前提条件
開始する前に、以下が準備できていることを確認してください。
-
Alibaba Cloud アカウント。お持ちでない場合は、こちらから登録してください。
-
Virtual Private Cloud (VPC) と vSwitch。設定手順については、「IPv4 VPC の作成」をご参照ください。
制限事項
-
ソース Elasticsearch クラスター、Logstash クラスター、および送信先 Elasticsearch クラスターは、すべて同じ VPC 内に存在する必要があります。異なる VPC にある場合は、Logstash クラスターがインターネット経由で両方のクラスターにアクセスできるように、NAT ゲートウェイを設定します。詳細については、「NAT ゲートウェイを設定してインターネット経由でデータ転送を行う」をご参照ください。
-
3 つすべてのクラスターのバージョンは、互換性の要件を満たす必要があります。続行する前に、「互換性マトリックス」をご確認ください。
概要
このガイドでは、次の手順について説明します。
-
準備 — ソースと送信先の Elasticsearch クラスターを作成し、送信先クラスターで自動インデックス作成を有効にして、テストデータをロードします。
-
Logstash クラスターの作成 — Logstash クラスターを作成し、アクティブになるまで待ちます。
-
パイプラインの作成と実行 — 2 つのクラスター間でデータを同期するように Logstash パイプラインを設定します。
-
結果の確認 — Kibana で送信先クラスターにクエリを実行し、データが到着したことを確認します。
事前準備
Elasticsearch クラスターの作成
-
Elasticsearch コンソールにログインします。
-
左側のナビゲーションウィンドウで、[Elasticsearch クラスター] をクリックします。
-
[作成] をクリックして、ソース用と送信先用に 2 つの Elasticsearch クラスターを作成します。この例では、Logstash V6.7.0 クラスターを使用して、2 つの Elasticsearch V6.7.0 Standard Edition クラスター間でデータを同期します。このガイドのパイプライン設定は、この組み合わせに適用されます。他のバージョンの組み合わせについては、まず「互換性マトリックス」で互換性を確認してください。ご利用のクラスターが要件を満たさない場合は、バージョンをアップグレードするか、新しいクラスターを作成してください。
Elasticsearch クラスターへのアクセスに使用されるデフォルトのユーザーは
elasticです。別のユーザーを使用するには、必要な権限をロールに付与し、そのロールをユーザーに割り当てます。詳細については、「Elasticsearch X-Pack が提供する RBAC メカニズムを使用してアクセス制御を実装する」をご参照ください。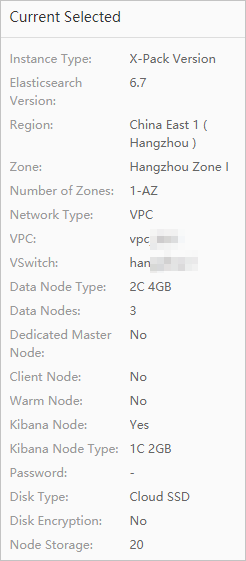
送信先クラスターでの自動インデックス作成の有効化
送信先 Elasticsearch クラスターの自動インデックス作成機能を有効にします。手順については、「YML ファイルの設定」をご参照ください。
Alibaba Cloud Elasticsearch は、セキュリティ上の理由から、デフォルトで自動インデックス作成を無効にしています。Logstash が Elasticsearch クラスターにデータを書き込む際、create index API を呼び出すのではなく、データを直接送信することでインデックスを作成します。パイプラインを実行する前に、送信先クラスターで自動インデックス作成を有効にするか、事前に手動でインデックスを作成し、そのマッピングを設定してください。
テストデータのロード
ソース Elasticsearch クラスターの Kibana コンソールにログインし、[開発ツール] に移動して、[コンソール] タブで次のコマンドを実行します。
以下のコードは Elasticsearch V6.7 クラスターにのみ適用され、テスト専用です。V7.0 以降のクラスターについては、「Elasticsearch の概要」をご参照ください。Kibana コンソールへのログイン手順については、「Kibana コンソールへのログイン」をご参照ください。
-
my_indexという名前で、タイプがmy_typeのインデックスを作成します。PUT /my_index { "settings" : { "index" : { "number_of_shards" : "5", "number_of_replicas" : "1" } }, "mappings" : { "my_type" : { "properties" : { "post_date": { "type": "date" }, "tags": { "type": "keyword" }, "title" : { "type" : "text" } } } } } -
