同期する際の TaskManager のメモリ不足 (OOM) エラーのリスクを軽減できます。最初のジョブ起動前にこのパラメーターを有効にすることを推奨します。 説明
Ververica Runtime (VVR) 11.1 以降のバージョンでサポートされています。 |
|
binlog.session.network.timeout |
バイナリログ接続のネットワークタイムアウトです。 |
いいえ |
DURATION |
10 m |
説明
Ververica Runtime (VVR) 11.5 以降のバージョンでサポートされています。 |
|
scan.rate-limit.records-per-second |
ソースが 1 秒あたりに出力できるレコードの最大数です。 |
いいえ |
LONG |
なし |
このパラメーターを使用して、データ読み取りレートを制限します。この制限は、スナップショットフェーズと増分フェーズの両方に適用されます。 ソースの スナップショット読み取りフェーズでは、通常、 説明
Ververica Runtime (VVR) 11.5 以降のバージョンでサポートされています。 |
|
include-binlog-meta.enable |
GTID やバイナリログオフセットなどの元の MySQL バイナリログ情報をメッセージに含めるかどうかを指定します。 |
いいえ |
BOOLEAN |
false |
これは、既存の Canal ベースの同期パイプラインを置き換えるなど、raw バイナリログ同期に役立ちます。 説明
Ververica Runtime (VVR) 11.6 以降のバージョンでサポートされています。 |
|
scan.binlog.tolerate.gtid-holes |
ジョブで GTID シーケンスのギャップを許容し、不連続なイベントをバイパスして実行を継続できるようにします。 |
いいえ |
BOOLEAN |
false |
このパラメーターを有効にする前に、ジョブの開始 GTID オフセットが期限切れになっていないことを確認してください。パージされた GTID オフセットから開始すると、エンジンは欠落しているログを警告なしにスキップし、データ損失を引き起こします。 説明
Ververica Runtime (VVR) 11.6 以降のバージョンでサポートされています。 |
既存のカタログの再利用
VVR 11.5 以降、Flink CDC データインジェストジョブでは、[Catalogs] ページから組み込みの MySQL カタログを直接参照できるため、接続プロパティを手動で設定する必要がなくなりました。
source:
type: mysql
using.built-in-catalog: mysql_rds_catalog現在、データインジェストジョブは、MySQL カタログから以下のパラメーターを自動的に再利用します。
-
hostname
-
port
-
username
-
password
-
catalog.table.metadata-columns
-
catalog.table.treat-tinyint1-as-boolean
これらのパラメーターをオーバーライドするには、YAML 設定で明示的に定義します。YAML で定義されたパラメーターが優先されます。
型マッピング
次の表に、データインジェストの型マッピングを示します。
|
MySQL CDC 型 |
Flink CDC 型 |
|
TINYINT(n) |
TINYINT |
|
SMALLINT |
SMALLINT |
|
TINYINT UNSIGNED |
|
|
TINYINT UNSIGNED ZEROFILL |
|
|
YEAR |
INT |
|
INT |
INT |
|
MEDIUMINT |
|
|
MEDIUMINT UNSIGNED |
|
|
MEDIUMINT UNSIGNED ZEROFILL |
|
|
SMALLINT UNSIGNED |
|
|
SMALLINT UNSIGNED ZEROFILL |
|
|
BIGINT |
BIGINT |
|
INT UNSIGNED |
|
|
INT UNSIGNED ZEROFILL |
|
|
BIGINT UNSIGNED |
DECIMAL(20, 0) |
|
BIGINT UNSIGNED ZEROFILL |
|
|
SERIAL |
|
|
FLOAT [UNSIGNED] [ZEROFILL] |
FLOAT |
|
DOUBLE [UNSIGNED] [ZEROFILL] |
DOUBLE |
|
DOUBLE PRECISION [UNSIGNED] [ZEROFILL] |
|
|
REAL [UNSIGNED] [ZEROFILL] |
|
|
NUMERIC(p, s) [UNSIGNED] [ZEROFILL] where p <= 38 |
DECIMAL(p, s) |
|
DECIMAL(p, s) [UNSIGNED] [ZEROFILL] where p <= 38 |
|
|
FIXED(p, s) [UNSIGNED] [ZEROFILL] where p <= 38 |
|
|
BOOLEAN |
BOOLEAN |
|
BIT(1) |
|
|
TINYINT(1) |
|
|
DATE |
DATE |
|
TIME [(p)] |
