ApsaraDB RDS for MySQL データベースから Alibaba Cloud Elasticsearch クラスタにデータを同期する場合、Alibaba Cloud Logstash が提供する logstash-input-jdbc プラグインとパイプライン設定機能を使用できます。 logstash-input-jdbc は Alibaba Cloud Logstash の組み込みプラグインであり、削除することはできません。 この方法を使用して、ApsaraDB RDS for MySQL データベースから Alibaba Cloud Elasticsearch クラスタに完全データまたは増分データを同期できます。 このトピックでは、手順について詳しく説明します。
背景情報
Alibaba Cloud Logstash は、データの収集、変換、最適化、および生成に使用できる強力なデータ処理ツールです。 Alibaba Cloud Logstash は logstash-input-jdbc プラグインを提供します。このプラグインはデフォルトで Logstash クラスタにインストールされており、削除することはできません。 このプラグインは、ApsaraDB RDS for MySQL の複数のデータレコードを一度にクエリし、それらのレコードを Alibaba Cloud Elasticsearch に同期できます。 このプラグインはラウンドロビン方式を使用して、ApsaraDB RDS for MySQL に最後に挿入または更新されたデータレコードを定期的に識別し、それらのレコードを Alibaba Cloud Elasticsearch に同期します。 詳細については、「Logstash と JDBC を使用してリレーショナルデータベースから Elasticsearch クラスタにデータを同期する」をご参照ください。 完全データを同期し、数秒の遅延を許容できる場合、または一度に特定のデータをクエリして同期する場合は、Alibaba Cloud Logstash を使用できます。
前提条件
同じ仮想プライベートクラウド(VPC)内に次のインスタンスとクラスタを作成することをお勧めします。
インターネット上にデプロイされている ApsaraDB RDS for MySQL インスタンスからデータを同期するために Logstash を使用することもできます。 操作を実行する前に、Logstash クラスタのソースネットワークアドレス変換(SNAT)エントリを設定し、ApsaraDB RDS for MySQL インスタンスのパブリック IP アドレスを有効にし、関連する IP アドレスを ApsaraDB RDS for MySQL インスタンスのホワイトリストに追加する必要があります。 SNAT エントリの構成方法の詳細については、「インターネット経由のデータ転送用の NAT ゲートウェイを構成する」をご参照ください。 ApsaraDB RDS for MySQL インスタンスのホワイトリストに IP アドレスを追加する方法の詳細については、「ApsaraDB RDS for MySQL インスタンスの IP アドレスホワイトリストを構成する」をご参照ください。
ApsaraDB RDS for MySQL インスタンスを作成します。 詳細については、「ApsaraDB RDS for MySQL インスタンスを作成する」をご参照ください。 この例では、MySQL 5.7 を実行する ApsaraDB RDS インスタンスが作成されます。
Alibaba Cloud Elasticsearch クラスタを作成します。 詳細については、「Alibaba Cloud Elasticsearch クラスタを作成する」をご参照ください。 この例では、Elasticsearch V7.10 クラスタが作成されます。
Alibaba Cloud Logstash クラスタを作成します。 詳細については、「Alibaba Cloud Logstash クラスタを作成する」をご参照ください。
制限事項
ApsaraDB RDS for MySQL インスタンス、Elasticsearch クラスタ、および Logstash クラスタは同じタイムゾーンに存在する必要があります。 同じタイムゾーンに存在しない場合、時間関連データは同期後にタイムゾーンオフセットを持つ可能性があります。
Elasticsearch クラスタの _id フィールドの値は、ApsaraDB RDS for MySQL データベースの id フィールドの値と同じである必要があります。
