Logstash はパイプラインを使用してデータを収集し、処理します。パイプライン構成は、input、output、およびオプションの filter プラグインで構成されます。input および output プラグインを使用してデータソースと宛先を設定し、filter プラグインを使用してデータをフィルタリングまたは前処理できます。Alibaba Cloud Logstash は、最大 20 のパイプラインの並列実行をサポートしています。このトピックでは、構成ファイルを使用したパイプラインの管理方法 (パイプラインの作成、変更、コピー、削除を含む) について説明します。
前提条件
Alibaba Cloud Elasticsearch インスタンスが作成されていること。
詳細については、「Alibaba Cloud Elasticsearch インスタンスの作成」をご参照ください。
宛先の Alibaba Cloud Elasticsearch インスタンスでインデックスの自動作成機能が有効になっているか、またはインスタンスにインデックスとそのマッピングが事前に作成されていること。このトピックでは、インデックスの自動作成機能を例として使用します。
インデックスの自動作成を有効にする方法の詳細については、「YML パラメーターの設定」をご参照ください。インデックスとマッピングの作成方法の詳細については、「初心者向けガイド:インスタンス作成からデータ取得まで」をご参照ください。
説明データセキュリティを確保するため、Alibaba Cloud Elasticsearch はデフォルトで Auto Create Index 設定を 許可しない に設定しています。Alibaba Cloud Logstash は、Create index API を呼び出すのではなく、データを送信することによってインデックスを作成するため、Alibaba Cloud Logstash を使用してデータをアップロードする前に、クラスターの Auto Create Index を 許可する に設定するか、事前にインデックスとマッピングを作成する必要があります。
Alibaba Cloud Logstash インスタンスが作成されていること。
詳細については、「Alibaba Cloud Logstash インスタンスの作成」をご参照ください。
制限事項
Alibaba Cloud Logstash は、最大 20 のパイプラインの並列実行をサポートしています。
output で指定されたデータソースが Alibaba Cloud Elasticsearch インスタンスである場合、インデックスの自動作成を有効にするか、宛先インデックスとマッピングを事前に作成する必要があります。
Alibaba Cloud プロダクトを設定する場合、インスタンスは同じ VPC (Virtual Private Cloud) 内にある必要があります。そうでない場合は、ネットワークとセキュリティの設定を行う必要があります。詳細については、「パブリックネットワークデータ伝送のための NAT 設定」をご参照ください。
output で file_extend パラメーターを使用する場合は、まず `logstash-output-file_extend` プラグインをインストールする必要があります。詳細については、「プラグインのインストールまたはアンインストール」をご参照ください。
パイプラインの作成
Alibaba Cloud Elasticsearch コンソールの [Logstash クラスター] ページに移動します。
対象のクラスターに移動します。
上部のナビゲーションバーで、クラスターが存在するリージョンを選択します。
Logstash クラスター ページで、対象のクラスターを見つけてその ID をクリックします。
左側のナビゲーションウィンドウで、パイプライン管理 をクリックします。
パイプラインの作成 をクリックします。
パイプライン ID と 設定内容 を入力します。
次のコードは設定例です。
input { beats { port => 8000 } } filter { } output { elasticsearch { hosts => ["http://es-cn-o40xxxxxxxxxx****.elasticsearch.aliyuncs.com:9200"] index => "logstash_test_1" password => "es_password" user => "elastic" } file_extend { path => "/ssd/1/ls-cn-v0h1kzca****/logstash/logs/debug/test" } }パラメーター
説明
input