TIME [(p)] |
|
DATETIME [(p)] |
TIMESTAMP [(p)] |
|
TIMESTAMP [(p)] |
マッピングは
|
|
CHAR(n) |
CHAR(n) |
|
VARCHAR(n) |
VARCHAR(n) |
|
BIT(n) |
BINARY(⌈(n + 7) / 8⌉) |
|
BINARY(n) |
BINARY(n) |
|
VARBINARY(N) |
VARBINARY(N) |
|
NUMERIC(p, s) [UNSIGNED] [ZEROFILL] where 38 < p <= 65 |
STRING 説明
MySQL の decimal データ型は最大 65 の精度をサポートしていますが、Flink の |
|
DECIMAL(p, s) [UNSIGNED] [ZEROFILL] where 38 < p <= 65 |
|
|
FIXED(p, s) [UNSIGNED] [ZEROFILL] where 38 < p <= 65 |
|
|
TINYTEXT |
STRING |
|
TEXT |
|
|
MEDIUMTEXT |
|
|
LONGTEXT |
|
|
ENUM |
|
|
JSON |
STRING 説明
Flink は JSON データ型を JSON フォーマットの文字列に変換します。 |
|
GEOMETRY |
STRING 説明
Flink は MySQL の空間データ型を、固定の JSON フォーマットの文字列に変換します。詳細については、「MySQL spatial data type mapping」をご参照ください。 |
|
POINT |
|
|
LINESTRING |
|
|
POLYGON |
|
|
MULTIPOINT |
|
|
MULTILINESTRING |
|
|
MULTIPOLYGON |
|
|
GEOMETRYCOLLECTION |
|
|
TINYBLOB |
BYTES 説明
MySQL の |
|
BLOB |
|
|
MEDIUMBLOB |
|
|
LONGBLOB |
例
-
CDC ソーステーブル
CREATE TEMPORARY TABLE mysqlcdc_source ( order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql', 'hostname' = '<yourHostname>', 'port' = '3306', 'username' = '<yourUsername>', 'password' = '<yourPassword>', 'database-name' = '<yourDatabaseName>', 'table-name' = '<yourTableName>' ); CREATE TEMPORARY TABLE blackhole_sink( order_id INT, customer_name STRING ) WITH ( 'connector' = 'blackhole' ); INSERT INTO blackhole_sink SELECT order_id, customer_name FROM mysqlcdc_source; -
ディメンションテーブル
CREATE TEMPORARY TABLE datagen_source( a INT, b BIGINT, c STRING, `proctime` AS PROCTIME() ) WITH ( 'connector' = 'datagen' ); CREATE TEMPORARY TABLE mysql_dim ( a INT, b VARCHAR, c VARCHAR ) WITH ( 'connector' = 'mysql', 'hostname' = '<yourHostname>', 'port' = '3306', 'username' = '<yourUsername>', 'password' = '<yourPassword>', 'database-name' = '<yourDatabaseName>', 'table-name' = '<yourTableName>' ); CREATE TEMPORARY TABLE blackhole_sink( a INT, b STRING ) WITH ( 'connector' = 'blackhole' ); INSERT INTO blackhole_sink SELECT T.a, H.b FROM datagen_source AS T JOIN mysql_dim FOR SYSTEM_TIME AS OF T.`proctime` AS H ON T.a = H.a; -
シンクテーブル
CREATE TEMPORARY TABLE datagen_source ( `name` VARCHAR, `age` INT ) WITH ( 'connector' = 'datagen' ); CREATE TEMPORARY TABLE mysql_sink ( `name` VARCHAR, `age` INT ) WITH ( 'connector' = 'mysql', 'hostname' = '<yourHostname>', 'port' = '3306', 'username' = '<yourUsername>', 'password' = '<yourPassword>', 'database-name' = '<yourDatabaseName>', 'table-name' = '<yourTableName>' ); INSERT INTO mysql_sink SELECT * FROM datagen_source; -