この条件により、データ同期タスクは ApsaraDB RDS for MySQL データベースのデータレコードと Elasticsearch クラスタのドキュメント間のマッピングを確立できます。 ApsaraDB RDS for MySQL データベースのデータレコードを更新すると、データ同期タスクは更新されたデータレコードを使用して、Elasticsearch クラスタで同じ ID を持つドキュメントを上書きします。
説明本質的に、Elasticsearch の更新操作は元のドキュメントを削除し、新しいドキュメントをインデックス付けします。 したがって、上書き操作は、データ同期タスクによって実行される 更新操作 と同じくらい効率的です。
ApsaraDB RDS for MySQL データベースにデータレコードを挿入または更新する場合、データレコードには、データレコードが挿入または更新された時間を示すフィールドが含まれている必要があります。
logstash-input-jdbc プラグインがラウンドロビンを実行するたびに、プラグインはラウンドロビン内の最後のデータレコードが ApsaraDB RDS for MySQL データベースに挿入または更新された時間を記録します。 Logstash は、次の要件を満たすデータレコードのみを ApsaraDB RDS for MySQL データベースから同期します。データレコードが ApsaraDB RDS for MySQL データベースに挿入または更新された時間は、前のラウンドロビン内の最後のデータレコードが ApsaraDB RDS for MySQL データベースに挿入または更新された時間よりも後です。
重要ApsaraDB RDS for MySQL データベースのデータレコードを削除した場合、logstash-input-jdbc プラグインは同じ ID を持つドキュメントを Elasticsearch クラスタから削除できません。 Elasticsearch クラスタからドキュメントを削除するには、Elasticsearch クラスタで関連コマンドを実行する必要があります。
手順
手順 1:準備を行う
Elasticsearch クラスタの自動インデックス作成機能を有効にします。 詳細については、「Elasticsearch クラスタにアクセスして構成する」をご参照ください。
Logstash クラスタで、ApsaraDB RDS for MySQL インスタンスのバージョンと互換性のあるバージョンの SQL JDBC ドライバをアップロードします。 この例では、mysql-connector-java-5.1.48.jar ドライバが使用されます。 詳細については、「サードパーティライブラリを構成する」をご参照ください。
テストデータを準備します。 この例では、次のステートメントを使用してテーブルを作成します。
CREATE table food ( id int PRIMARY key AUTO_INCREMENT, name VARCHAR (32), insert_time DATETIME, update_time DATETIME );次のステートメントを使用して、テーブルにデータを挿入します。
INSERT INTO food values(null,'Chocolates',now(),now()); INSERT INTO food values(null,'Yogurt',now(),now()); INSERT INTO food values(null,'Ham sausage',now(),now());Logstash クラスタのノードの IP アドレスを ApsaraDB RDS for MySQL インスタンスのホワイトリストに追加します。 IP アドレスは、Logstash クラスタの [基本情報] ページで取得できます。
手順 2:Logstash パイプラインを構成する
Alibaba Cloud Elasticsearch コンソールの [Logstash クラスタ] ページ に移動します。
目的のクラスタに移動します。
上部のナビゲーションバーで、クラスタが存在するリージョンを選択します。
[logstash クラスタ] ページで、クラスタを見つけてその ID をクリックします。
表示されるページの左側のナビゲーションペインで、[パイプライン] をクリックします。
[パイプライン] ページで、[パイプラインの作成] をクリックします。
[作成] ページで、[パイプライン ID] フィールドにパイプライン ID を入力し、[設定の設定] フィールドに必要な設定を入力します。
この例では、次の設定が [設定の設定] フィールドに入力されます。
input { jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" // JDBC ドライバーのクラス jdbc_driver_library => "/ssd/1/share/<Logstash cluster ID>/logstash/current/config/custom/mysql-connector-java-5.1.48.jar" // JDBC ドライバーのライブラリへのパス。 jdbc_connection_string => "jdbc:mysql://rm-bp1xxxxx.mysql.rds.aliyuncs.com:3306/<Database name>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" // MySQL データベースへの JDBC 接続文字列。 jdbc_user => "xxxxx" // MySQL データベースのユーザー名。 jdbc_password => "xxxx" // MySQL データベースのパスワード。 jdbc_paging_enabled => "true" // ページングを有効にするかどうか。 jdbc_page_size => "50000" // ページサイズ。 statement => "select * from food where update_time >= :sql_last_value" // データをクエリするための SQL ステートメント。 schedule => "* * * * *" // SQL ステートメントを実行する頻度。 record_last_run => true // 最後の実行結果を記録するかどうか。 last_run_metadata_path => "/ssd/1/<Logstash cluster ID>/logstash/data/last_run_metadata_update_time.txt" // 最後の実行時間を含むファイルのパス。 clean_run => false // last_run_metadata_path パラメーターで指定されたパスをクリアするかどうか。 tracking_column_type => "timestamp" // トラッキングするカラムのタイプ。 use_column_value => true // 特定のカラムの値を記録するかどうか。 tracking_column => "update_time" // トラッキングするカラム。 } } filter { } output { elasticsearch { hosts => "http://es-cn-0h****dd0hcbnl.elasticsearch.aliyuncs.com:9200" // Elasticsearch クラスタのホスト。 index => "rds_es_dxhtest_datetime" // Elasticsearch インデックス。 user => "elastic" // Elasticsearch ユーザー名。 password => "xxxxxxx" // Elasticsearch パスワード。 document_id => "%{id}" // ドキュメント ID。 } }説明上記のコードの
<Logstash cluster ID>は、使用する Logstash クラスタの ID に置き換える必要があります。 ID の取得方法の詳細については、「クラスタの基本情報を表示する」をご参照ください。表 1. [設定の設定] フィールドの設定の説明
パラメーター
説明
input
入力データソースを指定します。 サポートされているデータソースタイプの詳細については、「入力プラグイン」をご参照ください。 この例では、JDBC を使用して接続された入力データソースが使用されます。 関連パラメーターの詳細については、「入力部分のパラメーター」をご参照ください。
filter
入力データをフィルタリングするために使用されるプラグインを指定します。 サポートされているプラグインの詳細については、「フィルタープラグイン」をご参照ください。
output
出力データソースを指定します。 サポートされているデータソースタイプの詳細については、「出力プラグイン」をご参照ください。 この例では、ApsaraDB RDS for MySQL データベースのデータが Elasticsearch クラスタに同期されます。 したがって、Elasticsearch クラスタの情報は出力部分で構成されます。 関連パラメーターの詳細については、「手順 3:Logstash パイプラインを作成して実行する」をご参照ください。