入力データソースを指定します。サポートされているデータソースタイプの詳細については、「Input プラグイン」をご参照ください。
説明Input プラグインが Logstash プロセスが配置されているノードのポートをリッスンする必要がある場合は、8000 から 9000 の範囲のポートを使用してください。
input でプラグイン、ドライバー、またはその他のファイルを定義するには、拡張ファイルパスの表示 をクリックします。拡張ファイル管理 ダイアログボックスで アップロード をクリックし、プロンプトに従って対応するファイルをアップロードします。詳細については、「拡張ファイルの設定」をご参照ください。
filter
入力データをフィルタリングするプラグインを指定します。サポートされているプラグインタイプの詳細については、「Filter プラグイン」をご参照ください。
output
宛先データソースのタイプを指定します。サポートされているデータソースタイプの詳細については、「Output プラグイン」をご参照ください。
file_extend:オプション。デバッグログ機能を有効にし、path パラメーターを使用してデバッグログの出力パスを設定します。このパラメーターを設定すると、コンソールで直接出力結果を表示できます。このパラメーターが設定されていない場合、出力結果を確認するために宛先に移動してからコンソールに戻って変更する必要があり、時間がかかります。詳細については、「Logstash パイプライン設定を使用したデバッグ」をご参照ください。
重要file_extend パラメーターを使用する前に、`logstash-output-file_extend` プラグインをインストールしてください。詳細については、「プラグインのインストールまたはアンインストール」をご参照ください。path パラメーターは、デフォルトでシステム指定のパスに設定されています。変更しないでください。また、設定デバッグの有効化 をクリックして path の値を取得することもできます。
構成ファイルの構造とサポートされているデータ型 (バージョンによって異なる場合があります) の詳細については、「設定ファイルの構造」をご参照ください。
重要セキュリティ上の理由から、Java Database Connectivity (JDBC) ドライバーを使用してパイプラインを設定する場合は、jdbc_connection_string パラメーターに
allowLoadLocalInfile=false&autoDeserialize=falseを追加してください。そうしないと、Logstash 構成ファイルを追加する際に CDN マッピングシステムが検証失敗を報告します。例:jdbc_connection_string => "jdbc:mysql://xxx.drds.aliyuncs.com:3306/<database_name>?allowLoadLocalInfile=false&autoDeserialize=false"。設定に last_run_metadata_path などのパラメーターが含まれている場合、Alibaba Cloud Logstash サービスはファイルパスを提供する必要があります。バックエンドはテスト用に /ssd/1/<Logstash_instance_ID>/logstash/data/ パスを提供します。このディレクトリ内のデータは削除されません。したがって、十分なディスク領域が利用可能であることを確認する必要があります。パラメーターのパスを指定すると、Logstash は対応するパスにファイルを自動的に生成します。ファイルの内容は表示できません。
Alibaba Cloud Logstash は VPC 内に作成されるため、Alibaba Cloud プロダクトを設定する際には同じ VPC 内のインスタンスを使用する必要があります。パブリックネットワークから Alibaba Cloud Logstash にアクセスする場合は、ネットワークとセキュリティの設定を行う必要があります。詳細については、「パブリックネットワークデータ伝送のための NAT 設定」をご参照ください。
テスト中のログ出力には `file_extend` を使用してください。`stdout` は使用しないでください。
次へ をクリックし、パイプラインパラメーターを設定します。
パラメーター
説明
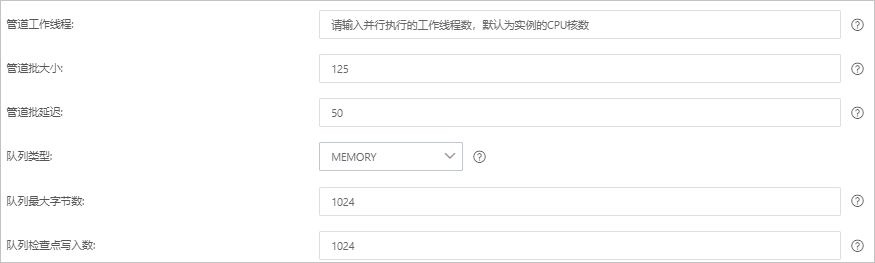
パイプラインワーカー
パイプラインのフィルターおよび出力ステージを並行して実行するワーカースレッドの数。イベントがバックログされているか、CPU が飽和状態でない場合は、スレッド数を増やして CPU 処理能力をより有効に活用することを検討してください。デフォルト値:インスタンスの CPU コア数。