Flink CDC ソース
source: type: mysql name: MySQL Source hostname: ${mysql.hostname} port: ${mysql.port} username: ${mysql.username} password: ${mysql.password} tables: ${mysql.source.table} server-id: 7601-7604 sink: type: values name: Values Sink print.enabled: true sink.print.logger: true
MySQL CDC ソース
-
仕組み
MySQL CDC ソースが起動すると、フルテーブルスキャンを実行し、プライマリキーに基づいてテーブルをチャンクに分割し、現在の Binlog オフセットを記録します。次に、インクリメンタルスナップショットアルゴリズムを使用し、
SELECTステートメントで各チャンクを順次読み取ります。ジョブは定期的にチェックポイントを実行して、完了したチャンクを記録します。フェイルオーバーが発生した場合、ジョブは未完了のチャンクの読み取りを再開します。すべてのチャンクが読み取られた後、ソースは以前に記録された Binlog オフセットから増分変更の読み取りに切り替わります。Flink ジョブは定期的にチェックポイントを実行し続け、Binlog オフセットを記録します。これにより、フェイルオーバーが発生した場合でも、ジョブは最後に記録されたオフセットから再開でき、exactly-once セマンティクスが実現されます。インクリメンタルスナップショットアルゴリズムの詳細については、「MySQL CDC コネクタ」をご参照ください。
-
メタデータ
メタデータは、シャーディングされたデータベースとテーブルを単一のシンクに同期およびマージするのに役立ちます。シャーディングされたテーブルをマージする場合、各レコードの元のソースデータベースとテーブルを特定する必要がよくあります。メタデータ列を使用すると、この情報にアクセスでき、複数のシャーディングされたテーブルを 1 つのシンクテーブルに簡単に統合できます。
MySQL CDC ソースはメタデータ列をサポートしており、これにより次のメタデータにアクセスできます。
メタデータキー
タイプ
説明
database_name
STRING NOT NULL
行を含むデータベースの名前。
table_name
STRING NOT NULL
行を含むテーブルの名前。
op_ts
TIMESTAMP_LTZ(3) NOT NULL
データベースで変更が発生した時刻。レコードが Binlog ではなくテーブルの履歴スナップショットからのものである場合、この値は
0です。説明このフィールドの精度はミリ秒単位です。
op_type
STRING NOT NULL
行の変更操作のタイプ。
-
+I: INSERT メッセージ
-
-D: DELETE メッセージ
-
-U: UPDATE_BEFORE メッセージ
-
+U: UPDATE_AFTER メッセージ
説明VVR 8.0.7 以降でサポートされています。
query_log
STRING NOT NULL
行に対応する MySQL クエリログレコード。
説明クエリログを記録するには、MySQL で
binlog_rows_query_log_eventsパラメーターを有効にする必要があります。次の例では、MySQL インスタンス内の複数のデータベースにある複数のシャーディングされた
ordersテーブルを、Hologres 内の単一のholo_ordersテーブルにマージします。CREATE TEMPORARY TABLE mysql_orders ( db_name STRING METADATA FROM 'database_name' VIRTUAL, -- データベース名を読み取ります。 table_name STRING METADATA FROM 'table_name' VIRTUAL, -- テーブル名を読み取ります。 operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL, -- 変更タイムスタンプを読み取ります。 op_type STRING METADATA FROM 'op_type' VIRTUAL, -- 変更タイプを読み取ります。 order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'flinkuser', 'password' = 'flinkpw', 'database-name' = 'mydb_.*', -- 正規表現で複数のシャーディングされたデータベースに一致させます。 'table-name' = 'orders_.*' -- 正規表現で複数のシャーディングされたテーブルに一致させます。 ); INSERT INTO holo_orders SELECT * FROM mysql_orders;WITH句でscan.read-changelog-as-append-only.enabledパラメーターをtrueに設定した場合、出力はシンクテーブルのプライマリキーがどのように設定されているかによって異なります:-