重要パイプラインの出力設定で file_extend パラメーターが指定されている場合、Logstash クラスタに logstash-output-file_extend プラグインがインストールされていることを確認する必要があります。 詳細については、「Logstash プラグインをインストールまたは削除する」をご参照ください。
表 2. 入力部分のパラメーター
パラメーター
説明
jdbc_driver_class
JDBC ドライバーのクラス。
jdbc_driver_library
JDBC ベースの接続に ApsaraDB RDS for MySQL データベースに使用されるドライバファイル。 このパラメーターは、/ssd/1/share/<Logstash cluster ID>/logstash/current/config/custom/<ドライバファイルの名前> 形式で構成します。 目的のドライバファイルを事前に Elasticsearch コンソールにアップロードする必要があります。 Logstash でサポートされているドライバファイルとドライバファイルのアップロード方法の詳細については、「サードパーティライブラリを構成する」をご参照ください。
jdbc_connection_string
ApsaraDB RDS for MySQL データベースへの接続に使用される接続文字列。 接続文字列には、関連する ApsaraDB RDS for MySQL インスタンスのエンドポイントとポート番号、および ApsaraDB RDS for MySQL データベースの名前が含まれています。 このパラメーターは、次の形式で構成します。
jdbc:mysql://<ApsaraDB RDS for MySQL インスタンスのエンドポイント>:<ApsaraDB RDS for MySQL インスタンスのポート番号>/<ApsaraDB RDS for MySQL データベースの名前>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false。<ApsaraDB RDS for MySQL インスタンスのエンドポイント>:ApsaraDB RDS for MySQL インスタンスの内部エンドポイントを指定する必要があります。
<ApsaraDB RDS for MySQL インスタンスのポート番号>:ポート番号は、ApsaraDB RDS for MySQL インスタンスの送信トラフィックのポート番号と同じである必要があります。 ほとんどの場合、ポート番号は 3306 です。
説明ApsaraDB RDS for MySQL インスタンスのパブリックエンドポイントを使用する場合は、Logstash クラスタのネットワークアドレス変換(NAT)ゲートウェイを構成し、
jdbc:mysql://<ApsaraDB RDS for MySQL インスタンスのパブリックエンドポイント>:<ApsaraDB RDS for MySQL インスタンスのポート番号>形式でパラメーターを構成して、Logstash クラスタがインターネットに接続できるようにする必要があります。 詳細については、「インターネット経由のデータ転送用の NAT ゲートウェイを構成する」をご参照ください。jdbc_user
ApsaraDB RDS for MySQL データベースへのアクセスに使用されるユーザー名。
jdbc_password
ApsaraDB RDS for MySQL データベースへのアクセスに使用されるパスワード。
jdbc_paging_enabled
ページングを有効にするかどうかを指定します。 デフォルト値:false。
jdbc_page_size
ページあたりのエントリ数。
statement
ApsaraDB RDS for MySQL データベースからデータをクエリするために使用される SQL ステートメント。 ApsaraDB RDS for MySQL データベースの複数のテーブルからデータをクエリする場合は、JOIN ステートメントを使用できます。
説明sql_last_value の値は、クエリする行を計算するために使用されます。 デフォルトでは、このパラメーターは 1970 年 1 月 1 日木曜日に設定されています。 詳細については、「JDBC 入力プラグイン」をご参照ください。
schedule
SQL ステートメントが実行される間隔。 値 * * * * * は、SQL ステートメントが毎分実行されることを示します。 このパラメーターは、Rufus でサポートされている cron 式に設定します。
record_last_run
