Logstash パイプラインが期待どおりの出力を生成しない場合、一般的なワークフローでは、送信先でデータの問題を確認し、コンソールに戻り、構成を更新して再デプロイするというサイクルを、出力が正しくなるまで繰り返す必要があります。パイプライン構成デバッグ機能を使用すると、デプロイ後に Alibaba Cloud Elasticsearch コンソールでパイプライン出力データを直接表示できるため、この往復作業が不要になります。
前提条件
開始する前に、以下を確認してください。
logstash-output-file_extendプラグインがインストールされていること。詳細については、「プラグインのインストールと削除」をご参照ください。
デバッグの有効化と出力データの表示
ステップ 1: パイプライン作成ページを開く
Alibaba Cloud Elasticsearch コンソールで、Logstash クラスターページに移動します。
上部のナビゲーションバーで、ご利用のクラスターが存在するリージョンを選択します。
[Logstash Clusters] ページで、クラスターの ID をクリックします。
左側のナビゲーションウィンドウで、[パイプライン] をクリックします。
[パイプライン] ページで、[パイプラインの作成] をクリックします。
ステップ 2: パイプラインの構成
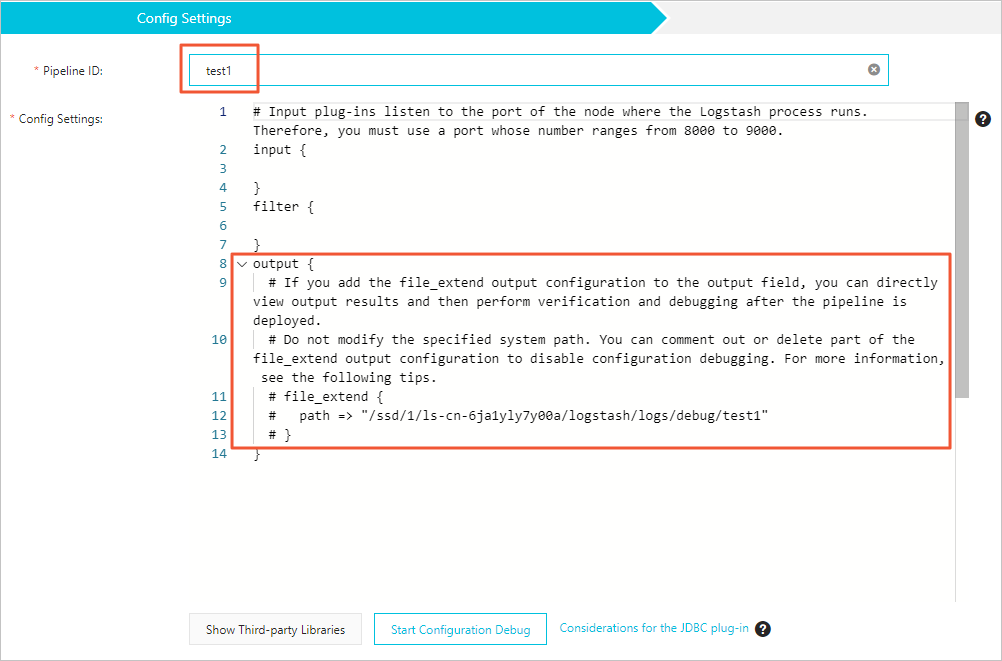
[構成設定] ステップで、[パイプライン ID] と [構成設定] を設定します。 構成設定セクション: 次の例では、ソース Elasticsearch クラスターから読み取り、送信先クラスターに書き込みます。
file_extendブロックはデバッグ用に含まれており、コメントを解除するとこの機能が有効になります。input: データソースを指定します。オープンソースの Logstash input プラグインは、
fileプラグインを除き、すべてサポートされています。filter: 収集されたデータを処理します。多数の filter プラグインがサポートされています。
output: 処理されたデータを送信先に送信します。オープンソースの Logstash output プラグインと Alibaba Cloud
file_extendoutput プラグインをサポートしています。パイプライン構成デバッグを有効にするには、file_extendブロックのコメントを解除してください。
重要output セクションの
file_extendブロックは、デフォルトでコメントアウトされています。デバッグを有効にするには、コメントを解除してください。pathの値はシステムによって割り当てられます。変更しないでください。正しいパスを取得するには、[設定デバッグの開始] をクリックします。パス内の
{pipelineid}は、ご利用のパイプライン ID に自動的にマッピングされます。変更しないでください。変更すると、デバッグログがキャプチャされません。