シンクテーブルのプライマリキーが
order_idの場合、出力にはソーステーブルからの各プライマリキーの最後の変更のみが含まれます。プライマリキーの最後の変更が削除操作だった場合、シンクテーブルには同じプライマリキーとop_typeが-Dのレコードが含まれます。 -
シンクテーブルのプライマリキーが
order_id、operation_ts、およびop_typeの複合キーである場合、出力にはソーステーブルからの各プライマリキーの完全な変更履歴が含まれます。
-
-
正規表現のサポート
MySQL CDC ソースは、
table-nameとdatabase-nameオプションで正規表現を使用して、複数のテーブルまたはデータベースに一致させることをサポートしています。次の例は、正規表現を使用して複数のテーブルを指定する方法を示しています。CREATE TABLE products ( db_name STRING METADATA FROM 'database_name' VIRTUAL, table_name STRING METADATA FROM 'table_name' VIRTUAL, operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL, order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = '(^(test).*|^(tpc).*|txc|.*[p$]|t{2})', -- 正規表現で複数のデータベースに一致させます。 'table-name' = '(t[5-8]|tt)' -- 正規表現で複数のテーブルに一致させます。 );上記の例の正規表現は、次のように説明します:
-
^(test).*は前方一致の例です。この式は、test1やtest2のようにtestで始まるデータベース名に一致します。 -
.*[p$]は後方一致の例です。この式は、cdcpやedcpのようにpで終わるデータベース名、またはcdc$のようにドル記号 ($) で終わるデータベース名に一致します。 -
txcは完全一致です。txcという名前のデータベースに一致します。
MySQL CDC ソースは、
database-name.table-nameパターンを使用して完全修飾テーブル名にマッチします。たとえば、パターン(^(test).*|^(tpc).*|txc|.*[p$]|t{2}).(t[5-8]|tt)は、データベース内のtxc.ttやtest2.t5などのテーブルに一致します。重要SQL ジョブでは、
table-nameおよびdatabase-nameオプションは、複数のテーブルまたはデータベースを指定するためのカンマ区切りリストをサポートしていません。-
複数のテーブルに一致させるか、複数の正規表現を使用するには、それらを括弧で囲み、パイプ文字 (
|) で区切ります。たとえば、userテーブルとproductテーブルから読み取るには、table-nameオプションを(user|product)に設定します。 -
一部の正規表現構文は、パイプ (
|) 演算子を使用して書き換える必要があります。たとえば、量指定子 {m,n} を含む式mytable_\d{1,2}は、サポートされている同等の(mytable_\d{1}|mytable_\d{2})に書き換えます。
-
-
並列度の管理
MySQL コネクタは全量データの並列読み取りをサポートしており、これによりデータ読み込み効率が向上します。Autopilot 機能と組み合わせることで、ジョブは並列読み取りが完了した後のインクリメンタルフェーズ中に自動的にリソースをスケールダウンし、コンピューティングリソースを節約できます。
Realtime Compute for Apache Flink コンソールでは、基本モードまたはエキスパートモードの [リソース設定] ページでジョブの並列度を設定できます。違いは次のとおりです:
-
基本モードは、ジョブ全体の並列度を設定します。

-
エキスパートモードでは、特定の VERTEX の並列度をオンデマンドで設定できます。
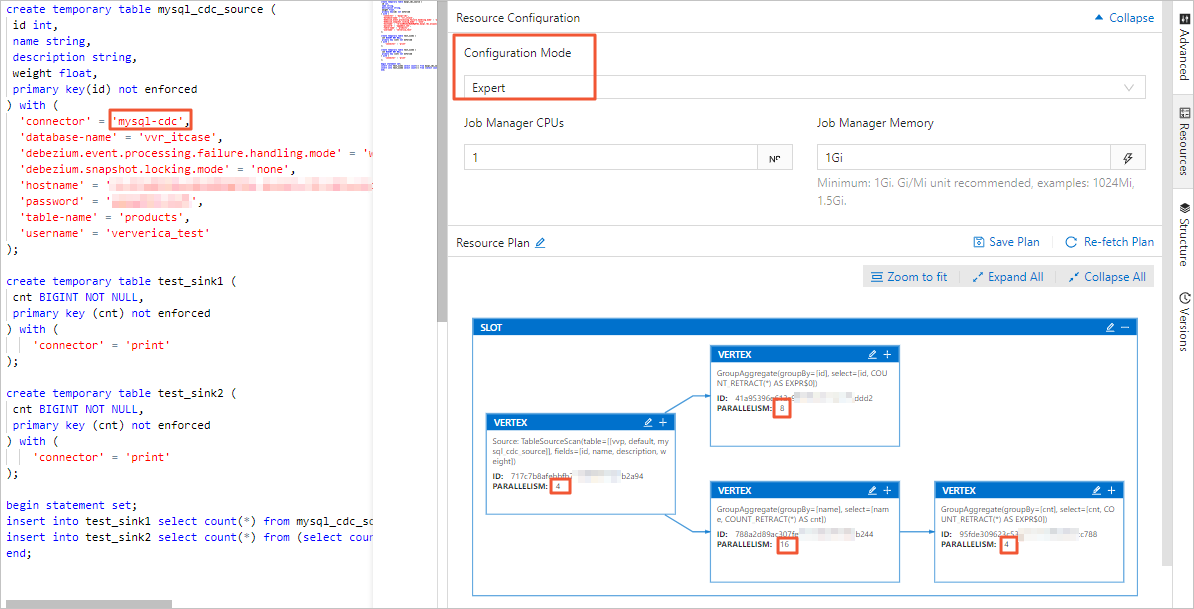
リソース設定の詳細については、「ジョブデプロイメント情報の設定」をご参照ください。
重要どちらのモードを使用するかにかかわらず、テーブルで宣言された
server-idの値の範囲は、ジョブの並列度以上でなければなりません。たとえば、server-idの範囲が5404-5412の場合、一意のサーバー ID が 9 つあるため、ジョブの最大並列度は 9 となります。さらに、同じ MySQL インスタンスに接続する異なるジョブのserver-id範囲は重複してはなりません。各ジョブには一意のserver-id範囲が必要です。 -
-
Autopilot 自動スケーリング