最後の実行結果を記録するかどうかを指定します。 このパラメーターを true に設定すると、最後の実行結果の tracking_column の値が、last_run_metadata_path パラメーターで指定されたパスにあるファイルに保存されます。
last_run_metadata_path
最後の実行時間を含むファイルのパス。 ファイルパスはバックエンドで提供されます。 パスは
/ssd/1/<Logstash cluster ID>/logstash/data/形式です。 パスを指定すると、Logstash はパスにファイルを自動的に生成しますが、ファイル内のデータを表示することはできません。説明Logstash パイプラインを構成するときは、このパラメーターを
/ssd/1/<Logstash cluster ID>/logstash/data/形式で構成することをお勧めします。 別の形式でこのパラメーターを構成すると、同期のための条件レコードを last_run_metadata_path パラメーターで指定されたパスにあるファイルに保存できません。 ストレージの失敗は、権限が不十分なためです。clean_run
last_run_metadata_path パラメーターで指定されたパスをクリアするかどうかを指定します。 デフォルト値:false。 このパラメーターを true に設定すると、各クエリはデータベースの最初のエントリから開始されます。
use_column_value
特定のカラムの値を記録するかどうかを指定します。 このパラメーターを true に設定すると、システムは tracking_column で指定されたカラムの最新の値を記録し、SQL ステートメントが次回実行されるときに tracking_column の値に基づいてファイル内で更新する必要があるレコードを決定します。
tracking_column_type
値を追跡するカラムのタイプ。 デフォルト値:numeric。
tracking_column
値を追跡するカラム。 値は昇順でソートする必要があります。 ほとんどの場合、このカラムは主キーです。
重要前述の設定はテストデータに基づいています。 ビジネス要件に基づいてパイプラインを構成できます。 入力プラグインでサポートされている他のパラメーターの詳細については、「Logstash JDBC 入力プラグイン」をご参照ください。
設定に last_run_metadata_path に類似したパラメーターが含まれている場合、ファイルパスは Logstash によって提供される必要があります。
/ssd/1/<Logstash cluster ID>/logstash/data/形式のパスがバックエンドで提供され、テストに使用できます。 システムはこのパスのデータを削除しません。 このパスを使用する場合は、ディスクに十分なストレージ容量があることを確認してください。 パスを指定すると、Logstash はパスにファイルを自動的に生成しますが、ファイル内のデータを表示することはできません。セキュリティ上の理由から、パイプラインを構成するときに JDBC ドライバーを指定する場合は、jdbc_connection_string パラメーターの末尾に allowLoadLocalInfile=false&autoDeserialize=false を追加する必要があります(例:
jdbc_connection_string => "jdbc:mysql://xxx.drds.aliyuncs.com:3306/<Database name>?allowLoadLocalInfile=false&autoDeserialize=false")。 そうしないと、Logstash パイプラインの設定ファイルを追加するときに、チェックの失敗を示すエラーメッセージが表示されます。
[設定の設定] フィールドのパラメーターの構成方法の詳細については、「Logstash 設定ファイル」をご参照ください。
[次へ] をクリックしてパイプラインパラメーターを構成します。
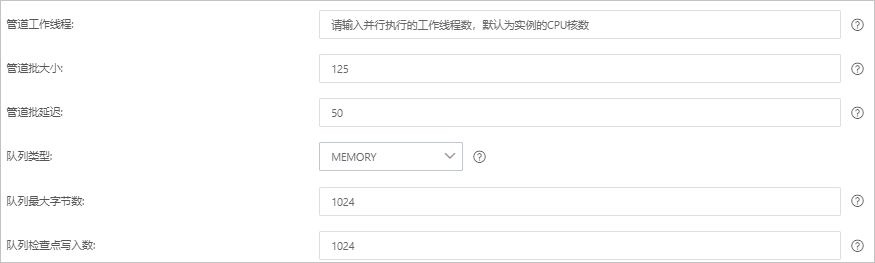
パラメーター
説明
パイプラインワーカー
パイプラインのフィルタープラグインと出力プラグインを並列で実行するワーカースレッドの数。 イベントのバックログが存在する場合、または一部の CPU リソースが使用されていない場合は、CPU 使用率を最大化するためにスレッド数を増やすことをお勧めします。 このパラメーターのデフォルト値は vCPU の数です。
パイプラインバッチサイズ