ドキュメント
1をmy_indexに挿入します。PUT /my_index/my_type/1?pretty { "title": "One", "tags": ["ruby"], "post_date":"2009-11-15T13:00:00" } -
ドキュメント
2をmy_indexに挿入します。PUT /my_index/my_type/2?pretty { "title": "Two", "tags": ["ruby"], "post_date":"2009-11-15T14:00:00" }
ステップ 1:Logstash クラスターの作成
-
Elasticsearch コンソールで、上部のナビゲーションバーから送信先 Elasticsearch クラスターが存在するリージョンを選択します。
-
左側のナビゲーションウィンドウで、[Logstash クラスター] をクリックします。
-
[Logstash クラスター] ページで、[作成] をクリックします。
-
購入ページでクラスターを設定します。この例では、[課金方法] を [従量課金] に、[Logstash バージョン] を [6.7] に設定し、他の設定はデフォルトのままにします。すべてのパラメーターリファレンスについては、「Alibaba Cloud Logstash クラスターの作成」をご参照ください。
従量課金クラスターは開発およびテストに適しています。サブスクリプションクラスターは、本番環境での使用に対して割引が適用されます。
-
[Logstash (従量課金) 利用規約] に同意し、[今すぐ購入] をクリックします。
-
クラスターが作成されたら、[コンソール] をクリックします。上部のナビゲーションバーで、Logstash クラスターが存在するリージョンを選択します。左側のナビゲーションウィンドウで、[Logstash クラスター] をクリックし、新しいクラスターがリストに表示されることを確認します。
ステップ 2:パイプラインの作成と実行
続行する前に、Logstash クラスターの状態が [アクティブ] に変わるまで待ちます。
-
[Logstash クラスター] ページで、ご利用のクラスターを見つけ、[操作] 列の [パイプライン管理] をクリックします。
-
[パイプライン] ページで、[パイプラインの作成] をクリックします。
-
[設定の構成] ステップで、[パイプライン ID] を設定し、パイプライン設定を入力します。次の設定は、ソースクラスターから送信先クラスターに、システムインデックス以外のすべてのインデックスを同期します。すべての例では、
inputおよびoutputElasticsearch プラグインを使用し、デバッグロギングにはfile_extendを使用します。プレースホルダー 説明 例 es-cn-0pp1f1y5g000h****ソース Elasticsearch クラスターの ID es-cn-0pp1f1y5g000h4udces-cn-mp91cbxsm000c****送信先 Elasticsearch クラスターの ID es-cn-mp91cbxsm000c3ugryour_passwordElasticsearch ユーザーのパスワード — ls-cn-v0h1kzca****Logstash クラスターの ID ( file_extendパスで使用)ls-cn-v0h1kzca4ool`input` パラメーター
パラメーター 必須 説明 hostsはい ソース Elasticsearch クラスターのエンドポイント。フォーマットは http://<source-cluster-id>.elasticsearch.aliyuncs.com:9200です。userはい ソースクラスターのユーザー名。デフォルトは elasticです。passwordはい ソースクラスターユーザーのパスワード。忘れたパスワードをリセットするには、「Elasticsearch クラスターのアクセスパスワードのリセット」をご参照ください。 indexはい 読み取るインデックス。値 *,-.monitoring*,-.security*,-.kibana*は、システムインデックス (.で始まる名前のインデックス) を除くすべてのインデックスを同期します。システムインデックスはクラスターのモニタリングデータを保存するため、同期する必要はありません。docinfoいいえ trueに設定すると、ドキュメントのメタデータ (_index、_type、_id) が抽出され、[@metadata]で利用可能になります。送信先のインデックス名、タイプ、ドキュメント ID をソースと一致させたい場合に必要です。`output` パラメーター