全量スナップショットフェーズでは、大量の履歴データが蓄積されます。読み取り効率を向上させるため、通常、データは並列で読み取られます。対照的に、増分 Binlog フェーズでは、データ量が少なく、グローバルな順序を維持する必要があるため、通常は単一のリーダーで十分です。Autopilot 機能は、これらの異なる要件を満たすために、パフォーマンスとリソースのバランスを自動的に取ります。
Autopilot は、各 MySQL CDC ソースタスクのトラフィックを監視します。ジョブが Binlog フェーズに入ると、1 つのタスクのみがアクティブに Binlog から読み取りを行い、他のタスクがアイドル状態の場合、Autopilot はソースの CU 数と並列度を自動的にスケールダウンします。Autopilot を有効にするには、ジョブの O&M ページに移動し、Autopilot モードをアクティブに設定します。
説明デフォルトでは、スケールダウンの最小トリガー間隔は 24 時間です。Autopilot のパラメーターと詳細については、「Autopilot の設定」をご参照ください。
-
起動モード
scan.startup.modeオプションを使用して、MySQL CDC ソースの起動モードを指定します。使用可能な値は次のとおりです:-
initial (デフォルト):最初の起動時にデータベーステーブルの完全なスナップショットを実行し、その後増分モードに切り替えて Binlog を読み取ります。
-
earliest-offset:スナップショットフェーズをスキップし、利用可能な最も古い Binlog オフセットから読み取りを開始します。
-
latest-offset:スナップショットフェーズをスキップし、Binlog の末尾から読み取りを開始します。このモードでは、ソースはジョブの開始後に発生したデータ変更のみを読み取ることができます。
-
specific-offset:スナップショットフェーズをスキップし、指定された Binlog オフセットから読み取りを開始します。オフセットは、Binlog ファイル名と位置、または GTID セットを使用して指定できます。
-
timestamp:スナップショットフェーズをスキップし、指定されたタイムスタンプから Binlog イベントの読み取りを開始します。
例:
CREATE TABLE mysql_source (...) WITH ( 'connector' = 'mysql-cdc', -- 'scan.startup.mode' = 'earliest-offset', -- 最も古いオフセットから開始します。 -- 'scan.startup.mode' = 'latest-offset', -- 最新のオフセットから開始します。 'scan.startup.mode' = 'specific-offset', -- 特定のオフセットから開始します。 -- 'scan.startup.mode' = 'timestamp', -- 特定のタイムスタンプから開始します。 'scan.startup.specific-offset.file' = 'mysql-bin.000003', -- specific-offset モードで Binlog ファイル名を指定します。 'scan.startup.specific-offset.pos' = '4', -- specific-offset モードで Binlog の位置を指定します。 -- 'scan.startup.specific-offset.gtid-set' = '24DA167-0C0C-11E8-8442-00059A3C7B00:1-19', -- specific-offset モードで GTID セットを指定します。 -- 'scan.startup.timestamp-millis' = '1667232000000' -- timestamp モードで起動タイムスタンプを指定します。 ... )重要-
各チェックポイント中に、MySQL ソースは現在のオフセットを INFO レベルでログに記録します。ログのプレフィックスは
Binlog offset on checkpoint {checkpoint-id}です。このログ情報を使用して、特定のチェックポイントオフセットからジョブを開始できます。 -
テーブルのスキーマが変更された場合、
earliest-offset、specific-offset、またはtimestampから開始するとエラーが発生する可能性があります。基礎となる Debezium リーダーは最新のスキーマを内部的に保持しており、異なるスキーマを持つ以前のデータを正しく解析できません。
-
-
プライマリキーのない CDC ソーステーブル
-
プライマリキーのないテーブルを使用するには、
scan.incremental.snapshot.chunk.key-columnオプションを一意の値を持つ非ヌル列に設定する必要があります。 -
プライマリキーのないテーブルの処理セマンティクスは、
scan.incremental.snapshot.chunk.key-columnで指定された列が更新されるかどうかによって異なります:-
指定された列が更新されない場合、exactly-once セマンティクスが保証されます。
-
指定された列が更新される場合、at-least-once セマンティクスのみが保証されます。ただし、シンクでプライマリキーを定義し、べき等な操作を使用することで、データの正確性を確保できます。
-
-