単一のワーカースレッドがフィルタープラグインと出力プラグインの実行を試みる前に、入力プラグインから収集できるイベントの最大数。 このパラメーターを大きな値に設定すると、単一のワーカースレッドはより多くのイベントを収集できますが、より多くのメモリを消費します。 ワーカースレッドがより多くのイベントを収集するのに十分なメモリを確保するには、LS_HEAP_SIZE 変数を指定して Java 仮想マシン(JVM)ヒープサイズを増やします。 デフォルト値:125。
パイプラインバッチ遅延
イベントの待機時間。 この時間は、小さなバッチをパイプラインワーカースレッドに割り当てる前、およびパイプラインイベントのバッチタスクを作成した後に発生します。 デフォルト値:50。 単位:ミリ秒。
キュータイプ
イベントをバッファリングするための内部キューモデル。 有効な値:
メモリ:従来のメモリベースのキュー。 これがデフォルト値です。
永続化:ディスクベースの ACKed キュー。これは永続キューです。
キュー最大バイト数
値はディスクの合計容量よりも小さくなければなりません。 デフォルト値:1024。 単位:MB。
キューチェックポイント書き込み
永続キューが有効になっているときにチェックポイントが適用される前に書き込まれるイベントの最大数。 値 0 は制限がないことを示します。 デフォルト値:1024。
警告パラメーターを構成した後、設定を保存してパイプラインをデプロイする必要があります。 これにより、Logstash クラスタの再起動がトリガーされます。 続行する前に、再起動がビジネスに影響を与えないことを確認してください。
[保存] または [保存してデプロイ] をクリックします。
保存:このボタンをクリックすると、システムはパイプライン設定を保存し、クラスタの変更をトリガーします。 ただし、設定は有効になりません。 [保存] をクリックすると、[パイプライン] ページが表示されます。 [パイプライン] ページで、作成したパイプラインを見つけて、[アクション] 列の [今すぐデプロイ] をクリックします。 次に、システムは Logstash クラスタを再起動して設定を有効にします。
保存してデプロイ:このボタンをクリックすると、システムは Logstash クラスタを再起動して設定を有効にします。
手順 3:結果を確認する
Elasticsearch クラスタの Kibana コンソールにログインします。
詳細については、「Kibana コンソールにログインする」をご参照ください。
左上隅にある
 アイコンをクリックし、 を選択します。
アイコンをクリックし、 を選択します。表示されるページの [コンソール] タブで、次のコマンドを実行して、同期されたデータを格納するインデックスの数を確認します。
GET rds_es_dxhtest_datetime/_count { "query": {"match_all": {}} }コマンドが正常に実行されると、次の結果が返されます。
{ "count" : 3, // 同期されたドキュメントの数。 "_shards" : { "total" : 1, // シャードの総数。 "successful" : 1, // 正常に実行されたシャードの数。 "skipped" : 0, // スキップされたシャードの数。 "failed" : 0 // 失敗したシャードの数。 } }MySQL テーブルのデータを更新し、テーブルにデータを挿入します。
UPDATE food SET name='Chocolates',update_time=now() where id = 1; INSERT INTO food values(null,'Egg',now(),now());更新および挿入されたデータを確認します。
name の値が Chocolates であるデータレコードをクエリします。
GET rds_es_dxhtest_datetime/_search { "query": { "match": { "name": "Chocolates" }} }コマンドが正常に実行されると、次の結果が返されます。
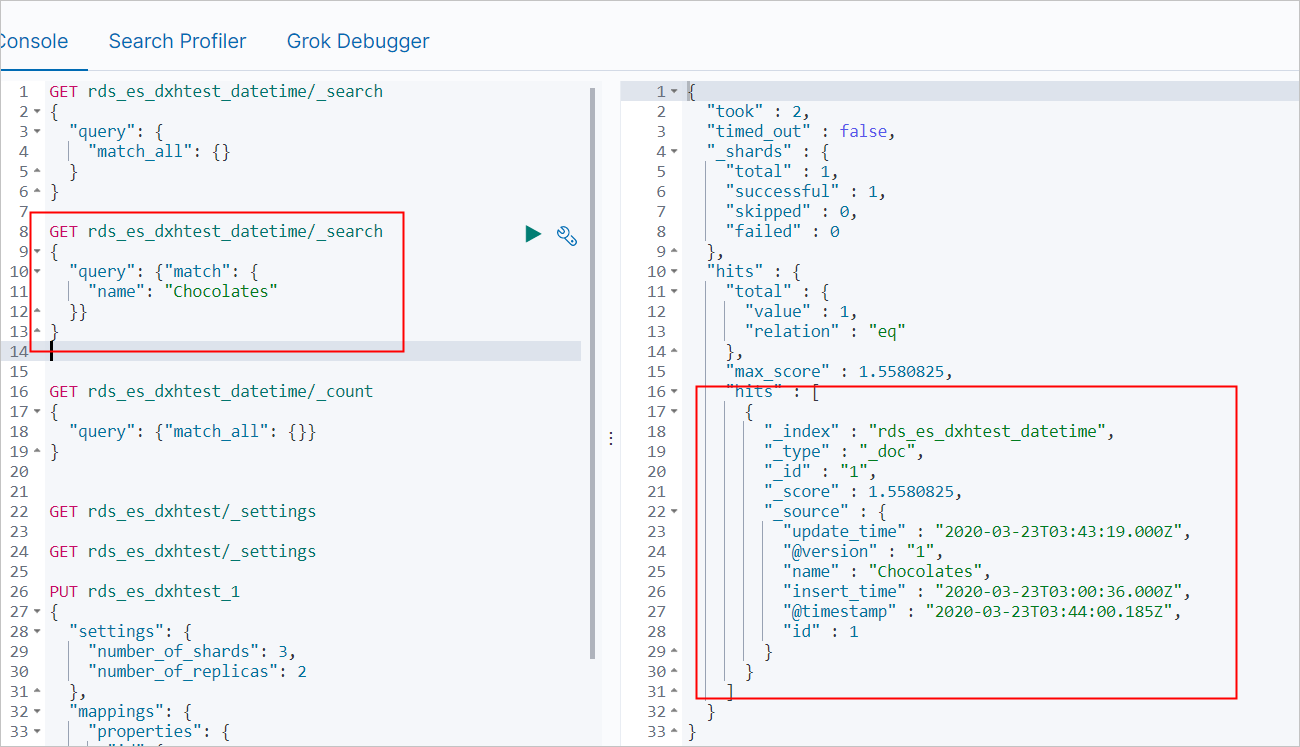
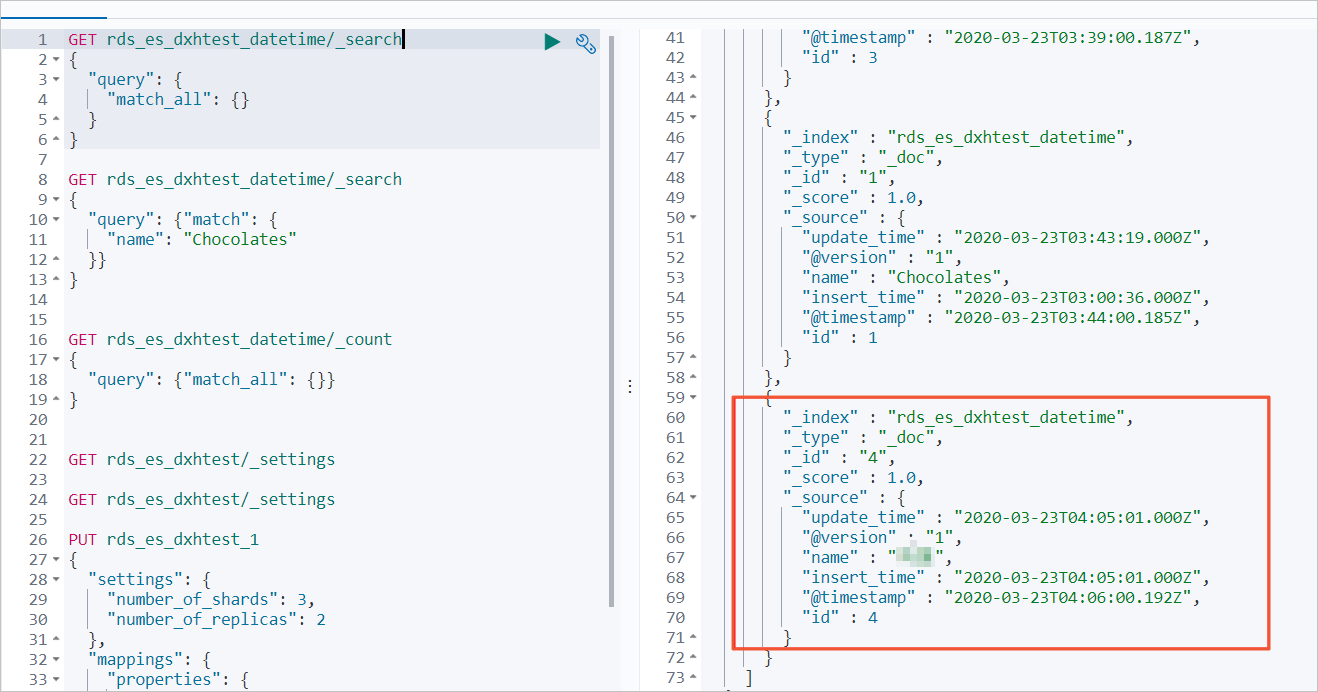
すべてのデータをクエリします。
GET rds_es_dxhtest_datetime/_search { "query": { "match_all": {} } }コマンドが正常に実行されると、次の図に示す結果が返されます。
FAQ
Q:パイプラインが初期化状態でスタックしている、同期前後のデータに矛盾がある、またはデータベースへの接続に失敗したためにデータ同期タスクが失敗した場合はどうすればよいですか?