パイプラインバッチサイズ
単一のワーカースレッドが、フィルターと出力を実行しようとする前に入力から収集できるイベントの最大数。バッチサイズが大きいと、メモリのオーバーヘッドが高くなる可能性があります。`LS_HEAP_SIZE` 変数を設定して JVM ヒープサイズを増やすことで、この値を効果的に使用できます。デフォルト値:125。
パイプラインバッチ遅延
小さなバッチをパイプラインワーカースレッドにディスパッチする前に、各イベントを待機する時間 (ミリ秒単位)。デフォルト値:50 ms。
キュータイプ
イベントバッファリングのための内部キューイングモデル。有効な値:
MEMORY:デフォルト。従来のインメモリキュー。
PERSISTED:ディスクベースの ACK 付きキュー (永続キュー)。
キューの最大バイト数
キューが保存できるデータの最大量 (
MB単位)。値は1から2<sup>53</sup>-1までの整数である必要があります。デフォルト値は1024 MBです。説明この値が総ディスク容量より小さいことを確認してください。
キューチェックポイント書き込み
永続キューが有効な場合、これはチェックポイントが強制される前に書き込むことができるイベントの最大数です。値が 0 の場合は制限なしを意味します。デフォルト値:1024。
警告設定が完了したら、変更を有効にするために保存してデプロイする必要があります。この操作によりインスタンスが再起動します。再起動がビジネスに影響しない場合にのみ、次のステップに進んでください。
保存 または 保存してデプロイ をクリックします。
保存:Logstash にパイプライン構成を保存します。構成はデプロイされるまで有効になりません。保存後、パイプライン管理 ページに戻ります。パイプラインリスト セクションの 操作 列で 今すぐデプロイ をクリックしてインスタンスを再起動し、構成を適用します。
保存してデプロイ:構成を保存してデプロイします。これによりインスタンスが再起動され、構成が適用されます。
成功メッセージで 確認 をクリックします。新しく作成されたパイプラインが パイプラインリスト に表示されます。
インスタンスが再起動されると、パイプラインタスクが作成されます。
パイプラインの変更
パイプラインを変更して保存し、デプロイするとインスタンスが再起動します。この操作は、再起動がビジネスに影響しない場合にのみ実行してください。
パイプラインリスト セクションで、対象のパイプラインを見つけ、操作 列で パイプラインの変更 をクリックします。
パイプラインタスクの変更 ページで、設定内容 と パイプラインパラメーター を変更できます。パイプライン ID は変更できません。
保存 または 保存してデプロイ をクリックします。インスタンスが再起動すると、パイプラインが更新されます。
パイプラインのコピー
パイプラインをコピーして保存し、デプロイするとインスタンスが再起動します。この操作は、再起動がビジネスに影響しない場合にのみ実行してください。
[パイプラインリスト] セクションで、コピーするパイプラインを見つけ、[操作] 列で
 > [パイプラインのコピー] を選択します。
> [パイプラインのコピー] を選択します。パイプラインタスクのコピー ページで、パイプライン ID を変更し、他の設定は変更しないでおきます。
保存 または 保存してデプロイ をクリックします。インスタンスが再起動すると、パイプラインがコピーされます。
パイプラインの削除
削除されたパイプラインは復元できず、実行中のパイプラインタスクは中断されます。続行する前に操作を確認してください。
パイプラインを削除すると、インスタンスの変更がトリガーされます。この操作は、変更がビジネスに影響しない場合にのみ実行してください。
[パイプラインリスト] セクションで、削除するパイプラインを見つけ、[操作] 列で
> [パイプラインの削除] を選択します。パイプラインの削除 ダイアログボックスで、警告を確認します。
続行 をクリックします。インスタンスの変更が完了すると、パイプラインは削除されます。
参考資料
パイプライン作成の API ドキュメント:CreatePipelines
Logstash を使用したデータ移行のベストプラクティス:Alibaba Cloud Logstash を使用してセルフマネージド Elasticsearch データを Alibaba Cloud に移行する
Logstash を使用した MySQL データ同期のベストプラクティス:Logstash を使用して RDS for MySQL データベースから Elasticsearch にデータを同期する
Logstash を使用したログデータ同期:logstash-input-sls プラグインの使用方法