パラメーター 必須 説明 hostsはい 送信先 Elasticsearch クラスターのエンドポイント。フォーマットは http://<destination-cluster-id>.elasticsearch.aliyuncs.com:9200です。userはい 送信先クラスターのユーザー名。 passwordはい 送信先クラスターユーザーのパスワード。 indexはい 送信先インデックス名。値 %{[@metadata][_index]}はソースインデックス名を使用します (inputでdocinfo => trueが必要)。document_typeいいえ 送信先インデックスのタイプ。値 %{[@metadata][_type]}はソースタイプと一致します。document_idいいえ 送信先インデックス内のドキュメントの ID。値 %{[@metadata][_id]}は元のドキュメント ID を保持します。file_extend>pathいいえ デバッグログのパス。このパラメーターを使用する前に、 logstash-output-file_extendプラグインをインストールします。詳細については、「プラグインのインストールおよび削除」をご参照ください。正しいパスを取得するには、コンソールで [設定デバッグの開始] をクリックします。システムで指定されたデフォルトパスは変更しないでください。input { elasticsearch { hosts => ["http://es-cn-0pp1f1y5g000h****.elasticsearch.aliyuncs.com:9200"] user => "elastic" password => "your_password" index => "*,-.monitoring*,-.security*,-.kibana*" docinfo => true } } filter {} output { elasticsearch { hosts => ["http://es-cn-mp91cbxsm000c****.elasticsearch.aliyuncs.com:9200"] user => "elastic" password => "your_password" index => "%{[@metadata][_index]}" document_type => "%{[@metadata][_type]}" document_id => "%{[@metadata][_id]}" } file_extend { path => "/ssd/1/ls-cn-v0h1kzca****/logstash/logs/debug/test" } }プレースホルダーを置き換えます:設定の構成の構文とサポートされているデータ型については、「設定ファイルの構造」をご参照ください。
-
[次へ] をクリックしてパイプラインパラメーターを設定します。[パイプラインワーカー] を Logstash クラスターの vCPU 数に設定し、他の設定はデフォルトのままにします。詳細については、「設定ファイルを使用したパイプラインの管理」をご参照ください。
-
[保存してデプロイ] をクリックします。
-
[保存] は設定を保存し、クラスターの変更をトリガーしますが、パイプラインは実行を開始しません。開始するには、[パイプライン] ページでパイプラインを見つけ、[デプロイ] をクリックします。
-
[保存してデプロイ] は Logstash クラスターをすぐに再起動し、設定を有効にします。
-
-
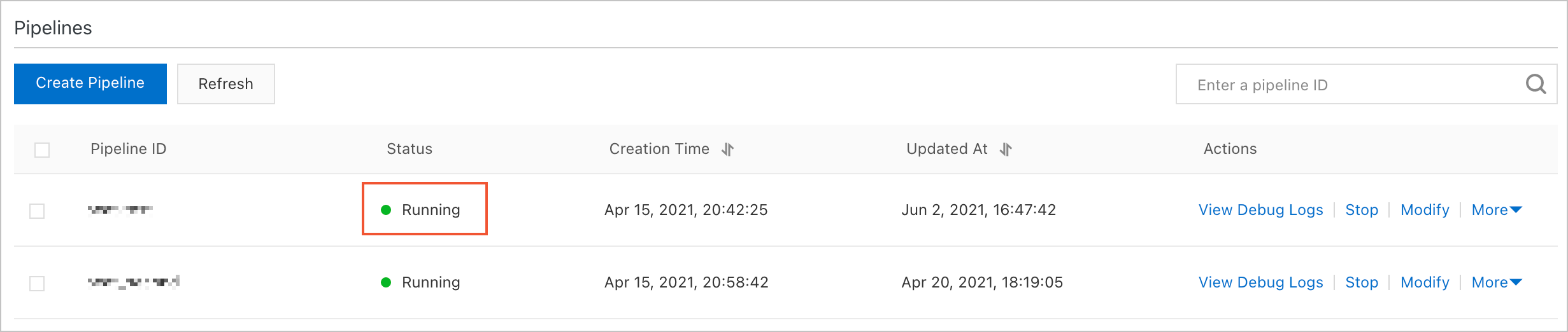
[OK] をクリックして確認します。新しいパイプラインが [パイプライン] セクションに表示されます。その状態が [実行中] に変わると、データ同期が開始されます。
ステップ 3:同期結果の確認
-
送信先 Elasticsearch クラスターの Kibana コンソールにログインします。手順については、「Kibana コンソールへのログイン」をご参照ください。
この例では、Elasticsearch V6.7.0 クラスターを使用しています。手順は他のバージョンでは異なる場合があります。
-
左側のナビゲーションウィンドウで、[開発ツール] をクリックします。
-
[コンソール] タブで、次のクエリを実行します。
GET /my_index/_search { "query": { "match_all": {} } }同期が成功した場合、送信先クラスターはソースクラスターと同じドキュメントを返します。インデックスサイズを比較するには、両方のクラスターで
GET _cat/indices?vを実行し、送信先インデックスのサイズがソースと一致することを確認します。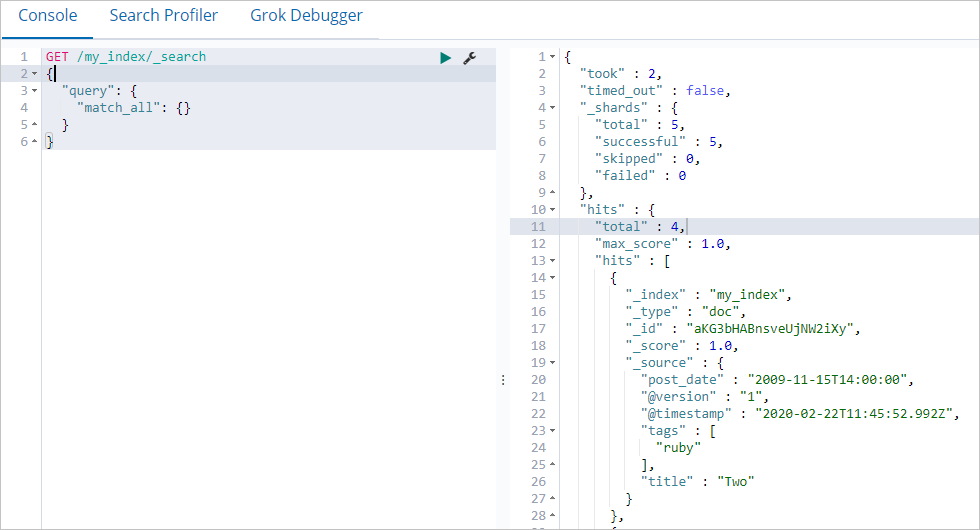
次のステップ
-
Logstash クラスターのモニタリングを設定します。
-
セルフマネージド Elasticsearch クラスターからデータを移行する:「Alibaba Cloud Logstash を使用してセルフマネージド Elasticsearch クラスターから Alibaba Cloud Elasticsearch クラスターにデータを移行する」