A:Logstash クラスタのクラスタログにエラー情報が含まれているかどうかを確認し、エラー情報に基づいて原因を特定します。 詳細については、「ログをクエリする」をご参照ください。 次の表に、エラーの一般的な原因とエラーの解決策を示します。
説明次の解決策で説明されている操作を実行するときに Logstash クラスタで更新操作が実行されている場合は、「クラスタタスクの進捗状況を表示する」を参照して更新操作を一時停止します。 解決策で説明されている操作が完了すると、システムは Logstash クラスタを再起動し、更新操作を再開します。
原因
解決策
Logstash クラスタのノードの IP アドレスが ApsaraDB RDS for MySQL インスタンスのホワイトリストに追加されていません。
Logstash クラスタのノードの IP アドレスを ApsaraDB RDS for MySQL インスタンスのホワイトリストに追加します。 詳細については、「データベースクライアントまたは CLI を使用して ApsaraDB RDS for MySQL インスタンスに接続する」をご参照ください。
説明Logstash クラスタのノードの IP アドレスを取得する方法の詳細については、「クラスタの基本情報を表示する」をご参照ください。
ECS インスタンスでホストされているセルフマネージド MySQL データベースからデータを同期するために Logstash クラスタを使用していますが、クラスタのノードのプライベート IP アドレスと内部ポートが ECS インスタンスのセキュリティグループに追加されていません。
クラスタのノードのプライベート IP アドレスと内部ポートを ECS インスタンスのセキュリティグループに追加します。 詳細については、「セキュリティグループルールを追加する」をご参照ください。
説明Logstash クラスタのノードの IP アドレスとポートを取得する方法の詳細については、「クラスタの基本情報を表示する」をご参照ください。
Elasticsearch クラスタが Logstash クラスタと同じ VPC にありません。
次のいずれかの解決策を使用します。
Logstash クラスタと同じ VPC にある Elasticsearch クラスタを購入します。 詳細については、「Alibaba Cloud Elasticsearch クラスタを作成する」をご参照ください。 Elasticsearch クラスタを購入した後、Logstash クラスタのパイプライン設定を変更します。
インターネット経由でデータを送信するように NAT ゲートウェイを構成します。 詳細については、「インターネット経由のデータ転送用の NAT ゲートウェイを構成する」をご参照ください。
ApsaraDB RDS for MySQL インスタンスのエンドポイントが正しくないか、インスタンスのポート番号が 3306 ではありません。
正しいエンドポイントとポート番号を取得します。 詳細については、「インスタンスのエンドポイントとポートを表示および管理する」をご参照ください。 次に、jdbc_connection_string パラメーターの値のエンドポイントとポート番号を取得したエンドポイントとポート番号に置き換えます。
重要<ApsaraDB RDS for MySQL インスタンスのエンドポイント>:ApsaraDB RDS for MySQL インスタンスの内部エンドポイントを指定する必要があります。 ApsaraDB RDS for MySQL インスタンスのパブリックエンドポイントを使用する場合は、Logstash クラスタがインターネットに接続できるように、Logstash クラスタの NAT ゲートウェイを構成する必要があります。 詳細については、「インターネット経由のデータ転送用の NAT ゲートウェイを構成する」をご参照ください。
Elasticsearch クラスタで自動インデックス作成機能が無効になっています。
Elasticsearch クラスタの自動インデックス作成機能を有効にします。 詳細については、「YML ファイルを構成する」をご参照ください。
Elasticsearch クラスタまたは Logstash クラスタの負荷が過度に高くなっています。
Elasticsearch クラスタまたは Logstash クラスタの構成をアップグレードします。 詳細については、「クラスタの構成をアップグレードする」をご参照ください。
説明Elasticsearch クラスタの負荷が過度に高い場合は、Elasticsearch コンソールでメトリックに基づいて収集された監視データを表示して、Elasticsearch クラスタの負荷情報を取得できます。 詳細については、「メトリックと例外処理の推奨事項」をご参照ください。 Logstash クラスタの負荷が過度に高い場合は、Logstash クラスタの X-Pack Monitoring 機能を有効にして、この機能を使用して Logstash クラスタを監視し、監視データを表示できます。 詳細については、「X-Pack Monitoring 機能を有効にする」をご参照ください。
JDBC ベースの接続に ApsaraDB RDS for MySQL データベースに使用されるドライバファイルがアップロードされていません。
ドライバファイルをアップロードします。 詳細については、「サードパーティライブラリを構成する」をご参照ください。