-
ApsaraDB RDS for MySQL のバックアップログの読み取り
MySQL CDC ソースは、ApsaraDB RDS for MySQL のバックアップログの読み取りをサポートしています。これは、全量スナップショットフェーズが長く、ローカルの Binlog ファイルがパージされても、バックアップファイル (自動または手動でアップロード) がまだ利用可能な場合に役立ちます。
例:
CREATE TABLE mysql_source (...) WITH ( 'connector' = 'mysql-cdc', 'rds.region-id' = 'cn-beijing', 'rds.access-key-id' = 'xxxxxxxxx', 'rds.access-key-secret' = 'xxxxxxxxx', 'rds.db-instance-id' = 'rm-xxxxxxxxxxxxxxxxx', 'rds.main-db-id' = '12345678', 'rds.download.timeout' = '60s' ... ) -
CDC ソースの再利用を有効にする
単一のジョブ内の複数の MySQL CDC ソーステーブルは、それぞれ別の Binlog クライアントを起動して同じインスタンスに接続すると、データベースの負荷が増加します。詳細については、「MySQL CDC FAQ」をご参照ください。
解決策
VVR バージョン 8.0.7 以降では、MySQL CDC ソースの再利用がサポートされています。再利用機能は、互換性のある MySQL CDC ソーステーブルをマージします。マージは、ソーステーブルがデータベース名、テーブル名、および
server-idを除いて同じ設定オプションを持つ場合に実行されます。エンジンは、同じジョブ内の MySQL CDC ソースを自動的にマージします。手順
-
SQL ジョブで
SETコマンドを使用します:SET 'table.optimizer.source-merge.enabled' = 'true'; # VVR 8.0.8 および 8.0.9 の場合は、このオプションも設定します: SET 'sql-gateway.exec-plan.enabled' = 'false';ソースの再利用は、VVR 11.1 以降ではデフォルトで有効になっています。
-
ステートなしでジョブを開始してください。 Source の再利用設定オプションを変更すると、ジョブトポロジーが変更されます。ステートなしでジョブを開始する必要があります。そうしないと、ジョブの開始に失敗したり、データが失われたりする可能性があります。ソースがマージされると、
MergetableSourceScanノードが表示されます。
重要-
再利用を有効にした後は、オペレーターチェーンを無効にしないことを推奨します。
pipeline.operator-chainingをfalseに設定すると、データのシリアル化とデシリアル化のオーバーヘッドが増加します。マージされるソースが多いほど、オーバーヘッドは高くなります。 -
VVR 8.0.7 では、オペレーターチェーンを無効にすると、シリアル化の問題が発生します。
-
バイナリログ読み取りの高速化
ソースとして使用する場合、MySQL コネクタは増分フェーズ中にバイナリログを解析して変更イベントを生成します。バイナリログは、すべてのテーブル変更をバイナリ形式で記録します。次の方法で、バイナリログの解析を高速化できます。
-
解析フィルターの有効化
-
scan.only.deserialize.captured.tables.changelog.enabledオプションを使用して、指定されたテーブルの変更イベントのみを解析できます。
-
-
Debezium パラメーターのチューニング
debezium.max.queue.size: 162580 debezium.max.batch.size: 40960 debezium.poll.interval.ms: 50-
debezium.max.queue.size: ブロッキングキュー内のレコードの最大数を指定します。このキューは、Debezium がデータベースから読み取ったイベントを、ダウンストリームに書き込むまで保持します。デフォルト: 8192。 -
debezium.max.batch.size: コネクタがイテレーションごとに処理するイベントの最大数を指定します。デフォルト: 2048。 -
debezium.poll.interval.ms: コネクタが新しい変更イベントのリクエスト間で待機する間隔をミリ秒単位で指定します。デフォルト: 1000 (1 秒)。
-
例:
CREATE TABLE mysql_source (...) WITH (
'connector' = 'mysql-cdc',
-- Debezium 設定
'debezium.max.queue.size' = '162580',
'debezium.max.batch.size' = '40960',
'debezium.poll.interval.ms' = '50',
-- 解析フィルターの有効化
'scan.only.deserialize.captured.tables.changelog.enabled' = 'true', -- 指定されたテーブルの変更イベントのみを解析
...