[パラメーター] [説明] パイプライン ID パイプラインの一意の識別子です。システムは、この値を file_extendoutput プラグインのpathフィールド内の{pipelineid}に自動的にマッピングします。設定 パイプライン構成は、 input、filter、outputの3つのセクションで構成されます。詳細については、以下を参照してください。input { elasticsearch { hosts => "http://es-cn-0pp1jxv000****.elasticsearch.aliyuncs.com:9200" user => "elastic" index => "twitter" password => "<YOUR_PASSWORD>" docinfo => true } } filter { } output { elasticsearch { hosts => ["http://es-cn-000000000i****.elasticsearch.aliyuncs.com:9200"] user => "elastic" password => "<your_password>" index => "%{[@metadata][_index]}" document_id => "%{[@metadata][_id]}" } file_extend { path => "/ssd/1/ls-cn-v0h1kzca****/logstash/logs/debug/test" } }バッチテストインポートに Elasticsearch input プラグインを使用する Elasticsearch input プラグインは、構成したクエリ文に基づいてクラスターからデータを読み取ります。これは、複数のテストログを一度にインポートするのに適しています。デフォルトでは、Logstash はすべてのデータが読み取られた後にプロセスを停止し、自動的に再起動します。これにより、パイプラインが1つしかない場合に重複書き込みが発生する可能性があります。重複を防ぐには、
scheduleパラメーターを cron 式とともに使用して、パイプラインを固定間隔で実行します。最初の実行後、Logstash はパイプラインを停止し、次のスケジュール時刻まで再起動しません。次の例では、パイプラインを毎年3月5日の13:20に実行するようにスケジュールしています。schedule => "20 13 5 3 *"詳細については、Logstash ドキュメントの「スケジューリング」をご参照ください。
[次へ] をクリックして、パイプラインのパラメーターを構成します。パラメーターの詳細については、「構成ファイルを使用してパイプラインを管理する」をご参照ください。
次のいずれかのオプションを使用して、パイプラインを保存してデプロイします。
オプション 動作 [保存] パイプラインの設定を保存し、クラスターの変更をトリガーしますが、設定は直ちに適用されません。保存後、[パイプライン] ページに移動し、パイプラインを見つけ、[操作] 列の [今すぐデプロイ] をクリックします。 [保存してデプロイ] 設定を保存し、Logstash クラスターを直ちに再起動して、それらを適用します。 確認メッセージで、[OK]をクリックします。
ステップ 3: デバッグログの表示
クラスターが再起動されると、デバッグログを表示する準備が整います。
[パイプライン]ページでパイプラインを見つけ、[操作]列の[デバッグログを表示]をクリックします。
[ログ] ページの [デバッグログ] タブで、パイプラインの出力データを確認します。 複数のパイプラインがある場合は、検索ボックスに
pipelineId: <Pipeline ID>を入力してログをフィルタリングします。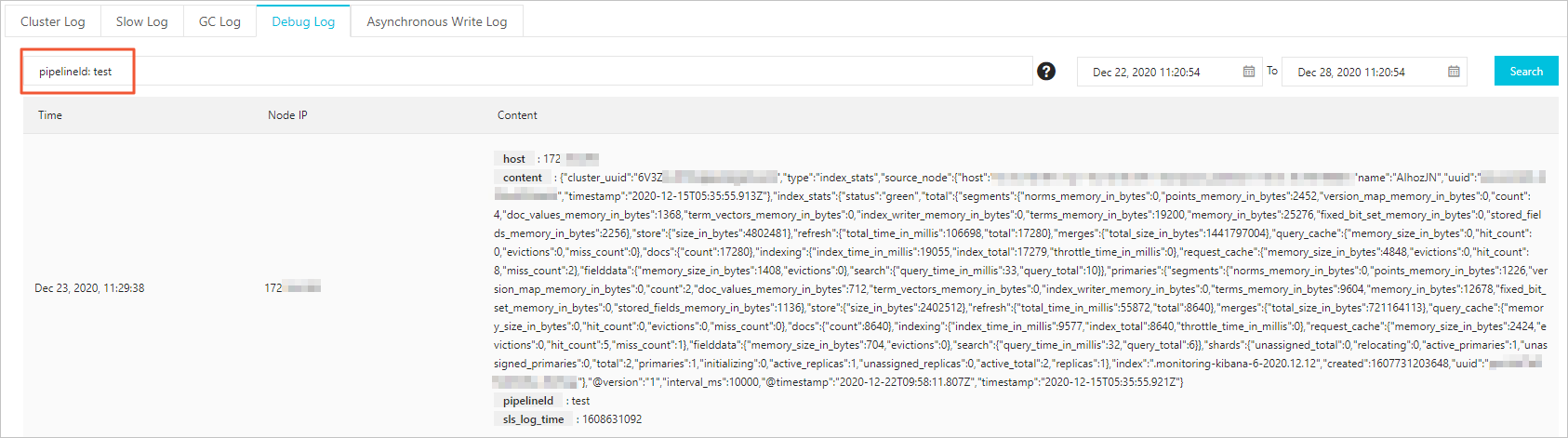
出力データが要件を満たさない場合は、パイプラインの構成に戻り、[構成設定] を調整して、再デプロイします。