file_extend がパイプラインの構成で指定されています。 ただし、logstash-output-file_extend プラグインがインストールされていません。
次のいずれかの解決策を使用します。
logstash-output-file_extend プラグインをインストールします。 詳細については、「プラグインをインストールおよび削除する」をご参照ください。
パイプラインの構成から file_extend パラメーターを削除します。
この問題の原因と解決策の詳細については、「Logstash を使用したデータ転送に関する FAQ」をご参照ください。
Q:パイプラインの入力設定でソースデータベースへの複数の JDBC 接続を構成するにはどうすればよいですか?
A:パイプラインの入力設定で複数の JDBC データソースを定義し、statement パラメーターで各テーブルのクエリステートメントを指定できます。 次のコードは例を示しています。
input { jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" // JDBC ドライバーのクラス。 jdbc_driver_library => "/ssd/1/share/<Logstash cluster ID>/logstash/current/config/custom/mysql-connector-java-5.1.48.jar" // JDBC ドライバーライブラリへのパス。 jdbc_connection_string => "jdbc:mysql://rm-bp1xxxxx.mysql.rds.aliyuncs.com:3306/<Database name>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" // MySQL データベースへの JDBC 接続文字列。 jdbc_user => "xxxxx" // MySQL データベースユーザー名。 jdbc_password => "xxxx" // MySQL データベースパスワード。 jdbc_paging_enabled => "true" // ページングが有効になっているかどうか。 jdbc_page_size => "50000" // ページサイズ。 statement => "select * from tableA where update_time >= :sql_last_value" // データをクエリするための SQL ステートメント。 schedule => "* * * * *" // SQL ステートメントが実行される頻度。 record_last_run => true // 最後の実行結果が記録されるかどうか。 last_run_metadata_path => "/ssd/1/<Logstash cluster ID>/logstash/data/last_run_metadata_update_time.txt" // 最後の実行時間を含むファイルへのパス。 clean_run => false // last_run_metadata_path パラメーターで指定されたパスがクリアされるかどうか。 tracking_column_type => "timestamp" // 追跡されるカラムのタイプ。 use_column_value => true // 特定のカラムの値が記録されるかどうか。 tracking_column => "update_time" // 追跡されるカラム。 type => "A" // データソースを識別するためのタイプ。 } jdbc { // tableB の設定。tableA の設定に似ています。 type => "B" // データソースを識別するためのタイプ。 } } output { if[type] == "A" { elasticsearch { hosts => "http://es-cn-0h****dd0hcbnl.elasticsearch.aliyuncs.com:9200" // Elasticsearch クラスタのホスト。 index => "rds_es_dxhtest_datetime_A" // Elasticsearch インデックス。 user => "elastic" // Elasticsearch ユーザー名。 password => "xxxxxxx" // Elasticsearch パスワード。 document_id => "%{id}" // ドキュメント ID。 } } if[type] == "B" { elasticsearch { hosts => "http://es-cn-0h****dd0hcbnl.elasticsearch.aliyuncs.com:9200" // Elasticsearch クラスタのホスト。 index => "rds_es_dxhtest_datetime_B" // Elasticsearch インデックス。 user => "elastic" // Elasticsearch ユーザー名。 password => "xxxxxxx" // Elasticsearch パスワード。 document_id => "%{id}" // ドキュメント ID。 } } }前の例では、type パラメーターが jdbc 設定に追加されています。 このパラメーターは、output 設定で条件を定義し、異なるテーブルのデータを異なるインデックスに同期するのに役立ちます。