)source:
type: mysql
name: MySQL Source
hostname: ${mysql.hostname}
port: ${mysql.port}
username: ${mysql.username}
password: ${mysql.password}
tables: ${mysql.source.table}
server-id: 7601-7604
# Debezium 設定
debezium.max.queue.size: 162580
debezium.max.batch.size: 40960
debezium.poll.interval.ms: 50
# 解析フィルターの有効化
scan.only.deserialize.captured.tables.changelog.enabled: trueフルマネージド MySQL コネクタは、最大 85 MB/s のレートでバイナリログを消費できます。これは、オープンソースの Flink MySQL コネクタのスループットの約 2 倍です。バイナリログの生成レートが 85 MB/s を超える場合 (6 秒ごとに 512 MB のファイル 1 つに相当)、Flink ジョブのレイテンシーは継続的に増加します。生成レートが低下すると、レイテンシーは減少します。バイナリログ内の大規模トランザクションは、処理レイテンシーの一時的なスパイクを引き起こす可能性があります。このスパイクは、トランザクションが完全に読み取られた後に収まります。
MySQL CDC DataStream API
DataStream API を使用してデータを読み書きするには、対応する DataStream コネクタを使用します。セットアップ手順については、「DataStream connector usage」をご参照ください。
次の例では、DataStream API プログラムで MySqlSource を使用する方法と、必要な POM の依存関係を示します。
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // キャプチャするデータベースを設定します。
.tableList("yourDatabaseName.yourTableName") // キャプチャするテーブルを設定します。
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // SourceRecord を JSON 文字列に変換します。
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// チェックポイントを有効にします。
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// ソースタスクの並列度を 4 に設定します。
.setParallelism(4)
.print().setParallelism(1); // メッセージの順序を維持するため、シンクの並列度は 1 にします。
env.execute("Print MySQL Snapshot + Binlog");
}
}<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>ververica-connector-mysql</artifactId>
<version>${vvr.version}</version>
</dependency>MySqlSource をビルドするには、次のパラメーターを指定します:
|
パラメーター |
説明 |
|
hostname |
MySQL データベースの IP アドレスまたはホスト名です。 |
|
port |
MySQL データベースのポート番号です。 |
|
databaseList |
キャプチャするデータベース名です。 説明
データベース名に正規表現を使用することで、複数のデータベースからデータを読み取れます。すべてのデータベースに一致させるには、 |
|
username |
MySQL データベースのユーザー名です。 |
|
password |
MySQL データベースのパスワードです。 |
|
deserializer |
|
POM の依存関係では、次のプレースホルダーを指定してください:
|
${vvr.version} |
Realtime Compute for Apache Flink のエンジンバージョンです (例: 説明
ホットフィックスが予告なくリリースされる場合があるため、Maven のバージョン番号を使用してください。 |
|
${flink.version} |
Apache Flink のバージョンです (例: 重要
互換性の問題を回避するため、Realtime Compute for Apache Flink のエンジンバージョンに対応する Apache Flink バージョンを使用してください。バージョンの互換性の詳細については、「Engines」をご参照ください。 |
よくある質問
CDC ソーステーブルの問題については、「CDC issues」をご参照ください。